

인터뷰 답변: 각 MySQL 테이블에는 2천만 개 이하의 데이터가 있는 것이 가장 좋습니다. 그렇죠?

MySQL의 각 테이블은 얼마나 많은 데이터를 저장할 수 있나요? 실제 상황에서는 각 테이블이 차지하는 필드와 공간이 다르기 때문에 최적의 성능으로 저장할 수 있는 데이터의 양도 다르기 때문에 수동 계산이 필요합니다.
사건은 이렇습니다
다음은 내 친구의 인터뷰 기록입니다.
인터뷰어: 인턴 기간 동안 무엇을 했는지 말해주세요.
친구: 인턴 기간 동안 사용자 작업 기록을 저장하는 기능을 만들었습니다. 주로 MQ의 업스트림 서비스에서 전송된 사용자 작업 정보를 얻은 다음 이 정보를 동료가 데이터 웨어하우스에서 사용할 수 있도록 MySQL에 저장합니다.
친구: 데이터의 양이 상대적으로 많기 때문에 매일 4천만~5천만 건 정도의 항목이 발생하므로 이에 대한 하위 테이블 작업도 수행했습니다. 매일 정기적으로 세 개의 테이블이 생성되며, 테이블에 과도한 데이터가 쿼리 속도를 저하시키는 것을 방지하기 위해 이 세 개의 테이블에 각각 데이터를 모델링하여 저장합니다.
이 표현에는 문제가 없는 것 같죠? 걱정하지 마세요. 계속 읽어보세요.
인터뷰어: 그러면 왜 테이블 두 개로 나눌 수 없나요? 테이블 4개가 작동하지 않나요?
친구: 각 MySQL 테이블은 2천만 개의 데이터를 초과해서는 안 되기 때문에 그렇지 않으면 쿼리 속도가 감소하고 성능에 영향을 미칩니다. 우리의 일일 데이터는 약 5천만 개이므로 3개의 테이블로 나누는 것이 더 안전합니다.
인터뷰어: 더 없어요?
친구: 이제 그만...뭐해? 앗
인터뷰어: 그럼 돌아가서 알림을 기다려요.
이제 말을 마쳤는데, 제 친구의 대답에 문제가 있는 것 같나요?
머리말
많은 사람들이 각 MySQL 테이블의 데이터가 2천만 개를 초과하지 않는 것이 가장 좋다고 말합니다. 그렇지 않으면 성능 저하가 발생합니다. Alibaba의 Java 개발 매뉴얼에도 단일 테이블의 행 수가 500만 개를 초과하거나 단일 테이블의 용량이 2GB를 초과하는 경우에만 하위 데이터베이스 및 테이블을 구현하는 것이 좋습니다.
사실 이 2천만, 5백만은 대략적인 숫자일 뿐이고 모든 시나리오에 적용되는 것은 아닙니다. 테이블 데이터가 2천만을 넘지 않으면 문제가 없을 것이라고 맹목적으로 생각한다면 그렇습니다. 시스템 오류가 발생할 가능성이 높습니다.
실제 상황에서는 테이블마다 필드가 다르고 필드가 차지하는 공간 등이 다르기 때문에 최적의 성능에서 저장할 수 있는 데이터의 양도 다릅니다.
그렇다면 각 테이블에 적절한 데이터 양을 계산하는 방법은 무엇일까요? 걱정하지 말고 천천히 아래를 내려다보세요.
이 기사는 독자에게 적합합니다. 이 기사를 읽으려면 특정 MySQL 기초가 필요합니다. InnoDB 및 B+ 트리에 대해 어느 정도 이해하고 있어야 합니다. 1년간의 MySQL 학습 경험(약 1년?), "InnoDB의 B+ 트리 높이를 3단계 이내로 유지하는 것이 일반적으로 더 좋습니다"라는 이론적 지식을 알고 있습니다.
이 글은 주로 "InnoDB에서 높이가 3인 B+ 트리에 얼마나 많은 데이터를 저장할 수 있는가?"라는 주제를 설명합니다. 게다가 이 기사의 데이터 계산은 상대적으로 엄격합니다(적어도 인터넷에 있는 관련 블로그 게시물의 95%보다 더 엄격함). 이러한 세부 사항에 관심이 있고 현재 명확하지 않은 경우 계속 읽으십시오.
이 글을 읽으시는데 10~20분 정도 소요됩니다. 읽으시면서 데이터를 확인하시면 30분정도 소요될 수 있습니다.
이 글의 마인드맵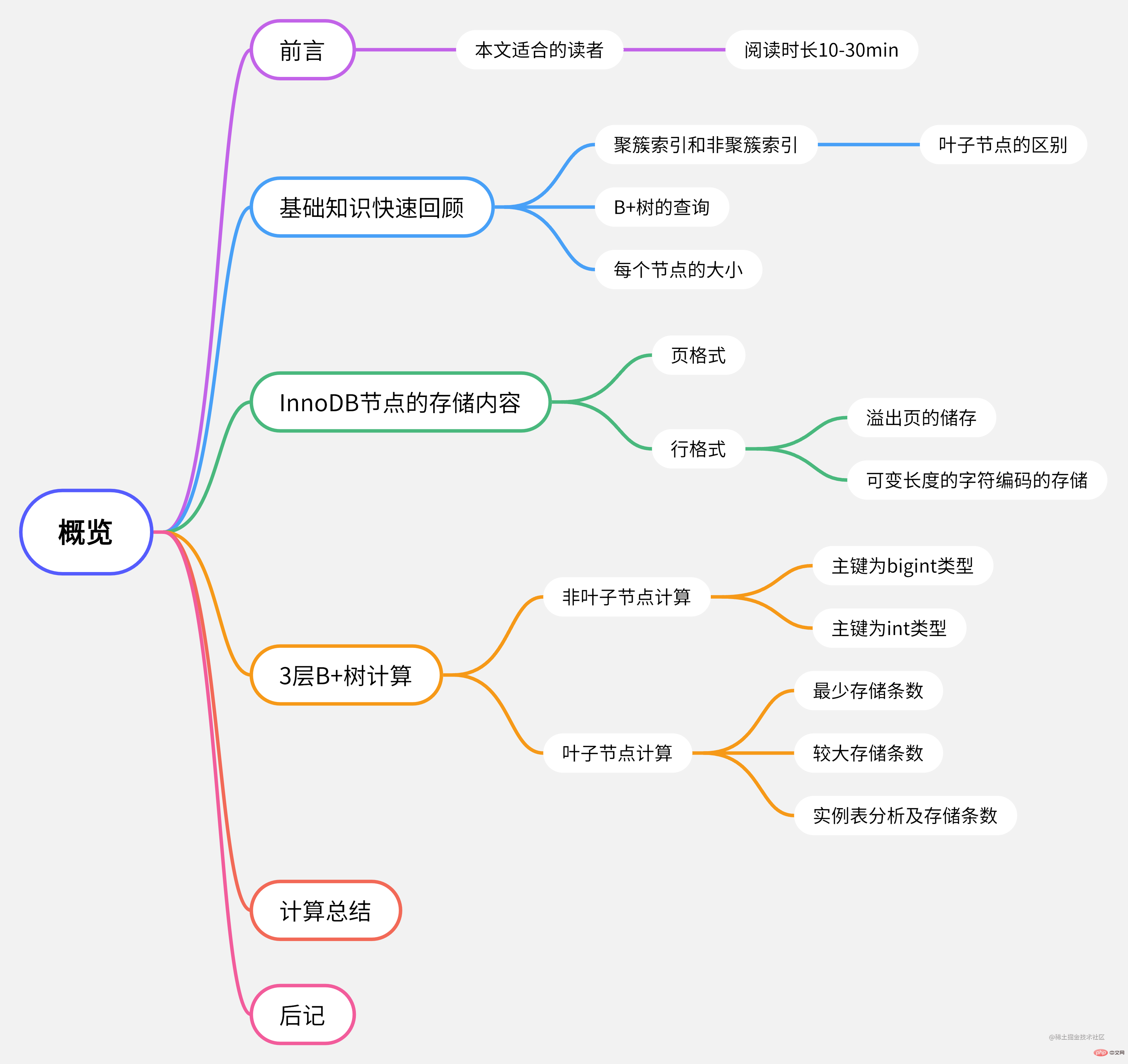
우리 모두 알고 있듯이, MySQL의 InnoDB 저장 구조는 B+ 트리입니다. , 오른쪽? 대략적인 특징은 다음과 같으니, 함께 빠르게 살펴보도록 하겠습니다!
가 생기면 다시 읽어보는 것이 좋습니다. ??
- 데이터 테이블은 일반적으로 하나 이상의 트리 저장에 해당합니다. 트리 수는 인덱스 수와 관련이 있습니다.
- 클러스터형 인덱스와 비클러스터형 인덱스:
-
기본 키 인덱스도 클러스터형 인덱스이고, 기본 키가 아닌 인덱스는 비클러스터형 인덱스입니다.
형식 정보를 제외하고 두 인덱스의 리프가 아닌 노드는 인덱스 데이터만 저장합니다. 예를 들어 인덱스가 id인 경우 리프가 아닌 노드는 id 데이터를 저장합니다. 리프 노드 간의 차이점은 다음과 같습니다.
- 클러스터형 인덱스의 리프 노드는 일반적으로 이 데이터의 모든 필드 정보를 저장합니다. 그래서 우리가
select * from table where id = 1할 때 우리는 항상 데이터를 얻기 위해 리프 노드로 이동합니다. - 비클러스터형 인덱스의 리프 노드에는 이 데이터에 해당하는 기본 키 및 인덱스 열정보가 저장됩니다. 예를 들어, 이 비클러스터형 인덱스가 사용자 이름이고 테이블의 기본 키가 id인 경우 비클러스터형 인덱스의 리프 노드는 사용자 이름과 ID를 저장하지만 다른 필드는 저장하지 않습니다. 이는 먼저 비클러스터형 인덱스에서 기본 키 값을 찾은 다음 기본 키 인덱스를 기반으로 데이터 내용을 확인하는 것과 같습니다. 일반적으로 (인덱스가 포함되지 않는 한) 두 번 확인해야 합니다. table return이라고도 하는데 이는 약간 포인터를 저장하는 것과 유사하며 데이터가 저장된 실제 주소를 가리킵니다.
- 클러스터형 인덱스의 리프 노드는 일반적으로 이 데이터의 모든 필드 정보를 저장합니다. 그래서 우리가
-
B+ 트리 쿼리는 위에서 아래로 계층별로 쿼리됩니다. 일반적으로 B+ 트리의 높이를 3개 계층 이내로 유지하는 것이 좋다고 생각합니다. 즉, 상위 2개 계층은 인덱스이고, 마지막 레이어 데이터를 저장하므로 테이블을 조회할 때 디스크 IO를 세 번만 수행하면 됩니다(루트 노드가 메모리에 상주하기 때문에 실제로는 한 번 더 적음). 저장할 수 있는 데이터의 양도 많은.
데이터 양이 너무 많아 B+ 숫자가 4레벨이 되면 각 쿼리에 4개의 디스크 IO가 필요하므로 성능이 저하됩니다. 이것이 우리가 InnoDB의 3계층 B+ 트리가 저장할 수 있는 최대 데이터 수를 계산하는 이유입니다.
-
각 MySQL 노드의 기본 크기는 16KB입니다. 즉, 각 노드는 최대 16KB의 데이터를 저장할 수 있으며 최대 64KB, 최소 4KB로 수정할 수 있습니다.
확장: 특정 행의 데이터가 특히 크고 노드 크기를 초과하면 어떻게 되나요?
MySQL5.7 문서 설명:
4KB, 8KB, 16KB 및 32KB 설정의 경우 최대 행 길이는 데이터베이스 페이지의 절반보다 약간 작습니다. 예를 들어 기본 16KB 페이지 크기의 경우 최대 행 길이는 8KB보다 약간 작으며 기본 32KB 페이지 크기의 경우 최대 행 길이는 16KB보다 약간 작습니다.
64KB 페이지의 경우 최대 행 길이는 16KB보다 약간 작습니다.
행이 최대 행 길이를 초과하는 경우 행이 최대 행 길이 제한을 충족할 때까지 가변 길이 열이 외부 페이지에 저장됩니다. 즉, 이 행의 데이터 길이를 줄이기 위해 가변 길이의 varchar 및 텍스트가 외부 페이지에 저장됩니다.

문서 주소: MySQL :: MySQL 5.7 참조 설명서 :: 14.12.2 파일 공간 관리
-
MySQL 쿼리 속도는 주로 디스크의 읽기 및 쓰기 속도에 따라 달라집니다. MySQL 쿼리는 한번에 하나의 노드만 메모리에 읽어들이고, 이 노드의 데이터를 통해 읽어야 할 다음 노드의 위치를 찾아내고, 필요한 데이터를 쿼리하거나 쿼리가 완료될 때까지 다음 노드의 데이터를 다시 읽어온다. 데이터가 존재하지 않습니다.
누군가는 각 노드의 데이터를 쿼리해야 하는 것이 아닌가요?라고 묻고 있을 것입니다. 여기서는 왜 소요시간이 계산되지 않나요?
전체 노드 데이터를 읽은 후 메모리에 저장되기 때문입니다. 실제로 메모리에 있는 노드 데이터를 쿼리하는 데는 MySQL 쿼리 방법과 결합하면 시간 복잡도가 거의
MySQL InnoDB 노드 저장 내용
Innodb의 B+ 트리에서 우리가 자주 호출하는 노드를 page(페이지)라고 하며, 각 페이지는 사용자 데이터를 저장하고 모든 페이지가 합쳐져 B+ 트리를 형성합니다( 물론 실제로는 훨씬 더 복잡하겠지만, 얼마나 많은 데이터를 저장할 수 있는지 계산하면 이렇게 이해할 수 있겠죠?)
Page는 InnoDB 스토리지 엔진이 데이터베이스를 관리하는 데 사용하는 가장 작은 디스크 단위입니다. 우리는 종종 각 노드가 16KB라고 말하며 이는 실제로 각 페이지의 크기가 16KB임을 의미합니다.
이 16KB 공간에는 페이지 형식 정보와 행 형식 정보가 저장되어야 합니다. 행 형식 정보에는 일부 메타데이터와 사용자 데이터도 포함되어 있습니다. 따라서 계산할 때 이러한 데이터를 모두 포함해야 합니다.
페이지 형식
각 페이지의 기본 형식, 즉 각 페이지에 포함될 일부 정보 요약 테이블은 다음과 같습니다.
| 이름 | Space | 의미 및 기능 etc. |
|---|---|---|
파일 헤더File Header
|
38字节 | 文件头,用来记录页的一些头信息。 包括校验和、页号、前后节点的两个指针、 页的类型、表空间等。 |
Page Header |
56字节 | 页头,用来记录页的状态信息。 包括页目录的槽数、空闲空间的地址、本页的记录数、 已删除的记录所占用的字节数等。 |
Infimum & supremum |
26字节 | 用来限定当前页记录的边界值,包含一个最小值和一个最大值。 |
User Records |
不固定 | 用户记录,我们插入的数据就存储在这里。 |
Free Space |
不固定 | 空闲空间,用户记录增加的时候从这里取空间。 |
Page Directort |
不固定 | 页目录,用来存储页当中用户数据的位置信息。 每个槽会放4-8条用户数据的位置,一个槽占用1-2个字节, 当一个槽位超过8条数据的时候会自动分成两个槽。 |
File Trailer | 38바이트파일 헤더, 페이지의 일부 헤더 정보를 기록하는 데 사용됩니다. | 체크섬, 페이지 번호, 이전 및 다음 노드에 대한 두 개의 포인터, | 페이지 유형, 테이블 공간 등 포함
페이지 헤더🎜🎜56바이트🎜🎜페이지 헤더, 페이지 상태 정보를 기록하는 데 사용됩니다. 🎜페이지 디렉토리의 슬롯 수, 여유 공간의 주소, 이 페이지의 레코드 수, 🎜삭제된 레코드가 차지하는 바이트 수 등이 포함됩니다. 🎜🎜🎜🎜Infimum & supremum🎜🎜26바이트🎜🎜는 최소값과 최대값을 포함하여 현재 페이지 레코드의 경계값을 제한하는 데 사용됩니다. 🎜🎜🎜🎜사용자 기록🎜🎜수정되지 않음🎜🎜사용자 기록, 우리가 삽입한 데이터는 여기에 저장됩니다. 🎜🎜🎜🎜여유 공간🎜🎜고정되지 않음🎜🎜여유 공간, 사용자 기록이 추가되면 여기에서 공간을 가져옵니다. 🎜🎜🎜🎜페이지 디렉터🎜🎜Unfixed🎜🎜페이지 디렉터리는 페이지 내 사용자 데이터의 위치 정보를 저장하는 데 사용됩니다. 🎜각 슬롯에는 4~8개의 사용자 데이터가 저장되며, 하나의 슬롯은 1~2바이트를 차지합니다. 🎜한 슬롯이 8개의 데이터를 초과하면 자동으로 2개의 슬롯으로 분할됩니다. 🎜🎜🎜🎜파일 예고편🎜🎜8바이트🎜🎜파일 정보의 끝, 주로 페이지 무결성을 확인하는 데 사용됩니다. 🎜🎜🎜🎜구성도:
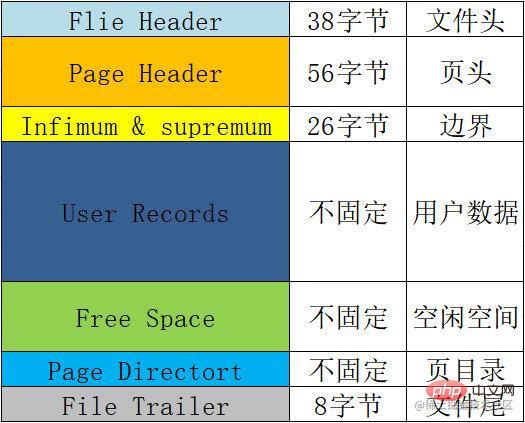
페이지 형식의 내용인데, 공식 홈페이지에서 한참 뒤져봤는데 그냥 못찾았나요?. . . . 제가 글을 작성하지 않아서인지, 아니면 제가 눈이 멀어서 그런 것인지 모르겠습니다. 혹시 찾으신 분이 계시다면 댓글란에 올려주시면 감사하겠습니다.
그래서 위 페이지 형식의 표 내용은 주로 일부 블로그에서 학습한 내용과 요약을 바탕으로 작성되었습니다.
또한 InnoDB 클러스터형 인덱스에 새 레코드가 삽입되면 InnoDB는 향후 인덱스 레코드 삽입 및 업데이트를 위해 페이지의 1/16을 비워 두려고 합니다. 색인 레코드를 순서대로(오름차순 또는 내림차순) 삽입하면 결과 페이지에는 사용 가능한 공간이 약 15/16이 됩니다. 레코드를 무작위 순서로 삽입하는 경우 페이지 공간의 약 1/2 ~ 15/16을 사용할 수 있습니다. 참조 문서: MySQL :: MySQL 5.7 참조 설명서 :: 14.6.2.2 InnoDB 인덱스의 물리적 구조
User Records和Free Space을 제외하고 점유된 메모리는 = 1523216회 분수{15} {16}1024 - 128 = 15232


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7533
7533
 15
1379
52
82
11
55
19
21
86
15
1379
52
82
11
55
19
21
86

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
백업 또는 트랜잭션 롤백 메커니즘이없는 한 데이터베이스에서 직접 삭제 된 행 복구는 일반적으로 불가능합니다. 키 포인트 : 거래 롤백 : 트랜잭션이 데이터를 복구하기 전에 롤백을 실행합니다. 백업 : 데이터베이스의 일반 백업을 사용하여 데이터를 신속하게 복원 할 수 있습니다. 데이터베이스 스냅 샷 : 데이터베이스의 읽기 전용 사본을 작성하고 데이터를 실수로 삭제 한 후 데이터를 복원 할 수 있습니다. 주의해서 삭제 명령문을 사용하십시오. 실수로 데이터를 삭제하지 않도록 조건을주의 깊게 점검하십시오. WHERE 절을 사용하십시오 : 삭제할 데이터를 명시 적으로 지정하십시오. 테스트 환경 사용 : 삭제 작업을 수행하기 전에 테스트하십시오.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다