

Oracle에서 데이터 중복을 제거하는 방법

제거 방법: 1. 중복 항목을 제거하려면 고유 키워드를 사용합니다. "SELECT DISTINCT field name FROM table name;" 2. 창 함수 row_number() over()를 사용하여 중복 항목을 제거합니다. 중복 제거의 경우 구문은 "필드 이름별로 테이블 이름 그룹에서 필드 이름 선택"입니다. 4. 의사 열을 중복 제거하려면 rowid를 사용합니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Oracle 11g 버전, Dell G3 컴퓨터.
비즈니스 시나리오
특정 데이터를 쿼리해야 합니다. 관련 쿼리에는 3개의 테이블이 필요하므로 쿼리 결과는 다음과 같습니다.

원본 SQL 문
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
SELECT DISTINCT를 사용하면 결과 집합에서 중복 행을 필터링하여 SELECT 절에서 반환된 지정된 열의 값이 고유한지 확인할 수 있습니다.
DISTINCT 문의 구문은 다음과 같습니다.
SELECT DISTINCT column_1,
column_2,
...
FROM
table_name;예:
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
참고: Oracle은 먼저 DISTINCT를 수행하여 중복 항목을 제거한 다음 ORDER BY를 사용하여 정렬해야 합니다. 따라서 ORDER BY로 정렬해야 할 필드가 Distinct 이후의 필드에 없다면 당연히 오류가 발생하게 됩니다.
오류 메시지는 다음과 같습니다.
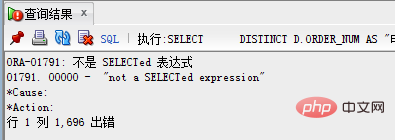
구문 형식
select * from (select A.*, row_number() over(partition by A.name1 order by A.name12 desc) rn from A) where rn = 1
예
select * from ( select d.order_num as "申请单号" , d.create_time , d.emp_name as "申请人", (select extractvalue(t1.row_data,'/root/row/FI13_wasteName') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "废料名称", (select extractvalue(t1.row_data,'/root/row/FI13_units') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "单位", (select extractvalue(t1.row_data,'/root/row/FI13_estimate') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "预估数量", (select extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "累计出库数量", (select extractvalue(t1.row_data,'/root/row/FI13_receivingTime') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdCGYTX' ) as "收购方收货时间", (select extractvalue(t2.row_data,'/root/row/FI13_collectionTime') from dat_table_row t2 where d.document_id = t2.document_id and t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) as "实际收款时间", row_number() over(partition by d.order_num order by d.create_time desc) rn from dat_document d, dat_table_row dtr where d.form_name ='FI14' and d.document_id =dtr.document_id and (d.document_status != 'deleted' or d.document_status is null ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' and d.order_num = 'FI1420210708002' --FI1420210708002 ) where rn = 1;
쿼리 결과
방법 3 :
select 字段名 from 表名 group by 字段名;
별로 그룹화 방법 4: rowid 사용(의사 열 중복 제거)
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
권장 튜토리얼: "Oracle Tutorial"
위 내용은 Oracle에서 데이터 중복을 제거하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7549
7549
 15
1382
52
83
11
58
19
22
90
15
1382
52
83
11
58
19
22
90

 Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle 테이블 스페이스 크기를 쿼리하려면 다음 단계를 따르십시오. 쿼리를 실행하여 테이블 스페이스 이름을 결정하십시오. 쿼리를 실행하여 테이블 스페이스 크기를 쿼리하십시오. sum (bytes)을 total_size, sum (bytes_free)으로 sum (bytes_free), sum (bytes) - sum (bytes_free)으로 dba_data_fices where tablespace_.
 오라클에서 시간을 얻는 방법
Apr 11, 2025 pm 08:09 PM
오라클에서 시간을 얻는 방법
Apr 11, 2025 pm 08:09 PM
Oracle에는 시간을 얻는 방법이 있습니다. current_timestamp : 현재 시스템 시간을 반환합니다. Systimestamp : current_timestamp보다 나노 초보다 더 정확합니다. sysdate : 시간 부분을 제외하고 현재 시스템 날짜를 반환합니다. to_char (sysdate, 'yyy-mm-dd hh24 : mi : ss') : 현재 시스템 날짜와 시간을 특정 형식으로 변환합니다. 추출 : 1 년, 월 또는 시간과 같은 시간 값에서 특정 부분을 추출합니다.
 Oracle View를 암호화하는 방법
Apr 11, 2025 pm 08:30 PM
Oracle View를 암호화하는 방법
Apr 11, 2025 pm 08:30 PM
Oracle View 암호화를 사용하면보기에서 데이터를 암호화 할 수 있으므로 민감한 정보의 보안을 향상시킬 수 있습니다. 단계에는 다음이 포함됩니다. 1) 마스터 암호화 키 생성 (MEK); 2) 암호화 된 뷰 생성, 암호화 할보기 및 MEK를 지정하는 것; 3) 사용자가 암호화 된보기에 액세스하도록 승인합니다. 암호화 된 뷰 작동 방식 : 사용자가 암호화 된보기를 쿼리 할 때 Oracle은 MEK를 사용하여 데이터를 해독하여 공인 사용자 만 읽기 쉬운 데이터에 액세스 할 수 있도록합니다.
 Oracle의 인스턴스 이름을 보는 방법
Apr 11, 2025 pm 08:18 PM
Oracle의 인스턴스 이름을 보는 방법
Apr 11, 2025 pm 08:18 PM
Oracle에서 인스턴스 이름을 보는 세 가지 방법이 있습니다. 명령 줄에 명령. "show instance_name"을 사용하십시오. sql*plus의 명령. 운영 체제의 작업 관리자, Oracle Enterprise Manager 또는 운영 체제를 통해 환경 변수 (Linux의 Oracle_Sid)를 확인하십시오.
 Oracle 설치를 제거하는 방법에 실패했습니다
Apr 11, 2025 pm 08:24 PM
Oracle 설치를 제거하는 방법에 실패했습니다
Apr 11, 2025 pm 08:24 PM
Oracle 설치 실패에 대한 방법 제거 : Oracle Service를 닫고 Oracle Program 파일 및 레지스트리 키 삭제, Oracle 환경 변수를 제거하고 컴퓨터를 다시 시작하십시오. 제거되지 않으면 Oracle 범용 제거 도구를 사용하여 수동으로 제거 할 수 있습니다.
 유효하지 않은 수의 Oracle을 확인하는 방법
Apr 11, 2025 pm 08:27 PM
유효하지 않은 수의 Oracle을 확인하는 방법
Apr 11, 2025 pm 08:27 PM
Oracle 유효하지 않은 숫자 오류는 데이터 유형 불일치, 숫자 오버플로, 데이터 변환 오류 또는 데이터 손상으로 인해 발생할 수 있습니다. 문제 해결 단계에는 데이터 유형 확인, 디지털 오버 플로우 감지, 데이터 변환 확인, 데이터 손상 확인 및 NLS_NUMERIC_CHARACTERS 매개 변수 구성 및 데이터 확인 로깅 활성화와 같은 다른 가능한 솔루션 탐색이 포함됩니다.
 Oracle 사용자를 설정하는 방법
Apr 11, 2025 pm 08:21 PM
Oracle 사용자를 설정하는 방법
Apr 11, 2025 pm 08:21 PM
Oracle에서 사용자를 만들려면 다음 단계를 따르십시오. 사용자 명령문을 사용하여 새 사용자를 만듭니다. 보조금 명세서를 사용하여 필요한 권한을 부여하십시오. 선택 사항 : 리소스 문을 사용하여 할당량을 설정하십시오. 기본 역할 및 임시 테이블 스페이스와 같은 다른 옵션을 구성하십시오.
 Oracle Cursor를 닫는 문제를 해결하는 방법
Apr 11, 2025 pm 10:18 PM
Oracle Cursor를 닫는 문제를 해결하는 방법
Apr 11, 2025 pm 10:18 PM
Oracle Cursor Closure 문제를 해결하는 방법에는 다음이 포함됩니다. Close 문을 사용하여 커서를 명시 적으로 닫습니다. For Update 절에서 커서를 선언하여 범위가 종료 된 후 자동으로 닫히십시오. 연관된 PL/SQL 변수가 닫히면 자동으로 닫히도록 사용 절에서 커서를 선언하십시오. 예외 처리를 사용하여 예외 상황에서 커서가 닫혀 있는지 확인하십시오. 연결 풀을 사용하여 커서를 자동으로 닫습니다. 자동 제출을 비활성화하고 커서 닫기를 지연시킵니다.
