

MySQL의 데이터베이스 버퍼 풀(Buffer Pool)에 대해 알아보세요.


InnoDB 스토리지 엔진을 사용하는 테이블의 경우 스토리지 공간은 메모리와 디스크 간 교체를 위한 기본 단위로 페이지 단위로 관리됩니다. 디스크에서 메모리로 페이지를 로드하면 디스크 I/O가 수행됩니다. 디스크 I/O의 오버헤드는 전체 성능에 큰 영향을 미치며, 해당 페이지를 메모리에서 직접 읽어오면 디스크 I/O로 인한 성능 손실이 줄어들고 효율성도 많이 향상되지 않을까요? 이를 바탕으로 Buffer Pool(
Buffer Pool)이 등장했으니 다음으로는 InnoDB의 Buffer Pool에 대해 알아보겠습니다.Buffer Pool) 出现了,那么接下来,我们就来谈谈InnoDB中的Buffer Pool。
缓冲池(Buffer Pool)
有人会想,既然缓冲池这么好,那我们将所有数据都存储到缓冲池中不就好了,不不不,缓冲池是操作系统分配的一片连续的内存。而内存相比于磁盘的容量小得多,并且价格昂贵。那么操作系统会给缓冲池分配多少内存呢?
- 默认情况下,缓冲池的大小为128MB;
当然,如果你的机器的内存容量非常大,可以在配置文件中配置启动选项参数innodb_buffer_pool_size单位是字节,最小不能小于5MB。
缓冲池的内部结构
缓冲池将操作系统分配的这一片连续的内存,划分成若干个大小默认为16KB的页(缓冲页)【此时还没有真正的磁盘页被缓存到Buffer Pool中】,当我们从磁盘中换入一个页到缓冲池中,如何分配位置呢?因此就需要一些控制信息来标识这些缓冲池中的缓冲页,这些控制信息都存放在一个叫控制块的内存区域中,与缓冲页一一对应。控制块的大小也是固定的。因此在这片连续的内存空间中,难免会产生内存碎片。综上,缓冲池的内部结构如下:
- 缓冲页
- 控制块:页号、缓冲页在缓冲池中的地址、链表节点信息等。
- 内存碎片【若内存分配得当,内存碎片可有可无】
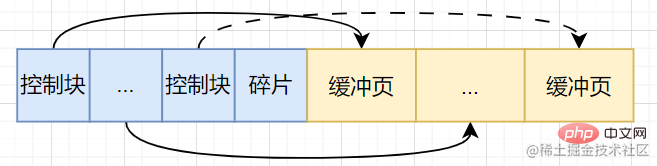
缓冲池的管理
上面在控制块中提到了链表节点信息,那么链表节点是用来做什么的呢?是为了更好的管理缓冲池中的页。而链表就是用来链接控制块的,因为控制块与缓冲页是一一对应的。
1)空闲链表
将所有空闲的缓冲页对应的控制块链接起来,形成的链表。
解决的问题:从磁盘中换入一个页到缓冲池中,如何区分缓冲池中的哪个页是空闲的呢?而有了空闲链表之后,换入一个磁盘页到缓冲池中时,就直接从空闲链表中获取一个空闲的缓冲页,并将磁盘页中对应的信息填到缓冲页对应的控制块中,然后将该控制块从空闲链表中删除即可。
2)更新链表
若修改了缓冲池中的缓冲页的数据,导致其与磁盘中数据不一致,该页称为脏页。将所有脏页对应的控制块链接起来形成更新链表,在将来的某个时间根据该链表将对应缓存页的数据刷新到磁盘中。
3)LRU链表
缓冲池的大小是有限的,如果缓存的页超出了缓冲池的大小,即没有空闲的缓冲页了,当有新的页要添加到缓冲池中时,采取LRU的策略将旧的缓冲页从缓冲池中移除,然后将新的页添加进来。由于LRU链表涉及的内容较多,我们接下来单独介绍。
LRU链表所蕴含的“哲理”
先提一下预读机制
在I/O上的优化机制,预读顾名思义,会异步地把某些页面加载到缓冲池中,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面,就是所谓的 局部性原理,目的是减少磁盘I/O。
了解预读机制之前,先回顾一下InnoDB逻辑存储单元:表空间(tablespace)→段(segment )→区(extent)→页(page)。其中特意提一下区,后面会用到:一个区就是物理位置上连续的64个页
버퍼 풀
버퍼 풀이 이렇게 좋으니 모든 데이터를 버퍼 풀에 저장하면 어떨까 하는 분들도 계실 텐데요. 괜찮아, 아니야 아니야,버퍼 풀은 운영 체제에서 할당한 연속 메모리입니다. 메모리는 디스크에 비해 용량이 훨씬 작고 가격도 비쌉니다. 그렇다면 운영 체제는 버퍼 풀에 얼마나 많은 메모리를 할당합니까? 
- 기본적으로 버퍼 풀의 크기는 128MB입니다.
innodb_buffer_pool_size단위는 bytes이며, 최소값은 5MB 이상일 수 없습니다.
버퍼 풀의 내부 구조
🎜버퍼 풀은 운영 체제에서 할당한 연속 메모리를 기본 크기 16KB로 여러 페이지(버퍼 페이지)로 나눕니다. 현재 버퍼 풀에는 실제 디스크 페이지가 캐시되어 있지 않습니다.] 디스크의 페이지를 버퍼 풀로 스왑할 때 위치를 어떻게 할당합니까? 따라서 이러한 버퍼 풀에서 버퍼 페이지를 식별하려면 일부 제어 정보가 필요합니다. 이 제어 정보는 제어 블록이라는 메모리 영역에 저장되며 버퍼 페이지와 일대일로 대응됩니다. 제어 블록의 크기도 고정되어 있습니다. 따라서 이 연속적인 메모리 공간에서는 필연적으로 메모리 단편화가 발생하게 된다. 버퍼 풀의 내부 구조를 정리하면 다음과 같다. 🎜- 버퍼 페이지
- 제어 블록: 페이지 번호, 버퍼 풀 내 버퍼 페이지 주소, 연결 리스트 노드 정보 , 등.
- 메모리 조각화 [메모리가 제대로 할당되면 메모리 조각화는 불필요]
 🎜
🎜버퍼 풀 관리
🎜 링크됨 리스트 노드 정보는 위에서 컨트롤 블록에 언급되어 있는데 링크드 리스트 노드는 어떤 용도로 사용되나요? 버퍼 풀의 페이지를 더 잘 관리하기 위한 것입니다. 연결된 목록은 제어 블록과 버퍼 페이지 사이에 일대일 대응이 있기 때문에 제어 블록을 연결하는 데 사용됩니다. 🎜1) 자유 연결 리스트
🎜 모든 자유 버퍼 페이지에 해당하는 제어 블록을 연결하여 연결 리스트를 형성합니다. 🎜🎜🎜문제 해결: 디스크에서 버퍼 풀로 페이지를 교환할 때 버퍼 풀의 어느 페이지가 사용 가능한지 어떻게 구별할 수 있나요? 프리 링크드 리스트는 디스크 페이지가 버퍼 풀로 스왑되면 프리 링크 리스트에서 직접 프리 버퍼 페이지를 얻어 디스크 페이지의 해당 정보를 버퍼 페이지에 해당하는 컨트롤 블록에 채우는 방식으로, 그런 다음 자유 연결 목록에서 제어 블록을 삭제하십시오. 🎜2) 연결 리스트 업데이트
🎜버퍼 풀에 있는 버퍼 페이지의 데이터가 수정되어 디스크의 데이터와 일치하지 않는 경우, 페이지를 더티 페이지라고 합니다. 모든 더티 페이지에 해당하는 컨트롤 블록을 연결하여 업데이트 연결 리스트를 형성하고, 이 연결 리스트를 기반으로 향후 특정 시간에 해당 캐시 페이지의 데이터를 디스크에 새로 고칩니다. 🎜3) LRU 연결 목록
🎜버퍼 풀의 크기는 제한되어 있습니다. 캐시된 페이지가 버퍼 풀의 크기를 초과하면 여유 버퍼가 없습니다. 새로운 페이지가 버퍼 풀에 추가될 때 버퍼 풀에서 이전 버퍼 페이지를 제거한 다음 새 페이지를 추가하는 LRU 전략이 채택됩니다. LRU 연결 리스트에는 많은 내용이 포함되어 있으므로 다음에 별도로 소개하겠습니다. 🎜LRU 연결 목록에 포함된 "철학"
먼저 사전 읽기 메커니즘에 대해 언급하겠습니다h2>🎜In I 이름에서 알 수 있듯이 /O의 최적화 메커니즘인 미리 읽기는 특정 페이지를 버퍼 풀에 비동기적으로 로드합니다. 이러한 요청은 범위의 모든 페이지를 곧 필요로 합니다. 소위 🎜 지역성 원칙 의 목적은 디스크 I/O를 줄이는 것입니다. 🎜🎜미리 읽기 메커니즘을 이해하기 전에 InnoDB의 논리적 저장 단위인 테이블스페이스 → 세그먼트 → 익스텐트 → 페이지를 살펴보겠습니다. 나중에 사용될 영역이 구체적으로 언급됩니다. 영역은 물리적 위치에서 연속적인 64페이지입니다. 즉, 영역의 크기는 1MB입니다.🎜🎜🎜🎜🎜사전 읽기 메커니즘은 다음 두 가지 유형으로 나눌 수 있습니다. 🎜
-
선형 미리 읽기: 버퍼 풀의 페이지에 대한 순차적 액세스를 기반으로 곧 필요할 페이지를 예측하는 기술입니다. innodb_read_ahead_threshold 파라미터를 설정하면, 순차적으로 접근하는 특정 영역의 페이지 수가 이 파라미터 값을 초과하는 경우 비동기 읽기 요청이 발생하여 다음 영역의 모든 페이지를 버퍼 풀로 읽어들인다.
-
Random read-ahead: 해당 페이지를 읽는 순서에 관계없이 이미 버퍼 풀에 있는 페이지를 기반으로 페이지가 필요할 시기를 예측할 수 있습니다. 동일한 익스텐트의 13개 연속 페이지가 버퍼 풀에서 발견되면 InnoDB는 익스텐트의 나머지 페이지를 프리페치하라는 요청을 비동기적으로 발행합니다. innodb_random_read_ahead 변수를 구성하여 무작위 읽기를 제어합니다.
기존 LRU는 버퍼 페이지를 어떻게 관리하나요?
LRU 알고리즘을 사용하여 가장 최근에 사용된 버퍼 페이지를 관리하고 쉽게 제거할 수 있도록 해당 연결 목록을 구성합니다.
페이지에 액세스한 경우[즉, 최근에 액세스한 경우]
- 페이지가 버퍼 풀에 있으면 해당 제어 블록을 LRU 연결 목록의 헤드로 이동합니다.
- 페이지가 버퍼 풀에 없으면 최소한의 블록을 제거합니다. 최근에 사용한 페이지를 마지막에 저장하고 디스크에서 제거합니다. 페이지를 로드하여 LRU 링크드 리스트의 선두에 배치합니다
그렇다면 InnoDB는 왜 이렇게 직관적인 LRU 알고리즘을 사용하지 않는 걸까요? 그 이유는 다음과 같습니다.
-
미리 읽기 실패
미리 읽기가 가능한 버퍼 풀의 페이지는 LRU 연결 목록의 선두에 배치되지만, 그 중 많은 페이지가 읽혀지지 않을 수 있습니다.
-
버퍼 풀 오염
자주 사용하지 않는 페이지를 버퍼 풀에 로드하면 자주 사용되는 페이지가 버퍼 풀에서 제거됩니다. 예를 들어, full table scan
최적화된 LRU는 버퍼 페이지를 어떻게 관리합니까?
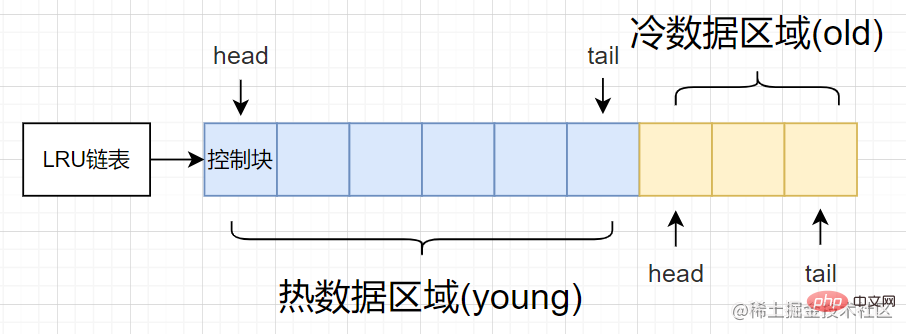
위의 단점을 기반으로 최적화된 특정 방법은 기존 LRU 연결 목록을 핫 데이터 영역[젊은 영역] 및 콜드 데이터 영역[올드 영역]
- 핫 데이터 영역[젊은 영역] 의 두 부분으로 나눕니다. 사용 빈도 높은 버퍼 페이지
- 콜드 데이터 영역[노인 지역]: 사용 빈도가 낮은 영역
간단한 구조도는 다음과 같습니다.
그림과 같이 핫 데이터 영역과 콜드 데이터 영역이 다른 영역을 차지하면 innodb_old_blocks_pct 시작 옵션을 통해 innodb_old_blocks_pct启动选项来控制冷数据区域所占比例。
改进后的LRU如何更好的解决预读失效问题呢?
- 某个页在初次加载到缓冲池中时,先淘汰掉冷数据区域尾部的控制块(即其对应的页淘汰掉),然后新页对应的控制块会先放到冷数据区域的头部。
- 若后续该页不被进行访问就会慢慢从冷数据区域中被淘汰掉,总体不会影响热数据区域访问频繁的缓冲页。
改进后的LRU如何更好的解决缓冲池污染问题呢?
先说结论,并没有很好的优化这个问题,原因如下【以全表扫描为例】:
- 某个初次访问的页同样会放到冷数据区域的头部,但后续访问又会将其放到热数据区域的头部,这样同样会把访问频率较高的页给挤掉。
那么到底该如何解决缓冲池污染问题呢?
- 缓冲池引入了冷数据区域时间窗口机制,即只有后续访问该页与第一访问该页的时间间隔大于规定的窗口值,就会将该页从冷数据区域移到热数据区域的头部。小于规定的窗口值,就不会进行移动操作。
- 同样,窗口值可通过
innodb_old_blocks_time콜드 데이터 영역 의 비율을 제어할 수 있습니다.
향상된 LRU는 어떻게 미리 읽기 실패 문제를 더 잘 해결할 수 있을까요?
- 페이지가 버퍼 풀에 처음 로드되면 콜드 데이터 영역 끝에 있는 제어 블록이 먼저 제거되고(즉, 해당 페이지가 제거됨) 다음에 해당하는 제어 블록이 제거됩니다. 새 페이지는 먼저 콜드 데이터 영역에 배치됩니다.
- 이후 페이지에 액세스하지 않으면 콜드 데이터 영역에서 천천히 제거됩니다. 일반적으로 핫 데이터 영역에서 자주 액세스하는 버퍼 페이지에는 영향을 미치지 않습니다.
향상된 LRU는 어떻게 버퍼풀 오염 문제를 더 잘 해결할 수 있을까요?
먼저 결론부터 말씀드리자면 이 문제는 잘 최적화되지 않았습니다. 그 이유는 다음과 같습니다. [전체 테이블 스캔을 예로 들어]: 🎜🎜🎜처음 방문한 페이지도 선두에 배치됩니다. 콜드 데이터 영역에 속하지만 이후 방문은 핫 데이터 영역의 선두에 위치하게 되어 접근 빈도가 높은 페이지도 밀려나게 됩니다. 🎜🎜🎜그렇다면 완충풀 오염 문제를 어떻게 해결할 수 있을까요? 🎜🎜🎜버퍼 풀은 콜드 데이터 영역 시간 창 메커니즘을 도입합니다. 즉, 페이지에 대한 후속 액세스와 페이지에 대한 첫 번째 액세스 사이의 시간 간격이 지정된 창 값보다 크면 페이지가 이동됩니다. 콜드 데이터 영역에서 핫 데이터 영역으로. 창 값이 지정된 값보다 작으면 이동 작업이 수행되지 않습니다. 🎜🎜마찬가지로 창 값은innodb_old_blocks_time 매개변수 [단위 ms]를 통해 설정할 수 있으며, 기본값은 1000ms이고 1s는 전체 테이블 스캔과 같은 대부분의 작업을 필터링합니다. 예를 들어, 전체 테이블 스캔 중에 페이지에 대한 다중 액세스 사이의 시간 간격은 1초를 초과하지 않습니다. 🎜🎜🎜버퍼 풀 VS 쿼리 캐시🎜🎜🎜버퍼 풀과 쿼리 캐시는 동일한가요? →아니요 🎜🎜🎜🎜버퍼 풀은 자주 사용되는 데이터를 저장하려고 시도합니다. MySQL은 페이지를 읽을 때 먼저 페이지가 버퍼 풀에 있는지 확인하고 그렇지 않으면 직접 읽습니다. 존재하는 경우에는 페이지를 메모리나 디스크를 통해 버퍼 풀에 저장한 후 직접 읽습니다. 🎜🎜쿼리 캐시는 쿼리 결과를 미리 캐시해 두므로 다음에 실행하지 않고도 바로 결과를 얻을 수 있습니다. MySQL의 쿼리 캐시는 쿼리 계획이 아니라 해당 쿼리 결과를 캐시한다는 점에 유의해야 합니다. 적중 조건이 엄격하고 데이터 테이블이 변경되는 한 쿼리 캐시가 무효화되므로 적중률이 낮습니다. 🎜🎜🎜【관련 추천: 🎜mysql 비디오 튜토리얼🎜】🎜위 내용은 MySQL의 데이터베이스 버퍼 풀(Buffer Pool)에 대해 알아보세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7684
7684
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos에 MySQL을 설치하려면 다음 단계가 필요합니다. 적절한 MySQL Yum 소스 추가. mysql 서버를 설치하려면 yum install mysql-server 명령을 실행하십시오. mysql_secure_installation 명령을 사용하여 루트 사용자 비밀번호 설정과 같은 보안 설정을 작성하십시오. 필요에 따라 MySQL 구성 파일을 사용자 정의하십시오. MySQL 매개 변수를 조정하고 성능을 위해 데이터베이스를 최적화하십시오.
 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
