

Golang을 사용하여 Bing 배경화면을 크롤링하는 방법에 대한 자세한 설명


말할 필요도 없이 Python을 사용하여 크롤러를 만들면 요청 하나로 세상을 해결할 수 있습니다. 하지만 golang에 내장된 http 패키지가 매우 강력하다고 들었습니다. 별다른 작업을 하지 않아도 새로운 것을 배우고 관련 지식 포인트를 복습하고 싶을 뿐입니다. http 프로토콜의 요청과 응답. 더 이상 고민하지 말고 바로 본론으로 들어가겠습니다requests包走天下。但是呢,听说golang中内置的http包非常牛逼,咱就是说不得整点活,也刚好学习学习新东西,复习下http协议的请求和响应相关的知识点。话不多说,咱直接开整
本文章爬下必应壁纸先小试牛刀。狗头保命 狗头保命 狗头保命
爬虫流程概述
graph TD 请求数据 --> 解析数据 --> 数据入库
上图的流程图大家可以看到,其实爬虫并不麻烦,整个流程就只有三步而已。接下来具体聊聊每一步需要做什么
请求数据:在这里我们需要使用golang中的内置包http包向目标地址发起请求,这一步就完成了
解析数据:这里我们需要对请求到的数据进行解析,因为不是整个请求到的数据我们都需要,我们只需要某些具体的关键的数据而已。这一步也叫数据清洗
数据入库:不难理解,这就是将解析好的数据进行入库操作
实战分析
先到必应壁纸官网上观察,做爬虫的话是需要对数据特别敏感的。这是首页信息,整个页面是非常简洁的
接下来,需要调出浏览器的开发者工具(这个大家应该都非常熟悉吧,不熟悉的话很难跟下去的喔)。直接按下F12
크롤러 프로세스 개요이 기사를 아래로 내려가세요Bing Wallpaper
 이 기사를 아래로 내려가세요
이 기사를 아래로 내려가세요 먼저 사용해 보겠습니다. 개 머리가 생명을 구합니다. 개 머리가 생명을 구합니다. 개 머리가 생명을 구합니다.
먼저 사용해 보겠습니다. 개 머리가 생명을 구합니다. 개 머리가 생명을 구합니다. 개 머리가 생명을 구합니다.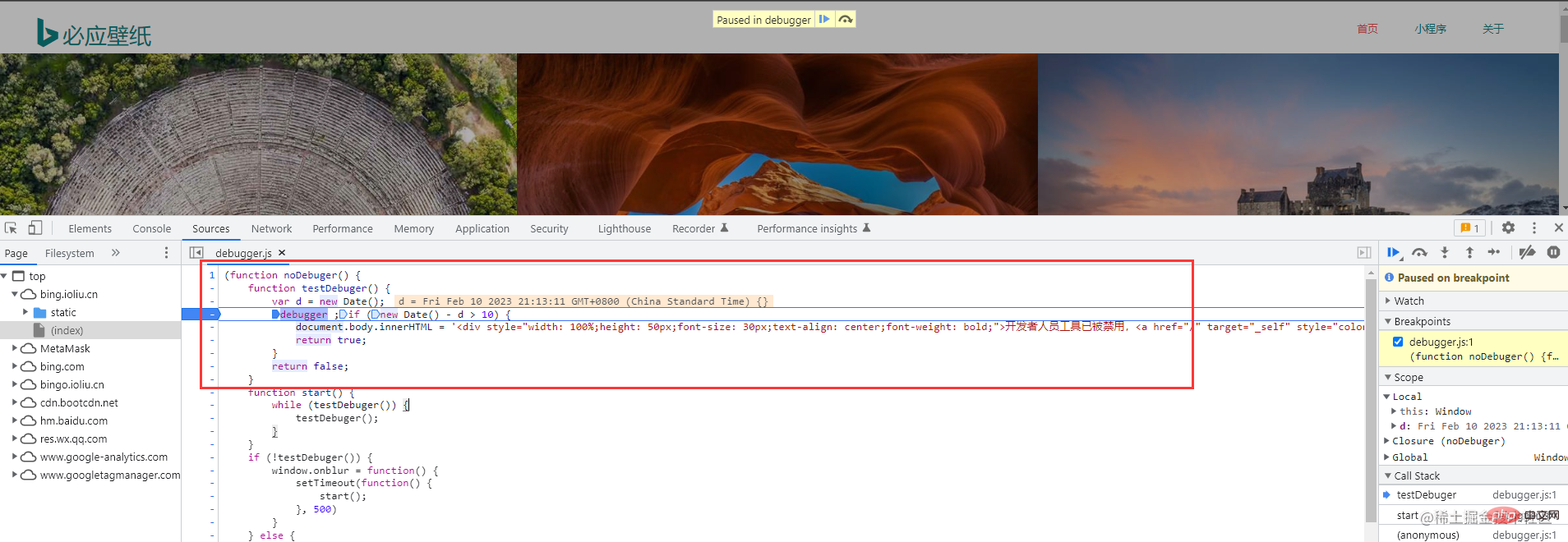
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}- 코드 연습
- 다음은 한 페이지를 크롤링하는 데이터입니다
- 다음은 여러 페이지를 크롤링하는 데이터입니다여러 페이지를 크롤링하는 코드는 크게 바뀌지 않았습니다. 먼저 웹사이트의 기능을 관찰해야 합니다
찾은 것이 있나요? 첫 번째 페이지 p=1, 두 번째 페이지 p=2, 열 번째 페이지 p=10
🎜그러므로 for 루프를 시작한 다음 이전에 단일 페이지를 크롤링했던 코드를 재사용합니다🎜rrreee🎜🎜요약🎜🎜🎜 이 예에서는 정규식을 사용하는 것이 너무 번거롭기 때문에 타사 도구 패키지를 사용하여 웹 페이지 데이터를 구문 분석합니다. 🎜🎜🎜css 선택기 사용: 🎜goQuery🎜🎜🎜xpath 선택기 사용: 🎜htmlquery🎜🎜 🎜regular : 내장 패키지, 권장하지 않음, 일반 규칙 작성이 어려움🎜🎜🎜추천 학습:🎜Golang 튜토리얼🎜🎜위 내용은 Golang을 사용하여 Bing 배경화면을 크롤링하는 방법에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
 데이터 요청: 여기서는 golang에 내장된 http 패키지를 사용하여 시작해야 합니다. 대상 주소에 대한 요청이 한 단계로 완료
데이터 요청: 여기서는 golang에 내장된 http 패키지를 사용하여 시작해야 합니다. 대상 주소에 대한 요청이 한 단계로 완료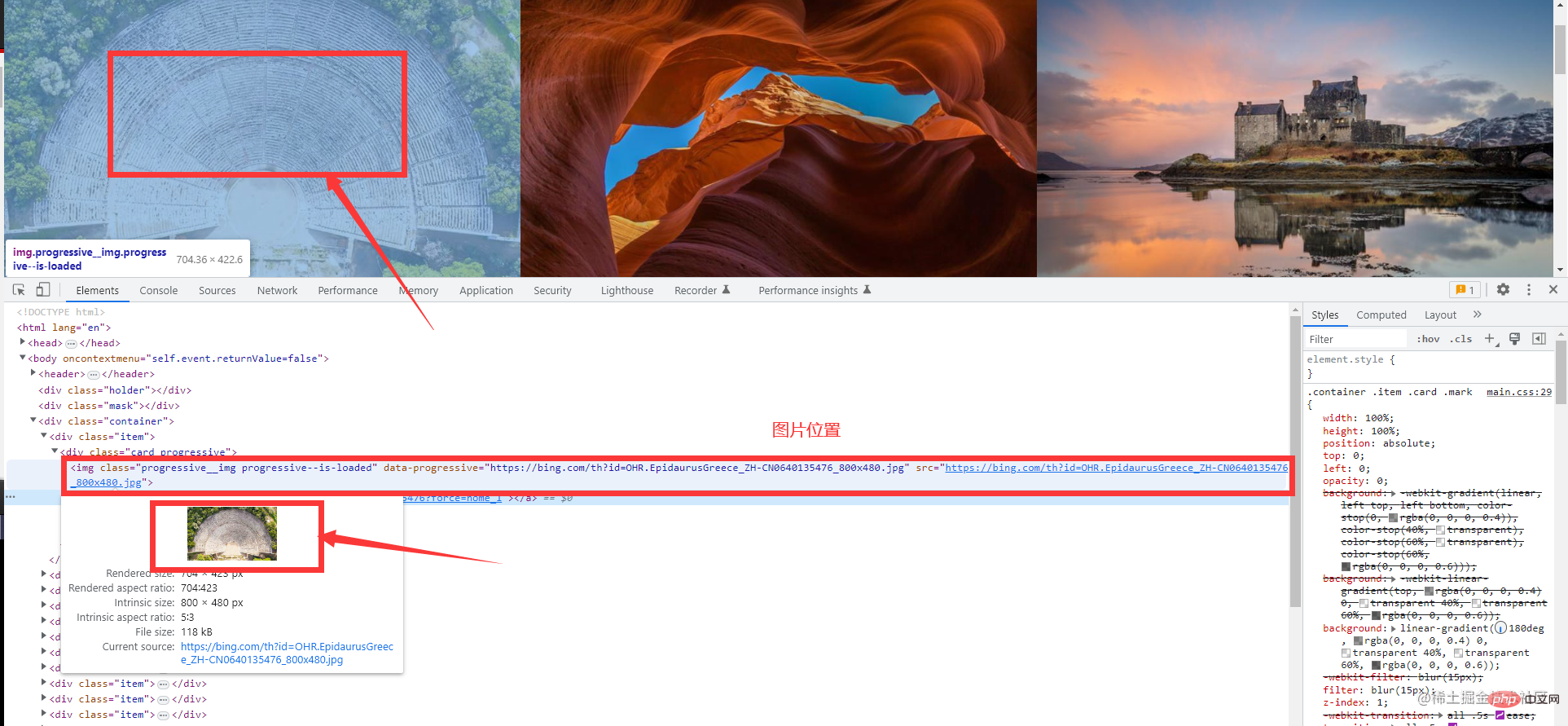
데이터 구문 분석: 요청한 데이터 전체가 필요하지 않고 특정 핵심 데이터만 필요하기 때문에 여기서는 요청된 데이터를 구문 분석해야 합니다. 이 단계는 데이터 정리라고도 합니다
데이터 저장: 이해하기 어렵지 않습니다. 이는 구문 분석된 데이터를 데이터베이스에 저장하는 것입니다
실용 분석
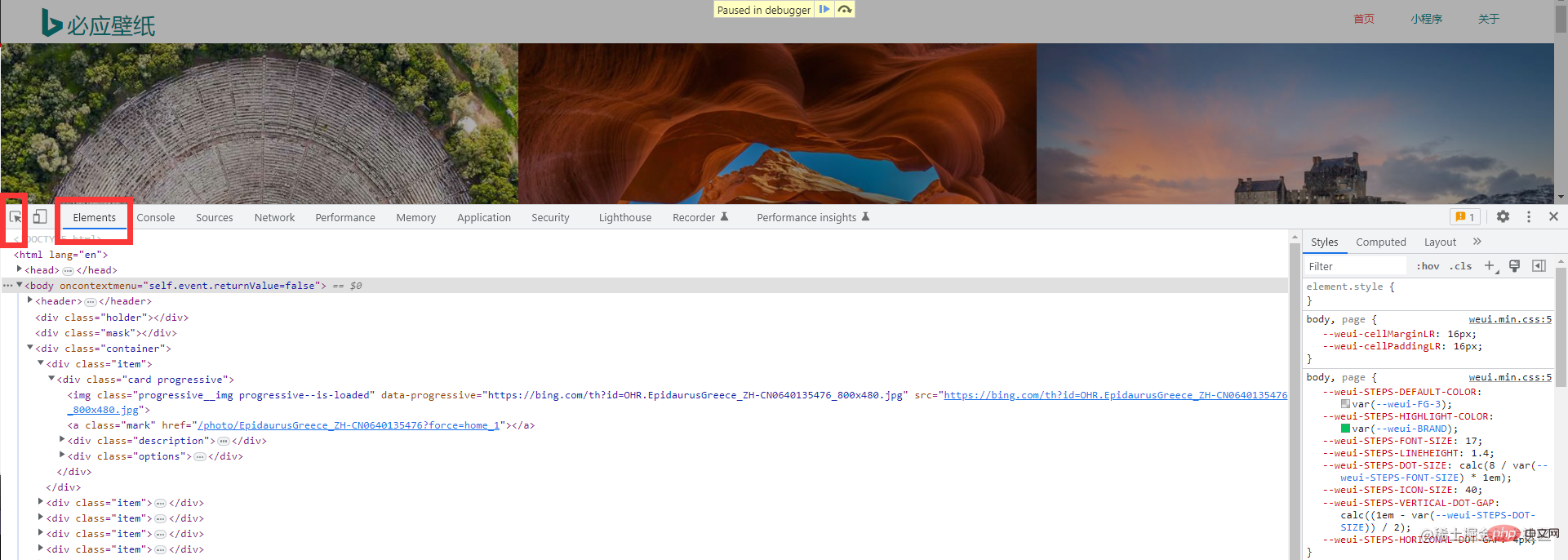
먼저 Bing Wallpaper 공식 웹사이트로 이동하여 관찰하고 크롤러를 수행합니다. 그렇다면 데이터에 특히 민감해야 합니다. 홈페이지 정보가 매우 간결합니다.
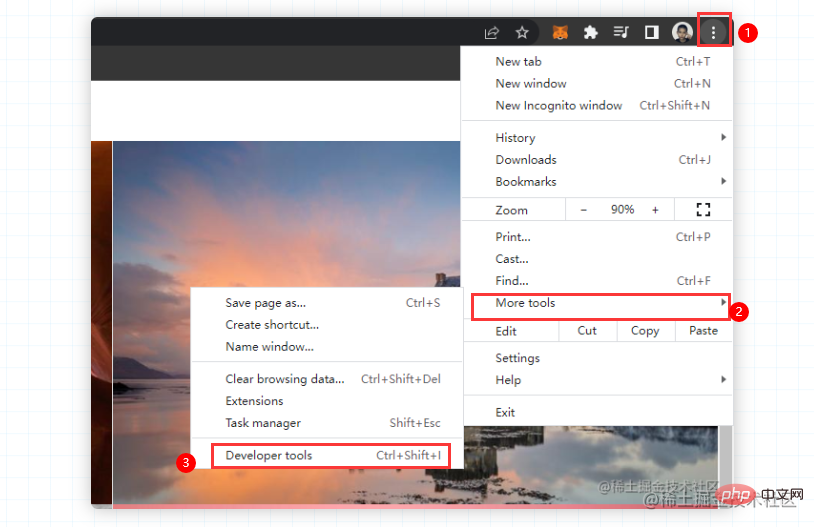
F12를 누르거나 마우스 오른쪽 버튼을 클릭하여 확인하세요. 하지만 어쩌죠? Bing 배경 화면에서는 마우스 오른쪽 버튼을 클릭해도 콘솔을 호출할 수 없으며 수동으로만 호출할 수 있습니다. 걱정하지 마시고 첫 번째 사진을 따라가시면 됩니다. 같은 반 친구의 크롬이 중국어로 되어 있으면 도구를 더 선택하고 개발자 도구를 선택하면 동일한 작업이 수행됩니다. 벽지 웹사이트의 크롤링 오류. (오래전에 크롤링할 때는 이러한 크롤링 방지 오류가 발생하지 않았습니다.) 이는 작업에 영향을 미치지 않습니다 다음으로, 원하는 요소를 빠르게 찾는 데 도움이 되는 이 도구를 선택하세요 그러면 필요한 것을 찾을 수 있습니다. 정보
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}
핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7723
7723
 15
1643
14
1396
52
1290
25
1233
29
15
1643
14
1396
52
1290
25
1233
29

 Golang을 사용하여 파일을 안전하게 읽고 쓰는 방법은 무엇입니까?
Jun 06, 2024 pm 05:14 PM
Golang을 사용하여 파일을 안전하게 읽고 쓰는 방법은 무엇입니까?
Jun 06, 2024 pm 05:14 PM
Go에서는 안전하게 파일을 읽고 쓰는 것이 중요합니다. 지침은 다음과 같습니다. 파일 권한 확인 지연을 사용하여 파일 닫기 파일 경로 유효성 검사 컨텍스트 시간 초과 사용 다음 지침을 따르면 데이터 보안과 애플리케이션의 견고성이 보장됩니다.
 Golang 데이터베이스 연결을 위한 연결 풀을 구성하는 방법은 무엇입니까?
Jun 06, 2024 am 11:21 AM
Golang 데이터베이스 연결을 위한 연결 풀을 구성하는 방법은 무엇입니까?
Jun 06, 2024 am 11:21 AM
Go 데이터베이스 연결을 위한 연결 풀링을 구성하는 방법은 무엇입니까? 데이터베이스 연결을 생성하려면 데이터베이스/sql 패키지의 DB 유형을 사용하고, 최대 동시 연결 수를 제어하려면 MaxIdleConns를 설정하고, 연결의 최대 수명 주기를 제어하려면 ConnMaxLifetime을 설정하세요.
 JSON 데이터를 Golang의 데이터베이스에 저장하는 방법은 무엇입니까?
Jun 06, 2024 am 11:24 AM
JSON 데이터를 Golang의 데이터베이스에 저장하는 방법은 무엇입니까?
Jun 06, 2024 am 11:24 AM
JSON 데이터는 gjson 라이브러리 또는 json.Unmarshal 함수를 사용하여 MySQL 데이터베이스에 저장할 수 있습니다. gjson 라이브러리는 JSON 필드를 구문 분석하는 편리한 방법을 제공하며, json.Unmarshal 함수에는 JSON 데이터를 비정렬화하기 위한 대상 유형 포인터가 필요합니다. 두 방법 모두 SQL 문을 준비하고 삽입 작업을 수행하여 데이터를 데이터베이스에 유지해야 합니다.
 Golang 프레임워크 vs. Go 프레임워크: 내부 아키텍처와 외부 기능 비교
Jun 06, 2024 pm 12:37 PM
Golang 프레임워크 vs. Go 프레임워크: 내부 아키텍처와 외부 기능 비교
Jun 06, 2024 pm 12:37 PM
GoLang 프레임워크와 Go 프레임워크의 차이점은 내부 아키텍처와 외부 기능에 반영됩니다. GoLang 프레임워크는 Go 표준 라이브러리를 기반으로 하며 기능을 확장하는 반면, Go 프레임워크는 특정 목적을 달성하기 위해 독립적인 라이브러리로 구성됩니다. GoLang 프레임워크는 더 유연하고 Go 프레임워크는 사용하기 더 쉽습니다. GoLang 프레임워크는 성능 면에서 약간의 이점이 있고 Go 프레임워크는 확장성이 더 좋습니다. 사례: gin-gonic(Go 프레임워크)은 REST API를 구축하는 데 사용되고 Echo(GoLang 프레임워크)는 웹 애플리케이션을 구축하는 데 사용됩니다.
 프론트 엔드에서 백엔드 개발로 전환하면 Java 또는 Golang을 배우는 것이 더 유망합니까?
Apr 02, 2025 am 09:12 AM
프론트 엔드에서 백엔드 개발로 전환하면 Java 또는 Golang을 배우는 것이 더 유망합니까?
Apr 02, 2025 am 09:12 AM
백엔드 학습 경로 : 프론트 엔드에서 백엔드 초보자로서 프론트 엔드에서 백엔드까지의 탐사 여행은 프론트 엔드 개발에서 변화하는 백엔드 초보자로서 이미 Nodejs의 기초를 가지고 있습니다.
 Golang 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾는 방법은 무엇입니까?
Jun 06, 2024 am 10:51 AM
Golang 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾는 방법은 무엇입니까?
Jun 06, 2024 am 10:51 AM
FindStringSubmatch 함수는 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾습니다. 이 함수는 일치하는 하위 문자열이 포함된 조각을 반환합니다. 첫 번째 요소는 전체 일치 문자열이고 후속 요소는 개별 하위 문자열입니다. 코드 예: regexp.FindStringSubmatch(text,pattern)는 일치하는 하위 문자열의 조각을 반환합니다. 실제 사례: 이메일 주소의 도메인 이름을 일치시키는 데 사용할 수 있습니다. 예를 들어 이메일:="user@example.com", 패턴:=@([^\s]+)$를 사용하여 도메인 이름 일치를 가져옵니다. [1].
 Golang 프레임워크 개발 실습 튜토리얼: FAQ
Jun 06, 2024 am 11:02 AM
Golang 프레임워크 개발 실습 튜토리얼: FAQ
Jun 06, 2024 am 11:02 AM
Go 프레임워크 개발 FAQ: 프레임워크 선택: Gin(API), Echo(확장 가능), Beego(ORM), Iris(성능) 등 애플리케이션 요구 사항 및 개발자 선호도에 따라 다릅니다. 설치 및 사용: gomod 명령을 사용하여 프레임워크를 설치하고 가져와서 사용합니다. 데이터베이스 상호 작용: gorm과 같은 ORM 라이브러리를 사용하여 데이터베이스 연결 및 작업을 설정합니다. 인증 및 권한 부여: gin-contrib/sessions와 같은 세션 관리 및 인증 미들웨어를 사용합니다. 실제 사례: Gin 프레임워크를 사용하여 POST, GET 및 기타 기능을 제공하는 간단한 블로그 API를 구축합니다.
 Golang에서 미리 정의된 시간대를 사용하는 방법은 무엇입니까?
Jun 06, 2024 pm 01:02 PM
Golang에서 미리 정의된 시간대를 사용하는 방법은 무엇입니까?
Jun 06, 2024 pm 01:02 PM
Go에서 미리 정의된 시간대를 사용하는 단계는 다음과 같습니다. "time" 패키지를 가져옵니다. LoadLocation 함수를 통해 특정 시간대를 로드합니다. Time 객체 생성, 시간 문자열 구문 분석, 날짜 및 시간 변환 수행 등의 작업에 로드된 시간대를 사용합니다. 미리 정의된 시간대 기능의 적용을 설명하기 위해 다양한 시간대를 사용하여 날짜를 비교합니다.
