

리눅스에서 디스크는 블록 저장 장치인 "디스크"를 의미합니다. 즉, 파일을 저장하는 데 사용되는 장치입니다. 파일 시스템은 실제로 디스크 공간을 매핑한 것입니다. 너무 큰 공간에 데이터를 저장하거나 읽어오는 것을 방지하여 접근 효율성을 낮추거나, 데이터를 카테고리별로 저장하고 관리하기 위해서는 디스크 공간을 여러 영역으로 나누어야 하는데, 이를 디스크 파티션이라고 합니다.

이 튜토리얼의 운영 환경: linux7.3 시스템, Dell G3 컴퓨터.
디스크(디스크)는 파일을 저장하는 데 사용되는 블록 저장 장치입니다. 파일 시스템은 실제로 디스크 공간의 매핑입니다.
Linux 시스템에서는 파일 시스템이 하드 디스크에 생성됩니다. 따라서 파일 시스템의 관리 메커니즘을 완전히 이해하려면 하드 디스크에 대한 이해부터 시작해야 합니다. . 하드 드라이브는 기계식 하드 드라이브(Hard Disk Drive, HDD)와 솔리드 스테이트 드라이브(Solid State Disk, SSD)로 나눌 수 있으며, 기계식 하드 드라이브는 자기 플래터를 사용하여 데이터를 저장하는 반면, 솔리드 스테이트 드라이브는 플래시 메모리 입자를 사용하여 데이터를 저장합니다.

ulouscred 기계식 하드 디스크는 디스크, 트랙, 섹터, 실린더와 변속기 샤프트로 구성됩니다.
디스크: 디스크에는 일반적으로 하나 이상의 플래터가 있습니다. 각 디스크에는 두 개의 측면이 있을 수 있습니다. 즉, 첫 번째 디스크의 앞면은 측면 0이고 뒷면은 측면 1입니다. 두 번째 디스크의 앞면은 측면 2입니다. 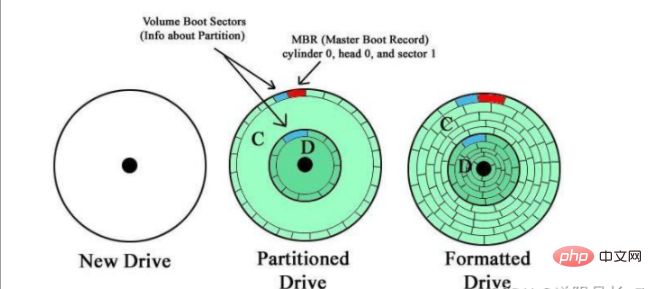
하드 디스크에서 데이터를 읽고 쓰는 과정
최신 하드 디스크는 CHS(실린더 헤드 섹터) 방식을 사용하여 검색합니다. 하드 디스크가 데이터를 읽을 때 읽기 및 쓰기 헤드가 해당 섹터로 방사형으로 이동합니다. 트랙 위에서는 이 기간을 탐색 시간이라고 합니다. 읽기 및 쓰기 헤드의 시작 위치와 목표 위치 사이의 거리가 다르기 때문에 탐색 시간도 다릅니다. 현재 하드 드라이브는 일반적으로 2~30밀리초가 소요되며 평균 약 9밀리초가 소요됩니다. 자기 헤드가 지정된 트랙에 도달한 후 디스크 회전을 통해 읽을 섹터가 읽기 및 쓰기 헤드 아래로 이동하는 시간을 7200(분당 회전 수) 하드 디스크라고 합니다. 각 회전에 필요한 시간은 60×1000¼7200=8.33밀리초이며, 평균 회전 지연 시간은 8.33¼2=4.17밀리초(평균적으로 반 바퀴 필요)입니다. 평균 탐색 시간과 평균 선택적 지연을 평균 액세스 시간이라고 합니다. 솔리드 스테이트 드라이브(SSD)현재 일반적인 기계식 하드 드라이브 인터페이스에는 다음 유형이 포함됩니다.
IDE 하드 디스크 인터페이스: "ATA 하드 디스크" 또는 "PATA 하드 디스크"라고도 알려진 (통합 드라이브 전자, 병렬 포트, 전자 통합 드라이브)는 초기 기계식 하드 디스크의 주요 인터페이스입니다. ATA133 하드의 이론적인 속도. 디스크는 133MB/s에 도달할 수 있습니다(이 속도는 이론상의 평균입니다). 병렬 포트 케이블의 간섭 방지 성능이 너무 낮고 케이블이 큰 공간을 차지하여 내부 열 방출에 도움이 되지 않기 때문입니다. 컴퓨터는 점차적으로 SATA로 대체되었습니다.
SATA 인터페이스: 전체 이름은 직렬 ATA이며 직렬 포트를 사용하는 ATA 인터페이스입니다. 이는 강력한 간섭 방지가 특징이며 ATA보다 데이터 라인에 대한 요구 사항이 훨씬 낮으며 핫 스왑 가능 및 기타 지원합니다. 기능. SATA-II의 인터페이스 속도는 300MiB/s인 반면, 새로운 SATA-III 표준은 600MiB/s의 전송 속도에 도달할 수 있습니다. 또한 SATA 데이터 케이블은 ATA 케이블보다 훨씬 얇아서 섀시 내부의 공기 순환에 도움이 되고 케이블 정리도 더 쉽습니다.
SCSI 인터페이스: 전체 이름은 Small Computer System Interface(소형 컴퓨터 시스템 인터페이스)입니다. 초기 SCSI-II부터 현재의 Ultra320 SCSI 및 Fiber-Channel(파이버 채널)에 이르기까지 여러 세대의 개발을 경험해 왔습니다. 또한 다양한 인터페이스 유형. SCSI 하드 드라이브는 워크스테이션 수준의 개인용 컴퓨터 및 서버에 널리 사용되므로 15,000rpm의 높은 디스크 속도와 같은 고급 기술을 사용하며 데이터 전송 시 CPU 사용량이 더 낮습니다. 동일한 용량의 ATA 및 SATA보다 가격이 더 비쌉니다.
SAS 인터페이스: 전체 이름은 Serial Attached SCSI입니다. 이는 SATA 하드 드라이브와 호환되는 차세대 SCSI 기술로, 모두 직렬 기술을 사용하여 12Gb/s에 도달할 수 있습니다. 또한 연결 케이블을 줄여 시스템 내부 공간을 확보했다.
FC 인터페이스: 전체 이름은 Fibre Channel(파이버 채널 인터페이스)입니다. 이 인터페이스를 갖춘 하드 드라이브는 다음과 같은 경우 핫스왑 가능성, 고속 대역폭(4Gb/s 또는 10Gb/s), 원격 연결 등의 특성을 갖습니다. 광섬유 연결을 사용하여 내부 전송 속도도 일반 하드 드라이브보다 높습니다. 하지만 가격이 비싸기 때문에 FC 인터페이스는 대개 고급 서버 분야에서만 사용됩니다
이제 대부분의 일반적인 기계식 디스크 인터페이스는 SATA이고 대부분의 SSD 인터페이스는 SAS
파일 시스템은 저장 장치(일반적으로 디스크이지만 NAND 플래시 기반 SSD) 또는 파티션의 파일을 식별하기 위해 운영 체제에서 사용하는 방법 및 데이터 구조입니다. 즉, 저장 장치에 있는 파일을 정리하는 방법입니다. 운영 체제에서 파일 정보를 관리하고 저장하는 소프트웨어 조직을 파일 관리 시스템, 줄여서 파일 시스템이라고 합니다. 파일 시스템에 대한 인터페이스, 객체 조작 및 관리, 객체 및 속성을 위한 소프트웨어 모음입니다. 시스템 관점에서 볼 때, 파일 시스템은 파일 저장 장치의 공간을 구성 및 할당하고, 파일 저장을 담당하며, 저장된 파일을 보호하고 검색하는 시스템이다. 특히 사용자를 위한 파일 생성, 파일 저장, 읽기, 수정 및 덤프, 파일 액세스 제어, 사용자가 더 이상 파일을 사용하지 않을 때 파일 취소 등을 담당합니다. 파일 시스템은 소프트웨어 시스템의 일부로, 응용 프로그램이 추상 명명된 데이터 개체와 가변 크기 공간을 편리하게 사용할 수 있도록 해줍니다. 파일의 저장 공간을 관리 및 예약하고, 파일의 논리적 구조, 물리적 구조 및 저장 방법을 제공하고, 식별에서 실제 주소로의 파일 매핑을 실현하고, 파일의 제어 작업 및 액세스 작업을 실현하고, 파일 정보 공유를 실현합니다. 신뢰할 수 있는 파일 제공 기밀성 및 보호 조치 문서에 대한 보안 조치를 제공합니다.
FAT:
Win 9X에서 FAT16이 지원하는 최대 파티션은 2GB입니다. 우리는 컴퓨터가 하드 디스크의 "클러스터"라는 영역에 정보를 저장한다는 것을 알고 있습니다. 사용되는 클러스터가 작을수록 정보를 더 효율적으로 저장할 수 있습니다. FAT16의 경우 파티션이 커질수록 클러스터도 커지며, 저장 효율도 떨어지기 때문에 필연적으로 저장 공간의 낭비가 발생하게 됩니다. 그리고 컴퓨터 하드웨어와 응용 프로그램이 지속적으로 개선되면서 FAT16 파일 시스템은 더 이상 시스템 요구 사항에 잘 적응할 수 없습니다. 이 경우 향상된 파일 시스템 FAT32가 도입되었습니다.
NTFS:
NTFS 파일 시스템은 보안 기반 파일 시스템으로 Windows NT에서 채택한 고유한 파일 시스템 구조로, 파일 및 디렉터리 데이터를 보호하는 동시에 스토리지 리소스를 절약하고 디스크 공간을 줄입니다. 고급 파일 시스템. 널리 사용되는 Windows NT 4.0은 NTFS 4.0 파일 시스템을 사용하며, 이것이 제공하는 강력한 시스템 보안은 대다수의 사용자에게 깊은 인상을 남겼을 것입니다. Win 2000은 NTFS 파일 시스템 NTFS 5.0의 업데이트 버전을 사용합니다. 이를 통해 사용자는 Win 9X만큼 편리하고 빠르게 컴퓨터를 작동하고 관리할 수 있을 뿐만 아니라 NTFS가 제공하는 시스템 보안을 누릴 수 있습니다.
exFAT:
전체 이름은 Extended File Allocation Table File System, 확장된 파일 할당 테이블인 확장 FAT는 Microsoft가 Windows Embeded 5.0 이상(Windows CE 5.0, 6.0, Windows 포함)에 도입한 시스템입니다. Mobile5, 6, 6.1) FAT32 및 4G 이상 대용량 파일을 지원하지 않는 기타 파일의 문제를 해결하기 위해 도입된 플래시 메모리에 적합한 파일 시스템입니다.
RAW:
RAW 파일 시스템은 처리되지 않거나 포맷되지 않은 디스크에 의해 생성된 파일 시스템입니다. 일반적으로 일반 파일 시스템이 RAW 파일 시스템이 되는 원인은 다음과 같습니다. 포맷하지 않음, 포맷 중 작업 취소 , 하드 디스크의 불량 섹터, 하드 디스크의 예측할 수 없는 오류 또는 바이러스. RAW 파일 시스템의 문제를 해결하는 가장 빠른 방법은 즉시 포맷하고 바이러스 백신 소프트웨어를 사용하여 완전히 치료하는 것입니다.
Ext:
Ext2: Ext는 GNU/Linux 시스템의 표준 파일 시스템입니다. 파일 액세스 성능이 매우 뛰어난 것이 특징입니다. 이는 주로 클러스터 캐시 레이어의 뛰어난 디자인 덕분에 중소 규모 파일에 더 많은 이점을 제공합니다.
Ext3: ext2 시스템의 확장인 저널링 파일 시스템이며 ext2와 호환됩니다. 저널 파일 시스템의 장점은 파일 시스템에 작업과 관련된 캐시 계층이 있기 때문에 캐시 계층의 데이터를 디스크에 다시 쓸 수 있도록 사용하지 않을 때 파일 시스템을 마운트 해제해야 한다는 것입니다. 따라서 시스템을 종료하려고 할 때마다 종료하기 전에 모든 파일 시스템을 종료해야 합니다. Ext4: Linux 커널은 2.6.28부터 새로운 파일 시스템 Ext4를 공식적으로 지원했습니다. Ext4는 Ext3의 향상된 버전으로, Ext3와 같은 로깅 기능을 Ext2에 추가하는 것뿐만 아니라 Ext3의 일부 중요한 데이터 구조를 수정합니다. Ext4는 더 나은 성능과 안정성은 물론 더 풍부한 기능을 제공할 수 있습니다.
XFS:
고성능 로그 파일 시스템이자 RHEL 7의 기본 파일 관리 시스템입니다. 예상치 못한 다운타임 이후에 특히 장점이 뚜렷합니다. 즉, 손상되었을 수 있는 파일을 빠르게 복원할 수 있다는 것입니다. . 파일이며 강력한 로깅 기능에는 매우 낮은 컴퓨팅 및 저장 성능만 필요합니다. 그리고 최대 지원 저장 용량은 18EB로 거의 모든 요구 사항을 충족합니다.HFS: HFS(Hierarchical File System)는 Apple Computer에서 개발하고 Mac OS에서 사용되는 파일 시스템입니다. 원래 플로피 디스크 및 하드 디스크와 함께 사용하도록 설계되었지만 CD-ROM과 같은 읽기 전용 미디어에서도 찾을 수 있습니다.
데이터 스트라이핑은 여러 개의 서로 다른 디스크에 데이터 조각을 저장합니다. 여러 개의 데이터 조각이 함께 전체 데이터 복사본을 형성하며 이는 일반적으로 성능을 고려하여 사용됩니다. 데이터 스트라이핑은 더 높은 동시성 세분성을 가지며, 데이터에 액세스할 때 서로 다른 디스크에 있는 데이터를 동시에 읽고 쓸 수 있으므로 I/O 성능이 크게 향상됩니다.
데이터 검증은 데이터 오류를 감지하고 복구하기 위해 중복 데이터를 사용합니다. 중복 데이터는 일반적으로 해밍 코드 및 XOR 연산과 같은 알고리즘을 사용하여 계산됩니다. 검증 기능을 사용하면 디스크 어레이의 신뢰성, 견고성 및 내결함성을 크게 향상시킬 수 있습니다. 그러나 데이터 검증에는 여러 위치에서 데이터를 읽고 계산 및 비교를 수행해야 하며 이는 시스템 성능에 영향을 미칩니다.
다양한 수준의 RAID는 세 가지 기술 중 하나 이상을 사용하여 다양한 데이터 안정성, 가용성 및 I/O 성능을 얻습니다. 어떤 종류의 RAID를 설계할지(또는 새로운 레벨이나 유형), 어떤 RAID 모드를 사용할지는 시스템 요구 사항에 대한 심층적인 이해를 바탕으로 합리적인 선택과 절충이 필요합니다. 신뢰성, 성능, 비용 등을 종합적으로 평가하여 선택하세요.
RAID의 고성능은 데이터 스트라이핑 기술의 이점을 활용합니다. 단일 디스크의 I/O 성능은 인터페이스 및 대역폭과 같은 컴퓨터 기술에 의해 제한되는 경우가 많으며 시스템 성능에 쉽게 병목 현상이 발생할 수 있습니다. 데이터 스트라이핑을 통해 RAID는 데이터 I/O를 구성원 디스크 전체에 분산시켜 단일 디스크보다 기하급수적으로 향상된 총 I/O 성능을 제공합니다.
(3) 신뢰성
가용성과 신뢰성은 RAID의 또 다른 중요한 기능입니다. 이론적으로 여러 디스크로 구성된 RAID 시스템은 단일 디스크보다 안정성이 떨어집니다. 여기에는 암묵적인 가정이 있습니다. 단일 디스크 오류로 인해 전체 RAID를 사용할 수 없게 됩니다. RAID는 미러링 및 데이터 패리티와 같은 데이터 중복 기술을 사용하여 이러한 가정을 깨뜨립니다. 미러링은 가장 원시적인 중복 기술로, 특정 디스크 드라이브 세트의 데이터를 다른 디스크 드라이브 세트로 완전히 복사하여 데이터 복사본을 항상 사용할 수 있도록 합니다. 미러링의 50% 중복 오버헤드에 비해 데이터 검증은 검증 중복 정보를 사용하여 데이터를 검증하고 수정합니다. RAID 중복 기술은 데이터 가용성과 신뢰성을 크게 향상시켜 여러 디스크 오류가 발생하더라도 데이터가 손실되지 않고 시스템의 지속적인 작동이 영향을 받지 않도록 보장합니다.
(4) 관리 효율성
사실 RAID는 여러 개의 물리적 디스크 드라이브를 대용량 논리 드라이브로 가상화하는 가상화 기술입니다. RAID는 외부 호스트 시스템을 위한 빠르고 안정적인 단일 대용량 디스크 드라이브입니다. 이러한 방식으로 사용자는 이 가상 드라이브에 애플리케이션 시스템 데이터를 구성하고 저장할 수 있습니다. 사용자 애플리케이션 관점에서 볼 때 스토리지 시스템을 간단하고 사용하기 쉽게 만들 수 있으며 관리도 매우 편리합니다. RAID는 내부적으로 많은 스토리지 관리 작업을 수행하므로 관리자는 단일 가상 드라이브만 관리하면 되므로 관리 작업이 많이 줄어듭니다. RAID는 디스크 드라이브를 동적으로 추가하거나 제거할 수 있으며 데이터 확인 및 데이터 재구성을 자동으로 수행할 수 있어 관리 작업을 크게 단순화할 수 있습니다.
RAID0
RAID1
RAID3
RAID5
RAID6
RAID10


포맷은 다음과 같습니다. 저장할 데이터를 준비하기 위해 데이터 저장 장치를 초기화하는 프로세스, 즉 파티션에 새로운 파일 시스템을 생성하는 프로세스입니다. 각 파티션은 데이터를 저장하기 전에 일종의 파일 시스템으로 포맷되어야 합니다.

Linux 비디오 튜토리얼"
위 내용은 리눅스 디스크가 뭐야?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!









![[초보자를 위한 입문서, 이해하기 쉽다] 일주일 만에 리눅스 배우기](https://img.php.cn/upload/course/000/000/068/6242a86a890b1568.png)


![Linux 운영 및 유지보수 기본과정 [전체 과정에 대한 자세한 설명]](https://img.php.cn/upload/course/000/000/068/63ff173c79edd672.jpg)






![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



