

Microsoft는 원스톱으로 고성능 경량 모델을 얻기 위해 자동화된 신경망 훈련 가지치기 프레임워크 OTO를 제안합니다.

OTO는 업계 최초의 자동화된 원스톱 사용자 친화적 다용도 신경망 훈련 및 구조 압축 프레임워크입니다.
인공지능 시대에는 신경망을 어떻게 배치하고 유지 관리할지가 제품화의 핵심 문제입니다. 모델 성능 손실을 최소화하면서 컴퓨팅 비용을 절감한다는 점을 고려하면 신경망 압축은 DNN 제품화의 핵심 중 하나가 되었습니다.

DNN 압축에는 일반적으로 가지치기, 지식 증류, 양자화의 세 가지 방법이 있습니다. 프루닝은 중복된 구조를 식별하여 제거하고 모델 성능을 최대한 유지하면서 DNN을 줄이는 것을 목표로 합니다. 이는 가장 다양하고 효과적인 압축 방법입니다. 일반적으로 세 가지 방법은 서로를 보완하고 함께 작동하여 최상의 압축 효과를 얻을 수 있습니다.

기존 가지치기 방법의 대부분은 특정 모델과 특정 작업만을 대상으로 하며 강력한 전문 도메인 지식이 필요하므로 일반적으로 AI 개발자는 이러한 방법을 자신의 시나리오에 적용하기 위해 많은 노력을 기울여야 합니다. 인적, 물적 비용이 많이 소모됩니다.
OTO 개요
기존 가지치기 방법의 문제점을 해결하고 AI 개발자에게 편의성을 제공하기 위해 Microsoft 팀에서는 Only-Train-Once OTO 프레임워크를 제안했습니다. OTO는 업계 최초의 자동화된 원스톱 사용자 친화적 범용 신경망 훈련 및 구조 압축 프레임워크입니다. 일련의 작업이 ICLR2023 및 NeurIPS2021에 게시되었습니다.
OTO를 사용하면 AI 엔지니어는 대상 신경망을 쉽게 훈련하고 원스톱으로 고성능 경량 모델을 얻을 수 있습니다. OTO는 엔지니어링 시간과 노력에 대한 개발자의 투자를 최소화하고, 기존 방법에서 일반적으로 요구되는 시간이 많이 소요되는 사전 교육 및 추가 모델 미세 조정이 필요하지 않습니다.
- Paper 링크 : :Otov2 ICLR 2023 : https://openreview.net/pdf?id=7ynox1ojpmt
- otov1 Neurips 2021 : https://proceedings.neurips.cc/paper_files/2021/file/a376033f78e144f499 4bfc743c0be3330 -Paper.pdf
- 코드 링크: https://github.com/tianyic/only_train_once
이상적인 구조 가지치기 알고리즘은 다음과 같아야 합니다: 일반 신경망용, 자동화된 원스톱 쉽게 훈련 이후의 미세 조정이 필요 없이 처음부터 고성능 경량 모델을 달성합니다. 그러나 신경망의 복잡성으로 인해 이 목표를 달성하는 것은 매우 어렵습니다. 이 궁극적인 목표를 달성하려면 다음 세 가지 핵심 질문을 체계적으로 해결해야 합니다.
제거할 수 있는 네트워크 구조를 찾는 방법은 무엇입니까?- 모델 성능을 최대한 잃지 않으면서 네트워크 구조를 제거하는 방법은 무엇입니까?
- 위의 두 가지 사항을 어떻게 자동으로 달성할 수 있나요?
- Microsoft 팀은 세 가지 핵심 알고리즘 세트를 설계하고 구현하여 이 세 가지 핵심 문제를 체계적이고 종합적으로 해결했습니다.
네트워크 구조의 복잡성과 상관 관계로 인해 네트워크 구조를 삭제하면 나머지 네트워크 구조가 유효하지 않게 될 수 있습니다. 따라서 자동화된 네트워크 구조 압축의 가장 큰 문제 중 하나는 나머지 네트워크가 여전히 유효하도록 함께 정리해야 하는 모델 매개변수를 찾는 방법입니다. 이 문제를 해결하기 위해 Microsoft 팀은 OTOv1에서 ZIG(Zero-Invariant Group)를 제안했습니다. 영불변 그룹은 제거 가능한 가장 작은 단위의 유형으로 이해될 수 있으므로 그룹의 해당 네트워크 구조가 제거된 후에도 나머지 네트워크는 여전히 유효합니다. 영불변 그룹의 또 다른 큰 특성은 영불변 그룹이 0과 같으면 입력 값이 무엇이든 출력 값은 항상 0이라는 것입니다. OTOv2에서 연구원들은 일반 네트워크에서 제로 불변 그룹의 그룹화 문제를 해결하기 위해 일련의 자동화된 알고리즘을 제안하고 구현했습니다. 자동화된 그룹화 알고리즘은 일련의 그래프 알고리즘을 신중하게 조합한 것입니다. 전체 알고리즘은 매우 효율적이며 선형적인 시간 및 공간 복잡성을 갖습니다.

대상 네트워크의 모든 영불변 그룹을 나눈 후 다음 모델 훈련 및 가지치기 작업에서는 어떤 영불변 그룹이 중복되는지 알아내야 합니다. . 나머지는 중요한 것입니다. 압축 모델의 성능을 보장하려면 중복된 제로 불변 그룹에 해당하는 네트워크 구조를 삭제하고 중요한 제로 불변 그룹을 유지해야 합니다. 연구진은 이 문제를 구조적 희소화 문제로 공식화하고, 이를 해결하기 위한 새로운 DHSPG(Dual Half-Space Projected Gradient) 최적화 알고리즘을 제안했습니다.

DHSPG는 중복된 제로 불변 그룹을 매우 효과적으로 찾아 이를 0으로 투영할 수 있으며, 중요한 제로 불변 그룹을 지속적으로 훈련하여 원래 모델과 비슷한 성능을 달성할 수 있습니다.
기존 희소 최적화 알고리즘과 비교하여 DHSPG는 더 강력하고 안정적인 희소 구조 탐색 기능을 갖추고 훈련 검색 공간을 확장하므로 일반적으로 더 높은 실제 성능 결과를 달성합니다.

경량 압축 모델을 자동으로 구축
DHSPG를 사용하여 모델을 학습하면 영불변 그룹의 높은 구조적 희소성을 준수하는 솔루션을 얻을 수 있습니다. 즉, 솔루션에 많은 것이 있습니다. 이는 0의 0 불변 그룹으로 투영되며 이 솔루션은 또한 높은 모델 성능을 갖습니다. 다음으로, 연구진은 중복된 제로 불변 그룹에 해당하는 모든 구조를 삭제하여 자동으로 압축 네트워크를 구축했습니다. 영불변 그룹의 특성으로 인해, 즉 영불변 그룹이 0이면 입력 값이 무엇이든 출력 값은 항상 0이 되므로 중복된 영불변 그룹을 삭제하면 네트워크에 영향을 미칠 수 있습니다. 따라서 OTO를 통해 얻은 압축 네트워크는 기존 방법에서 요구되는 추가 모델 미세 조정이 필요 없이 전체 네트워크와 동일한 출력을 갖게 됩니다.
수많은 실험 CIFAR10의 VGG16 및 VGG16-BN 모델과 CIFAR10의 VGG16-BN 모델에서 볼륨이 97.5% 감소했으며 성능이 인상적이었습니다.
 표 2: CIFAR10에 대한 ResNet50 실험
표 2: CIFAR10에 대한 ResNet50 실험
CIFAR10에 대한 ResNet50 실험에서 OTO는 단 7.8%의 FLOP와 4.1%의 매개변수를 사용하여 양자화 없이 SOTA 신경망 압축 프레임워크 AMC 및 ANNC보다 성능이 뛰어났습니다.
 표 3. ImageNet의 ResNet50 실험
표 3. ImageNet의 ResNet50 실험
ImageNet의 ResNet50 실험에서 OTOv2는 다양한 구조적 희소화 목표 하에서 기존 SOTA 방법과 비슷하거나 훨씬 더 나은 성능을 보여주었습니다.
 표 4: 추가 구조 및 데이터 세트
표 4: 추가 구조 및 데이터 세트
OTO는 또한 더 많은 데이터 세트 및 모델 구조에서 좋은 성능을 달성합니다.
저수준 비전 작업

표 4: CARNx2 실험
초해상도 작업에서 OTO 원스톱 훈련은 CARNx2 네트워크를 압축하여 원래 모델과 경쟁력 있는 결과를 얻었습니다. 성능을 향상시키고 계산 작업량과 모델 크기를 75% 이상 압축했습니다.언어 모델 작업

또한 연구진은 핵심 알고리즘 중 하나인 DHSPG 최적화 알고리즘에 대해 Bert에 대한 비교 실험을 진행하여 다른 희소 최적화 알고리즘에 비해 높은 성능을 검증했습니다. Squad에서는 훈련에 DHSPG를 사용하여 얻은 매개변수 감소 및 모델 성능이 다른 희소 최적화 알고리즘보다 훨씬 우수하다는 것을 알 수 있습니다.
결론Microsoft 팀은 OTO(Only-Train-Once)라는 자동화된 원스톱 신경망 훈련 구조 가지치기 프레임워크를 제안했습니다. 고성능을 유지하면서 전체 신경망을 경량 네트워크로 자동 압축할 수 있습니다. OTO는 기존 구조 가지치기 방법의 복잡한 다단계 프로세스를 크게 단순화하고 다양한 네트워크 아키텍처 및 애플리케이션에 적합하며 사용자의 추가 엔지니어링 투자를 최소화합니다. 다용도이고 효과적이며 사용하기 쉽습니다.위 내용은 Microsoft는 원스톱으로 고성능 경량 모델을 얻기 위해 자동화된 신경망 훈련 가지치기 프레임워크 OTO를 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7552
7552
 15
1382
52
83
11
59
19
22
95
15
1382
52
83
11
59
19
22
95

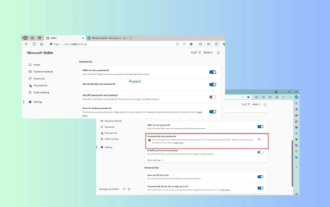 Microsoft Edge 업그레이드: 자동 비밀번호 저장 기능이 금지되나요? ! 유저들은 충격을 받았습니다!
Apr 19, 2024 am 08:13 AM
Microsoft Edge 업그레이드: 자동 비밀번호 저장 기능이 금지되나요? ! 유저들은 충격을 받았습니다!
Apr 19, 2024 am 08:13 AM
4월 18일 뉴스: 최근 Canary 채널을 사용하는 Microsoft Edge 브라우저의 일부 사용자가 최신 버전으로 업그레이드한 후 비밀번호 자동 저장 옵션이 비활성화된 것을 발견했다고 보고했습니다. 조사 결과 이는 기능의 취소라기보다는 브라우저 업그레이드 이후의 소소한 조정인 것으로 밝혀졌습니다. Edge 브라우저를 사용하여 웹 사이트에 액세스하기 전에 사용자는 브라우저에서 웹 사이트의 로그인 비밀번호를 저장할 것인지 묻는 창을 표시한다고 보고했습니다. 저장을 선택하면 Edge는 다음 로그인 시 저장된 계정번호와 비밀번호를 자동으로 입력해 사용자에게 큰 편의성을 제공합니다. 그러나 최신 업데이트는 기본 설정을 변경하는 조정과 유사합니다. 사용자는 비밀번호를 저장하도록 선택한 다음 설정에서 저장된 계정 및 비밀번호 자동 채우기를 수동으로 켜야 합니다.
 마이크로소프트, 보안 강화, 잠금 화면 최적화 등 Win11 8월 누적 업데이트 출시
Aug 14, 2024 am 10:39 AM
마이크로소프트, 보안 강화, 잠금 화면 최적화 등 Win11 8월 누적 업데이트 출시
Aug 14, 2024 am 10:39 AM
8월 14일 이 사이트의 소식에 따르면 오늘 8월 패치 화요일 이벤트 당일 마이크로소프트는 22H2와 23H2용 KB5041585 업데이트, 21H2용 KB5041592 업데이트를 포함해 윈도우 11 시스템용 누적 업데이트를 출시했다. 위 장비가 8월 누적 업데이트로 설치된 후, 본 사이트에 첨부된 버전번호 변경 사항은 다음과 같습니다. 21H2 장비 설치 후, 장비 설치 후 버전번호가 Build22000.314722H2로 증가되었습니다. Windows 1121H2용 KB5041585 업데이트의 주요 내용은 다음과 같습니다.
 Microsoft의 전체 화면 팝업은 Windows 10 사용자에게 서둘러 Windows 11로 업그레이드하도록 촉구합니다.
Jun 06, 2024 am 11:35 AM
Microsoft의 전체 화면 팝업은 Windows 10 사용자에게 서둘러 Windows 11로 업그레이드하도록 촉구합니다.
Jun 06, 2024 am 11:35 AM
6월 3일자 뉴스에 따르면, 마이크로소프트는 모든 윈도우 10 사용자에게 적극적으로 전체 화면 알림을 보내 윈도우 11 운영체제로의 업그레이드를 독려하고 있다. 이 이동에는 하드웨어 구성이 새 시스템을 지원하지 않는 장치가 포함됩니다. 2015년부터 Windows 10은 거의 70%의 시장 점유율을 차지하며 Windows 운영 체제로서의 지배력을 확고히 자리 잡았습니다. 하지만 시장점유율은 82%를 훨씬 웃돌며, 2021년 출시 예정인 윈도우 11보다 시장점유율이 훨씬 높다. Windows 11이 출시된 지 거의 3년이 지났지만 시장 침투 속도는 여전히 느립니다. Microsoft는 Windows 10에 대한 기술 지원을 2025년 10월 14일 이후 종료한다고 발표했습니다.
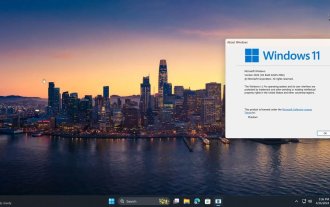 Microsoft Win11의 7z 및 TAR 파일 압축 기능이 24H2에서 23H2/22H2 버전으로 다운그레이드되었습니다.
Apr 28, 2024 am 09:19 AM
Microsoft Win11의 7z 및 TAR 파일 압축 기능이 24H2에서 23H2/22H2 버전으로 다운그레이드되었습니다.
Apr 28, 2024 am 09:19 AM
4월 27일 이 사이트의 소식에 따르면 마이크로소프트는 이달 초 카나리아 및 개발자 채널에 윈도우 11 빌드 26100 프리뷰 버전 업데이트를 출시했는데, 이는 윈도우 1124H2 업데이트의 후보 RTM 버전이 될 것으로 예상된다. 새 버전의 주요 변경 사항은 파일 탐색기, Copilot 통합, PNG 파일 메타데이터 편집, TAR 및 7z 압축 파일 생성 등입니다. @PhantomOfEarth는 Microsoft가 TAR 및 7z 압축 파일 생성과 같은 24H2 버전(게르마늄)의 일부 기능을 23H2/22H2(니켈) 버전으로 위임했다는 사실을 발견했습니다. 다이어그램에 표시된 것처럼 Windows 11은 TAR의 기본 생성을 지원합니다.
 Microsoft Edge 브라우저 업데이트: 사용자 경험 개선을 위해 '이미지 확대' 기능 추가
Mar 21, 2024 pm 01:40 PM
Microsoft Edge 브라우저 업데이트: 사용자 경험 개선을 위해 '이미지 확대' 기능 추가
Mar 21, 2024 pm 01:40 PM
3월 21일 뉴스에 따르면 마이크로소프트는 최근 마이크로소프트 엣지 브라우저를 업데이트하고 실용적인 '이미지 확대' 기능을 추가했다. 이제 Edge 브라우저를 사용할 때 사용자는 이미지를 마우스 오른쪽 버튼으로 클릭하기만 하면 팝업 메뉴에서 이 새로운 기능을 쉽게 찾을 수 있습니다. 더욱 편리한 점은 사용자가 이미지 위에 커서를 놓은 다음 Ctrl 키를 두 번 클릭하여 이미지 확대 기능을 빠르게 호출할 수도 있다는 것입니다. 편집자의 이해에 따르면 최근 출시된 Microsoft Edge 브라우저는 Canary 채널의 새로운 기능에 대해 테스트되었습니다. 안정적인 버전의 브라우저에서는 실용적인 "이미지 확대" 기능도 공식적으로 출시되어 사용자에게 더욱 편리한 이미지 탐색 경험을 제공합니다. 해외 과학기술 언론도 이에 주목했다.
 이미지 유사성 비교를 위해 대비 손실을 사용하는 Siamese 네트워크 탐색
Apr 02, 2024 am 11:37 AM
이미지 유사성 비교를 위해 대비 손실을 사용하는 Siamese 네트워크 탐색
Apr 02, 2024 am 11:37 AM
소개 컴퓨터 비전 분야에서 이미지 유사성을 정확하게 측정하는 것은 광범위한 실제 응용 분야에서 중요한 작업입니다. 이미지 검색 엔진부터 얼굴 인식 시스템, 콘텐츠 기반 추천 시스템까지 유사한 이미지를 효과적으로 비교하고 찾는 능력이 중요합니다. 대조 손실과 결합된 Siamese 네트워크는 데이터 기반 방식으로 이미지 유사성을 학습하기 위한 강력한 프레임워크를 제공합니다. 이 블로그 게시물에서는 Siamese 네트워크에 대해 자세히 알아보고 대비 손실의 개념을 살펴보고 이 두 구성 요소가 어떻게 함께 작동하여 효과적인 이미지 유사성 모델을 생성하는지 살펴보겠습니다. 첫째, Siamese 네트워크는 동일한 가중치와 매개변수를 공유하는 두 개의 동일한 하위 네트워크로 구성됩니다. 각 하위 네트워크는 입력 이미지를 특징 벡터로 인코딩합니다.
 Microsoft는 2024년 하반기에 Windows 11에서 NTLM을 단계적으로 폐지하고 Kerberos 인증으로 완전히 전환할 계획입니다.
Jun 09, 2024 pm 04:17 PM
Microsoft는 2024년 하반기에 Windows 11에서 NTLM을 단계적으로 폐지하고 Kerberos 인증으로 완전히 전환할 계획입니다.
Jun 09, 2024 pm 04:17 PM
2024년 하반기, 마이크로소프트 공식 보안 블로그는 보안 커뮤니티의 요청에 대한 응답으로 메시지를 게시했습니다. 회사는 보안 강화를 위해 2024년 하반기 출시되는 윈도우 11에서 NTLM(NTLAN Manager) 인증 프로토콜을 삭제할 계획이다. 이전 설명에 따르면 Microsoft는 이전에도 비슷한 조치를 취한 적이 있습니다. 작년 10월 12일 Microsoft는 공식 보도 자료를 통해 NTLM 인증 방법을 단계적으로 폐지하고 더 많은 기업과 사용자가 Kerberos로 전환하도록 유도하는 전환 계획을 제안했습니다. NTLM 인증을 끈 후 유선 응용 프로그램 및 서비스에 문제가 발생할 수 있는 기업을 돕기 위해 Microsoft는 IAKerb 및
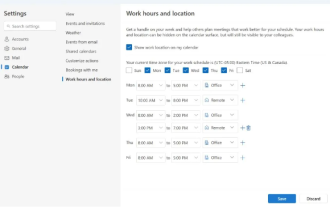 Microsoft, Windows용 Outlook 새 버전 출시: 달력 기능의 포괄적인 업그레이드
Apr 27, 2024 pm 03:44 PM
Microsoft, Windows용 Outlook 새 버전 출시: 달력 기능의 포괄적인 업그레이드
Apr 27, 2024 pm 03:44 PM
4월 27일 뉴스에서 Microsoft는 Windows 클라이언트용 Outlook의 새 버전에 대한 테스트를 곧 출시할 것이라고 발표했습니다. 이번 업데이트는 사용자의 작업 효율성을 향상하고 일상적인 작업 흐름을 더욱 단순화하는 것을 목표로 달력 기능 최적화에 주로 중점을 두고 있습니다. Windows 클라이언트용 Outlook 새 버전의 개선 사항은 더욱 강력한 일정 관리 기능에 있습니다. 이제 사용자는 개인 근무 시간과 위치 정보를 더 쉽게 공유할 수 있어 회의 계획이 더욱 효율적이 됩니다. 또한 Outlook에는 사용자 친화적인 설정이 추가되어 사용자가 회의를 자동으로 일찍 종료하거나 나중에 시작하도록 설정할 수 있으므로 회의실을 바꾸거나 휴식을 취하거나 커피를 마시려는 경우 사용자에게 더 많은 유연성을 제공합니다. . ~에 따르면
