

ChatGPT API로 구동되는 음성 챗봇을 만들었습니다. 지침을 따르십시오.

오늘의 기사는 ChatGPT API를 사용하여 비공개 음성 Chatbot 웹 애플리케이션을 만드는 데 중점을 둡니다. 목적은 인공 지능에 대한 더 많은 잠재적인 사용 사례와 비즈니스 기회를 탐색하고 발견하는 것입니다. 여러분이 프로세스를 이해하고 직접 복제할 수 있도록 개발 프로세스를 단계별로 안내해 드리겠습니다.
필요한 이유
- 모든 사람이 타이핑 기반 서비스를 환영하는 것은 아닙니다. 아직 글쓰기 기술을 배우고 있는 어린이나 화면에서 단어를 제대로 볼 수 없는 노인을 상상해보세요. 음성 기반 AI Chatbot은 이 문제에 대한 솔루션입니다. 예를 들어 우리 아이가 음성 Chatbot에게 취침 시간에 이야기를 읽어달라고 요청하는 데 도움이 되었습니다.
- Apple의 Siri 및 Amazon의 Alexa와 같은 기존 보조 옵션을 고려할 때 GPT 모델에 음성 상호 작용을 추가하면 더 넓은 범위의 가능성이 열릴 수 있습니다. ChatGPT API는 일관되고 상황에 맞는 응답을 생성하는 탁월한 능력을 갖추고 있으며, 이는 음성 기반 스마트 홈 연결 아이디어와 결합되어 풍부한 비즈니스 기회를 제공할 수 있습니다. 이 기사에서 만든 음성 도우미가 진입점 역할을 합니다.
이론은 충분합니다. 시작해 보겠습니다.
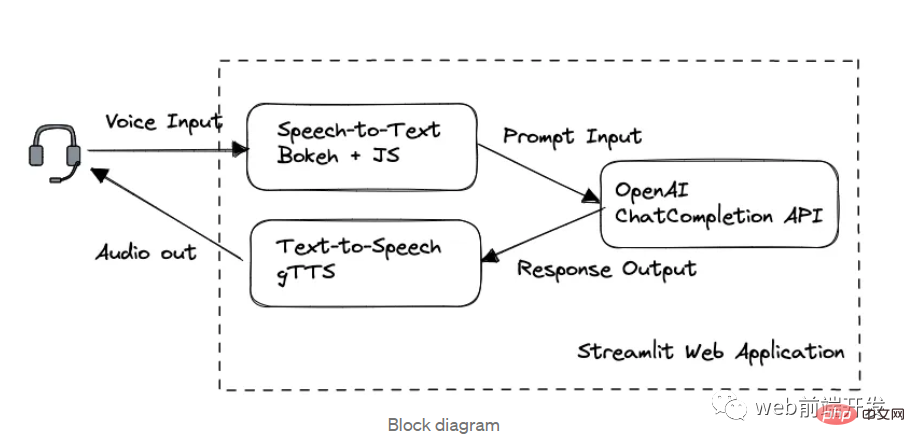
1. 블록 다이어그램
이 애플리케이션에서는 처리 순서에 따라 세 가지 주요 모듈로 나뉩니다.
- Bokeh 및 Web Speech API의 음성 텍스트 변환
- 채팅은 OpenAI GPT-3.5 API를 통해 완료됩니다.
- gTTS 텍스트 음성 변환
Streamlit에서 구축한 웹 프레임워크입니다.
GPT 3.5 모델에서 OpenAI API를 사용하는 방법과 Streamlit을 사용하여 웹 애플리케이션을 설계하는 방법을 이미 알고 있다면 읽기 시간을 절약하기 위해 1부와 2부를 건너뛰는 것이 좋습니다.
2. OpenAI GPT API
API 키 받기
이미 OpenAI API 키가 있는 경우 새 키를 만드는 대신 그대로 사용하세요. 그러나 OpenAI를 처음 사용하는 경우 새 계정에 가입하고 계정 메뉴에서 다음 페이지를 찾으세요.
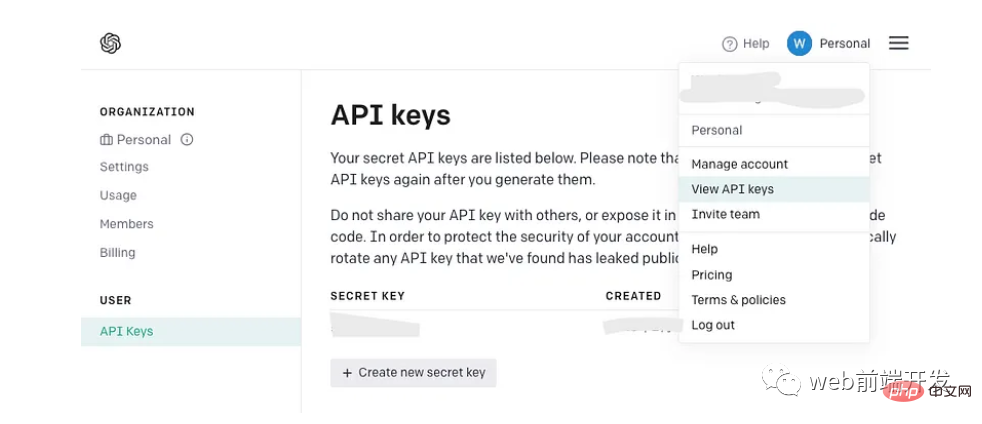
API 키를 생성하면 한 번만 표시된다는 점을 기억하세요. 나중에 사용할 수 있도록 안전한 장소에 복사해 두십시오.
Usage of ChatCompletion API
현재 GPT-4.0이 막 출시되었고, 이 모델의 API는 아직 완전히 출시되지 않았기 때문에 저희 AI 음성 챗봇을 완성하기에 충분한 스틸 GPT 3.5 모델의 개발을 소개하겠습니다. 데모.
이제 ChatCompletion API(gpt-3.5 API 또는 ChatGPT API라고도 함)의 기본 정의를 이해하기 위해 OpenAI의 가장 간단한 데모를 살펴보겠습니다.
설치 패키지:
!pip install opena
이전에 OpenAI에서 개발한 경우 일부 레거시 GPT 모델의 경우 pip를 통해 패키지를 업그레이드해야 할 수도 있습니다.
!pip install --upgrade openai
프롬프트 생성 및 보내기:
import openai
complete = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)텍스트 응답 받기:
message=complete.choices[0].message.content
GPT 3.5 API는 채팅 기반 텍스트 완성 API이므로 다음을 확인하세요. request ChatCompletion 메시지 본문에는 대화 기록이 컨텍스트로 포함되어 있으며 모델이 현재 요청에 대한 응답으로 보다 상황에 맞는 응답을 참조하기를 원합니다.
이 기능을 구현하려면 메시지 본문의 목록 개체를 다음 순서로 구성해야 합니다.
- 시스템 메시지는 메시지 목록 상단의 콘텐츠에 지침을 추가하여 챗봇의 동작을 설정하는 것으로 정의됩니다. 소개에서 언급했듯이 이 기능은 현재 gpt-3.5-turbo-0301에서 완전히 출시되지 않았습니다.
- 사용자 메시지는 사용자의 입력이나 쿼리를 나타내고, 도우미 메시지는 GPT-3.5 API의 해당 응답을 나타냅니다. 이러한 쌍을 이루는 대화는 컨텍스트에 대한 모델에 대한 참조를 제공합니다.
- 마지막 사용자 메시지는 현재 요청된 프롬프트를 나타냅니다.
3. 웹 개발
우리는 계속해서 강력한 Streamlit 라이브러리를 사용하여 웹 애플리케이션을 구축할 것입니다.
Streamlit은 데이터 과학자와 개발자가 기계 학습 및 데이터 과학 프로젝트를 위한 대화형 웹 애플리케이션을 빠르게 구축하고 공유할 수 있게 해주는 오픈 소스 프레임워크입니다. 또한 st.table(...)과 같이 단 한 줄의 Python 코드로 생성할 수 있는 여러 위젯을 제공합니다.
웹 개발에 능숙하지 않고 나처럼 대규모 상용 애플리케이션을 구축할 의향이 없다면 Streamlit은 HTML에 대한 전문 지식이 거의 필요하지 않으므로 항상 최고의 옵션 중 하나입니다.
Streamlit 웹 애플리케이션을 구축하는 빠른 예를 살펴보겠습니다.
설치 패키지:
!pip install streamlit
Python 파일 "demo.py" 만들기:
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")로컬 컴퓨터 또는 원격 서버에서 실행:
!python -m streamlit run demo.py
한 번 인쇄 내보낸 경우 나열된 주소와 포트를 통해 웹사이트에 액세스할 수 있습니다:
You can now view your Streamlit app in your browser. Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501

Streamlit 提供的所有小部件的用法可以在其文档页面中找到:https://docs.streamlit.io/library/api-reference
4.语音转文字的实现
此 AI 语音聊天机器人的主要功能之一是它能够识别用户语音并生成我们的 ChatCompletion API 可用作输入的适当文本。
OpenAI 的 Whisper API 提供的高质量语音识别是一个很好的选择,但它是有代价的。或者,来自 Javascript 的免费 Web Speech API 提供可靠的多语言支持和令人印象深刻的性能。
虽然开发 Python 项目似乎与定制的 Javascript 不兼容,但不要害怕!在下一部分中,我将介绍一种在 Python 程序中调用 Javascript 代码的简单技术。
不管怎样,让我们看看如何使用 Web Speech API 快速开发语音转文本演示。您可以找到它的文档(地址:https://wicg.github.io/speech-api/)。
语音识别的实现可以很容易地完成,如下所示。
var recognition = new webkitSpeechRecognition(); recognition.continuous = false; recognition.interimResults = true; recognition.lang = 'en'; recognition.start();
通过方法 webkitSpeechRecognition() 初始化识别对象后,需要定义一些有用的属性。continuous 属性表示您是否希望 SpeechRecognition 函数在语音输入的一种模式处理成功完成后继续工作。
我将其设置为 false,因为我希望语音聊天机器人能够以稳定的速度根据用户语音输入生成每个答案。
设置为 true 的 interimResults 属性将在用户语音期间生成一些中间结果,以便用户可以看到从他们的语音输入输出的动态消息。
lang 属性将设置请求识别的语言。请注意,如果它在代码中是未设置,则默认语言将来自 HTML 文档根元素和关联的层次结构,因此在其系统中使用不同语言设置的用户可能会有不同的体验。
识别对象有多个事件,我们使用 .onresult 回调来处理来自中间结果和最终结果的文本生成结果。
recognition.onresult = function (e) {
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
}5.引入Bokeh库
从用户界面的定义来看,我们想设计一个按钮来启动我们在上一节中已经用 Javascript 实现的语音识别。

Streamlit 库不支持自定义 JS 代码,所以我们引入了 Bokeh。Bokeh 库是另一个强大的 Python 数据可视化工具。可以支持我们的演示的最佳部分之一是嵌入自定义 Javascript 代码,这意味着我们可以在 Bokeh 的按钮小部件下运行我们的语音识别脚本。
为此,我们应该安装 Bokeh 包。为了兼容后面会提到的streamlit-bokeh-events库,Bokeh的版本应该是2.4.2:
!pip install bokeh==2.4.2
导入按钮和 CustomJS:
from bokeh.models.widgets import Button from bokeh.models import CustomJS
创建按钮小部件:
spk_button = Button(label='SPEAK', button_type='success')
定义按钮点击事件:
spk_button.js_on_event("button_click", CustomJS(code="""
...js code...
"""))定义了.js_on_event()方法来注册spk_button的事件。
在这种情况下,我们注册了“button_click”事件,该事件将在用户单击后触发由 CustomJS() 方法嵌入的 JS 代码块…js 代码…的执行。
Streamlit_bokeh_event
speak 按钮及其回调方法实现后,下一步是将 Bokeh 事件输出(识别的文本)连接到其他功能块,以便将提示文本发送到 ChatGPT API。
幸运的是,有一个名为“Streamlit Bokeh Events”的开源项目专为此目的而设计,它提供与 Bokeh 小部件的双向通信。你可以在这里找到它的 GitHub 页面。
这个库的使用非常简单。首先安装包:
!pip install streamlit-bokeh-events
通过 streamlit_bokeh_events 方法创建结果对象。
result = streamlit_bokeh_events( bokeh_plot = spk_button, events="GET_TEXT,GET_ONREC,GET_INTRM", key="listen", refresh_on_update=False, override_height=75, debounce_time=0)
使用 bokeh_plot 属性来注册我们在上一节中创建的 spk_button。使用 events 属性来标记多个自定义的 HTML 文档事件
- GET_TEXT 接收最终识别文本
- GET_INTRM 接收临时识别文本
- GET_ONREC 接收语音处理阶段
我们可以使用 JS 函数 document.dispatchEvent(new CustomEvent(…)) 来生成事件,例如 GET_TEXT 和 GET_INTRM 事件:
spk_button.js_on_event("button_click", CustomJS(code="""
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
recognition.start();
}
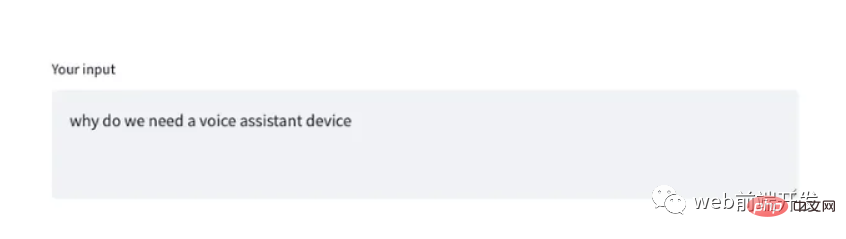
"""))并且,检查事件 GET_INTRM 处理的 result.get() 方法,例如:
tr = st.empty()
if result:
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", result.get("GET_INTRM"))这两个代码片段表明,当用户正在讲话时,任何临时识别文本都将显示在 Streamlit text_area 小部件上:
6. 文字转语音实现
提示请求完成,GPT-3.5模型通过ChatGPT API生成响应后,我们通过Streamlit st.write()方法将响应文本直接显示在网页上。

但是,我们需要将文本转换为语音,这样我们的 AI 语音 Chatbot 的双向功能才能完全完成。
有一个名为“gTTS”的流行 Python 库能够完美地完成这项工作。在与谷歌翻译的文本转语音 API 接口后,它支持多种格式的语音数据输出,包括 mp3 或 stdout。你可以在这里找到它的 GitHub 页面。
只需几行代码即可完成转换。首先安装包:
!pip install gTTS
在这个演示中,我们不想将语音数据保存到文件中,所以我们可以调用 BytesIO() 来临时存储语音数据:
sound = BytesIO() tts = gTTS(output, lang='en', tld='com') tts.write_to_fp(sound)
输出的是要转换的文本字符串,你可以根据自己的喜好,通过tld从不同的google域中选择不同的语言by lang。例如,您可以设置 tld='co.uk' 以生成英式英语口音。
然后,通过 Streamlit 小部件创建一个像样的音频播放器:
st.audio(sound)
全语音聊天机器人
要整合上述所有模块,我们应该完成完整的功能:
- 已完成与 ChatCompletion API 的交互,并在用户和助手消息块中定义了附加的历史对话。使用 Streamlit 的 st.session_state 来存储运行变量。
- 考虑到 .onspeechstart()、.onsoundend() 和 .onerror() 等多个事件以及识别过程,在 SPEAK 按钮的 CustomJS 中完成了事件生成。
- 完成事件“GET_TEXT、GET_ONREC、GET_INTRM”的事件处理,以在网络界面上显示适当的信息,并管理用户讲话时的文本显示和组装。
- 所有必要的 Streamit 小部件
请找到完整的演示代码供您参考:
import streamlit as st
from bokeh.models.widgets import Button
from bokeh.models import CustomJS
from streamlit_bokeh_events import streamlit_bokeh_events
from gtts import gTTS
from io import BytesIO
import openai
openai.api_key = '{Your API Key}'
if 'prompts' not in st.session_state:
st.session_state['prompts'] = [{"role": "system", "content": "You are a helpful assistant. Answer as concisely as possible with a little humor expression."}]
def generate_response(prompt):
st.session_state['prompts'].append({"role": "user", "content":prompt})
completinotallow=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = st.session_state['prompts']
)
message=completion.choices[0].message.content
return message
sound = BytesIO()
placeholder = st.container()
placeholder.title("Yeyu's Voice ChatBot")
stt_button = Button(label='SPEAK', button_type='success', margin = (5, 5, 5, 5), width=200)
stt_button.js_on_event("button_click", CustomJS(code="""
var value = "";
var rand = 0;
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'start'}));
recognition.onspeechstart = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'running'}));
}
recognition.onsoundend = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.onresult = function (e) {
var value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
}
recognition.onerror = function(e) {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.start();
"""))
result = streamlit_bokeh_events(
bokeh_plot = stt_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)
tr = st.empty()
if 'input' not in st.session_state:
st.session_state['input'] = dict(text='', sessinotallow=0)
tr.text_area("**Your input**", value=st.session_state['input']['text'])
if result:
if "GET_TEXT" in result:
if result.get("GET_TEXT")["t"] != '' and result.get("GET_TEXT")["s"] != st.session_state['input']['session'] :
st.session_state['input']['text'] = result.get("GET_TEXT")["t"]
tr.text_area("**Your input**", value=st.session_state['input']['text'])
st.session_state['input']['session'] = result.get("GET_TEXT")["s"]
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", value=st.session_state['input']['text']+' '+result.get("GET_INTRM"))
if "GET_ONREC" in result:
if result.get("GET_ONREC") == 'start':
placeholder.image("recon.gif")
st.session_state['input']['text'] = ''
elif result.get("GET_ONREC") == 'running':
placeholder.image("recon.gif")
elif result.get("GET_ONREC") == 'stop':
placeholder.image("recon.jpg")
if st.session_state['input']['text'] != '':
input = st.session_state['input']['text']
output = generate_response(input)
st.write("**ChatBot:**")
st.write(output)
st.session_state['input']['text'] = ''
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)
st.audio(sound)
st.session_state['prompts'].append({"role": "user", "content":input})
st.session_state['prompts'].append({"role": "assistant", "content":output})输入后:
!python -m streamlit run demo_voice.py
您最终会在网络浏览器上看到一个简单但智能的语音聊天机器人。
请注意:不要忘记在弹出请求时允许网页访问您的麦克风和扬声器。
就是这样,一个简单聊天机器人就完成了。
最后,希望您能在本文中找到有用的东西,感谢您的阅读!
위 내용은 ChatGPT API로 구동되는 음성 챗봇을 만들었습니다. 지침을 따르십시오.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7488
7488
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39

 이제 ChatGPT를 사용하면 무료 사용자가 일일 한도가 있는 DALL-E 3를 사용하여 이미지를 생성할 수 있습니다.
Aug 09, 2024 pm 09:37 PM
이제 ChatGPT를 사용하면 무료 사용자가 일일 한도가 있는 DALL-E 3를 사용하여 이미지를 생성할 수 있습니다.
Aug 09, 2024 pm 09:37 PM
DALL-E 3는 이전 모델보다 대폭 개선된 모델로 2023년 9월 공식 출시되었습니다. 복잡한 디테일의 이미지를 생성할 수 있는 현재까지 최고의 AI 이미지 생성기 중 하나로 간주됩니다. 그러나 출시 당시에는 제외되었습니다.
 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
 AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
7월 5일 이 웹사이트의 소식에 따르면 글로벌파운드리는 올해 7월 1일 보도자료를 통해 타고르 테크놀로지(Tagore Technology)의 전력질화갈륨(GaN) 기술 및 지적재산권 포트폴리오 인수를 발표하고 자동차와 인터넷 시장 점유율 확대를 희망하고 있다고 밝혔다. 더 높은 효율성과 더 나은 성능을 탐구하기 위한 사물 및 인공 지능 데이터 센터 응용 분야입니다. 생성 AI와 같은 기술이 디지털 세계에서 계속 발전함에 따라 질화갈륨(GaN)은 특히 데이터 센터에서 지속 가능하고 효율적인 전력 관리를 위한 핵심 솔루션이 되었습니다. 이 웹사이트는 이번 인수 기간 동안 Tagore Technology의 엔지니어링 팀이 GLOBALFOUNDRIES에 합류하여 질화갈륨 기술을 더욱 개발할 것이라는 공식 발표를 인용했습니다. G
 SK하이닉스가 8월 6일 12단 HBM3E, 321고 NAND 등 AI 관련 신제품을 선보인다.
Aug 01, 2024 pm 09:40 PM
SK하이닉스가 8월 6일 12단 HBM3E, 321고 NAND 등 AI 관련 신제품을 선보인다.
Aug 01, 2024 pm 09:40 PM
1일 본 사이트 소식에 따르면 SK하이닉스는 오늘(1일) 블로그 게시물을 통해 8월 6일부터 8일까지 미국 캘리포니아주 산타클라라에서 열리는 글로벌 반도체 메모리 서밋 FMS2024에 참가한다고 밝혔다. 많은 새로운 세대의 제품. 인공지능 기술에 대한 관심이 높아지고 있는 가운데, 이전에는 주로 NAND 공급업체를 대상으로 한 플래시 메모리 서밋(FlashMemorySummit)이었던 미래 메모리 및 스토리지 서밋(FutureMemoryandStorage) 소개를 올해는 미래 메모리 및 스토리지 서밋(FutureMemoryandStorage)으로 명칭을 변경했습니다. DRAM 및 스토리지 공급업체와 더 많은 플레이어를 초대하세요. SK하이닉스가 지난해 출시한 신제품
 SearchGPT: Open AI가 자체 AI 검색 엔진으로 Google을 상대합니다.
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI가 자체 AI 검색 엔진으로 Google을 상대합니다.
Jul 30, 2024 am 09:58 AM
오픈AI(Open AI)가 드디어 검색에 본격 진출한다. 샌프란시스코 회사는 최근 검색 기능을 갖춘 새로운 AI 도구를 발표했습니다. 올해 2월 The Information에서 처음 보고한 새로운 도구는 SearchGPT라고 불리며
