
인공지능을 배우려면 필연적으로 일부 데이터 세트가 필요합니다. 예를 들어 음란물을 식별하는 인공지능에는 유사한 사진이 필요합니다. 음성인식과 코퍼스를 위한 인공지능은 필수다. 인공지능을 처음 접하는 학생들은 종종 데이터 세트에 대해 걱정합니다. 오늘은 매우 간단하지만 매우 유용한 데이터 세트인 MNIST를 소개하겠습니다. 이 데이터 세트는 우리가 인공지능 관련 알고리즘을 배우고 실습하는데 매우 적합합니다.
MNIST 데이터세트는 미국 국립표준기술연구소(NIST)에서 제작한 매우 간단한 데이터세트입니다. 그렇다면 이 데이터 세트는 무엇에 관한 것일까요? 실제로는 손으로 쓴 아라비아 숫자(0에서 9까지의 10개 숫자)입니다.
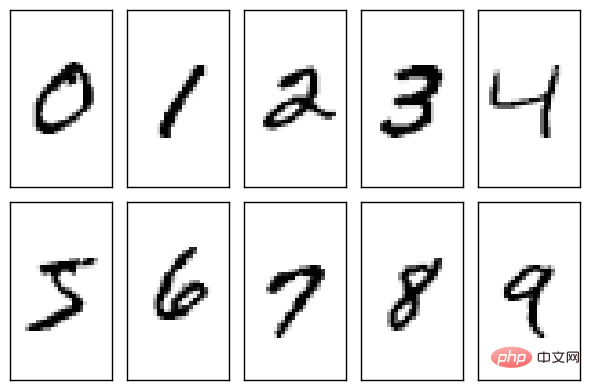
NIST는 데이터 세트를 생성할 때 여전히 매우 진지합니다. 데이터 세트의 훈련 세트는 250명의 서로 다른 사람들이 손으로 쓴 숫자로 구성되며, 그 중 50%는 고등학생이고 50%는 인구 조사국 직원입니다. 테스트 세트 역시 손으로 쓴 숫자 데이터와 동일한 비율입니다.
MNIST 데이터셋은 공식 홈페이지(http://yann.lecun.com/exdb/mnist/)에서 다운로드 받을 수 있습니다. 느린. 여기에는 네 부분이 포함되어 있습니다:
위 내용에는 두 가지 유형의 콘텐츠가 포함되어 있는데 하나는 사진이고 다른 하나는 라벨이며 그림과 라벨이 하나씩 해당됩니다. 그런데 여기의 사진은 우리가 흔히 보는 사진 파일이 아니라 바이너리 파일입니다. 이 데이터 세트는 60,000개의 이미지를 바이너리 형식으로 저장합니다. 라벨은 그림에 해당하는 실제 숫자입니다.
아래 그림과 같이 이 글에서는 데이터 세트를 로컬로 다운로드하고 결과를 압축 해제합니다. 비교의 용이성을 위해 원본 압축 패키지와 압축 해제 파일이 포함되어 있습니다.
압축 해제 후 압축된 패키지는 그림이 아니지만 압축된 각 패키지는 독립적인 문제에 해당한다는 사실을 누구나 발견했습니다. 이 파일에는 수만 장의 사진이나 태그에 대한 정보가 저장됩니다. 그러면 이 정보는 이 파일에 어떻게 저장됩니까?
사실 MNIST 공식 홈페이지에 자세한 설명이 나와있습니다. 트레이닝 세트의 이미지 파일을 예로 들면, 공식 홈페이지에서 제공하는 파일 형식 설명은 다음과 같습니다.
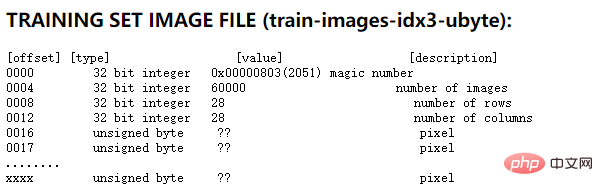
위 그림에서 알 수 있듯이 처음 4개의 32자리 숫자가 설명 정보입니다. 훈련 세트의. 첫 번째는 0x0803의 고정 값인 매직 넘버입니다. 두 번째는 사진 수, 0xea60으로 60000입니다. 즉, 사진의 크기는 28*입니다. 28픽셀. 다음은 1바이트의 각 픽셀에 대해 설명합니다. 이 파일의 픽셀을 설명하는 데 1바이트가 사용되므로 픽셀 값이 0부터 255까지 가능하다는 것을 알 수 있습니다. 여기서 0은 흰색을 의미하고 255는 검정색을 의미합니다.

라벨 파일의 형식은 이미지 파일의 형식과 유사합니다. 앞에는 2개의 32자리 숫자가 있는데, 첫 번째 숫자는 매직 넘버이고, 두 번째 숫자는 태그 수를 설명하는 데 사용됩니다. 다음 데이터는 1바이트로 표시되는 각 태그의 값입니다. 여기서 표현되는 값의 범위는

실제 훈련 세트의 라벨 파일에 해당하는 데이터는 다음과 같습니다. 위 형식의 설명과 일치함을 알 수 있다. 또한, 이 라벨 세트에 대응하여 이전 그림이 나타내는 숫자는 각각 5, 0, 4, 1 등이 되어야 함을 알 수 있습니다. 여기서 기억해두세요. 나중에 사용됩니다.

데이터 세트의 파일 형식에 대해 알고 있으므로 실제로 사용해 보겠습니다.
위 데이터의 저장 형식을 알고 나면 데이터를 구문 분석할 수 있습니다. 예를 들어, 다음 문서에서는 사진 컬렉션의 사진을 구문 분석하고 시각적 결과를 얻는 작은 프로그램을 구현합니다. 물론 실제로 라벨 세트의 값을 보면 어떤 그림인지 알 수 있습니다. 이는 단지 실험일 뿐입니다. 최종 결과는 문자 "Y"를 사용하여 필기체를 나타내고 문자 "0"을 배경색으로 사용하여 텍스트 파일에 저장됩니다. 특정 프로그램 코드는 매우 간단하므로 이 문서에서는 자세히 설명하지 않습니다.
# -*- coding: UTF-8 -*-
def trans_to_txt(train_file, txt_file, index):
with open(train_file, 'rb') as sf:
with open(txt_file, "w") as wf:
offset = 16 + (28*28*index)
cur_pos = offset
count = 28*28
strlen = 1
out_count = 1
while cur_pos < offset+count:
sf.seek(cur_pos)
data = sf.read(strlen)
res = int(data[0])
#虽然在数据集中像素是1-255表示颜色,这里简化为Y
if res > 0 :
wf.write(" Y ")
else:
wf.write(" 0 ")
#由于图片是28列,因此在此进行换行
if out_count % 28 == 0 :
wf.write("n")
cur_pos += strlen
out_count += 1
trans_to_txt("../data/train-images.idx3-ubyte", "image.txt", 0)위 코드를 실행하면 image.txt라는 파일을 얻을 수 있습니다. 파일의 내용은 다음과 같이 볼 수 있습니다. 주로 더 나은 가시성을 위해 빨간색 메모가 나중에 추가되었습니다. 사진에서 볼 수 있듯이 실제로는 손으로 쓴 "5"입니다.

이전에는 기본 Python 인터페이스를 통해 데이터 세트를 시각적으로 분석했습니다. Python에는 이미 많은 라이브러리 함수가 구현되어 있으므로 라이브러리 함수를 통해 위 함수를 단순화할 수 있습니다.
기본 Python 인터페이스를 사용하여 구현하는 것은 약간 복잡합니다. 우리는 Python에 많은 타사 라이브러리가 있다는 것을 알고 있으므로 타사 라이브러리를 사용하여 데이터 세트를 구문 분석하고 표시할 수 있습니다.
# -*- coding: utf-8 -*-
import os
import struct
import numpy as np
# 读取数据集,以二维数组的方式返回图片信息和标签信息
def load_mnist(path, kind='train'):
# 从指定目录加载数据集
labels_path = os.path.join(path,
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
#解析图片信息,存储在images中
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 在终端打印某个图片的数据信息
def print_image(data, index):
idx = 0;
count = 0;
for item in data[index]:
if count % 28 == 0:
print("")
if item > 0:
print("33[7;31mY 33[0m", end="")
else:
print("0 ", end="")
count += 1
def main():
cur_path = os.getcwd()
cur_path = os.path.join(cur_path, "..data")
imgs, labels = load_mnist(cur_path)
print_image(imgs, 0)
if __name__ == "__main__":
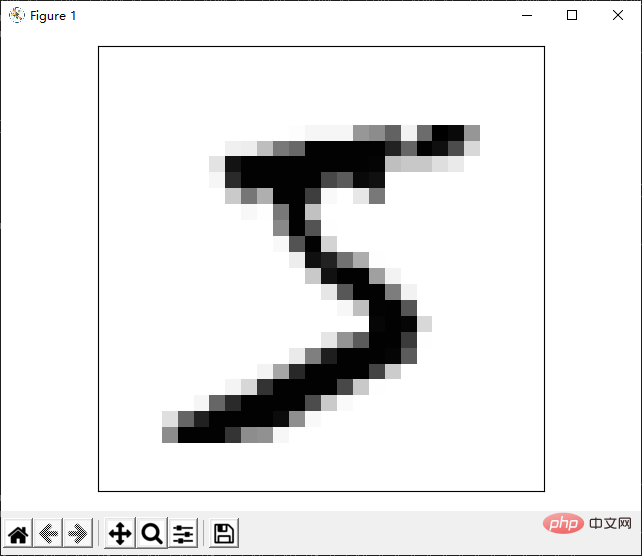
main()위 코드는 두 단계로 나누어집니다. 첫 번째 단계는 데이터 세트를 배열로 구문 분석하는 것이고, 두 번째 단계는 배열에 특정 그림을 표시하는 것입니다. 여기의 표시도 텍스트 프로그램을 통해서인데 파일에 저장되지 않고 터미널에 인쇄됩니다. 예를 들어 첫 번째 사진을 계속 인쇄하면 효과는 다음과 같습니다.

위 결과의 프레젠테이션은 문자를 통해 그림만 시뮬레이션합니다. 실제로 타사 라이브러리를 사용하면 더욱 완벽한 이미지 표현을 얻을 수 있습니다. 다음으로 matplotlib 라이브러리를 통해 그림을 표시하는 방법을 소개합니다. 이 라이브러리는 매우 유용하며 나중에 이 라이브러리를 접하게 될 것입니다.
우리는
def show_image(data, index): fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, sharey=True, ) img = data[0].reshape(28, 28) ax.imshow(img, cmap='Greys', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.show()
를 구현합니다. 이때 위의 기능을 구현할 때
에는 matplotlib 등 일부 타사 라이브러리가 부족할 수 있음을 알 수 있습니다. 이때, 구체적인 방법은 다음과 같습니다.
pip install matplotlib -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
MNIST는 TensorFlow가 이미 지원하고 있을 정도로 유명합니다. 따라서 TensorFlow를 통해 이를 로드하고 구문 분석할 수 있습니다. 아래에는 TensorFlow로 구현된 코드가 나와 있습니다.
# -*- coding: utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import pylab
def show_mnist():
# 通过TensorFlow库解析数据
mnist = input_data.read_data_sets("../data", one_hot=True)
im = mnist.train.images[0]
im = im.reshape(28 ,28)
# 进行绘图
pylab.imshow(im, cmap='Greys', interpolation='nearest')
pylab.show()
if __name__ == "__main__":
show_mnist()이 코드로 얻은 최종 효과는 이전 예제와 일치하므로 여기서는 자세히 설명하지 않겠습니다.
위 내용은 인공지능을 배우고 싶다면 MNIST 소개와 활용을 마스터해야 합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



