
Translator | Zhu Xianzhong
Reviewer | Sun Shujuan
딥러닝 신경망이 최근 많은 주목을 받고 있습니다. 지금은 요즘 음성 인식, 인간 얼굴 인식, 음성 인식, 자율주행차, 뇌종양 진단 기술 등의 기술은 20년 전에는 우리 삶의 일부가 아니었습니다. 이러한 신경망은 복잡해 보이지만 인간과 마찬가지로 다양한 예를 통해 학습합니다. 그러나 신경망은 훈련을 위해 많은 수의 데이터 세트를 사용하며 최상의 컴퓨팅 결과를 얻기 위해 여러 네트워크 계층과 여러 반복을 통해 최적화됩니다.
지난 20년 동안 컴퓨팅 성능과 데이터 양이 기하급수적으로 증가하면서 딥 러닝 신경망을 위한 완벽한 개발 조건이 만들어졌습니다. 실제로는 기계 학습이나 인공 지능과 같은 고급 용어를 접하게 되지만 이러한 기술은 선형 대수학 및 미적분학이 계산과 결합된 것에 지나지 않습니다.
Keras, PyTorch 및 TensorFlow와 같은 프레임워크는 심층 신경망의 어려운 구축, 훈련, 검증 및 배포 프로세스를 사용자 정의하는 데 도움이 됩니다. 실제 생활에서 딥 러닝 애플리케이션을 만드는 경우 , 이러한 프레임워크가 분명히 첫 번째 선택이 됩니다.
그럼에도 불구하고 때로는 한발 물러서서 앞으로 나아가는 것이 중요합니다. 즉, 프레임워크 뒤에서 무슨 일이 일어나고 있는지 진정으로 이해한다는 의미입니다. 이 기사에서는 NumPy 기본 프레임워크만 사용하여 심층 신경망을 생성하고 이를 이미지 분류 문제에 적용하여 이를 수행합니다. 계산 중에, 특히 미적분과 관련된 역전파 중에 길을 잃을 수도 있지만 걱정하지 마십시오. 프레이밍을 할 때의 계산보다는 과정에 대한 직관이 더 중요합니다.
이 기사에서는 총 1652개의 이미지로 구성된 두 세트를 사용하여 훈련할 이미지 분류(고양이 또는 고양이 없음) 신경망을 구축할 것입니다. 그 중 852개 이미지는 개와 고양이 이미지 데이터세트의 고양이 이미지이고, 나머지 800개는 Unsplash 무작위 이미지 세트의 random Images입니다. 시작하려면 먼저 이미지를 배열로 변환해야 합니다. 원본 크기를 128x128 픽셀로 줄여 계산 속도를 높이겠습니다. 원본 모양을 유지하면 모델을 학습하는 데 오랜 시간이 걸리기 때문입니다. 이러한 128x128 이미지에는 모두 세 가지 색상 레이어(빨간색, 녹색, 파란색)가 있습니다. 혼합하면 이러한 색상이 이미지의 원래 색상에 도달합니다. 각 이미지의 128x128 픽셀 각각은 0에서 255까지의 빨간색, 녹색, 파란색 값을 가지며, 이는 이미지 벡터의 값입니다. 따라서 계산에서는 1652개의 이미지에 대해 총 128x128x3 벡터를 처리하게 됩니다.
위의 벡터를 네트워크에서 실행하려면 아래 이미지와 같이 세 가지 색상 레이어를 단일 배열로 쌓아 재구성해야 합니다. 그런 다음 1323개의 이미지 벡터를 사용하여 모델을 학습하고 학습된 모델을 사용하여 이미지 분류(고양이 또는 고양이 없음)를 예측하여 테스트하는 데 사용할 (49152, 1652) 크기 벡터를 얻습니다. 이러한 예측을 이미지의 실제 분류 레이블과 비교한 후 모델의 정확도를 추정할 수 있습니다.
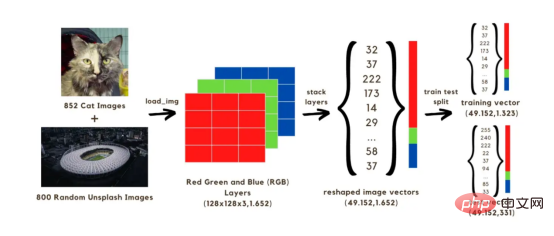
이미지 1: 이미지를 벡터로 변환하는 과정
훈련 벡터에 대한 설명을 마쳤으니 이제 그림 2와 같이 네트워크 아키텍처에 대해 논의할 차례입니다. 훈련 벡터에는 49152개의 값이 사용되었으므로 모델의 입력 레이어에는 동일한 수의 노드(또는 뉴런)가 있어야 합니다. 그런 다음 출력 레이어 앞에 3개의 숨겨진 레이어가 있는데, 이는 이 그림에서 고양이일 확률이 됩니다. 실제 모델에는 일반적으로 3개 이상의 숨겨진 레이어가 있습니다. 빅데이터 환경에서 제대로 작동하려면 네트워크가 더 깊어야 하기 때문입니다.
이 기사에서는 간단한 분류 모델에 충분하기 때문에 3개의 숨겨진 레이어만 사용했습니다. 아키텍처에는 레이어가 4개만 있지만(출력 레이어는 계산되지 않음) 이 코드는 레이어의 차원을 훈련 함수의 매개변수로 사용하여 더 깊은 신경망을 생성할 수 있습니다.
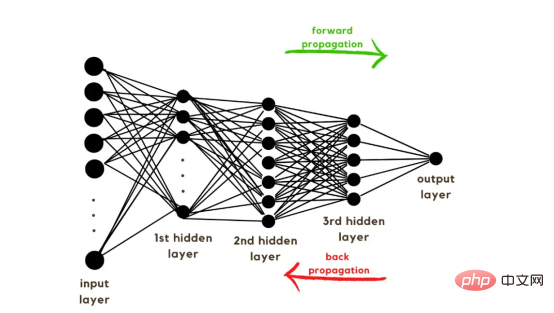
그림 2: Network Architecture
지금까지 이미지 벡터와 채택된 네트워크 아키텍처를 설명했습니다. 다음으로 최적화 알고리즘을 사용하겠습니다. 그림 3에 표시된 경사하강법 알고리즘에 설명되어 있습니다. 다시 말하지만, 모든 단계를 즉시 완료할 수 없더라도 걱정하지 마십시오. 이 문서에서는 나중에 코딩 섹션의 다이어그램에 표시된 각 단계에 대해 자세히 설명합니다.
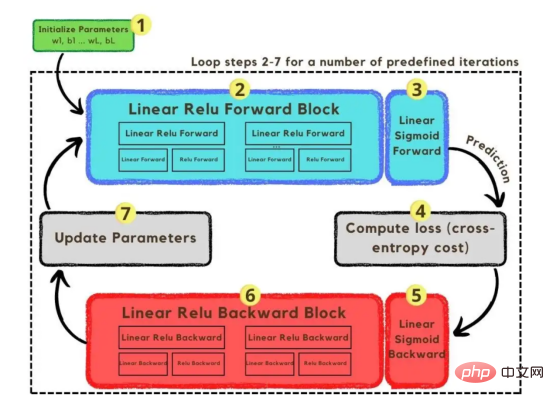
그림 3: TrainingProcess
먼저, 네트워크의 매개변수를 시작합니다. 이러한 매개변수는 이미지 2에 표시된 노드의 각 연결에 대한 가중치(w)와 편향(b)입니다. 코드에서는 각 가중치 및 편향 매개변수의 작동 방식과 초기화 방식을 더 쉽게 이해할 수 있습니다. 나중에 이러한 매개변수가 초기화되면 순방향 전파 블록을 실행하고 마지막 활성화에 시그모이드 함수를 적용하여 확률적 예측을 얻을 차례입니다.
우리의 경우 사진에 고양이가 나올 확률입니다. 그런 다음 분류 모델을 최적화하는 데 널리 사용되는 손실 함수인 교차 엔트로피 비용을 통해 예측을 이미지의 실제 레이블(고양이 또는 고양이 아님)과 비교했습니다. 마지막으로 계산된 비용을 역전파 모듈을 통해 반환하여 매개변수 w 및 b에 대한 기울기를 계산합니다. 이제 w와 b에 대한 손실 함수의 기울기가 알려져 있으므로, 손실 함수를 최소화하는 w와 b 값의 방향을 가리킬 때 개별 기울기를 합산하여 매개변수를 업데이트할 수 있습니다.
목표는 손실 함수를 최소화하는 것이므로 루프는 미리 정의된 반복 횟수에 걸쳐 손실 함수의 최소값을 향해 작은 단계를 거쳐야 합니다. 어느 시점에서는 최소값에 가까워질수록 기울기가 0이 되는 경향이 있기 때문에 매개변수 변경이 중지됩니다.
import numpy as np import pandas as pd import os from os.path import join from tensorflow.keras.preprocessing.image import load_img, img_to_array from sklearn.model_selection import train_test_split
먼저 라이브러리를 로드해야 합니다. keras.preprprocessing.image를 사용하여 이미지를 벡터로 변환하는 것 외에도 Numpy, Pandas 및 OS의 세 가지 라이브러리 모듈만 가져오면 됩니다. 반면에 sklearn.model_selection을 사용하여 이미지 벡터를 두 부분으로 분할합니다. : 훈련 벡터 및 테스트 벡터.
cats_dir = "data\cats"
all_cats_path = [join(cats_dir,filename) for filename in os.listdir(cats_dir)]
images_dir = "data\random_images"
images_path = [join(images_dir,filename) for filename in os.listdir(images_dir)]
all_paths = all_cats_path + images_path
df = pd.DataFrame({
'path': all_paths,
'is_cat': [1 if path in all_cats_path else 0 for path in all_paths] })데이터는 cats와 random_images라는 두 폴더에서 로드되어야 합니다. 이는 모든 파일 이름을 가져오고 각 파일에 대한 경로를 작성하여 수행할 수 있습니다. 그런 다음 데이터프레임의 모든 파일 경로를 병합하고 조건부 열 "is_cat"을 만듭니다. 경로가 cats 폴더에 있으면 값은 1이고, 그렇지 않으면 값은 0입니다.
X = df.path Y = df.is_cat X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=.2 , shuffle= True) X_train = [load_img(img_path,target_size=(128,128)) for img_path in X_train] X_train = np.array([img_to_array(img) for img in X_train]) X_test = [load_img(img_path,target_size=(128,128)) for img_path in X_test] X_test = np.array([img_to_array(img) for img in X_test]) (X_train.shape,X_test.shape)
경로 데이터세트를 사용하여 이미지를 분할하여 훈련 및 테스트 벡터를 구축할 차례입니다. 그 중 80%는 훈련용이고 20%는 테스트용입니다. Y는 기능의 실제 레이블을 나타내고, 마지막으로 img_to_array 함수를 사용하여 이미지를 배열로 변환합니다. X_train 및 X_test 벡터의 모양은 다음과 같습니다.
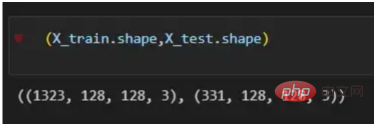
图4:X_train和X_test向量的形状
def initialize(layers_dimensions):
parameters = {}
L = len(layers_dimensions)
for l in range (1,L):
parameters['w' + str(l)] = np.random.randn(layers_dimensions[l],layers_dimensions[l-1]) / np.sqrt(layers_dimensions[l-1])
parameters['b' + str(l)] = np.zeros((layers_dimensions[l],1))
return parameters由于线性函数是z=w*x+b并且网络具有4个层,所以要初始化的参数向量是w1、w2、w3、w4、b1、b2、b3和b4。在代码中,这是通过在层维度列表的长度上循环来完成的——稍后将定义;但是在这里它是一个硬编码列表,其中包含网络中每个层中的神经元数量。
参数w和b必须使用不同的初始化方式:w必须初始化为随机小数字矩阵,b必须初始化为零矩阵。这是因为如果我们将权重初始化为零,则权重wrt(相对于)损失函数的导数将全部相同,因此后续迭代中的值将始终相同,隐藏层将全部对称,导致神经元只学习相同的几个特征。因此,我们把权重初始化为随机数,以打破这种对称性,从而允许神经元学习不同的特征。需要注意的是,偏置可以初始化为零,因为对称性已经被权重打破,并且神经元中的值都将不同。
最后,为了理解参数向量初始化时定义的形状,必须知道权重参与矩阵乘法,而偏差参与矩阵和运算(还记得z1=w1*x+b1吗?)。得益于Python广播技术,可以使用不同大小的数组进行矩阵加法运算。另一方面,矩阵乘法只有在形状兼容时才可能进行运算,如(m,n)x(n,k)=(m,k)。这意味着,第一个阵列上的列数需要与第二个阵列上行数匹配,最终矩阵将具有阵列1的行数和阵列2的列数。图5显示了神经网络上使用的所有参数向量的形状。
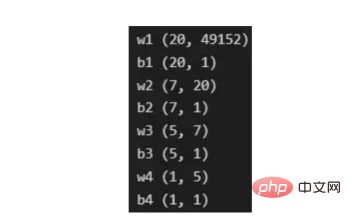
图5:参数向量的形状
在第一层中,当我们将w1参数向量乘以原始49152个输入值时,我们需要w1形状为(20,49152)*(49152,1323)=(20,1323),这是第一个隐藏层激活的形状。b1参数与矩阵乘法的结果相加(记住z1=w1*x+b1),因此我们可以将(20,1)数组添加到乘法的(20,1323)结果中,因为广播会自动考虑不匹配的形状。这一逻辑继续到下一层,因此我们可以假设w(l)形状的公式是(节点数量层l+1,节点数量层l),而b(l)的公式为(节点数量,层l+1)。
最后,我们对权重向量初始化进行重要分析。我们应该将随机初始化值除以正在初始化w参数向量的各个层上节点数量的平方根。例如,输入层有49152个节点,因此我们将随机初始化的参数除以√49152,即222,而第一个隐藏层有20个节点;所以,我们将随机初始的w2参数除以√20,即结果值为45。初始化必须保持较小,因为这是随机梯度下降的要求。
现在,参数向量已经被初始化,现在我们可以进行正向传播了。该正向传播将线性操作z=w*x+b与ReLU激活相结合,直到最后一层,当sigmoid激活函数替代ReLU激活函数时,我们得到最后一次激活的概率。线性运算的输出通常用字母“z”表示,称为预激活参数。因此,预激活参数z将是ReLU和sigmoid激活的输入。
在输入层之后,给定层L上的线性操作将是z[L]=w[L]*a[L-1]+b[L],使用前一层的激活值而不是数据输入x。线性操作和激活函数的参数都将存储在缓存列表中,用作稍后在反向传播块上计算梯度的输入。
因此,首先定义线性正向函数:
def linear_forward(activation, weight, bias): Z = np.dot(weight,activation) + bias cache = (activation, weight, bias) return Z, cache
接下来,我们来定义Sigmoid和ReLU两个激活函数。图6显示了这两个函数的图形示意。其中,Sigmoid激活函数通常用于二类分类问题,以预测二元变量的概率。这是因为S形曲线使大多数值接近0或1。因此,我们将仅在网络的最后一层使用Sigmoid激活函数来预测猫出现在图片中的概率。
另一方面,如果输入为正,ReLU函数将直接输出;否则,将输出零。这是一个非常简单的操作,因为它没有任何指数运算,有助于加快内层的计算速度。此外,与tanh和sigmoid函数不同,使用ReLU作为激活函数降低了消失梯度问题的可能性。
值得注意的是,ReLU激活函数不会同时激活所有节点,因为激活后所有负值将变为零。在整个网络中设置一些0值很重要,因为它增加了神经网络的一个理想特性——稀疏性;这意味着网络具有更好的预测能力和更少的过度拟合。毕竟,神经元正在处理有意义的信息部分。像我们的例子中一样,可能存在一个特定的神经元可以识别猫耳朵;但是,如果图像是人或风景的话,显然应该将其设置为0。
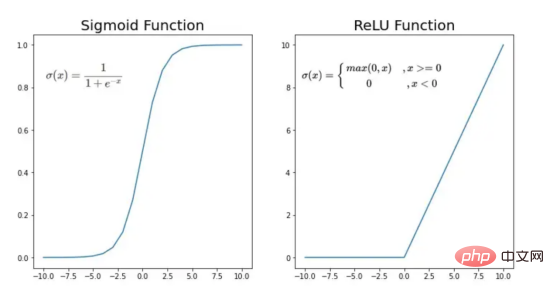
图6:Sigmoid和ReLU激活函数图形示意
def sigmoid(Z): activation = 1/ (1+ np.exp(-Z)) cache = Z return activation, cache def relu(Z): activation = np.maximum(0,Z) cache = Z return activation, cache
现在可以实现全部的激活函数了。
def sigmoid_activation(previous_activation, weight, bias): Z, linear_cache = linear_forward(previous_activation,weight, bias) activation, activation_cache = sigmoid(Z) cache = (linear_cache,activation_cache) return activation, cache def relu_activation(previous_activation, weight, bias): Z, linear_cache = linear_forward(previous_activation,weight, bias) activation, activation_cache = relu(Z) cache = (linear_cache,activation_cache) return activation, cache
最后,是时候根据前面预先计划的网络架构在一个完整的函数中整合上面的激活函数了。首先,创建缓存列表,将第一次激活函数设置为数据输入(训练向量)。由于网络中存在两个参数(w和b),因此可以将层的数量定义为参数字典长度的一半。然后,该函数在除最后一层外的所有层上循环;在最后一层应用线性前向函数,随后应用的是ReLU激活函数。
def l_layer_model_forward(data, parameters): caches = [] activation = data n_layers = len(parameters)//2 for layer in range (1,n_layers): previous_activation = activation activation, cache = relu_activation(previous_activation, weight = parameters['w' + str(layer)], bias = parameters['b' + str(layer)]) caches.append(cache) last_activation, cache = sigmoid_activation(activation, weight = parameters['w' + str(layer+1)], bias = parameters['b' + str(layer+1)]) caches.append(cache) return last_activation, caches
损失函数通过将预测的概率(最后一次激活的结果)与图像的真实标签进行比较来量化模型对给定数据的性能。如果网络使用数据进行学习,则每次迭代后成本(损失函数的结果)必须降低。在分类问题中,交叉熵损失函数通常用于优化目的,其公式如下图7所示:
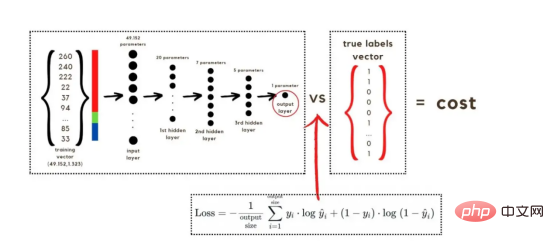
图7:神经网络的成本(损失函数的输出结果)示意图
在本例中,我们使用NumPy定义交叉熵成本函数:
def cross_entropy_cost(last_activation,true_label): m = true_label.shape[1] cost = -1/m * np.sum(np.dot(true_label,np.log(last_activation).T) + np.dot(1-true_label, np.log(1-last_activation).T)) cost = np.squeeze(cost) return cost
在反向传播模块中,我们应该在网络上从右向左移动,计算与损失函数相关的参数梯度,以便稍后更新。就像在前向传播模块中一样的顺序,接下来,我们首先介绍一下线性反向传播,然后是sigmoid和relu,最后通过一个函数整合网络架构上的所有功能。
对于给定的层L,线性部分为z[L]=w[L]*a[L-1]+b[L]。假设我们已经计算了导数dZ[L],即线性输出的成本导数,对应的公式稍后很快就会给出。但首先让我们看看下图8中dW[L]、dA[L-1]和db[L]的导数公式,以便首先实现线性后向函数。
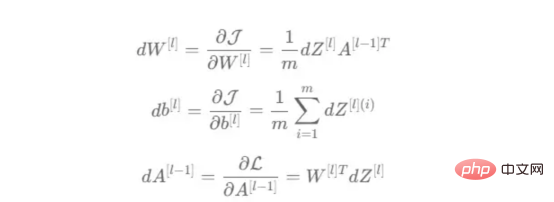
图8:成本相关权重、偏差和先前激活函数的导数
这些公式是交叉熵成本函数相对于权重、偏差和先前激活(a[L-1])的导数。本文不打算进行导数计算,但它们已经在我的另一篇文章《走向数据科学》一文中进行了介绍。
定义线性向后函数需要使用dZ作为输入,因为在反向传播中线性部分位于sigmoid或relu向后激活函数之后。在下一段代码中,将计算dZ,但为了在正向传播上遵循相同的函数实现逻辑,首先应用线性反向函数。
在执行梯度计算之前,必须从前一层加载参数权重、偏置和激活,所有这些都在线性传播期间存储在缓存中。参数m最初来自交叉熵成本公式,是先前激活函数的向量大小,可以通过previous_activation.shape[1]获得。然后,可以使用NumPy实现梯度公式的矢量化计算。在偏置梯度中,keepdims=True和axis=1参数是必要的,因为求和需要在向量的行中进行,并且必须保持向量的原始维度,这意味着dB将具有与dZ相同的维度。
def linear_backward(dZ, cache): previous_activation, weight, bias = cache m = previous_activation.shape[1] dw = 1/m * np.dot(dZ, previous_activation.T) db = 1/m * np.sum(dZ, keepdims = True, axis = 1) dpreviousactivation = np.dot(weight.T,dZ) return dpreviousactivation, dw, db
成本wrt对线性输出(dZ)公式的导数如图9所示,其中g’(Z[L])代表激活函数的导数。
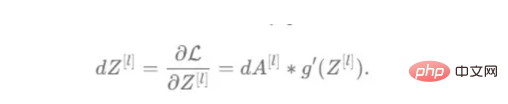
图9——线性输出成本的导数。
因此,必须首先计算Sigmoid函数和ReLU函数的导数。在ReLU中,如果该值为正,则导数为1;否则,未定义。但是,为了计算ReLU后向激活函数中的dZ,有可能只复制去激活向量(因为dactivation * 1 = dactivation),并在z为负时将dZ设置为0。对于Sigmoid函数s,其导数为s*(1-s),将该导数乘以去激活,矢量dZ在Sigmoid向后函数中实现。
def relu_backward(dactivation, cache): Z = cache dZ = np.array(dactivation, copy=True) dZ[Z <= 0] = 0 return dZ def sigmoid_backward(dactivation, cache): Z = cache s = 1/(1+np.exp(-Z)) dZ = dactivation * s * (1-s) return dZ
现在可以实现linear_activation_backward函数。
def linear_activation_backward(dactivation, cache, activation): linear_cache, activation_cache = cache if activation == 'relu': dZ = relu_backward(dactivation, activation_cache) dprevious_activation, dw, db = linear_backward(dZ,linear_cache) elif activation == 'sigmoid': dZ = sigmoid_backward(dactivation, activation_cache) dprevious_activation, dw, db = linear_backward(dZ,linear_cache) return dprevious_activation, dw, db
首先,必须从缓存列表中检索线性缓存和激活缓存。然后,对于每一次激活,首先运行activation_backward函数,获得dZ,然后将其作为输入,与线性缓存结合,用于linear_backward函数。最后,函数返回dW、dB和dprevious_activation梯度。请记住,这是正向传播的逆序,因为我们在网络上从右向左传播。
现在,我们可以为整个网络实现后向传播函数了。该函数将从最后一层L开始向后迭代所有隐藏层。因此,代码需要计算dAL;dAL是上次激活时成本函数的导数,以便将其用作sigmoid激活函数的linear_activation_backward函数的输入。dAL的公式如下图10所示:
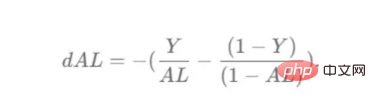
图10:最后激活函数的成本导数
现在,实现后向传播函数的一切都设置到位。
def l_layer_model_backward(last_activation, true_labels, caches):
gradients = {}
n_layers = len(caches)
true_labels = true_labels.reshape(last_activation.shape)
dlast_activation =-(np.divide(true_labels, last_activation) - np.divide(1 - true_labels, 1 - last_activation))
current_cache = caches[n_layers-1]
dprevious_activation, dw_temp, db_temp = linear_activation_backward(dlast_activation,current_cache,'sigmoid')
gradients["da" + str(n_layers-1)] = dprevious_activation
gradients["dw" + str(n_layers)] = dw_temp
gradients["db" + str(n_layers)] = db_temp
for layer in reversed(range(n_layers-1)):
current_cache = caches[layer]
dprevious_activation, dw_temp, db_temp = linear_activation_backward(gradients["da" + str(layer + 1)],current_cache,'relu')
gradients["da" + str(layer)] = dprevious_activation
gradients["dw" + str(layer+1)] = dw_temp
gradients["db" + str(layer+1)] = db_temp
return gradients首先,创建梯度字典。网络的层数是通过获取缓存字典的长度来定义的,因为每个层在前向传播块期间都存储了其线性缓存和激活缓存,因此缓存列表长度与层数相同。稍后,该函数将遍历这些层的缓存,以检索线性激活反向函数的输入值。此外,真正的标签向量(Y_train)被重构为与上一次激活的形状相匹配的维度,因为这是dAL计算中一个除以另一个的要求,即代码的下一行。
创建current_cache对象并将其设置为检索最后一层的线性缓存和激活缓存(请记住,python索引从0开始,因此最后一层是n_layers-1)。然后,到最后一层,在linear_activation_backward函数上,激活缓存将用于sigmoid_backward函数,而线性缓存将作为linear_backward的输入。最后,该函数收集函数的返回值并将它们分配给梯度字典。在dA的情况下,因为计算的梯度公式来自于先前的激活,所以有必要在索引上使用n_layer-1来分配它。在该代码块之后,计算网络的最后一层的梯度。
按照网络的反向顺序,下一步是在线性层向relu层上反向循环并计算其梯度。但是,在反向循环期间,linear_activation_backward函数必须使用“relu”参数而不是“sigmoid”,因为需要为其余层调用relu_backward函数。最后,该函数返回计算的所有层的dA、dW和dB梯度,并完成反向传播。
随着梯度的计算,我们将通过用梯度更新原始参数以向成本函数的最小值移动来结束梯度下降。
def update_parameters(parameters, gradients, learning_rate): parameters = parameters.copy() n_layers = len(parameters) // 2 for layer in range (n_layers): parameters["w" + str(layer+1)] = parameters["w" + str(layer+1)]- learning_rate * gradients["dw" + str(layer+1)] parameters["b" + str(layer+1)] = parameters["b" + str(layer+1)]- learning_rate * gradients["db" + str(layer+1)] return parameters
该函数通过在层上循环并将w和b参数的原始值减去学习率输入乘以相应的梯度来实现。乘以学习率是控制每次更新模型权重时响应于估计误差改变网络参数w和b的程度的方法。
最后,我们实现了计算梯度下降优化所需的所有函数,从而可以对训练和测试向量进行预处理,为训练做好准备。
初始化函数的layers_dimensions输入必须进行硬编码,这是通过创建一个包含每个层中神经元数量的列表来实现的。随后,必须将X_train和X_test向量展平,以作为网络的输入,如图11所示。这可以通过使用NumPy函数重构来完成。此外,有必要将X_train和X_test值除以255,因为它们是以像素为单位的(范围从0到255),并且将值标准化为0到1是一个很好的做法。这样,数字会更小,计算速度更快。最后,Y_train和Y_test被转换为数组,并被展平。
layers_dimensions = [49152, 20, 7, 5, 1]
X_train_flatten = X_train.reshape(X_train.shape[0], -1).T
X_test_flatten = X_test.reshape(X_test.shape[0], -1).T
X_train = X_train_flatten/255.
X_test = X_test_flatten/255.
y_train = np.array(y_train)
y_test = np.array(y_test)
Y_train = y_train.reshape(-1,1).T
Y_test = y_test.reshape(-1,1).T
print(f'X train shape: {X_train.shape}')
print(f'Y train shape: {Y_train.shape}')
print(f'X test shape: {X_test.shape}')
print(f'Y test shape: {Y_test.shape}')这些是训练和测试向量的最终形状打印结果:
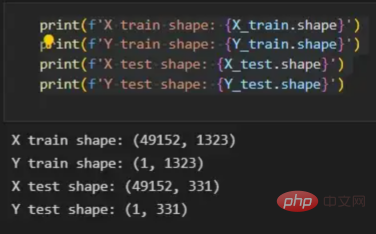
图11:训练和测试向量的形状大小
有了所有的函数,只需要将它们组织成一个循环来创建训练迭代即可。
def l_layer_model(X, Y, layers_dimensions, learning_rate = 0.0075, iterations = 3000, print_cost=False):
costs = []
parameters = initialize(layers_dimensions)
for i in range(0, iterations):
last_activation, caches = l_layer_model_forward(X, parameters)
cost = cross_entropy_cost(last_activation, Y)
gradients = l_layer_model_backward(last_activation, Y, caches)
parameters = update_parameters(parameters, gradients, learning_rate)
if print_cost and i % 50 == 0 or i == iterations - 1:
print(f"Cost after iteration {i}: {np.squeeze(cost)}")
if i % 100 == 0 or i == iterations:
costs.append(cost)
return parameters, costs但首先,创建一个空列表来存储cross_entropy_cost函数的成本输出,并初始化参数,因为这必须在迭代之前完成一次,因为这些参数将由梯度更新。
现在,在输入的迭代次数上创建循环,以正确的顺序调用实现的函数:l_layer_model_forward、cross_entropy_cost、l_layer_mmodel_backward和update_parameters。最后,是一个每50次迭代或最后一次迭代打印一次成本的条件语句。
调用函数2500次迭代的形式如下:
parameters, costs = l_layer_model(X_train, Y_train, layers_dimensions, iterations = 2500, print_cost = True)
调用训练函数的代码
下面输出展示了成本从第一次迭代的0.69下降到最后一次迭代的0.09。
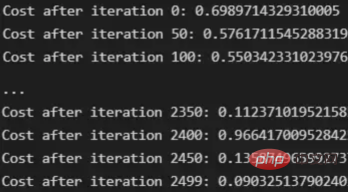
图12:成本输出值越来越小
这意味着,在NumPy中开发的梯度下降函数优化了训练过程中的参数,这必将导致更好的预测结果,从而降低了成本。
训练结束以后,接下来我们可以检查训练后的模型是如何预测测试图像标签的。
通过使用训练的参数,该函数运行X_test向量的正向传播以获得预测,然后将其与真标签向量Y_test进行比较以返回精度。
def predict(X, y, parameters):
m = X.shape[1]
p = np.zeros((1,m))
probs, _ = l_layer_model_forward(X, parameters)
for i in range(0, probs.shape[1]):
if probs[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
print("Accuracy: "+ str(np.sum((p == y)/m)))
return p
pred_test = predict(X_test, Y_test , parameters)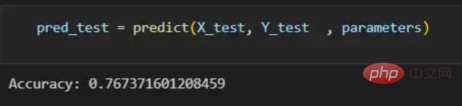
图13:调用预测函数
该模型在测试图像上检测猫的准确率达到了77%。考虑到仅使用NumPy构建网络,这已经是一个相当不错的准确性了。将新图像添加到训练数据集、增加网络的复杂性或使用数据增强技术将现有训练图像转换为新图像都是提高准确性的可能方案。
最后,值得再次强调的是,当我们深入数学基础时,准确性并不是重点。这正是本文所强调的。努力学习神经网络的基础知识将为以后深入学习神经网络应用的迷人世界奠定扎实的基础。真诚希望您继续深入下去!
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Behind the Scenes of a Deep Learning Neural Network for Image Classification,作者:Bruno Caraffa
위 내용은 이미지 분류를 위한 딥러닝 신경망의 실제 적용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



