
DeepRec(PAI-TF)는 Alibaba Group의 통합 오픈 소스 추천 엔진(https://github.com/alibaba/DeepRec)으로 주로 희소 모델 훈련 및 예측에 사용되며 수천억 개의 기능과 기능을 지원할 수 있습니다. 초대형 희소 훈련은 훈련 성능과 효과 측면에서 분명한 이점을 가지고 있습니다. 현재 DeepRec은 Taobao 검색, 추천, 광고 및 기타 시나리오를 지원하며 Taobao, Tmall, Alimama, Amap 및 기타 비즈니스에서 널리 사용되고 있습니다. .
인텔은 2019년부터 Alibaba PAI 팀과 긴밀히 협력하여 Intel 인공 지능(AI) 기술을 DeepRec에 적용하고 연산자, 하위 그래프, 런타임, 프레임워크 레이어 및 모델 등을 타겟팅해 왔습니다. Intel의 소프트웨어 및 하드웨어 이점은 Alibaba가 내부 및 외부 AI 비즈니스 성과를 가속화하는 데 도움이 됩니다.
현재 주류 오픈 소스 엔진은 여전히 초대형 스파스 훈련 시나리오를 지원하는 데 특정 제한 사항이 있습니다. 예를 들어, 온라인 교육을 지원하지 않고, 기능을 동적으로 로드할 수 없으며, 온라인 배포 반복이 불편합니다. 특히 비즈니스 요구 사항을 충족하기 어려운 성능 문제가 특히 분명합니다. 위의 문제를 해결하기 위해 DeepRec은 TensorFlow1.15를 기반으로 하는 희소 모델 시나리오에 대해 심층적으로 사용자 정의되고 최적화되었습니다. 주요 조치에는 다음 세 가지 범주가 포함됩니다.
모델 효과: 주로 EmbeddingVariable(EV)을 추가합니다. ) 동적 탄성 기능과 Adagrad Optimizer를 개선하여 최적화를 달성합니다. EV 기능은 기본 변수 크기 추정의 어려움 및 기능 충돌과 같은 문제를 해결하고 기능 허용 및 제거 전략과 같은 풍부한 고급 기능을 제공하는 동시에 빈도에 따라 핫 및 콜드 기능 차원을 자동으로 구성합니다. 특징 발생, 추가 고주파 특징의 표현력은 과잉 맞춤을 완화하고 희소 모델의 효과를 크게 향상시킬 수 있습니다.
훈련 및 추론 성능: 희소 시나리오의 경우 DeepRec은 분포, 하위 그래프 측면에서 구현되었습니다. 분산 전략 최적화, 자동 파이프라인 SmartStage, 자동 그래프 융합, Embedding 및 Attention 등의 그래프 최적화, 공통 희소 연산자 최적화, 메모리 관리 최적화 등 심층적인 성능 최적화를 통해 메모리 사용량을 대폭 줄이고, 엔드투엔드 훈련 및 추론 성능을 가속화합니다.
배포 및 제공: DeepRec은 증분 모델 내보내기 및 로딩을 지원하여 10TB급 초대형 모델의 분 단위 온라인 교육 및 업데이트를 지원하여 높은 비즈니스 요구 사항을 충족합니다. 희박성을 목표로 하는 적시성 요구 사항 DeepRec은 다중 레벨 하이브리드 스토리지(최대 4레벨 하이브리드 스토리지, 즉 HBM+DRAM+PMem+SSD) 기능을 제공합니다. 비용을 절감하면서 대형 모델의 성능을 향상시킵니다.
Intel과 Alibaba PAI 팀 간의 긴밀한 협력은 위의 세 가지 고유한 이점을 달성하는 데 중요한 역할을 했습니다. DeepRec의 세 가지 주요 장점은 Intel 기술의 큰 가치를 완전히 반영합니다. :
성능 최적화 측면에서 Intel의 초대형 클라우드 소프트웨어 팀은 Alibaba와 긴밀히 협력하여 Intel® Xeon을 최대한 활용할 수 있도록 연산자, 하위 그래프, 프레임워크, 런타임 및 기타 수준에서 CPU 플랫폼을 최적화합니다. ® 확장 가능한 프로세서의 다양한 새로운 기능은 하드웨어 이점을 최대한 활용할 수 있습니다. CPU 플랫폼에서 DeepRec의 사용 편의성을 향상시키기 위해
, modelzoo는 대부분의 주류 권장 모델을 지원하도록 구축되었으며, DeepRec의 고유한 EV 기능이 이러한 모델에 적용되어 즉시 사용 가능한 사용자 경험을 제공합니다.동시에 스토리지 및 KV 조회 작업을 위한 초대형 희소 학습 모델 EV의 특별한 요구에 부응하여 인텔 Optane 혁신 센터 팀은 메모리 관리 및 스토리지 솔루션을 지원하고 협력합니다. 대용량 메모리와 저렴한 비용의 요구 사항을 충족하는 DeepRec 다중 레벨 하이브리드 스토리지 솔루션
프로그래머블 솔루션 부문 팀은 FPGA를 사용하여 임베딩용 KV 검색 기능을 구현하는 동시에 임베딩 쿼리 기능을 크게 향상시킵니다. , 더 많은 CPU 리소스를 해제할 수 있습니다. 시스템 관점에서 CPU, PMem 및 FPGA의 다양한 하드웨어 특성과 결합된 Intel의 소프트웨어 및 하드웨어 장점은 다양한 요구 사항에 맞게 완전히 활용될 수 있습니다. 이를 통해 Alibaba의 AI 비즈니스에서 DeepRec 구현을 가속화하고 전체 스파스에 더 나은 솔루션을 제공할 수 있습니다. 시나리오 비즈니스 생태계.
Intel® DL Boost는 DeepRec에 핵심 성능 가속화를 제공합니다Intel® DL Boost(Intel® Deep Learning Acceleration)는 DeepRec을 최적화하며 주로 프레임워크 최적화 및 연산자 최적화, 하위 그래프 최적화에 반영됩니다. 및 모델 최적화 4가지 레벨.
Intel® Xeon® Scalable 프로세서가 등장한 이후 Intel은 AVX 256에서 AVX-512로 업그레이드하여 AVX 기능을 두 배로 향상시켰습니다. 딥 러닝 훈련 및 추론 기능, 2세대 Intel®에 DL Boost_VNNI 도입 Strong® Scalable 프로세서 이후 Intel은 딥 러닝 훈련 및 추론 성능을 더욱 향상시키기 위해 BFloat16(BF16) 데이터 유형을 지원하는 명령어 세트를 출시했습니다. 하드웨어 기술의 지속적인 혁신과 개발을 통해 인텔은 차세대 Xeon® Scalable 프로세서에 새로운 AI 처리 기술을 출시하여 VNNI 및 BF16의 기능을 1차원 벡터에서 2차원 매트릭스로 더욱 향상시킬 것입니다. 위에서 언급한 하드웨어 명령어 세트 기술은 DeepRec의 최적화에 적용되어 다양한 컴퓨팅 요구에 따라 다양한 하드웨어 기능을 사용할 수 있도록 하며, Intel® AVX-512 및 BF16이 희소 교육 및 추론 가속에 매우 적합하다는 것도 확인했습니다. 시나리오.
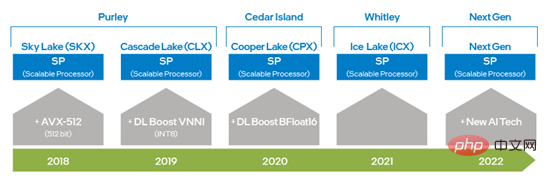
그림 1 Intel x86 플랫폼 AI 기능 진화 다이어그램
DeepRec은 Intel의 오픈 소스 크로스 플랫폼을 통합합니다. form 깊이 학습 성능 가속화 라이브러리 oneDNN(oneAPI Deep Neural Network Library), oneDNN의 원래 스레드 풀을 수정하고 이를 DeepRec의 Eigen 스레드 풀로 통합하면 스레드 풀 전환 비용이 줄어들고 서로 다른 스레드 풀 간의 경쟁으로 인한 성능 저하를 방지할 수 있습니다. oneDNN은 검색 및 프로모션 모델에 대한 강력한 성능 지원을 제공할 수 있는 MatMul, BiasAdd, LeakyReLU 및 기타 일반 연산자를 포함한 다수의 주류 연산자에 대한 성능 최적화를 구현했으며 oneDNN의 연산자는 BF16 데이터 유형도 지원합니다. BF16 명령 세트가 장착된 3세대 Intel® Xeon® 확장 가능 프로세서와 함께 사용하면 모델 훈련 및 추론 성능을 크게 향상시킬 수 있습니다.
DeepRec 컴파일 옵션에서 "--config=mkl_threadpool"만 추가하면 oneDNN 최적화를 쉽게 활성화할 수 있습니다.
oneDNN을 사용하면 계산 집약적인 연산자의 성능을 크게 향상시킬 수 있지만 검색 광고 추천 모델에는 Select, DynamicStitch, Transpose, Tile, SparseSegmentMean 등. 이러한 연산자의 기본 구현 대부분에는 메모리 액세스 최적화를 위한 특정 공간이 있으며 대상 솔루션을 사용하여 추가 최적화를 달성할 수 있습니다. 이 최적화는 AVX-512 지침을 호출하며 컴파일 명령에 "--copt=-march=skylake-avx512"를 추가하여 켤 수 있습니다. 다음은 최적화 사례 중 두 가지입니다.
Case 1: Select 연산자의 구현 원리는 조건에 따라 요소를 선택하는 것입니다. 이때 그림 2의 왼쪽 그림과 같이 Intel® AVX-512의 마스크 로드 방법을 사용할 수 있습니다. 다수의 판단으로 인한 시간 오버헤드를 줄이고 배치 선택을 통해 데이터 읽기 및 쓰기 효율성을 높이기 위해 최종 온라인 테스트에서 성능이 크게 향상되었습니다.
 그림 2 연산자 최적화 사례 선택
그림 2 연산자 최적화 사례 선택
사례 2: 마찬가지로 Intel® AVX-512의 unpack 및 shuffle 명령을 사용하여 전치 연산자를 최적화할 수 있습니다. 즉, 작은 행렬을 통해 행렬을 전치할 수 있습니다. 블록은 그림 2의 오른쪽 그림과 같이 최종 워프 위의 테스트를 통해 성능 향상도 매우 중요하다는 것을 알 수 있습니다.
하위 그래프 최적화
CPU 플랫폼을 기반으로 Intel은 WDL, DeepFM, DLRM, DIEN, DIN, DSSM, BST, MMoE, DBMTL, ESMM과 같은 여러 주류 모델을 포괄하는 DeepRec에 대한 고유한 권장 사항을 구축했습니다. 리콜, 정렬, 다목적 등 다양한 공통 시나리오와 하드웨어 플랫폼의 성능 최적화를 포함하는 모델 수집. 다른 프레임워크와 비교하여 이러한 모델은 오픈 소스 데이터 세트를 기반으로 CPU 플랫폼에서 뛰어난 성능을 제공합니다. 크리테오가 홍보하는 것처럼요. 가장 뛰어난 성능은 의심할 여지 없이 혼합 정밀도 BF16 및 Float32의 최적화된 구현입니다. 희소 장면의 고성능 및 고정밀 요구 사항을 충족하기 위해 DeepRec에 DNN 레이어의 데이터 유형을 사용자 정의하는 기능을 추가하여 최적화를 활성화하는 방법은 그림 3과 같습니다. 현재 변수의 데이터 유형은 다음과 같이 유지됩니다. 그라디언트 누적으로 인한 정확도 저하를 방지하기 위해 사용되는 Keep_weights를 통한 Float32, 그리고 두 가지 캐스트 연산을 사용하여 DNN 연산을 BF16으로 변환하여 계산합니다. 3세대 Intel® Xeon® Scalable의 BF16 하드웨어 컴퓨팅 장치에 의존합니다. 프로세서를 사용하면 DNN 컴퓨팅 성능이 크게 향상되는 동시에 그래프 융합 캐스트 작업을 통해 성능이 더욱 향상됩니다. 그림 3 혼합 정밀도 최적화를 켜는 방법 BF16이 모델 정확도 AUC(Area Under Curve) 및 성능에 미치는 영향을 표시할 수 있도록 하기 위해 Gsteps/ s, 기존 modelzoo의 경우 모델은 모두 위의 혼합 정밀도 최적화 방법을 적용합니다. Alibaba Cloud 플랫폼에서 DeepRec을 사용하는 Alibaba PAI 팀의 평가에 따르면 Criteo 데이터 세트를 기반으로 [1] BF16을 사용하여 최적화한 후 모델 WDL 정확도 또는 AUC가 FP32에 근접할 수 있습니다. , BF16 모델의 경우 훈련 성능이 1.4배 향상되는데 이는 놀라운 효과입니다. 향후 CPU 플랫폼의 하드웨어 장점을 더욱 활용하기 위해, 특히 새로운 하드웨어 기능의 효과를 극대화하기 위해 DeepRec은 최적화 연산자, 주의 사항 등 다양한 각도에서 최적화를 구현해 나갈 것입니다. 희박한 장면을 위한 고성능 CPU 솔루션을 만들기 위해 하위 그래프 및 다중 목표 모델 추가 등을 수행합니다. PMem을 사용하여 임베딩 스토리지 구현 초대규모 희소 모델 교육 및 예측 엔진용(천억 개의 특징, 수조 개의 샘플, 모델 10TB 수준), 모두 동적 무작위인 경우 스토리지에 사용되는 액세스 메모리(DRAM)는 총 소유 비용(총 소유 비용, TCO)을 크게 증가시키는 동시에 기업의 IT 운영 및 관리에 큰 부담을 안겨 구현하게 됩니다. 의 AI 솔루션이 문제에 직면합니다. PMem은 더 높은 저장 밀도와 데이터 지속성의 장점을 갖고 있으며 I/O 성능은 DRAM에 가깝고 비용은 더 저렴하여 초대형의 고성능 및 대용량 요구 사항을 완벽하게 충족할 수 있습니다. - 규모의 희소 훈련 및 예측. PMem은 메모리 모드와 앱 다이렉트 모드라는 두 가지 작동 모드를 지원합니다. 메모리 모드에서는 일반 휘발성(비영구) 시스템 스토리지와 동일하지만 비용이 저렴하고 시스템 예산을 유지하면서 더 많은 용량을 사용할 수 있으며 단일 서버에서 테라바이트급 메모리를 제공합니다. 메모리 모드, 애플리케이션에 비해 총 용량; 직접 액세스 모드는 PMem의 지속성 기능을 활용할 수 있습니다. 애플리케이션 직접 액세스 모드에서는 PMem과 그에 인접한 DRAM 메모리가 바이트 주소 지정 가능 메모리로 인식됩니다. 운영 체제는 PMem 하드웨어를 두 개의 서로 다른 장치로 사용할 수 있습니다. 하나는 FSDAX 모드이며, PMem은 블록 장치로 구성되며 사용자는 이를 수행할 수 있습니다. 사용하기 위해 파일 시스템으로 포맷합니다. 다른 하나는 DEVDAX 모드이고 PMem은 단일 문자 장치로 구동되며 커널(5.1 이상)에서 제공하는 KMEM DAX 기능을 사용하고 PMem을 휘발성으로 처리합니다. DRAM과 유사하게 더 느리고 더 큰 메모리 NUMA 노드로서 애플리케이션이 이에 투명하게 액세스할 수 있습니다. 매우 대규모의 특성 훈련에서는 가변 저장소 내장이 메모리의 90% 이상을 차지하며 메모리 용량은 병목 현상 중 하나가 됩니다. EV를 PMem에 저장하면 이러한 병목 현상이 해소되고 대규모 분산 교육의 메모리 저장 용량 향상, 대규모 모델의 교육 및 예측 지원, 여러 시스템 간의 통신 감소, 모델 교육 성능 향상 등 다양한 가치를 창출할 수 있습니다. TCO 절감. 다단계 하이브리드 스토리지 내장에서 PMem은 DRAM 병목 현상을 해결하는 탁월한 선택이기도 합니다. 현재 PMem에 EV를 저장하는 방법에는 세 가지가 있으며, 다음 세 가지 방법으로 마이크로 벤치마크, WDL 모델 및 WDL-프록시 모델을 실행할 때 성능은 EV를 DRAM에 저장하는 성능과 매우 유사하므로 의심할 여지 없이 TCO가 발생합니다. 큰 장점: 따라서 다음 최적화 계획에서는 PMem을 사용하여 모델을 저장하고 희소 모델 체크포인트 파일을 영구 메모리에 저장합니다. 여러 단계의 성능 향상을 달성하고 SSD를 사용하여 매우 큰 모델을 저장하고 복원하는 현재의 딜레마를 제거합니다. 이 작업에는 시간이 오래 걸리고 이 기간 동안 훈련 예측이 중단됩니다.
FPGA는 임베딩 조회를 가속화합니다대규모 희소 훈련 및 예측은 분산 훈련, 단일 머신 및 분산 예측, 이기종 컴퓨팅 훈련과 같은 다양한 시나리오를 다룹니다. 기존 CNN(Convolutional Neural Network) 또는 RNN(Recurrent Neural Networks)과 비교할 때 임베딩 테이블 처리라는 중요한 차이점이 있으며 이러한 시나리오의 임베딩 테이블 처리 요구 사항은 새로운 과제에 직면합니다. 멀티 스레딩을 통해 소프트웨어로 구현된 KV 엔진이 순환 병목 현상이 되었습니다. I 시리즈 FPGA를 최적화에 도입했습니다. 구현 경로는 그림 5에 나와 있습니다. : TM I 시리즈 FPGA 구현 최적화를 소개합니다. 요약 이전 기사에서는 CPU, PMem, FPGA의 다양한 하드웨어에서 DeepRec의 최적화 구현 방식을 소개하고 이를 Alibaba의 여러 내부 및 외부 비즈니스 시나리오에 성공적으로 배포했으며 명확한 엔드 투 엔드를 달성했습니다. 엔드엔드 성능 가속화는 초대형 희소 시나리오가 직면한 문제와 과제를 다양한 각도에서 해결합니다. 우리 모두 알고 있듯이 Intel은 AI 애플리케이션을 위한 다양한 하드웨어 옵션을 제공하여 고객이 동시에 보다 비용 효율적인 AI 솔루션을 선택할 수 있도록 합니다. Intel, Alibaba 및 고객은 다음을 기반으로 소프트웨어 하드웨어 혁신을 구현하기 위해 협력하고 있습니다. 다양한 하드웨어. 인텔 기술과 플랫폼의 가치를 더욱 완벽하게 실현하기 위해 협력하고 최적화합니다. 인텔은 또한 업계 파트너들과 계속 협력하여 더 깊은 협력을 발전시키고 AI 기술 배포에 지속적으로 기여하기를 희망합니다. 인텔은 제3자 데이터를 통제하거나 감사하지 않습니다. 이 내용을 검토하고 다른 출처를 참조하여 언급된 데이터가 정확한지 확인하십시오. 설명된 비용 절감 시나리오는 특정 인텔 제품이 향후 비용에 어떻게 영향을 미치고 특정 상황 및 구성에서 비용 절감을 제공할 수 있는지 보여주기 위해 작성되었습니다. 모든 상황은 다릅니다. 인텔은 비용이나 비용 절감을 보장하지 않습니다. 인텔 기술 기능과 이점은 시스템 구성에 따라 다르며 활성화하려면 활성화된 하드웨어, 소프트웨어 또는 서비스가 필요할 수 있습니다. 제품 성능은 시스템 구성에 따라 달라집니다. 어떤 제품이나 구성 요소도 완전히 안전하지는 않습니다. 자세한 내용은 원래 장비 제조업체나 소매점에서 확인하거나 intel.com을 참조하십시오. Intel, Intel 로고 및 기타 Intel 상표는 미국 및/또는 기타 국가에서 Intel Corporation 또는 그 자회사의 상표입니다. © Copyright Intel Corporation [1] https://github.com/alibaba/DeepRec/tree/main/modelzoo/를 참조하세요. WDL[2] https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101 .0.0.787c4df5FgibRE#re7p을 참조하세요. 

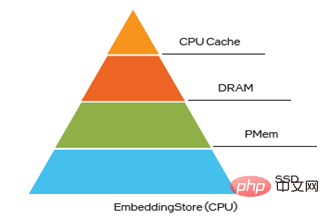 그림 4 다중 레벨 하이브리드 저장소 내장
그림 4 다중 레벨 하이브리드 저장소 내장
TM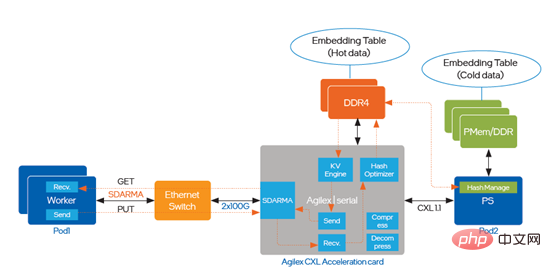
법적 고지
위 내용은 인텔은 오픈 소스 대규모 희소 모델 교육/예측 엔진 DeepRec 구축을 지원합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



