

Python에서 대규모 기계 학습 데이터 세트를 처리하는 쉬운 방법

이 기사의 대상 독자:
- 대규모 데이터 세트에서 Pandas/NumPy 작업을 수행하려는 사람들.
- Python을 사용하여 빅데이터에 대한 머신러닝 작업을 수행하려는 사람들.

이 기사에서는 .csv 형식 파일을 사용하여 Python의 다양한 작업은 물론 배열, 텍스트 파일 등과 같은 기타 형식을 보여줍니다.
대규모 기계 학습 데이터세트에 팬더를 사용할 수 없는 이유는 무엇인가요?
우리는 Pandas가 컴퓨터 메모리(RAM)를 사용하여 기계 학습 데이터 세트를 로드한다는 것을 알고 있습니다. 하지만 컴퓨터에 8GB의 메모리(RAM)가 있는데 왜 Pandas는 여전히 2GB 데이터 세트를 로드할 수 없나요? 그 이유는 Pandas를 사용하여 2GB 파일을 로드하려면 2GB RAM뿐만 아니라 더 많은 메모리가 필요하기 때문입니다. 전체 메모리 요구 사항은 데이터 세트의 크기와 해당 데이터 세트에서 수행할 작업에 따라 다르기 때문입니다.
다음은 컴퓨터 메모리에 로드된 다양한 크기의 데이터 세트를 빠르게 비교한 것입니다.
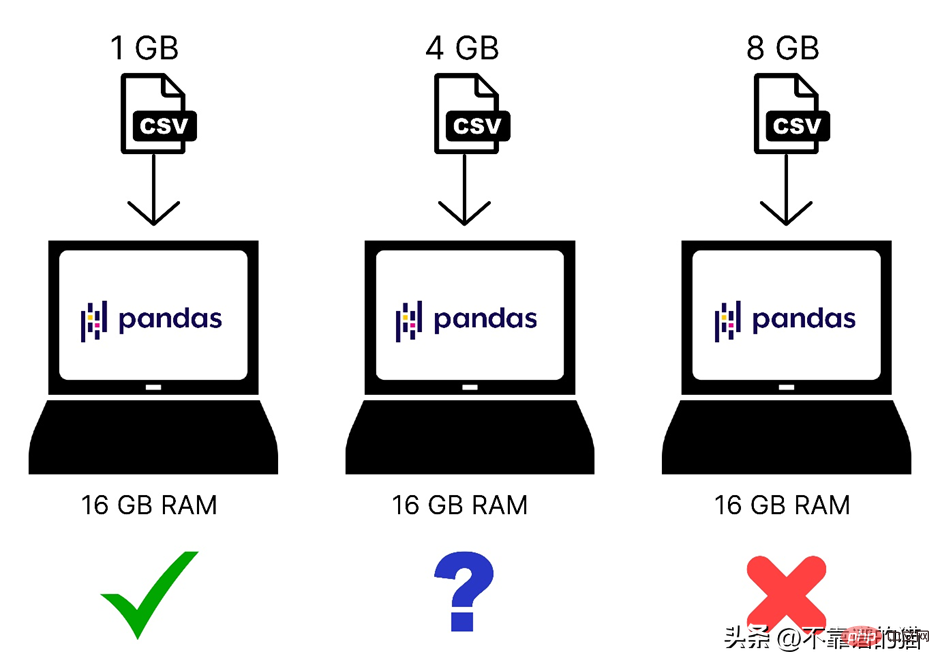
또한 Pandas는 운영 체제의 코어 하나만 사용하므로 처리 속도가 느려집니다. 즉, 팬더는 병렬성(문제를 더 작은 작업으로 나누는 것)을 지원하지 않는다고 말할 수 있습니다.
컴퓨터에 4개의 코어가 있다고 가정합니다. 다음 그림은 CSV 파일을 로드할 때 Pandas가 사용하는 코어 수를 보여줍니다.
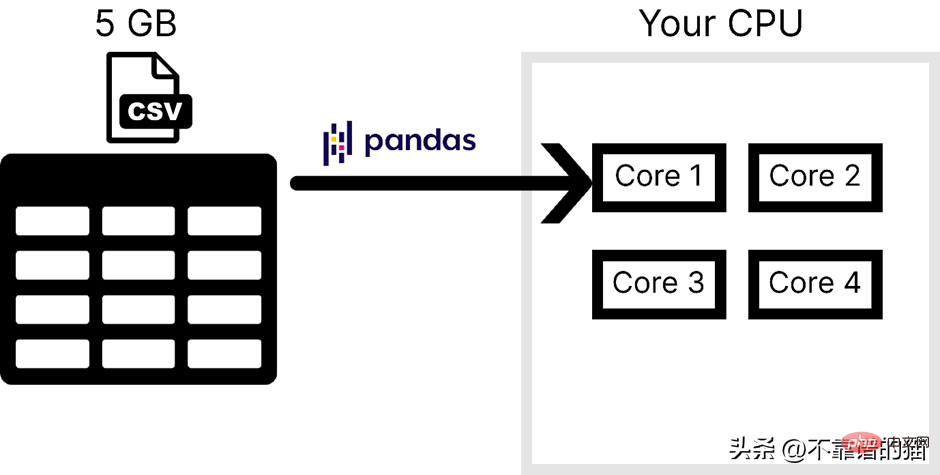
Pandas가 일반적으로 대규모 기계 학습 데이터 세트를 처리하는 데 사용되지 않는 주요 이유는 다음과 같습니다. 다음은 하나는 컴퓨터 메모리 사용량이고, 두 번째는 병렬성 부족입니다. NumPy와 Scikit-learn에서는 대규모 데이터 세트에 대해 동일한 문제가 발생합니다.
이 두 가지 문제를 해결하기 위해 Dask라는 Python 라이브러리를 사용할 수 있습니다. 이를 통해 대규모 데이터 세트에 대해 Pandas, NumPy 및 ML과 같은 다양한 작업을 수행할 수 있습니다.
Dask는 어떻게 작동하나요?
Dask는 파티션에 데이터 세트를 로드하는 반면, 팬더는 일반적으로 전체 기계 학습 데이터 세트를 데이터 프레임으로 로드합니다. Dask에서는 데이터 세트의 각 파티션이 Pandas 데이터 프레임으로 간주됩니다.
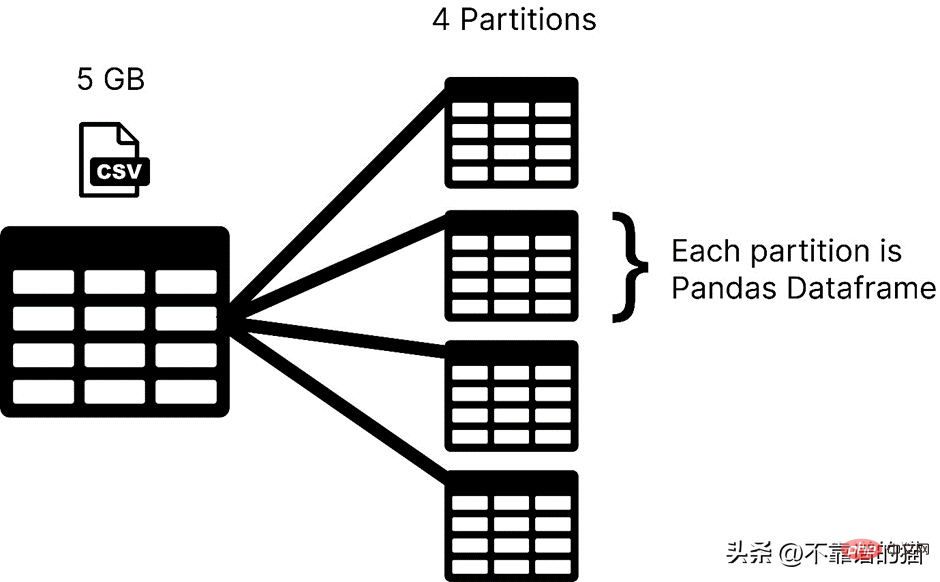
Dask는 한 번에 하나의 파티션을 로드하므로 메모리 할당 오류에 대해 걱정할 필요가 없습니다.
다음은 dask를 사용하여 컴퓨터 메모리에 다양한 크기의 기계 학습 데이터 세트를 로드하는 방법을 비교한 것입니다.
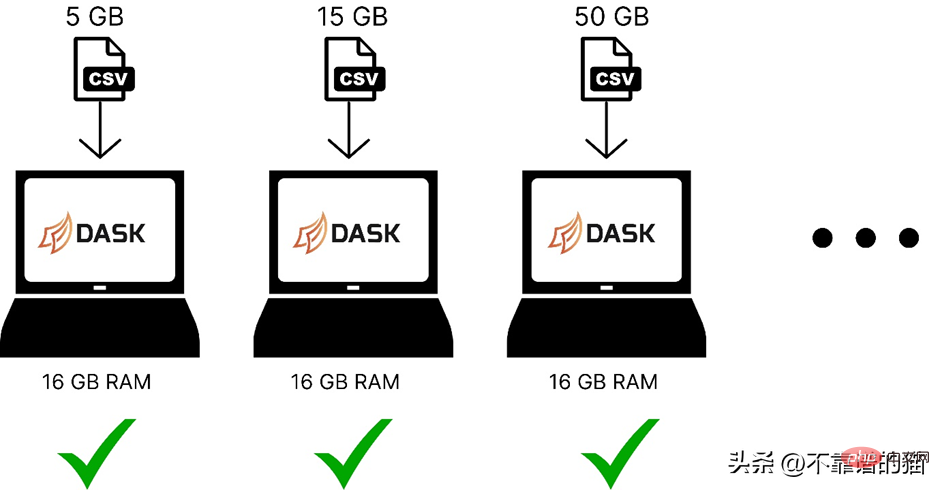
Dask는 별도의 코어를 사용하여 데이터를 여러 파티션으로 분할하여 계산을 수행하므로 병렬성 문제를 해결합니다. 데이터 세트에서 더 빠르게.
컴퓨터에 4개의 코어가 있다고 가정할 때 dask가 5GB csv 파일을 로드하는 방법은 다음과 같습니다.
dask 라이브러리를 사용하려면 다음 명령을 사용하여 설치할 수 있습니다.
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask에는 dask와 같은 여러 모듈이 있습니다. array, dask.dataframe 및 dask.distributed는 각각 해당 라이브러리(예: NumPy, pandas 및 Tornado)를 설치한 경우에만 작동합니다.
dask를 사용하여 대용량 CSV 파일을 처리하는 방법은 무엇입니까?
dask.dataframe은 대용량 csv 파일을 처리하는 데 사용됩니다. 먼저 pandas를 사용하여 8GB 크기의 데이터 세트를 가져오려고 했습니다.
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
16GB RAM 노트북에서 메모리 할당 오류가 발생했습니다.
이제 dask.dataframe을 사용하여 동일한 8GB 데이터를 가져와 보세요.
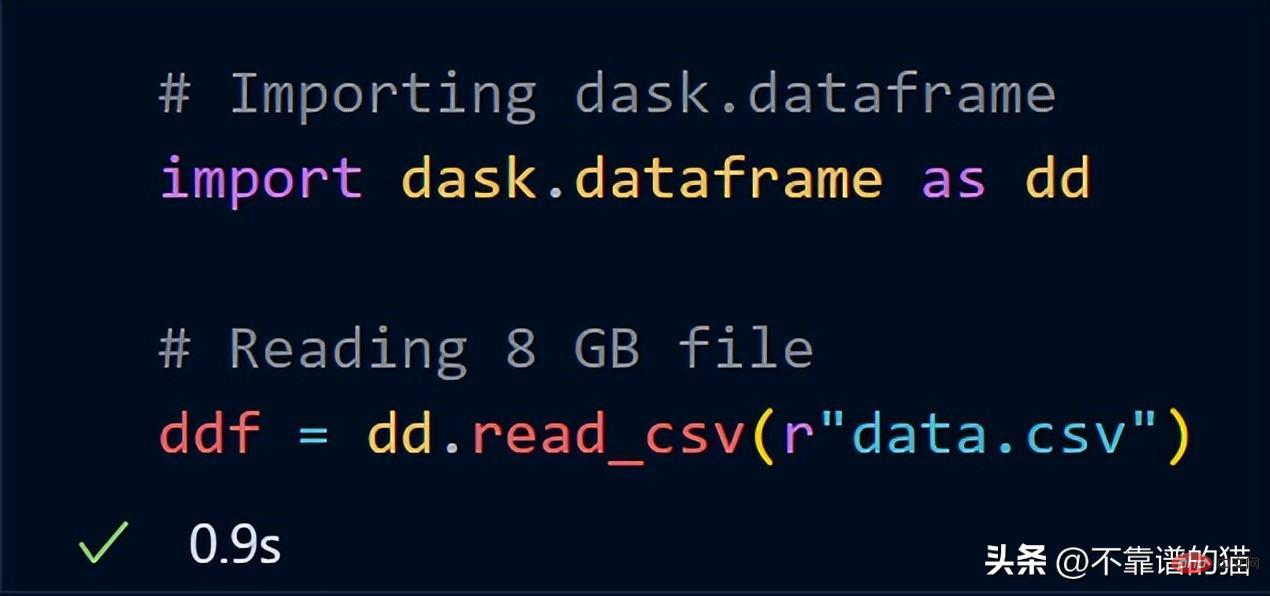
dask는 전체 8GB 파일을 ddf 변수에 로드하는 데 1초밖에 걸리지 않았습니다.
ddf 변수의 출력을 살펴보겠습니다.
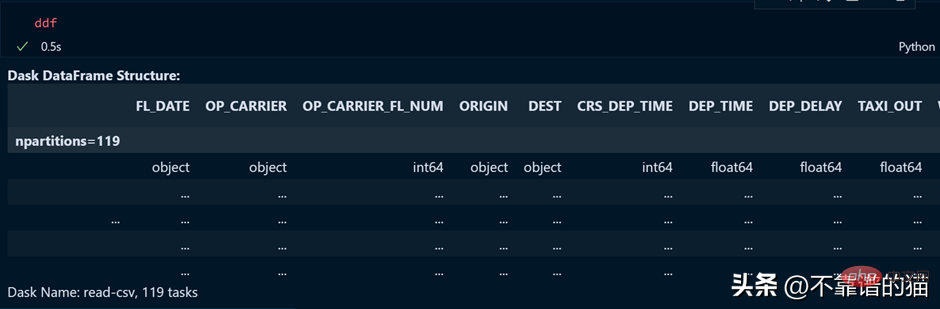
보시다시피 실행시간은 0.5초이며, 119개의 파티션으로 나누어져 나와있습니다.
다음을 사용하여 데이터프레임의 파티션 수를 확인할 수도 있습니다.
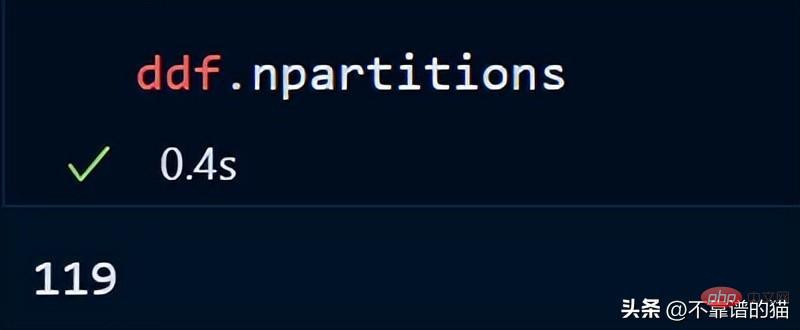
기본적으로 dask는 8GB CSV 파일을 119개의 파티션(각 파티션 크기는 64MB)에 로드했습니다. 이는 사용 가능한 파티션을 기준으로 합니다. 실제 메모리와 컴퓨터의 코어 수를 기반으로 수행됩니다.
CSV 파일을 로드할 때 blocksize 매개변수를 사용하여 나만의 파티션 수를 지정할 수도 있습니다.
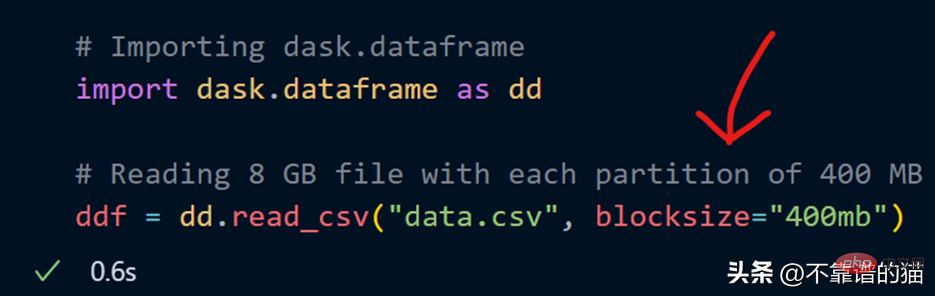
이제 문자열 값이 400MB인 blocksize 매개변수가 지정되어 각 파티션 크기가 400MB가 됩니다. 얼마나 많은 파티션이 있는지 살펴보겠습니다.
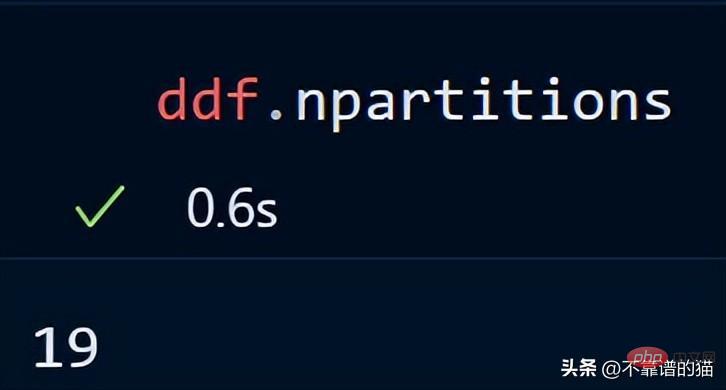
핵심 포인트: Dask DataFrames를 사용할 때 좋은 규칙 경험상 파티션을 100MB 미만으로 유지하는 것이 좋습니다.
데이터프레임의 특정 파티션은 다음을 사용하여 호출할 수 있습니다.
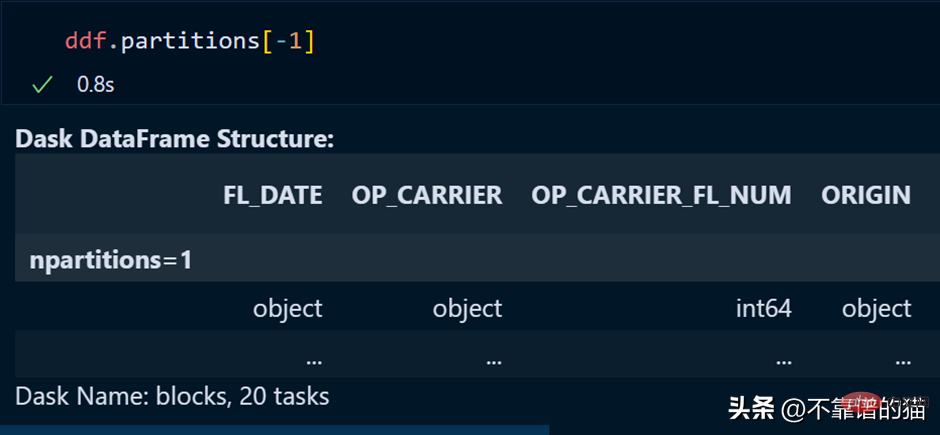
목록의 마지막 요소를 호출할 때 했던 것처럼 마지막 파티션도 음수 인덱스를 사용하여 호출할 수 있습니다.
데이터세트의 모양을 살펴보겠습니다.
len()을 사용하여 데이터세트의 행 수를 확인할 수 있습니다.
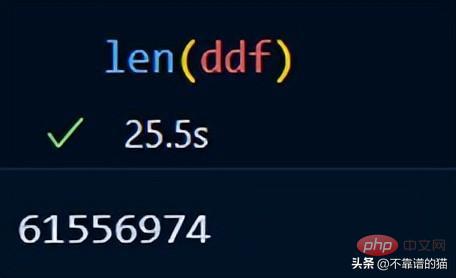
Dask에는 이미 예제 데이터세트가 포함되어 있습니다. 시계열 데이터를 사용하여 dask가 데이터 세트에서 수학적 연산을 수행하는 방법을 보여 드리겠습니다.
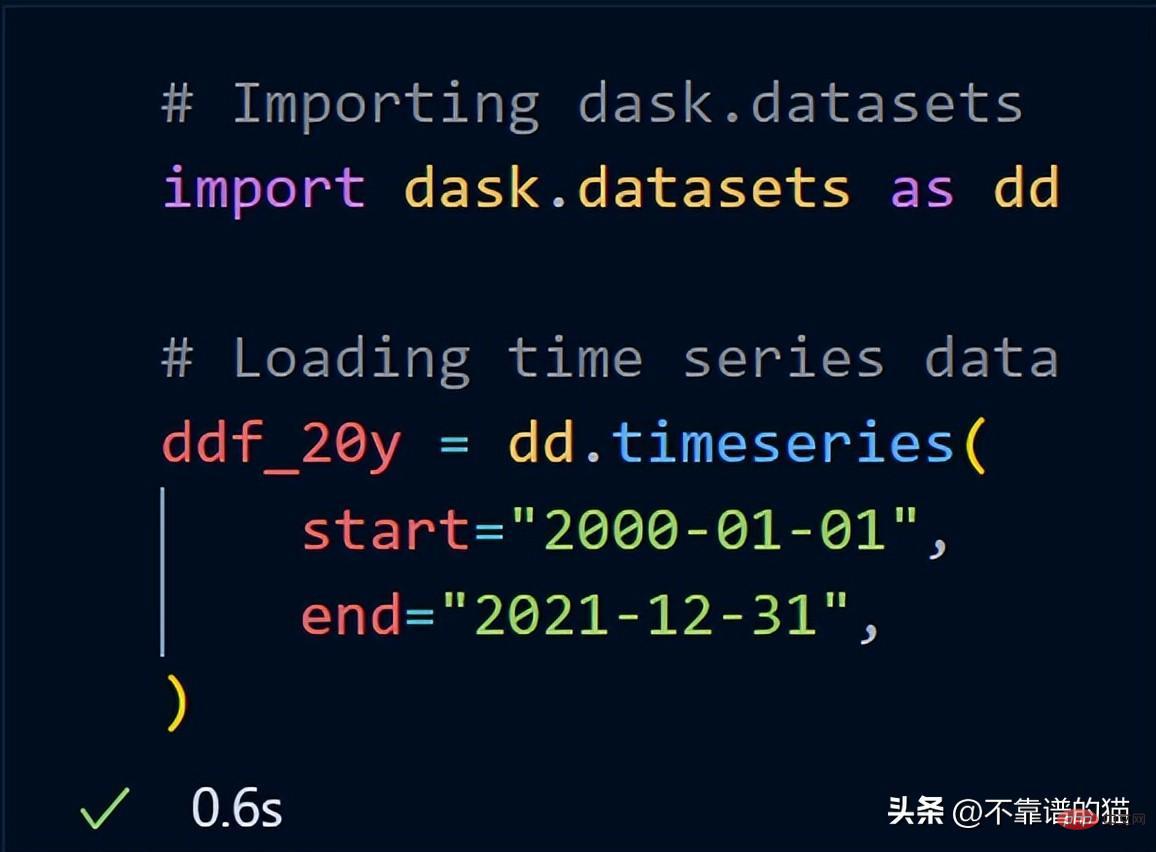
dask.datasets를 가져온 후 ddf_20y는 2000년 1월 1일부터 2021년 12월 31일까지의 시계열 데이터를 로드했습니다.
시계열 데이터의 파티션 수를 살펴보겠습니다.
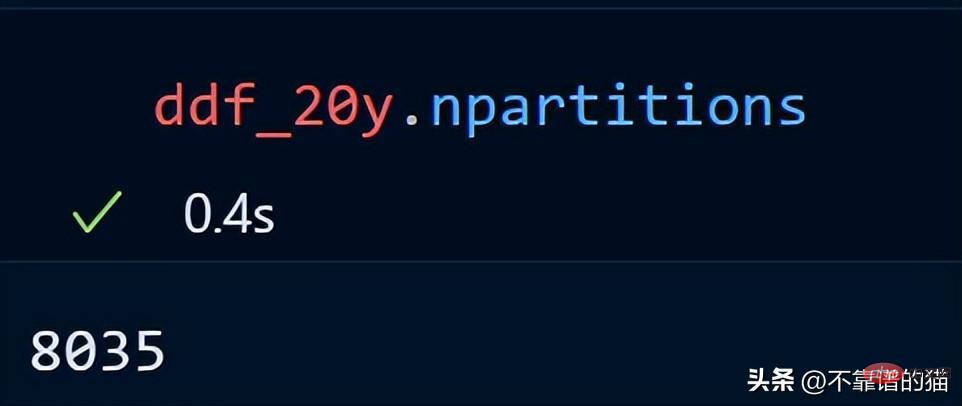
20년간의 시계열 데이터는 8035개의 파티션으로 분산되어 있습니다.
pandas에서는 head를 사용하여 데이터 세트의 처음 몇 행을 인쇄하며 dask에서도 마찬가지입니다.
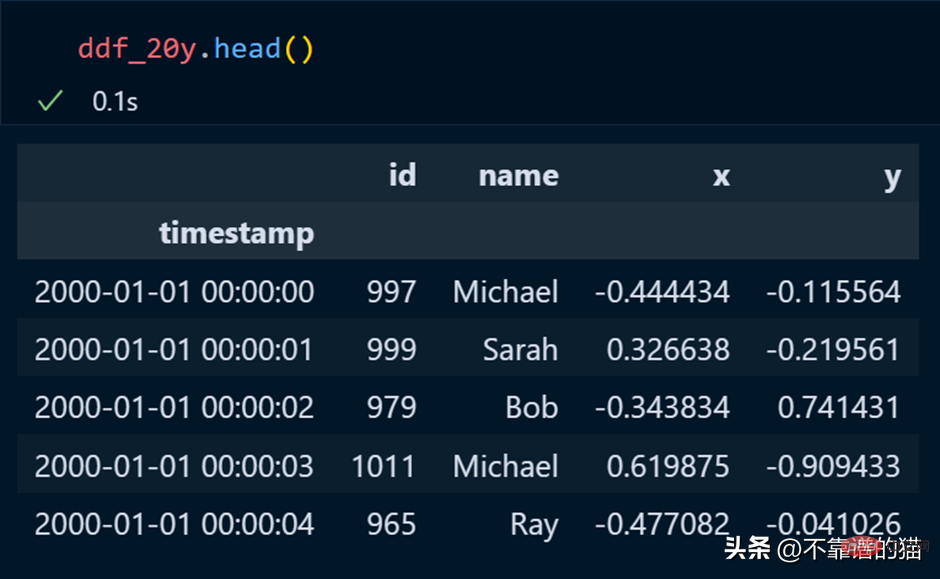
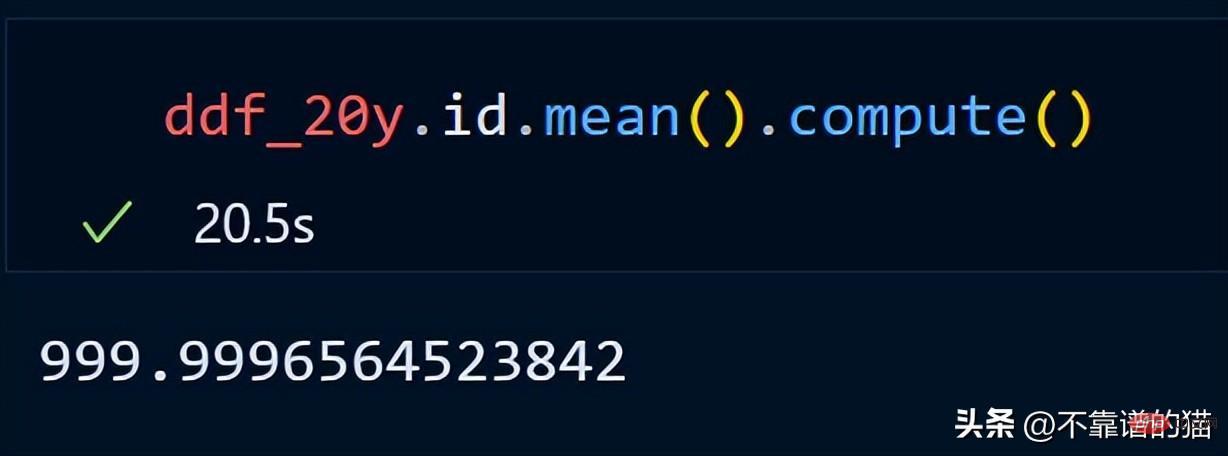
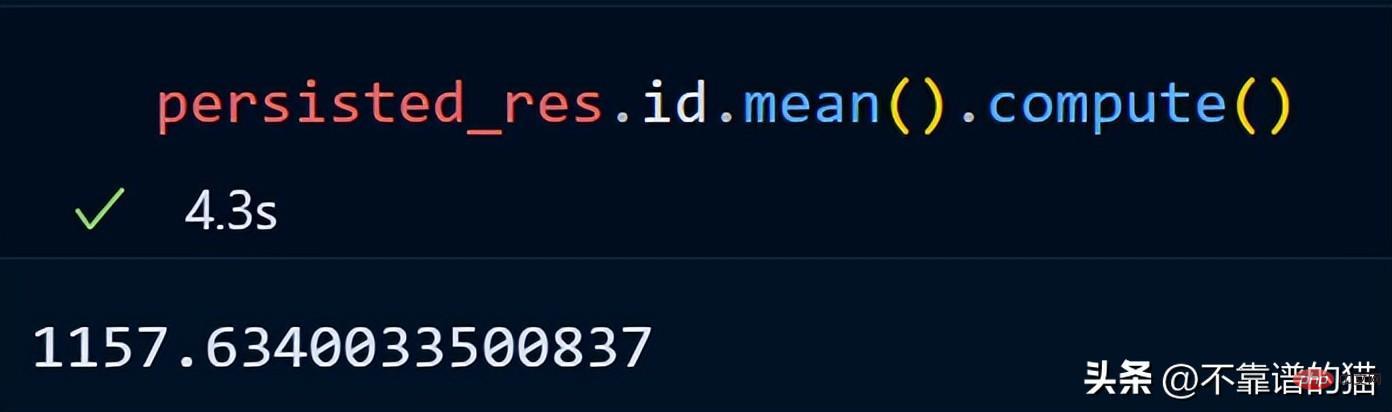
id 열의 평균을 계산해 보겠습니다.
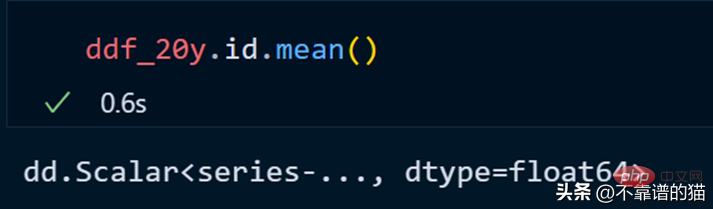
dask는 게으른 계산을 사용하기 때문에 데이터프레임의 총 행 수를 인쇄하지 않습니다(출력은 필요할 때까지 표시되지 않습니다). 출력을 표시하려면 계산 메소드를 사용할 수 있습니다.
데이터 세트의 각 열을 정규화하려고 한다고 가정하면(값을 0과 1 사이로 변환) Python 코드는 다음과 같습니다.
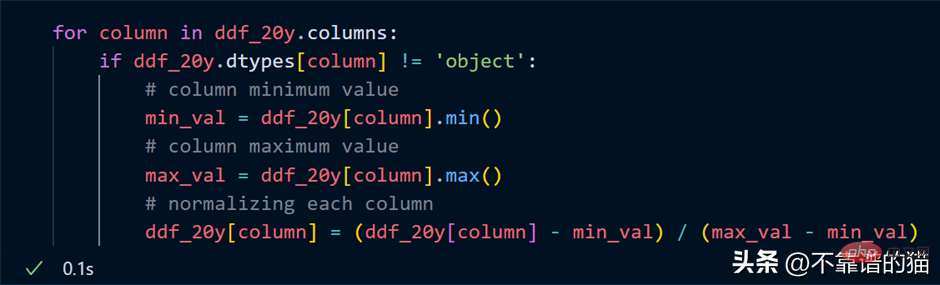
열을 반복하여 각 열의 최소 합계를 찾습니다. 열 최대값을 계산하고 간단한 수학 공식을 사용하여 이러한 열을 정규화합니다.
핵심 사항: 정규화 예에서는 실제 수치 계산이 발생한다고 생각하지 마십시오. 이는 단지 게으른 평가일 뿐입니다(필요할 때까지 출력이 표시되지 않습니다).
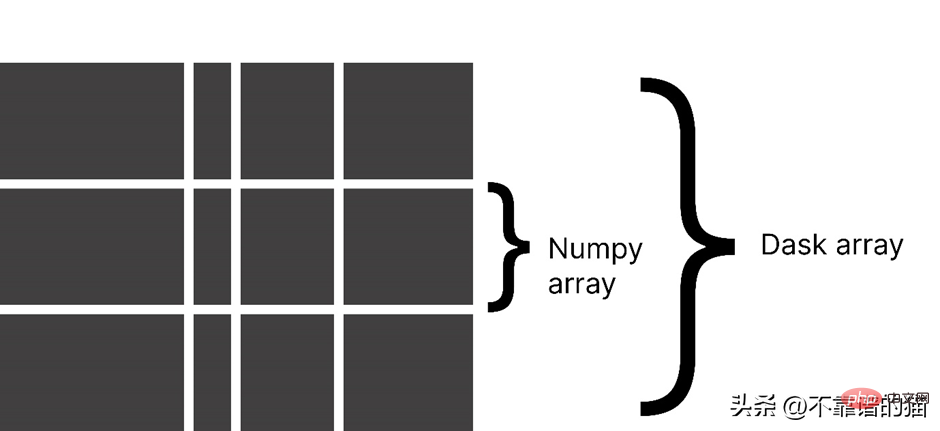
Dask 어레이를 사용하는 이유는 무엇인가요?
Dask는 배열을 작은 덩어리로 분할하며, 각 덩어리는 NumPy 배열입니다.
dask.arrays는 대규모 배열을 처리하는 데 사용됩니다. 다음 Python 코드는 dask를 사용하여 10000 x 10000 배열을 만들고 이를 x 변수에 저장합니다.
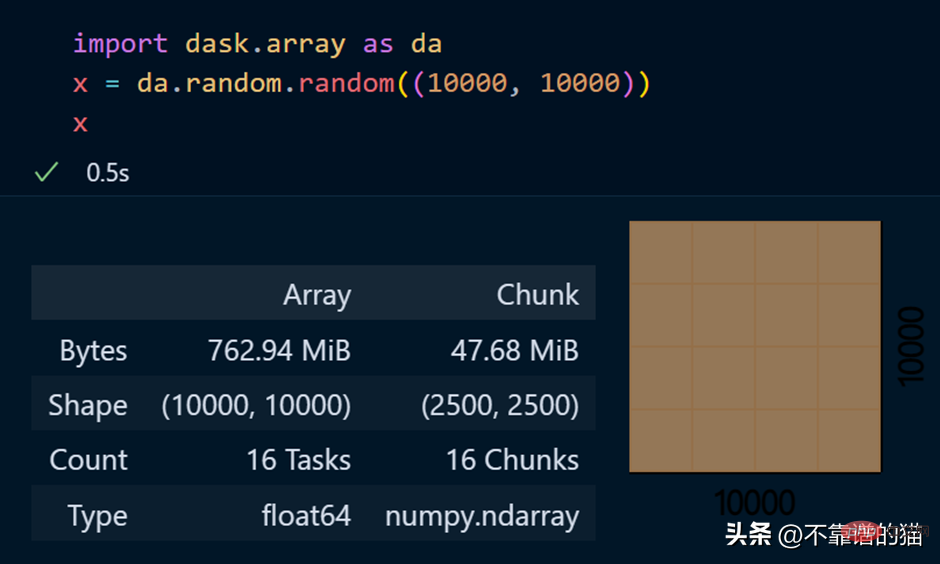
x 변수를 호출하면 배열에 대한 다양한 정보가 생성됩니다.
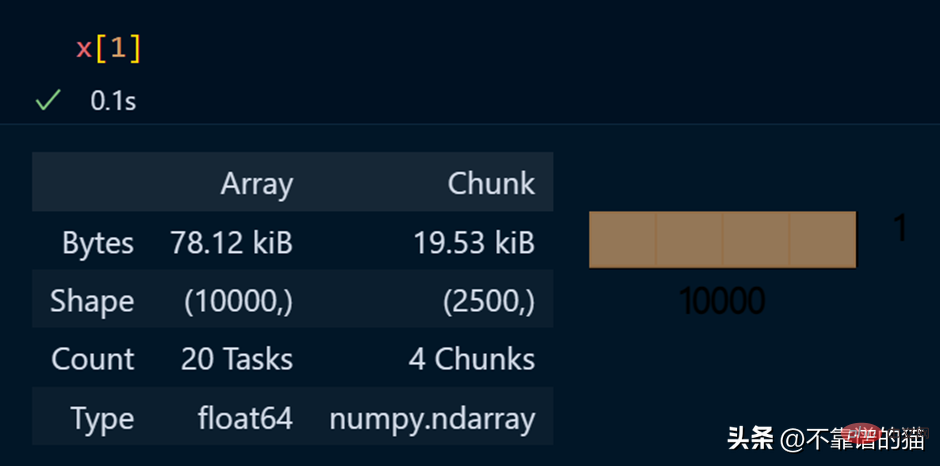
배열의 특정 요소 보기
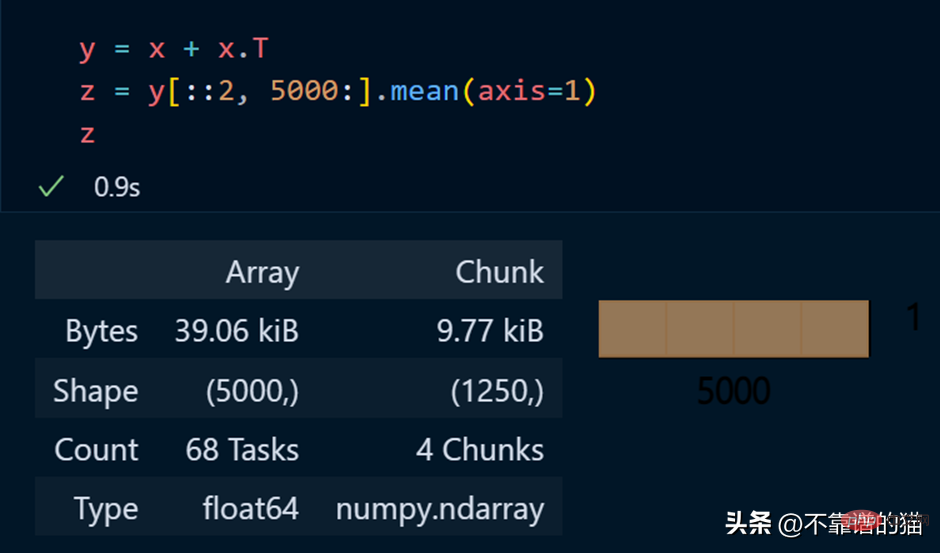
DASK 배열에서 수학 연산을 수행하는 Python 예:
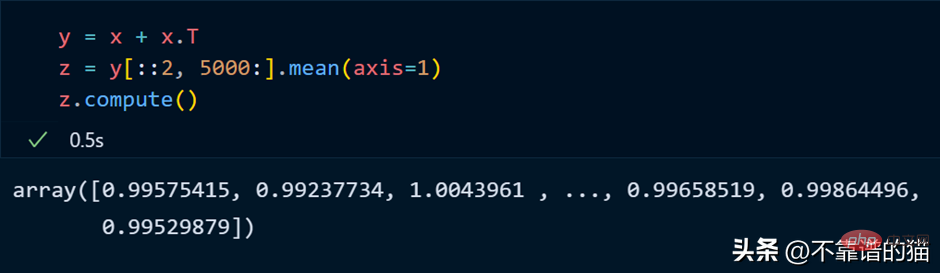
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
让我们取数据集的一个子集并计算该子集的总行数。
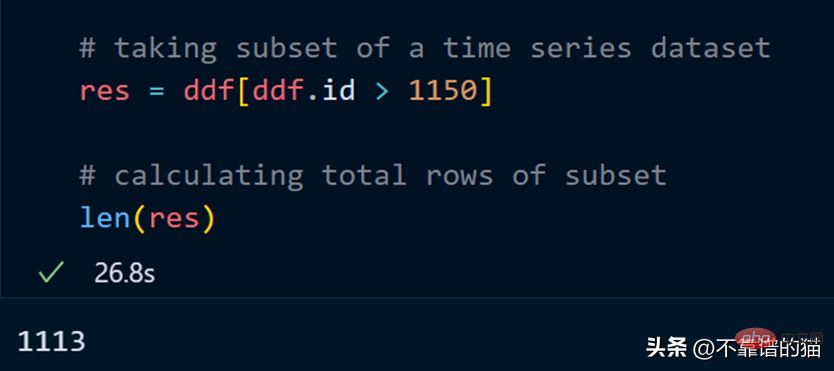
计算总行数需要 27 秒。
我们现在使用 persist 方法:
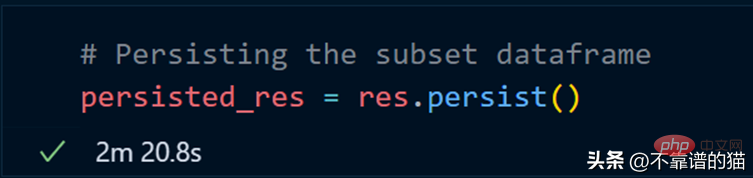
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
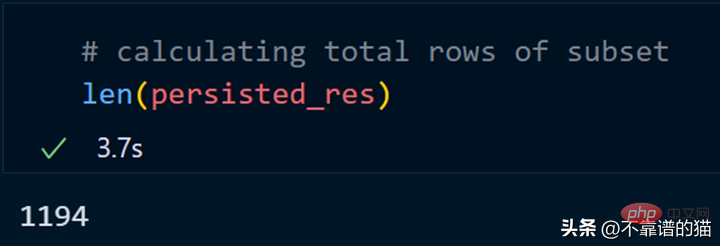
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
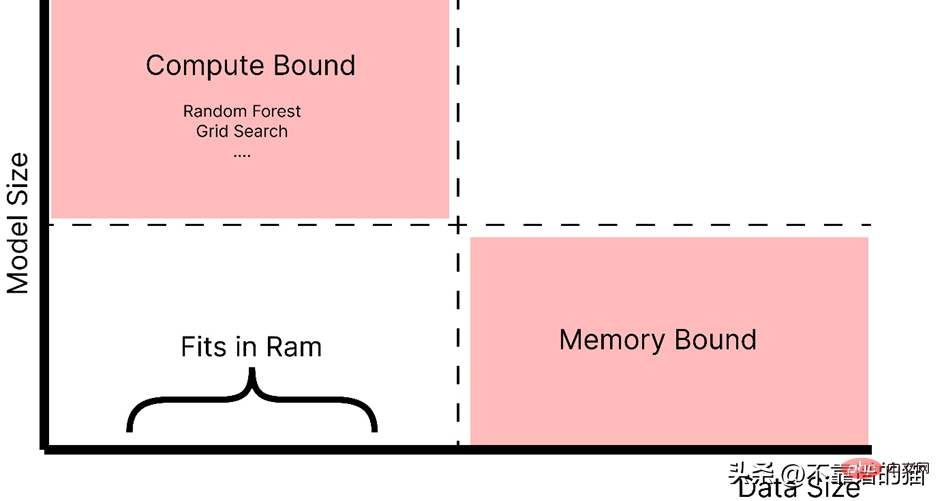
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
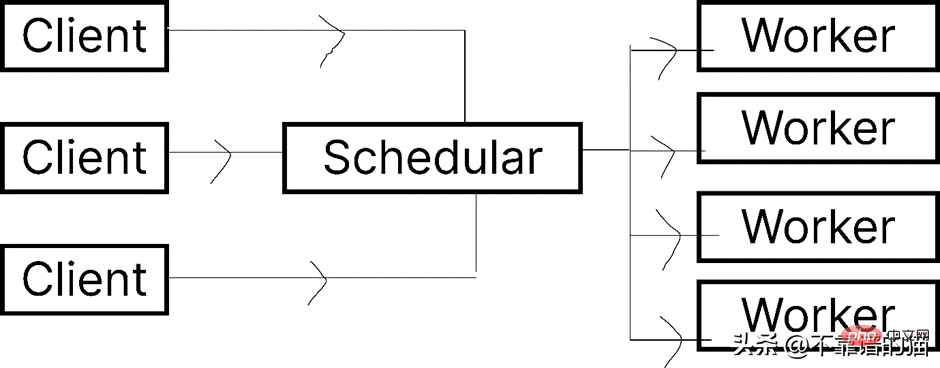
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
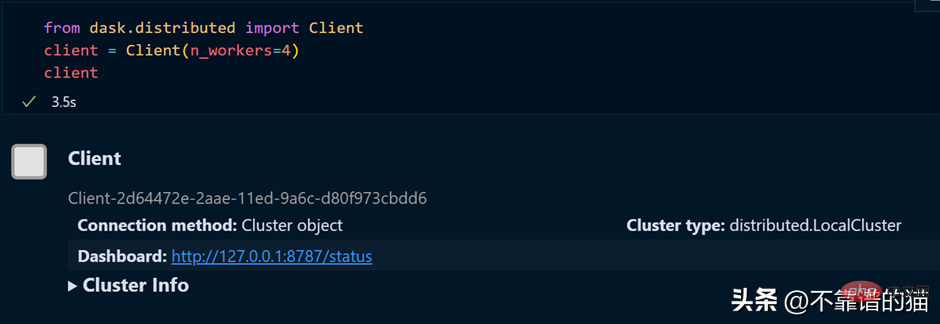
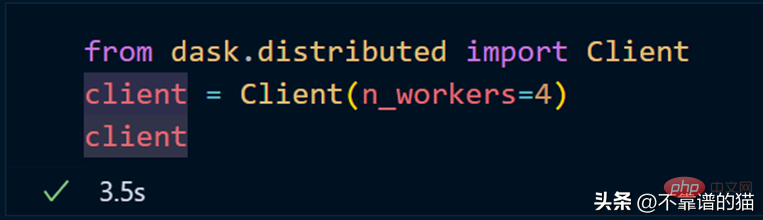
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
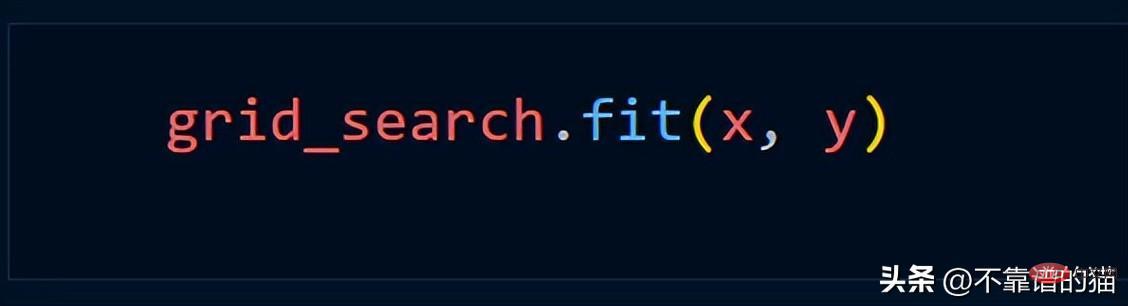
Grid_Search 메서드를 사용한다고 가정하면 일반적으로 다음 Python 코드를 사용합니다.
dask.distributed를 사용하여 클러스터를 만듭니다.
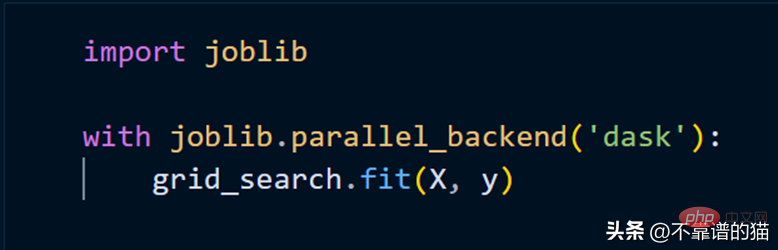
클러스터를 사용하여 scikit-learn 모델을 맞추려면 joblib만 사용하면 됩니다.
위 내용은 Python에서 대규모 기계 학습 데이터 세트를 처리하는 쉬운 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7490
7490
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench는 구성이 올바른 경우 MariadB에 연결할 수 있습니다. 먼저 커넥터 유형으로 "mariadb"를 선택하십시오. 연결 구성에서 호스트, 포트, 사용자, 비밀번호 및 데이터베이스를 올바르게 설정하십시오. 연결을 테스트 할 때는 마리아드 브 서비스가 시작되었는지, 사용자 이름과 비밀번호가 올바른지, 포트 번호가 올바른지, 방화벽이 연결을 허용하는지 및 데이터베이스가 존재하는지 여부를 확인하십시오. 고급 사용에서 연결 풀링 기술을 사용하여 성능을 최적화하십시오. 일반적인 오류에는 불충분 한 권한, 네트워크 연결 문제 등이 포함됩니다. 오류를 디버깅 할 때 오류 정보를 신중하게 분석하고 디버깅 도구를 사용하십시오. 네트워크 구성을 최적화하면 성능이 향상 될 수 있습니다
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL을 해결하는 방법은 로컬 호스트에 연결할 수 없습니다
Apr 08, 2025 pm 02:24 PM
MySQL을 해결하는 방법은 로컬 호스트에 연결할 수 없습니다
Apr 08, 2025 pm 02:24 PM
MySQL 연결은 다음과 같은 이유로 인한 것일 수 있습니다. MySQL 서비스가 시작되지 않았고 방화벽이 연결을 가로 채고 포트 번호가 올바르지 않으며 사용자 이름 또는 비밀번호가 올바르지 않으며 My.cnf의 청취 주소가 부적절하게 구성되어 있습니다. 1. MySQL 서비스가 실행 중인지 확인합니다. 2. MySQL이 포트 3306을들을 수 있도록 방화벽 설정을 조정하십시오. 3. 포트 번호가 실제 포트 번호와 일치하는지 확인하십시오. 4. 사용자 이름과 암호가 올바른지 확인하십시오. 5. my.cnf의 바인드 아드 드레스 설정이 올바른지 확인하십시오.
 Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
데이터 전문가는 다양한 소스에서 많은 양의 데이터를 처리해야합니다. 이것은 데이터 관리 및 분석에 어려움을 겪을 수 있습니다. 다행히도 AWS Glue와 Amazon Athena의 두 가지 AWS 서비스가 도움이 될 수 있습니다.
