

주소 표준화 서비스 AI 딥러닝 모델 추론 최적화 실습

소개
딥 러닝은 자연어 처리 등 분야의 실제 비즈니스 시나리오에서 널리 구현되었으며, 추론 성능을 최적화하는 것이 배포 프로세스의 중요한 부분이 되었습니다. 추론 성능 향상: 한편으로는 배포된 하드웨어의 기능을 최대한 활용하고 사용자 응답 시간을 단축하며 비용을 절감할 수 있으며, 다른 한편으로는 응답 시간을 유지하면서 더 복잡한 구조의 딥 러닝 모델을 사용할 수 있습니다. 변경되지 않아 비즈니스 정확도 지표가 향상됩니다.
이 글에서는 주소 표준화 서비스의 딥러닝 모델에 대한 추론 성능 최적화 작업을 수행합니다. 고성능 연산자, 정량화, 컴파일 최적화 등의 최적화 방법을 통해 정확도 지수를 줄이지 않고도 AI 모델의 엔드투엔드 추론 속도를 최대 4.11배 향상시킬 수 있다. 1. 모델 추론 성능 최적화 방법론
모델 추론 성능 최적화는 AI 서비스 배포 시 중요한 측면 중 하나입니다. 한편으로는 모델 추론의 효율성을 향상시키고 하드웨어 성능을 완전히 발휘할 수 있습니다. 반면에, 추론 지연을 변경하지 않고 유지하면서 비즈니스가 더 복잡한 모델을 채택할 수 있게 하여 정확도 지수를 향상시킬 수 있습니다. 그러나 실제 시나리오에서는 추론 성능을 최적화하는 데 몇 가지 어려움이 있습니다.1.1 자연어 처리 시나리오 최적화의 어려움
일반적인 자연어 처리(NLP) 작업에는 RNN(Recurrent Neural Network)과 BERT[7](BiDirectional Encoder Representations from Transformers.)가 두 가지 유형의 모델입니다. 이용률이 높은 구조. 온라인 서비스 배포의 탄력적인 확장 메커니즘과 높은 비용 효율성을 촉진하기 위해 자연어 처리 작업은 일반적으로 Intel® Xeon® 프로세서와 같은 x86 CPU 플랫폼에 배포됩니다. 그러나 비즈니스 시나리오가 더욱 복잡해짐에 따라 서비스의 추론 컴퓨팅 성능 요구 사항도 점점 더 높아지고 있습니다. 위의 RNN 및 BERT 모델을 예로 들면 CPU 플랫폼에 배포할 때의 성능 문제는 다음과 같습니다.
RNN
- 반복 신경망은 시퀀스 데이터를 다음과 같이 취하는 신경망 유형입니다. 입력 진화 방향으로 재귀를 수행하며 모든 노드(순환 단위)가 체인으로 연결되는 재귀 신경망입니다. 실제 사용에서 일반적으로 사용되는 RNN에는 LSTM, GRU 및 일부 파생 변형이 포함됩니다. 계산 과정에서 아래 그림과 같이 RNN 구조의 각 후속 단계 출력은 해당 입력 및 이전 단계 출력에 따라 달라집니다. 따라서 RNN은 시퀀스 유형의 작업을 완료할 수 있으며 최근에는 NLP 분야는 물론 컴퓨터 비전 분야에서도 널리 사용되고 있습니다. BERT와 비교하여 RNN은 계산이 덜 필요하고 모델 매개변수를 공유하지만 계산 타이밍 종속성으로 인해 시퀀스에 대한 병렬 계산을 수행하는 것이 불가능합니다.
RNN 구조 다이어그램
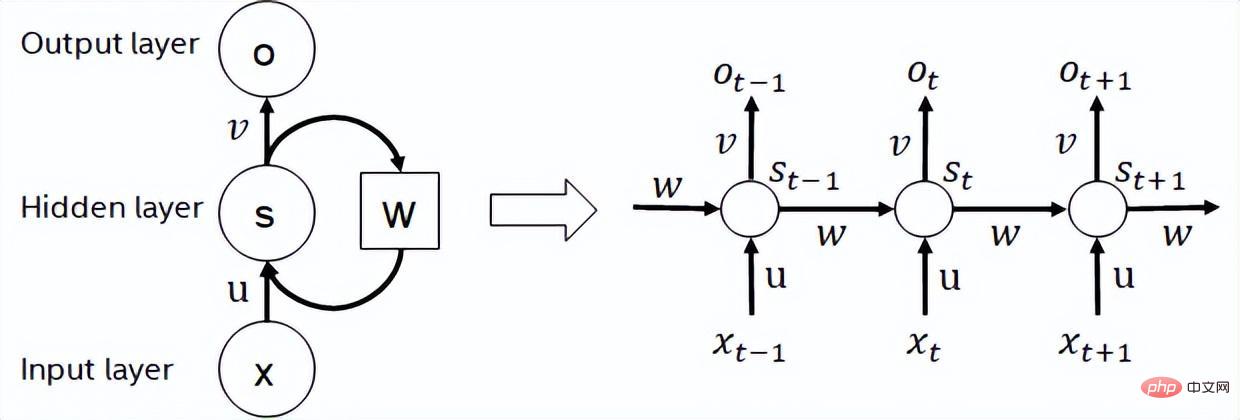
- BERT[7]은 더 깊은 네트워크를 갖춘 대규모 데이터 세트에 대해 비지도 사전 훈련(Unsupervised Pre-training)을 완료할 수 있음을 입증했습니다. 구조를 작성한 다음 특정 작업에 대한 미세 조정을 위한 모델을 제공합니다. 이는 이러한 특정 작업의 정확도 성능을 향상시킬 뿐만 아니라 교육 프로세스도 단순화합니다. BERT의 모델 구조는 간단하고 확장하기 쉽습니다. 단순히 네트워크를 심화하고 넓히면 RNN 구조보다 더 나은 정확도를 얻을 수 있습니다. 반면, 정확도 향상은 더 큰 컴퓨팅 오버헤드를 초래합니다. BERT 모델에는 많은 수의 행렬 곱셈 연산이 있는데 이는 CPU에 큰 과제입니다.
BERT 모델 구조의 도식
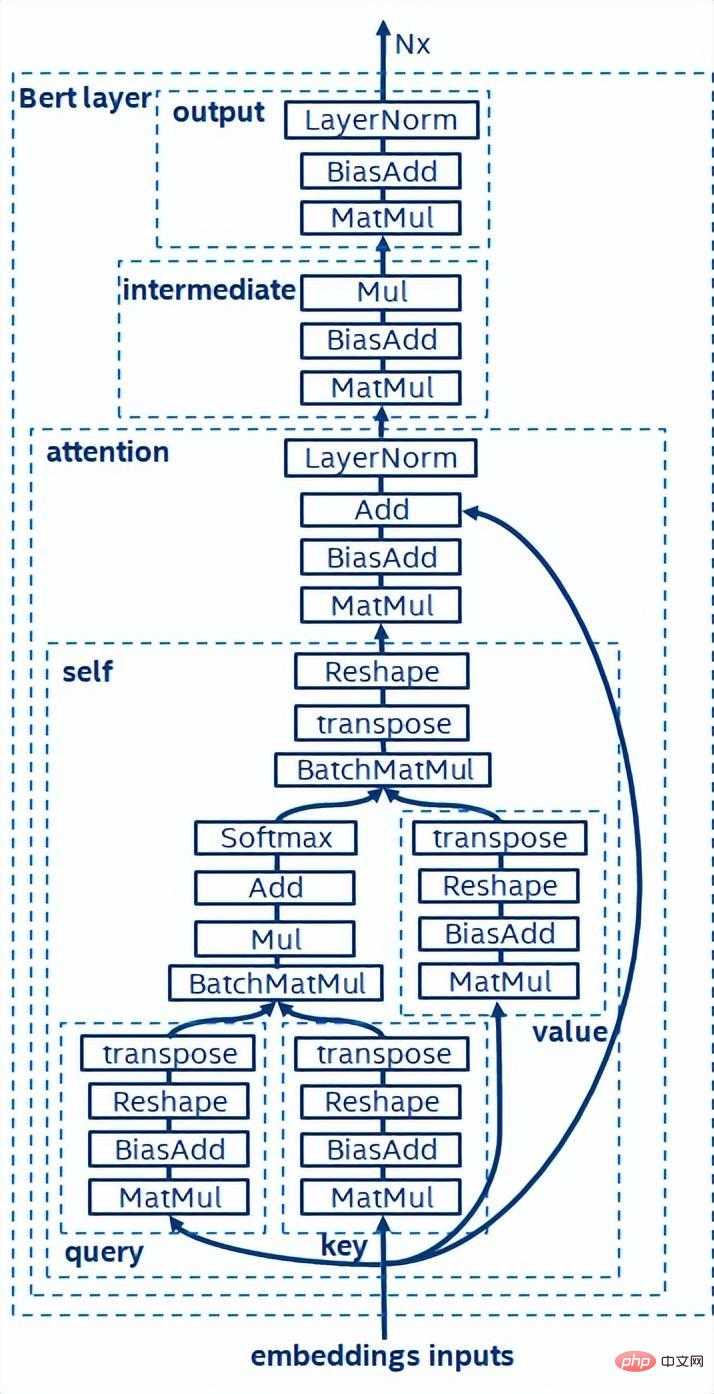
위의 추론 성능 문제 분석을 바탕으로 소프트웨어 스택 수준에서 모델 추론을 최적화하는 데 주로 다음이 포함된다고 생각합니다. 전략:
모델 압축: 양자화, 희소, 가지치기 등 포함
- 특정 시나리오를 위한 고성능 연산자
- AI 컴파일러 최적화
- Quantization
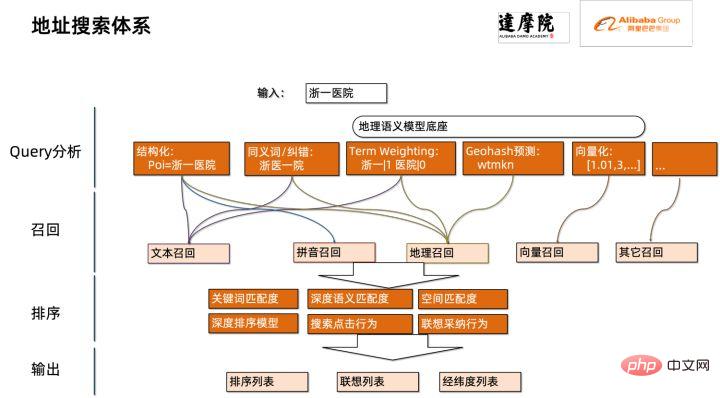
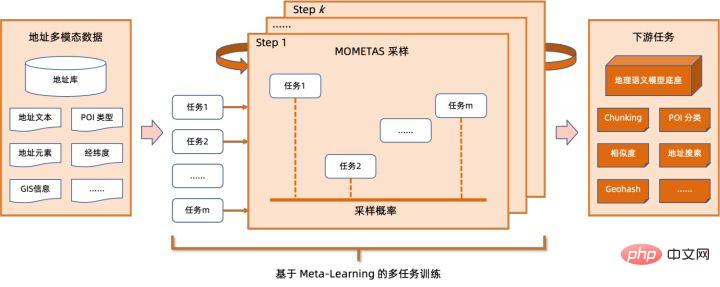
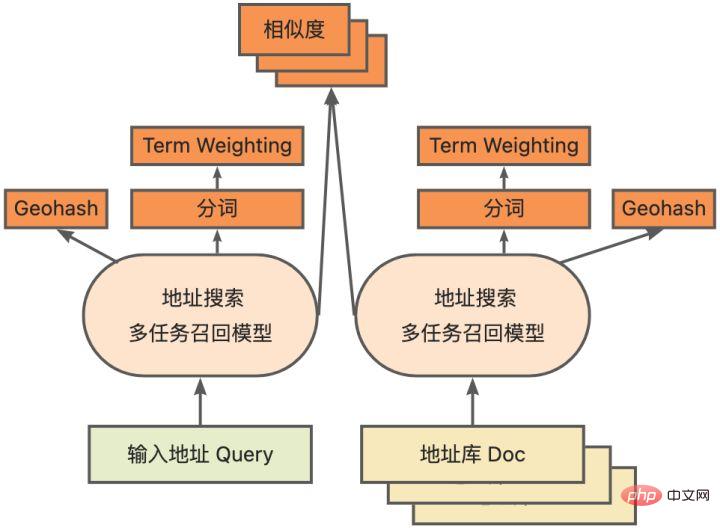
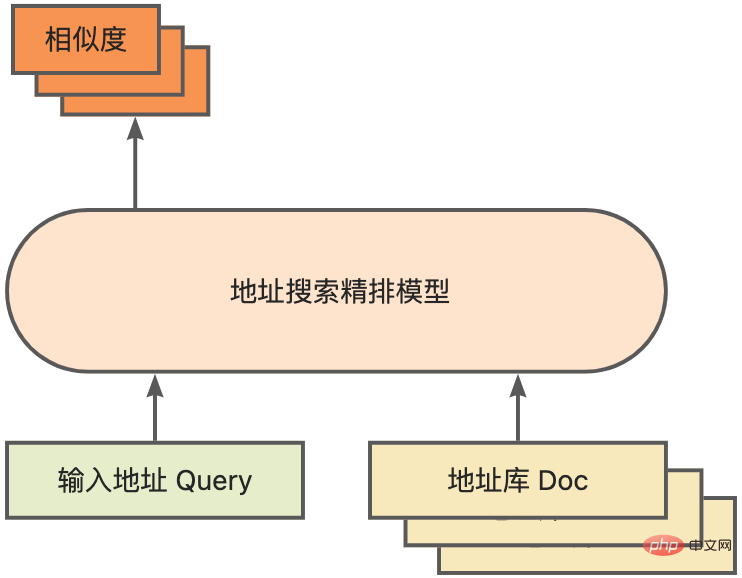
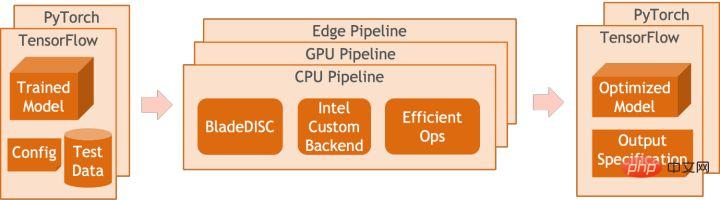
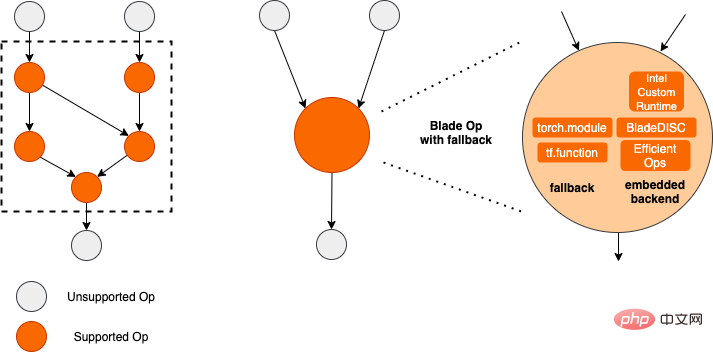
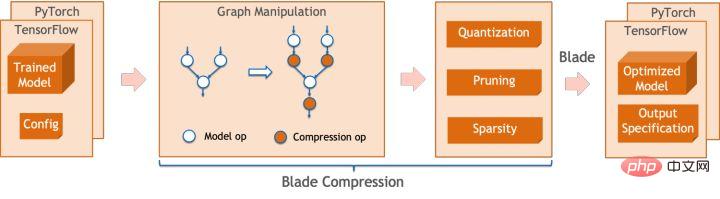
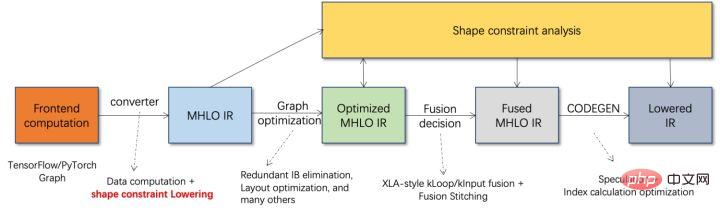
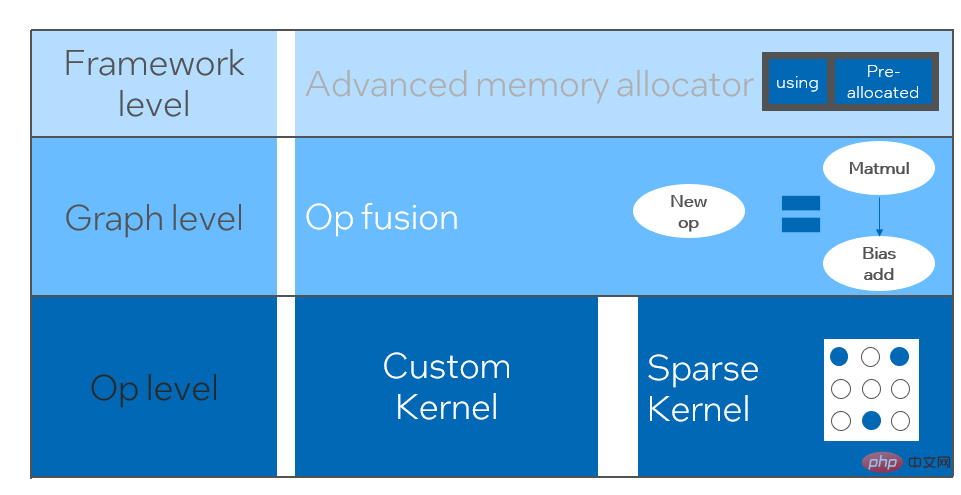
모델 양자화는 부동 소수점 활성화 값 또는 가중치(보통 32비트 부동 소수점 수로 표시)를 낮은 비트 정수(16비트 또는 8비트)로 근사화한 후 계산을 완료하는 프로세스를 말합니다. 낮은 비트 표현으로. 일반적으로 모델 양자화는 모델 매개변수를 압축하여 모델 저장 오버헤드를 줄이고, 메모리 액세스를 줄이고 낮은 비트 컴퓨팅 명령어(예: Intel® Deep Learning Boost Vector Neural Network Instructions, VNNI)를 효과적으로 활용하여 추론을 달성할 수 있습니다. 속도 개선. 부동 소수점 값이 주어지면 다음 공식을 통해 이를 낮은 비트 값에 매핑할 수 있습니다. 합은 양자화 알고리즘을 통해 얻습니다. 이를 바탕으로 Gemm 연산을 예로 들어 부동 소수점 계산 프로세스가 있다고 가정하면: 낮은 비트 영역에서 해당 계산 프로세스를 완료할 수 있습니다: 고성능 연산자 딥 러닝 프레임워크의 다양성을 유지하고 다양한 프로세스(예: 교육)를 고려하기 위해 연산자의 추론 오버헤드에 중복성이 있습니다. 모델 구조가 결정되면 운영자의 추론 프로세스는 원래 전체 프로세스의 하위 집합일 뿐입니다. 따라서 모델 구조가 결정되면 고성능 추론 연산자를 구현하고 원래 모델의 일반 연산자를 대체하여 추론 속도를 향상시킬 수 있습니다. CPU에서 고성능 연산자를 구현하는 핵심은 메모리 액세스를 줄이고 보다 효율적인 명령어 세트를 사용하는 것입니다. 원래 연산자의 계산 과정에는 한편으로는 중간 변수가 많고, 이러한 변수는 메모리에 대해 많은 수의 읽기 및 쓰기 작업을 수행하므로 추론 속도가 느려집니다. 이러한 상황에 대응하여 계산 논리를 수정하여 중간 변수 비용을 줄일 수 있습니다. 반면에 벡터화된 명령어 세트를 직접 호출하여 Intel® Xeon® 처리 효율성과 같은 연산자 내부의 일부 계산 단계를 가속화할 수 있습니다. 프로세서에 AVX512 명령어 세트가 있습니다. AI 컴파일러 최적화 딥러닝 분야의 발전과 함께 모델의 구조와 배포되는 하드웨어도 다양하게 진화하는 추세를 보이고 있습니다. 모델을 다양한 하드웨어 플랫폼에 배포할 때 일반적으로 각 하드웨어 제조업체에서 시작한 런타임을 호출합니다. 실제 비즈니스 시나리오에서는 다음과 같은 몇 가지 문제에 직면할 수 있습니다. 위 문제를 해결하기 위해 AI 컴파일러가 제안되었습니다. 이는 위 문제 중 일부를 해결하기 위해 여러 수준을 추상화합니다. 첫째, 각 프런트엔드 프레임워크의 모델 계산 그래프를 입력으로 받아들이고 다양한 변환기를 통해 통일된 중간 표현을 생성합니다. 이후 추론 성능을 향상시키기 위해 연산자 융합 및 루프 확장과 같은 그래프 최적화 단계가 중간 표현에 적용됩니다. 마지막으로 AI 컴파일러는 최적화된 계산 그래프를 기반으로 특정 하드웨어 플랫폼에 대한 코드 생성을 수행하여 실행 가능한 코드를 생성합니다. 이 과정에서 스티치 및 모양 제약과 같은 최적화 전략이 도입됩니다. AI 컴파일러는 매우 강력하고 적응력이 뛰어나며 사용하기 쉽고 상당한 최적화 이점을 얻을 수 있습니다. 이 기사에서는 Alibaba Cloud 기계 학습 플랫폼 PAI 팀이 Intel 데이터 센터 소프트웨어 팀, Intel 인공 지능 및 분석 팀, DAMO Academy NLP 주소 표준화 팀과 협력하여 주소 표준화의 추론 성능 문제를 해결했습니다. 고성능 추론 최적화 체계를 달성하기 위해 서비스를 제공하고 협력합니다. 공공 보안 및 정부 업무, 전자상거래 물류, 에너지(물, 전기 및 가스), 운영자, 신규 소매, 금융, 의료 및 기타 산업에는 많은 양의 주소가 필요한 경우가 많습니다. 사업 개발 과정에서 발생하는 데이터, 그리고 이러한 데이터에는 표준적인 구조 명세가 없는 경우가 많고, 한 곳에 주소가 누락되거나 이름이 여러 개 존재하는 등의 문제가 있는 경우가 많습니다. 디지털화가 진행되면서 비표준 도시 주소 문제가 점점 더 두드러지고 있습니다. 주소 적용의 기존 문제 주소 표준화[2](주소 정제)는 Alibaba Cloud의 대규모 주소 코퍼스와 강력한 NLP 알고리즘을 기반으로 Alibaba Damo Academy NLP 팀이 개발한 고품질 솔루션입니다. 고성능, 고정밀도의 표준 주소 알고리즘 서비스입니다. 주소 표준화 제품은 주소 데이터의 표준화 및 통일된 표준 주소 라이브러리 구축 관점에서 고성능 주소 알고리즘을 제공합니다. 주소 표준화의 장점 이 주소 알고리즘 서비스는 주소 데이터를 자동으로 표준화할 수 있어 한 곳에서 여러 이름 문제, 주소 식별, 주소 진위 식별 및 기타 주소 데이터 불규칙성과 시간 문제를 효과적으로 해결할 수 있습니다. 수동 관리 소모 노동력 소모 및 주소 데이터베이스 구축의 중복 문제를 해결하고 기업, 정부 기관 및 개발자에게 주소 데이터 정리 및 주소 표준화 기능을 제공하여 주소 데이터가 비즈니스를 더 잘 지원할 수 있도록 합니다. 주소 표준화 제품은 다음과 같은 특징을 가지고 있습니다. 이번에 최적화된 모듈은 주소 표준화의 검색 모듈에 속합니다. 주소 검색은 사용자가 주소 텍스트와 관련된 정보를 입력하는 것을 의미하며, 주소 라이브러리와 검색 엔진을 기반으로 사용자가 입력한 주소 텍스트를 검색하고 연관시켜 관련 POI(Point of Interest) 정보를 반환합니다. 주소 검색 기능은 사용자 데이터 처리 경험을 향상시킬 뿐만 아니라 위도 및 경도 쿼리, 문 주소 표준화, 주소 정규화 등과 같은 다중 주소 다운스트림 서비스의 기반이기도 하므로 전체 주소에서 중요한 역할을 합니다. 서비스 시스템. 주소 서비스 검색 시스템 개략도 구체적으로, 이번에 최적화된 모델은 Multi-task 지리적 사전 학습 언어 모델 베이스를 기반으로 하며, Multi-task 벡터 리콜 모델 및 훌륭한 순위 모델 . Multi-task 지리 사전 학습 언어 모델 베이스Masked Language Model(MLM) task를 기반으로 관련 관심 지점 분류와 주소 요소 식별(도, 시, 구, POI 등)을 결합합니다. 메타 학습(Meta Learning) 방식을 통해 여러 작업의 샘플링 확률을 적응적으로 조정하고 일반적인 주소 지식을 언어 모델에 통합합니다. 다중 작업 주소 사전 학습 모델 기반의 개략도 다중 작업 벡터 재현 모델은 위의 기반을 기반으로 트윈 타워 유사성, Geohash(주소 인코딩)를 포함하여 학습됩니다. ) 예측, 단어 분할 및 용어 가중치(단어 가중치) ) 네 가지 작업입니다. 다중 작업 벡터 재현 모델의 도식 주소 유사성 매칭을 계산하는 핵심 모듈인 Fine Ranking Model은 위의 기반을 바탕으로 대규모 클릭 데이터와 주석 데이터를 도입합니다. 훈련 [3], 모델 증류 기술 [4]을 통해 모델의 효율성을 향상시킵니다. 마지막으로 모델 리콜을 적용하기 위해 주소 라이브러리 문서를 재정렬했습니다. 위 프로세스를 기반으로 학습된 4계층 단일 모델은 CCKS2021 중국 NLP 주소 상관 작업[5]에서 12계층 기준 모델보다 더 나은 결과를 얻을 수 있습니다(자세한 내용은 성능 표시 섹션 참조). 정제된 모델의 도식 Alibaba Cloud 기계 학습 플랫폼 PAI 팀이 출시한 블레이드 제품은 위에서 언급한 모든 최적화 솔루션을 지원하고 통합된 사용자 인터페이스를 제공하며 다양한 기능을 제공합니다. 고성능 운영자, Intel Custom Backend, BladeDISC 등과 같은 소프트웨어 백엔드 Blade 모델 추론 최적화 아키텍처 다이어그램 3.1 Blade Blade는 Alibaba Cloud 머신 러닝 PAI(인공 지능 플랫폼) 팀에서 출시한 일반 추론 최적화 도구입니다. 모델 시스템을 통해 최적화되어 모델이 최적의 추론 성능을 달성할 수 있습니다. 계산 그래프 최적화, Intel® oneDNN, BladeDISC 컴파일 최적화, 블레이드 고성능 연산자 라이브러리, Costom 백엔드, 블레이드 혼합 정밀도 및 기타 최적화 방법과 같은 공급업체 최적화 라이브러리를 유기적으로 통합합니다. 동시에 간단한 사용법으로 모델 최적화의 한계점을 낮추고 사용자 경험과 생산 효율성을 향상시킵니다. PAI-Blade는 Tensorflow pb, PyTorch torchscript 등을 포함한 다양한 입력 형식을 지원합니다. 최적화할 모델을 위해 PAI-Blade는 이를 분석한 후 가능한 다양한 최적화 방법을 적용하고, 다양한 최적화 결과 중 가장 확실한 가속 효과가 있는 모델을 최종 최적화 결과로 선택합니다. Blade 최적화 다이어그램 배포 성공률을 보장하면서 최대의 최적화 효과를 얻기 위해 PAI-Blade는 최적화를 위한 "원형 다이어그램" 방법을 채택합니다. 즉, Blade Circle Diagram Blade Compression은 개발자가 효율적인 모델 압축 최적화 작업을 지원하도록 설계된 모델 압축용 툴킷입니다. 여기에는 양자화, 가지치기, 희소화 등을 포함한 다양한 모델 압축 기능이 포함되어 있습니다. 압축된 모델은 블레이드를 통해 쉽게 추가로 최적화되어 모델 시스템 조합의 궁극적인 최적화를 얻을 수 있습니다. 정량화 측면에서 Blade Compression: 동시에 특정 상황에 대한 맞춤형 개발을 촉진하기 위해 풍부한 원자 기능 API를 제공합니다. Blade Compression Schematic BladeDISC은 Alibaba Cloud 기계 학습 플랫폼 PAI 팀에서 출시한 기계 학습 시나리오를 위한 동적 형태 딥 러닝 컴파일러이며 Blade의 백엔드 중 하나입니다. 주류 프런트엔드 프레임워크(TensorFlow, PyTorch)와 백엔드 하드웨어(CPU, GPU)를 지원하고 추론 및 훈련 최적화도 지원합니다. BladeDISC Architecture Diagram 3.2 Intel® 기반의 고성능 오퍼레이터 모델 구축을 위한 기본 모듈이자 특정 기능을 담당하는 모듈로, 이들 모듈의 다양한 조합을 통해 다양한 모델을 얻을 수 있으며, 이 모듈도 핵심입니다. AI 컴파일러의 최적화 대상. 따라서 최고 성능의 기본 모듈을 획득하여 최고 성능의 모델을 달성하기 위해 Intel은 효율적인 AVX512 명령 활성화, 운영자 내부 계산 스케줄링, 운영자 활성화를 포함하여 X86 아키텍처에 대한 이러한 기본 모듈의 다단계 최적화를 수행했습니다. 융합, 캐시 최적화, 병렬 최적화 등 주소 표준화 서비스에는 RNN(Recurrent Neural Network) 모델이 자주 등장하는데, RNN 모델에서 성능에 가장 큰 영향을 미치는 모듈은 LSTM이나 GRU 등의 모듈을 예로 들어 설명합니다. 가변 길이 및 다차원에서 배치 입력 시 LSTM의 궁극적인 성능 최적화를 달성하는 방법. 일반적으로 다양한 사용자의 요구와 요구를 충족하기 위해 고성능과 저비용을 추구하는 클라우드 서비스는 다양한 사용자 요청을 일괄 처리하여 컴퓨팅 리소스 활용도를 극대화합니다. 아래 그림과 같이 임베딩 문장은 총 3개가 있으며, 내용과 입력 길이가 다릅니다. 원본 입력 데이터 원본 입력 데이터 LSTM의 입력 계산 단계 LSTM 컴퓨팅 퓨전[8] 인텔 맞춤형 백엔드[9]는 블레이드의 소프트웨어 백엔드로서 모델 양자화 및 희소 추론 성능을 강력하게 가속화하며 주로 세 가지를 포함합니다. 최적화 수준. 첫째, Primitive Cache 전략을 사용하여 메모리를 최적화합니다. 둘째, 그래프 융합 최적화가 수행됩니다. 마지막으로 연산자 수준에서는 희소 및 양자화 연산자를 포함하는 효율적인 연산자 라이브러리가 구현됩니다. 인텔 맞춤형 백엔드 아키텍처 다이어그램 낮은 정밀도 양자화 희소 및 양자화와 같은 고속 연산자는 VNNI 명령 세트와 같은 인텔® DL 부스트 가속 명령 세트의 이점을 활용합니다.
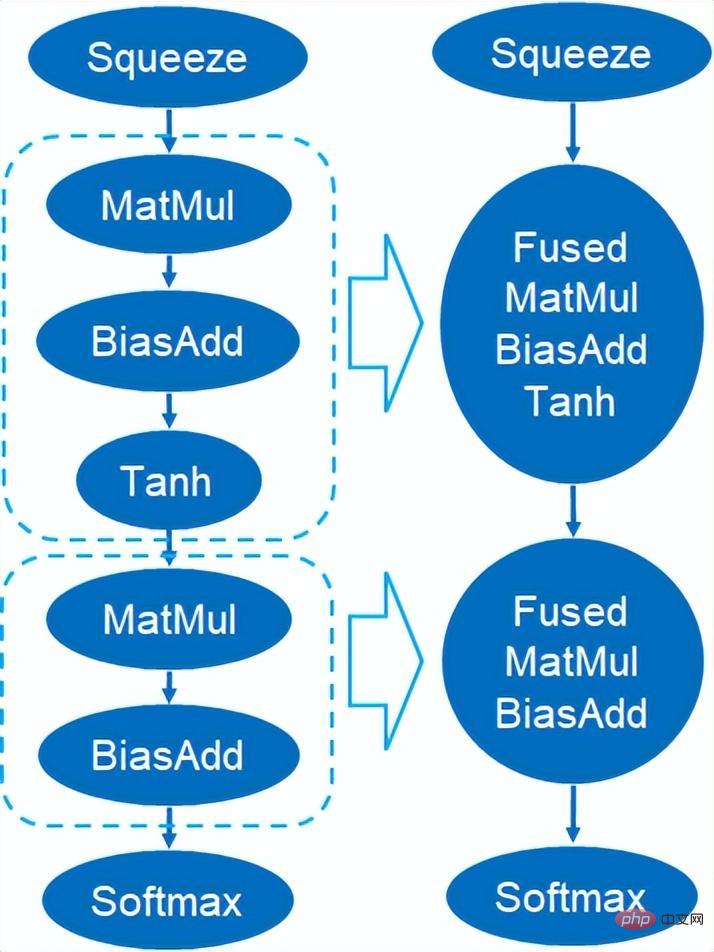
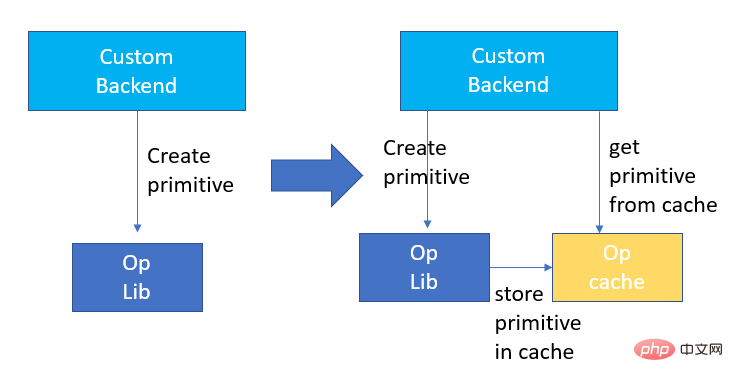
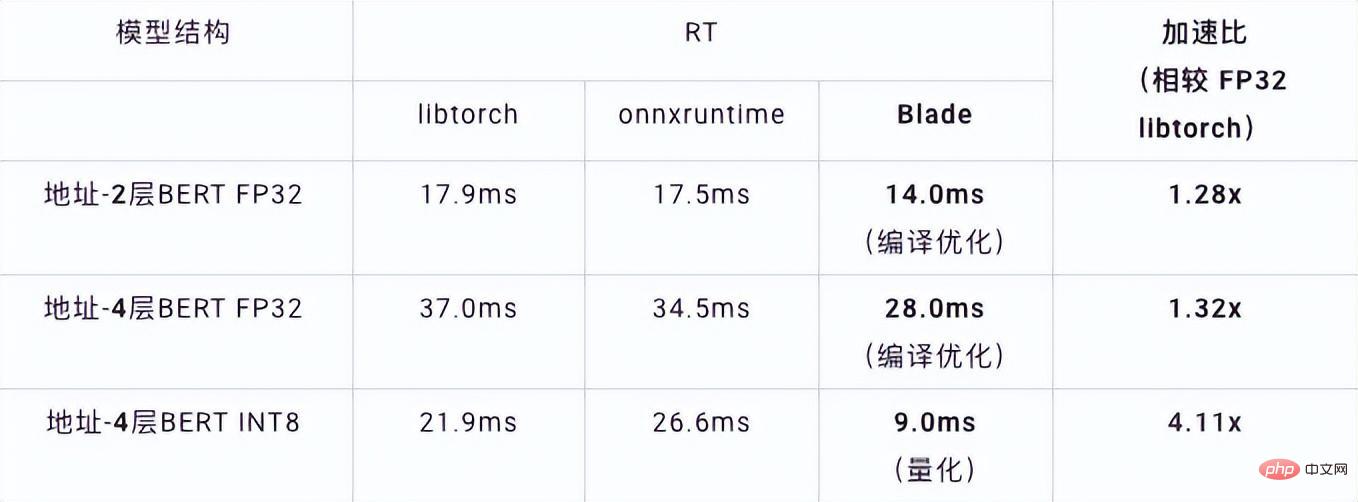
VNNI 명령어 소개 위 그림은 3개의 AVX512 BW 명령어를 사용하여 8비트를 가속할 수 있음을 보여줍니다. VPMADDUBSW는 먼저 8비트로 구성된 2쌍의 배열을 곱하고 추가하여 16비트 데이터를 합산합니다. 32비트 데이터를 얻고 마지막으로 VPADDD에 상수를 추가합니다. 이 세 가지 함수는 AVX512_VNNI를 형성할 수 있으며 추론에서 행렬 곱셈을 가속화하는 데 사용할 수 있습니다. Graph fusion 또한 Custom Backend는 그래프 융합도 제공합니다. 예를 들어 행렬 곱셈 후 중간 임시 Tensor가 출력되지 않고 후속 명령이 직접 실행됩니다. 후자의 연산자를 융합하면 데이터 이동이 줄어들어 실행 시간이 단축됩니다. 아래 그림은 빨간색 상자의 연산자를 융합한 후 추가 데이터 이동을 제거할 수 있는 예입니다. 새로운 운영자. Graph fusion 메모리 최적화 메모리 할당 및 해제가 운영 체제와 통신하므로 런타임 지연이 증가합니다. 이 부분의 오버헤드를 줄이기 위해 Custom Backend가 추가됩니다. Primitive Cache의 디자인이 변경되었습니다. Primitive Cache는 생성된 Primitive를 시스템에서 재활용할 수 없도록 캐시하는 데 사용되어 다음 호출의 생성 오버헤드를 줄입니다. 동시에 아래 그림과 같이 시간이 많이 걸리는 운영자를 위한 캐시 메커니즘이 구축되어 운영자의 작업 속도를 높입니다. Primitive Cache 앞서 언급했듯이, 모델 크기를 줄인 후에는 계산 및 액세스 오버헤드가 크게 줄어들어 성능이 크게 향상됩니다. 위 최적화 솔루션의 효과를 확인하기 위해 주소 검색 서비스에서 두 가지 대표적인 모델 구조를 선택했습니다. 테스트 환경은 다음과 같습니다. 4.1 ESIM ESIM[6 ] 자연어 추론을 위해 설계된 LSTM의 향상된 버전으로, 추론 오버헤드는 주로 모델의 LSTM 구조에서 발생합니다. Blade는 Intel 데이터 센터 소프트웨어 팀에서 개발한 고성능 범용 LSTM 연산자를 사용하여 PyTorch 모듈의 기본 LSTM(Baseline)을 대체합니다. 이번에 테스트한 ESIM에는 단일 연산자 최적화 전후의 성능이 표에 나와 있습니다. 최적화된 RT 가속 LSTM A 7x200 0.199ms 0.066ms +3.02x 202x200 0.914ms 0.307ms +2.98x LSTM - B 70x50 0.266ms 0.098ms +2.71x 202x50 0.804ms 0.209ms +3.85x 최적화 전과 후의 LSTM 단일 연산자 추론 성능 최적화 전과 후의 ESIM 종단간 추론 속도는 표와 같으나, 최적화 전과 후 모델의 정확도는 그대로 유지됩니다. 변함없이. 모델 구조 ESIM[6] ESIM[6]+블레이드 연산자 최적화 속도 향상 RT 6.3ms 3.4ms +1.85x 최적화 전후의 ESIM 모델 추론 성능 4.2 BERT BERT[7]는 최근 자연어 처리(NLP), 컴퓨터 비전(CV) 및 기타 분야에서 널리 채택되었습니다. 블레이드에는 이 구조에 대한 컴파일 최적화(FP32) 및 양자화(INT8)와 같은 다양한 방법이 있습니다. 속도 테스트에서 테스트 데이터의 모양은 10x53으로 고정됩니다. 다양한 백엔드의 속도 성능과 다양한 최적화 방법은 아래 표와 같습니다. 블레이드 컴파일 및 최적화 후 또는 INT8 양자화 후 모델 추론 속도가 추론 백엔드가 Intel Custom Backend 및 BladeDisc인 libtorch 및 onnxruntime보다 우수하다는 것을 알 수 있습니다. 주목할 점은 정량적 가속 후 4레이어 BERT의 속도가 2레이어 BERT의 1.5배라는 점입니다. 이는 속도를 높이는 동안 비즈니스가 더 큰 모델을 사용하고 더 나은 비즈니스 정확도를 얻을 수 있음을 의미합니다. 주소 BERT 추론 성능 표시 정확도 측면에서는 아래 표와 같이 CCKS2021 중국어 NLP 주소 상관 작업[5]을 기반으로 관련 모델 성능을 보여줍니다. DAMO 아카데미 주소팀이 자체 개발한 4레이어 BERT 매크로 F1의 정확도는 표준 12레이어 BERT 기반보다 높습니다. 블레이드 컴파일 최적화는 무손실 정확도를 달성할 수 있으며, 블레이드 압축 양자화 훈련 후 실제 양자화 모델의 정확도는 원래 부동 소수점 모델보다 약간 높습니다. 모델 구조 매크로 F1(높을수록 좋음) 12층 BERT 기반 77.24 Address-4-layer BERT 78.72(+1.48) Address-4-layer BERT + 블레이드 최적화 78.72 (+1.48) 주소 - 4레이어 BERT + 블레이드 양자화 78.85 (+1.61) 주소 BERT 관련 정확도 결과
2. 주소 표준화 소개
3. 모델 추론 최적화 솔루션




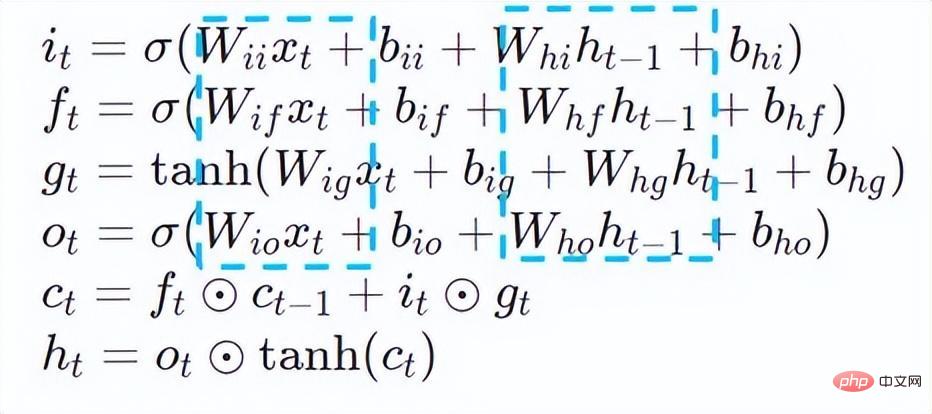
4. 전체 성능 표시
위 내용은 주소 표준화 서비스 AI 딥러닝 모델 추론 최적화 실습의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7486
7486
 15
1377
52
77
11
51
19
19
38
15
1377
52
77
11
51
19
19
38

 SQL에서 새 열을 추가하는 방법
Apr 09, 2025 pm 02:09 PM
SQL에서 새 열을 추가하는 방법
Apr 09, 2025 pm 02:09 PM
Alter Table 문을 사용하여 SQL의 기존 테이블에 새 열을 추가하십시오. 특정 단계에는 다음이 포함됩니다. 테이블 이름 및 열 정보 결정, Alter Table 문 작성 및 진술 실행. 예를 들어, 고객 테이블에 이메일 열을 추가하십시오 (Varchar (50)) : Alter Table 고객 이메일 추가 Varchar (50);
 SQL에서 열을 추가하기위한 구문은 무엇입니까?
Apr 09, 2025 pm 02:51 PM
SQL에서 열을 추가하기위한 구문은 무엇입니까?
Apr 09, 2025 pm 02:51 PM
SQL에서 열을 추가하기위한 구문은 Alter Table_Name ADD CORMEN_NAME DATY_TYPE [NOT NULL] [DEFAULT DEFAULT_VALUE]; 여기서 table_name은 테이블 이름이고 column_name은 새 열 이름, data_type는 데이터 유형이며 NULL은 NULL 값이 허용되는지 여부를 지정하고 기본값 기본값을 지정합니다.
 SQL 클리어 테이블 : 성능 최적화 팁
Apr 09, 2025 pm 02:54 PM
SQL 클리어 테이블 : 성능 최적화 팁
Apr 09, 2025 pm 02:54 PM
SQL 테이블 개선 성능을 개선하기위한 팁 : 삭제 대신 Truncate 테이블을 사용하고 공간을 확보하고 ID 열을 재설정하십시오. 계단식 삭제를 방지하기 위해 외국의 주요 제약 조건을 비활성화하십시오. 트랜잭션 캡슐화 작업을 사용하여 데이터 일관성을 보장합니다. 배치는 빅 데이터를 삭제하고 한계를 통해 행 수를 제한합니다. 쿼리 효율성을 향상시키기 위해 지우고 지수를 재구성하십시오.
 SQL에서 열을 추가 할 때 기본값을 설정하는 방법
Apr 09, 2025 pm 02:45 PM
SQL에서 열을 추가 할 때 기본값을 설정하는 방법
Apr 09, 2025 pm 02:45 PM
새로 추가 된 열에 대한 기본값을 설정하고 Alter Table 문을 사용하십시오. 문 : 열 추가를 지정하고 기본값을 설정하십시오. Alter Table_Name Add Column_name Data_Type Default_value; 구속 조건 조항을 사용하여 기본값을 지정하십시오. ALTER TABLE TABLE_NAME CORMENT CORMEN_NAME DATA DATA DATA DATA DATA DATA DATA DATAY_TYPE 제한 DEFAULT_COSSTRANT DEFAULT DEFAULT_VALUE;
 삭제 명령문을 사용하여 SQL 테이블을 지우십시오
Apr 09, 2025 pm 03:00 PM
삭제 명령문을 사용하여 SQL 테이블을 지우십시오
Apr 09, 2025 pm 03:00 PM
예, 삭제 명령문은 SQL 테이블을 지우는 데 사용될 수 있습니다. 단계는 다음과 같습니다. 삭제 명령문 사용 : table_name에서 삭제; TABLE_NAME을 제거 할 테이블 이름으로 바꾸십시오.
 Redis 메모리 조각화를 처리하는 방법?
Apr 10, 2025 pm 02:24 PM
Redis 메모리 조각화를 처리하는 방법?
Apr 10, 2025 pm 02:24 PM
Redis 메모리 조각화는 할당 된 메모리에 재 할당 할 수없는 작은 자유 영역의 존재를 말합니다. 대처 전략에는 다음이 포함됩니다. REDIS를 다시 시작하십시오 : 메모리를 완전히 지우지 만 인터럽트 서비스. 데이터 구조 최적화 : Redis에 더 적합한 구조를 사용하여 메모리 할당 및 릴리스 수를 줄입니다. 구성 매개 변수 조정 : 정책을 사용하여 최근에 가장 적게 사용 된 키 값 쌍을 제거하십시오. 지속 메커니즘 사용 : 데이터를 정기적으로 백업하고 Redis를 다시 시작하여 조각을 정리하십시오. 메모리 사용 모니터링 : 적시에 문제를 발견하고 조치를 취하십시오.
 phpmyadmin은 데이터 테이블을 만듭니다
Apr 10, 2025 pm 11:00 PM
phpmyadmin은 데이터 테이블을 만듭니다
Apr 10, 2025 pm 11:00 PM
phpmyadmin을 사용하여 데이터 테이블을 만들려면 다음 단계가 필수적입니다. 데이터베이스에 연결하고 새 탭을 클릭하십시오. 테이블의 이름을 지정하고 저장 엔진을 선택하십시오 (InnoDB 권장). 열 이름, 데이터 유형, NULL 값 허용 여부 및 기타 속성을 포함하여 열 추가 버튼을 클릭하여 열 디테일을 추가하십시오. 기본 키로 하나 이상의 열을 선택하십시오. 저장 버튼을 클릭하여 테이블과 열을 만듭니다.
 Oracle 데이터베이스 작성 방법 Oracle 데이터베이스 작성 방법
Apr 11, 2025 pm 02:33 PM
Oracle 데이터베이스 작성 방법 Oracle 데이터베이스 작성 방법
Apr 11, 2025 pm 02:33 PM
Oracle 데이터베이스를 만드는 것은 쉽지 않으므로 기본 메커니즘을 이해해야합니다. 1. 데이터베이스 및 Oracle DBMS의 개념을 이해해야합니다. 2. SID, CDB (컨테이너 데이터베이스), PDB (Pluggable Database)와 같은 핵심 개념을 마스터합니다. 3. SQL*Plus를 사용하여 CDB를 생성 한 다음 PDB를 만들려면 크기, 데이터 파일 수 및 경로와 같은 매개 변수를 지정해야합니다. 4. 고급 응용 프로그램은 문자 세트, 메모리 및 기타 매개 변수를 조정하고 성능 튜닝을 수행해야합니다. 5. 디스크 공간, 권한 및 매개 변수 설정에주의를 기울이고 데이터베이스 성능을 지속적으로 모니터링하고 최적화하십시오. 그것을 능숙하게 마스터 함으로써만 지속적인 연습이 필요합니다. Oracle 데이터베이스의 생성 및 관리를 진정으로 이해할 수 있습니다.
