

Python을 사용한 데이터 정리에 대한 전체 가이드

다음 유명한 데이터 과학 인용문을 들어보셨을 것입니다.
데이터 과학 프로젝트에서 80%의 시간은 데이터 처리에 사용됩니다.
들어본 적이 없다면 기억하세요. 데이터 정리는 데이터 과학 워크플로의 기초입니다. 기계 학습 모델은 제공된 데이터를 기반으로 수행됩니다. 지저분한 데이터는 성능이 저하되거나 잘못된 결과로 이어질 수 있지만, 깨끗한 데이터는 좋은 모델 성능을 위한 전제 조건입니다. 물론 깨끗한 데이터가 항상 좋은 성능을 의미하는 것은 아닙니다. 올바른 모델 선택(나머지 20%)도 중요하지만, 깨끗한 데이터가 없으면 가장 강력한 모델이라도 기대한 수준을 달성할 수 없습니다.
이 기사에서는 데이터 정리에서 해결해야 할 문제를 나열하고 가능한 해결 방법을 보여줍니다. 이 기사를 통해 단계별로 데이터 정리를 수행하는 방법을 배울 수 있습니다.
Missing Values
데이터 세트에 누락된 데이터가 포함된 경우 채우기 전에 일부 데이터 분석을 수행할 수 있습니다. 빈 셀의 위치 자체가 유용한 정보를 알려줄 수 있기 때문입니다. 예:
- NA 값은 데이터 세트의 끝이나 중간에만 나타납니다. 이는 데이터 수집 과정에서 기술적인 문제가 있었을 수 있음을 의미합니다. 특정 샘플 시퀀스에 대한 데이터 수집 프로세스를 분석하고 문제의 원인을 식별해야 할 수도 있습니다.
- 한 열의 NA 개수가 70~80%를 초과하면 해당 열을 삭제할 수 있습니다.
- 양식 내 선택 질문 열에 NA 값이 있는 경우 해당 열은 사용자가 답변한 항목(1) 또는 답변하지 않은 항목(0)으로 추가로 코딩할 수 있습니다.
missingno 이 Python 라이브러리를 사용하면 위의 상황을 확인할 수 있으며 사용이 매우 간단합니다. 예를 들어 아래 그림의 흰색 선은 NA입니다.
import missingno as msno msno.matrix(df)

채우는 방법은 다양합니다. 누락된 값(예:
- 평균, 중앙값, 최빈값
- kNN
- 0 또는 상수 등)
다양한 방법에는 서로 장단점이 있으며, 전체적으로 작동하는 "최고의" 기술은 없습니다. 상황. 자세한 내용은 이전 기사를 참조하세요.
Outliers
Outliers는 데이터 세트의 다른 지점에 비해 매우 크거나 매우 작은 값입니다. 이들의 존재는 수학적 모델의 성능에 큰 영향을 미칩니다. 다음 간단한 예를 살펴보겠습니다.
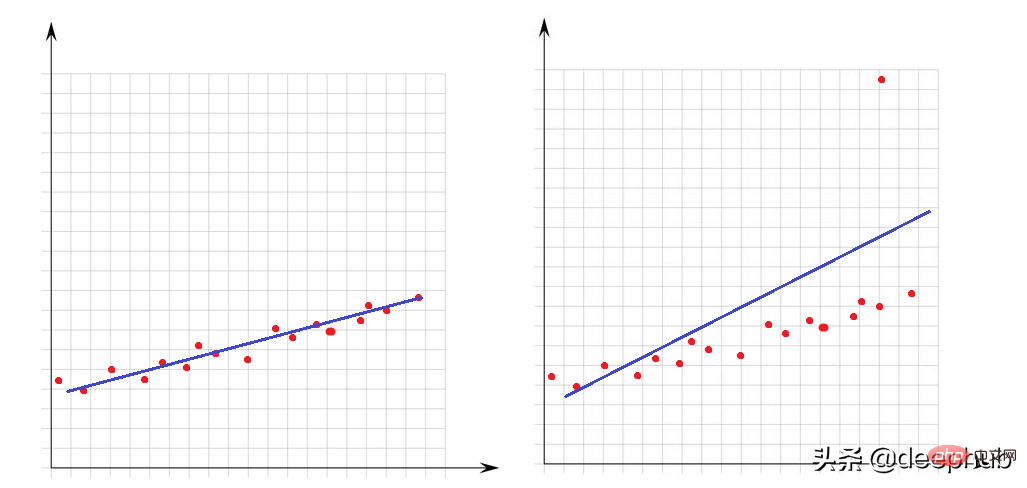
왼쪽 이미지에는 이상치가 없으며 선형 모델이 데이터 포인트에 매우 잘 맞습니다. 오른쪽 이미지에는 이상치가 있습니다. 모델이 데이터 세트의 모든 점을 포함하려고 할 때 이 이상치가 있으면 모델이 적합하는 방식이 바뀌고 모델이 최소 절반 이상의 점에 적합하지 않게 됩니다.
아웃라이어의 경우 이상치를 판단하는 방법을 소개해야 합니다. 이를 위해서는 수학적 관점에서 최대값과 최소값이 무엇인지 명확히 해야 합니다.
Q3+1.5 x IQR보다 크거나 Q1-1.5 x IQR보다 작은 값은 이상치로 간주될 수 있습니다. IQR(사분위간 범위)은 Q3과 Q1의 차이입니다(IQR = Q3-Q1).
다음 함수를 사용하여 데이터 세트의 이상값 수를 확인할 수 있습니다.
def number_of_outliers(df): df = df.select_dtypes(exclude = 'object') Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 return ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
이상값을 처리하는 한 가지 방법은 이상값을 Q3 또는 Q1과 동일하게 만드는 것입니다. 아래 lower_upper_range 함수는 pandas 및 numpy 라이브러리를 사용하여 외부에 이상값이 있는 범위를 찾은 다음, Clip 함수를 사용하여 값을 지정된 범위로 자릅니다.
def lower_upper_range(datacolumn): sorted(datacolumn) Q1,Q3 = np.percentile(datacolumn , [25,75]) IQR = Q3 - Q1 lower_range = Q1 - (1.5 * IQR) upper_range = Q3 + (1.5 * IQR) return lower_range,upper_range for col in columns: lowerbound,upperbound = lower_upper_range(df[col]) df[col]=np.clip(df[col],a_min=lowerbound,a_max=upperbound)
일관되지 않은 데이터
이상치 문제는 숫자 특성에 관한 것이었습니다. 이제 문자 유형(범주형) 특성을 살펴보겠습니다. 데이터가 일치하지 않는다는 것은 고유한 열 클래스의 표현이 서로 다르다는 것을 의미합니다. 예를 들어 성별 열에는 남/여와 남/여가 모두 있습니다. 이 경우에는 4개의 클래스가 있지만 실제로는 2개의 클래스가 있습니다.
현재 이 문제에 대한 자동 해결 방법이 없으므로 수동 분석이 필요합니다. 이러한 분석을 위해 pandas의 고유한 기능이 준비되어 있습니다. 자동차 브랜드의 예를 살펴보겠습니다.
df['CarName'] = df['CarName'].str.split().str[0] print(df['CarName'].unique())
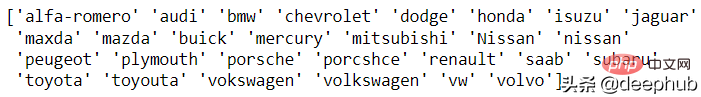
maxda-mazda, Nissan-nissan, porcshce-porsche, toyouta-toyota 등이 모두 병합될 수 있습니다.
df.loc[df['CarName'] == 'maxda', 'CarName'] = 'mazda' df.loc[df['CarName'] == 'Nissan', 'CarName'] = 'nissan' df.loc[df['CarName'] == 'porcshce', 'CarName'] = 'porsche' df.loc[df['CarName'] == 'toyouta', 'CarName'] = 'toyota' df.loc[df['CarName'] == 'vokswagen', 'CarName'] = 'volkswagen' df.loc[df['CarName'] == 'vw', 'CarName'] = 'volkswagen'
잘못된 데이터
잘못된 데이터는 논리적으로 전혀 올바르지 않은 값을 나타냅니다. 예를 들어,
- 누군가의 나이는 560이고,
- 특정 작업은 -8시간이 걸렸습니다.
- 사람의 키는 1200cm입니다.
숫자 열의 경우 pandas의 설명 기능을 사용하여 이를 식별할 수 있습니다. 오류:
df.describe()
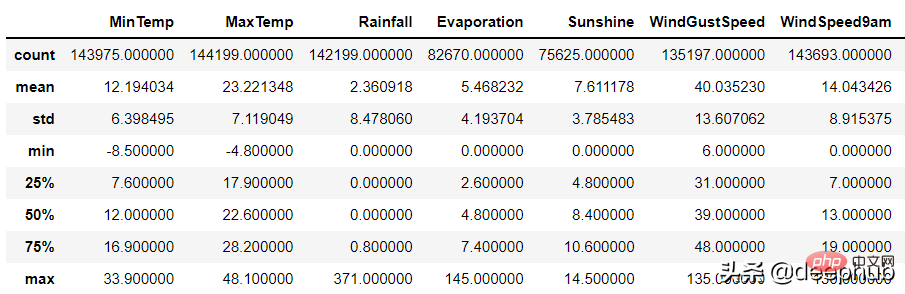
데이터가 잘못된 이유는 두 가지일 수 있습니다.
1. 데이터 수집 오류: 예를 들어 입력 시 범위를 판단하지 않고 키 입력 시 179cm 대신 1799cm가 입력되지만 프로그램에서는 데이터의 범위를 판단하지 않습니다.
2. 데이터 연산 오류
数据集的某些列可能通过了一些函数的处理。 例如,一个函数根据生日计算年龄,但是这个函数出现了BUG导致输出不正确。
以上两种随机错误都可以被视为空值并与其他 NA 一起估算。
重复数据
当数据集中有相同的行时就会产生重复数据问题。 这可能是由于数据组合错误(来自多个来源的同一行),或者重复的操作(用户可能会提交他或她的答案两次)等引起的。 处理该问题的理想方法是删除复制行。
可以使用 pandas duplicated 函数查看重复的数据:
df.loc[df.duplicated()]
在识别出重复的数据后可以使用pandas 的 drop_duplicate 函数将其删除:
df.drop_duplicates()
数据泄漏问题
在构建模型之前,数据集被分成训练集和测试集。 测试集是看不见的数据用于评估模型性能。 如果在数据清洗或数据预处理步骤中模型以某种方式“看到”了测试集,这个就被称做数据泄漏(data leakage)。 所以应该在清洗和预处理步骤之前拆分数据:
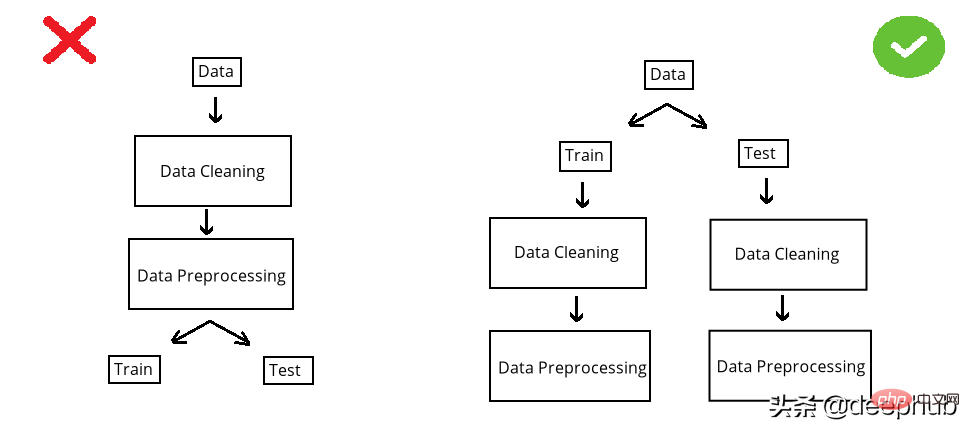
以选择缺失值插补为例。数值列中有 NA,采用均值法估算。在 split 前完成时,使用整个数据集的均值,但如果在 split 后完成,则使用分别训练和测试的均值。
第一种情况的问题是,测试集中的推算值将与训练集相关,因为平均值是整个数据集的。所以当模型用训练集构建时,它也会“看到”测试集。但是我们拆分的目标是保持测试集完全独立,并像使用新数据一样使用它来进行性能评估。所以在操作之前必须拆分数据集。
虽然训练集和测试集分别处理效率不高(因为相同的操作需要进行2次),但它可能是正确的。因为数据泄露问题非常重要,为了解决代码重复编写的问题,可以使用sklearn 库的pipeline。简单地说,pipeline就是将数据作为输入发送到的所有操作步骤的组合,这样我们只要设定好操作,无论是训练集还是测试集,都可以使用相同的步骤进行处理,减少的代码开发的同时还可以减少出错的概率。
위 내용은 Python을 사용한 데이터 정리에 대한 전체 가이드의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7549
7549
 15
1382
52
83
11
58
19
22
90
15
1382
52
83
11
58
19
22
90

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
CentOS 시스템에 Pytorch를 설치할 때는 적절한 버전을 신중하게 선택하고 다음 주요 요소를 고려해야합니다. 1. 시스템 환경 호환성 : 운영 체제 : CentOS7 이상을 사용하는 것이 좋습니다. Cuda 및 Cudnn : Pytorch 버전 및 Cuda 버전은 밀접하게 관련되어 있습니다. 예를 들어, pytorch1.9.0은 cuda11.1을 필요로하고 Pytorch2.0.1은 cuda11.3을 필요로합니다. CUDNN 버전도 CUDA 버전과 일치해야합니다. Pytorch 버전을 선택하기 전에 호환 CUDA 및 CUDNN 버전이 설치되었는지 확인하십시오. 파이썬 버전 : Pytorch 공식 지점
