

Python은 관광 명소 정보 및 리뷰를 획득하고 워드 클라우드 및 데이터 시각화를 생성합니다.


안녕하세요 여러분 잔슈씨 입니다!
멀리서 친구가 찾아오면 참 좋지 않을까요? 친구들이 우리와 함께 놀러 오는 것은 매우 행복한 일이므로 집주인이되어 친구들을 데리고 놀 수 있도록 최선을 다해야합니다! 그래서 질문은 언제 가장 좋은 시간과 어디로 가야 하는지, 그리고 가장 재미있는 장소는 어디인가 하는 것입니다.
오늘은 스레드 풀을 활용해 관광지 정보를 크롤링하고, 같은 여행의 데이터를 리뷰하고, 워드클라우드와 데이터 시각화를 만드는 방법을 차근차근 가르쳐드리겠습니다! ! ! 다양한 도시의 관광명소 정보를 알려드립니다.
데이터 크롤링을 시작하기 전에 먼저 스레드에 대해 이해해 봅시다.
Thread
프로세스: 프로세스는 데이터 수집에 대한 코드의 실행 활동이며 시스템의 리소스 할당 및 예약의 기본 단위입니다.
스레드: 경량 프로세스이자 프로그램 실행의 최소 단위이자 프로세스의 실행 경로입니다.
프로세스에는 하나 이상의 스레드가 있으며 프로세스의 여러 스레드는 프로세스의 리소스를 공유합니다.
스레드 수명주기
다중 스레드를 생성하기 전에 먼저 아래 그림과 같이 스레드 수명주기에 대해 알아봅시다.
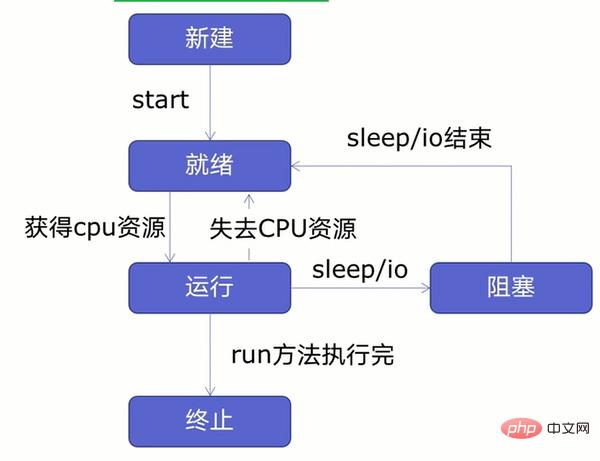
그림에서 볼 수 있듯이 스레드는 5가지 상태로 나눌 수 있습니다. - New , 준비 및 실행 중, 차단, 종료.
먼저 새 스레드를 생성하고 스레드를 시작합니다. 스레드가 준비 상태에 들어간 후에는 CPU 리소스를 얻은 후에만 실행 상태로 들어갑니다. 스레드는 CPU 리소스를 잃거나 발생할 수 있습니다. 절전 또는 IO 작업(읽기, 쓰기 등) 시 스레드는 준비 상태 또는 차단 상태로 들어가며 절전, IO 작업이 끝나거나 CPU 리소스가 부족할 때까지 실행 상태로 들어가지 않습니다. 실행 후 종료 상태로 들어갑니다.
참고: 새로운 스레드 시스템을 생성하려면 리소스 할당이 필요하고, 스레드 시스템을 종료하려면 리소스 재활용이 필요합니다. 그렇다면 스레드 생성/종료에 따른 시스템 오버헤드를 어떻게 줄일 수 있을까요? 이때 스레드 풀을 생성하여 스레드를 재사용할 수 있습니다. 시스템 오버헤드를 줄일 수 있다는 것입니다.
스레드 풀을 만들기 전에 먼저 멀티스레드 생성 방법을 알아볼까요?
멀티 스레드 만들기
멀티 스레드 만들기는 다음 네 단계로 나눌 수 있습니다.
- 스레드 만들기
- 스레드 시작
- 만들기 a function
시연의 편의를 위해 블로그 파크의 웹 페이지를 크롤러 기능으로 사용합니다. 구체적인 코드는 다음과 같습니다. import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))
이전 단계에서는 크롤러 함수를 생성했으며 다음으로 스레드를 생성합니다. 구체적인 코드는 다음과 같습니다. import threading
#多线程
def multi_thread():
threads=[]
for url in urls:
threads.append(
threading.Thread(target=get_parse,args=(url,))
)
- args의 매개변수는 튜플로 전달되어야 하며, 그런 다음 .append() 메서드를 통해 스레드를 빈 스레드 목록에 추가해야 합니다.
스레드가 생성되었으며 다음 스레드가 시작됩니다. 스레드를 시작하는 것은 매우 간단합니다. 구체적인 코드는 다음과 같습니다.for thread in threads:
thread.start()
스레드를 시작한 후 스레드가 끝날 때까지 기다립니다. 구체적인 코드는 다음과 같습니다. for thread in threads:
thread.join()
멀티스레딩이 생성되었습니다. 다음으로, 구체적인 코드는 다음과 같습니다.
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
실행 결과는 다음과 같습니다.
멀티스레딩은 50개의 블로그를 크롤링합니다. 공원 웹 페이지는 1초 이상만 소요되며 다중 스레드 네트워크 요청의 URL은 무작위입니다.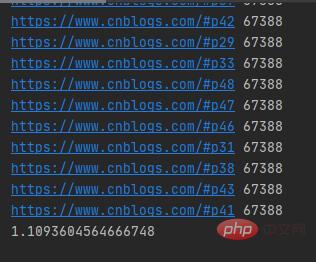 단일 스레드의 실행 시간을 테스트해 보겠습니다. 구체적인 코드는 다음과 같습니다.
단일 스레드의 실행 시간을 테스트해 보겠습니다. 구체적인 코드는 다음과 같습니다.
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
실행 결과는 아래 그림과 같습니다.
블로그 파크 웹 50개를 크롤링하는 데 9초 이상 걸렸습니다. 단일 스레드가 있는 페이지. 네트워크 요청을 보내는 URL은 순차적입니다.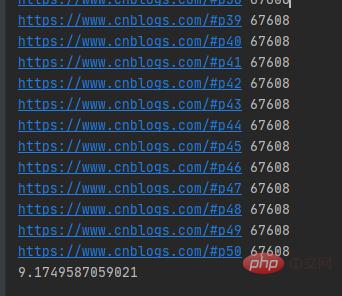 위에서 말했듯이 새로운 스레드 시스템을 만들려면 리소스 할당이 필요하고 스레드 시스템을 종료하려면 리소스 재활용이 필요합니다. 시스템 오버헤드를 줄이기 위해 스레드 풀을 만들 수 있습니다.
위에서 말했듯이 새로운 스레드 시스템을 만들려면 리소스 할당이 필요하고 스레드 시스템을 종료하려면 리소스 재활용이 필요합니다. 시스템 오버헤드를 줄이기 위해 스레드 풀을 만들 수 있습니다.
线程池原理
一个线程池由两部分组成,如下图所示:
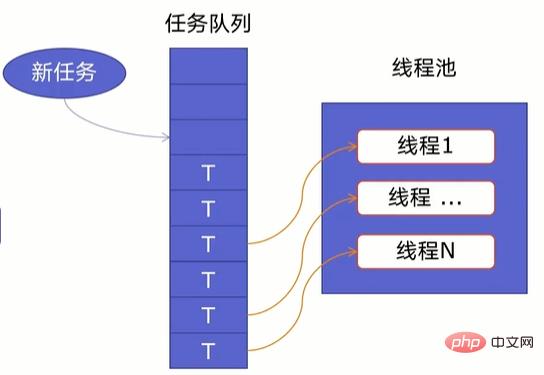
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
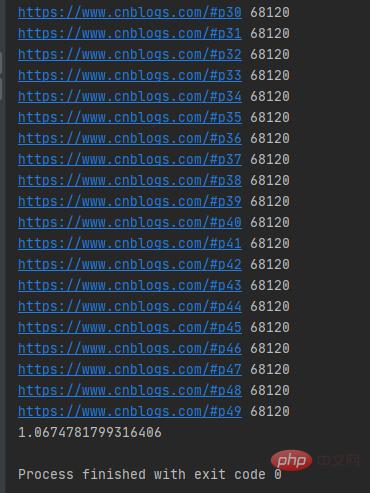
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
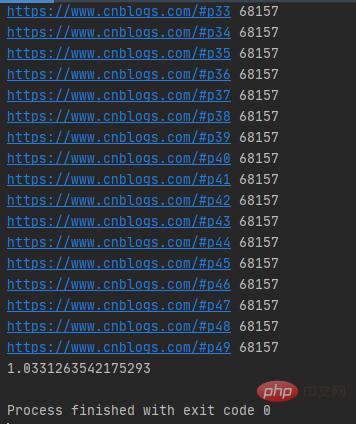
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
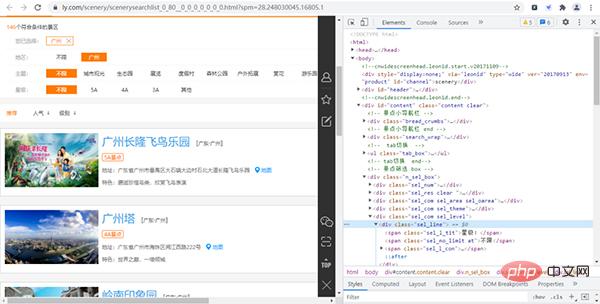
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
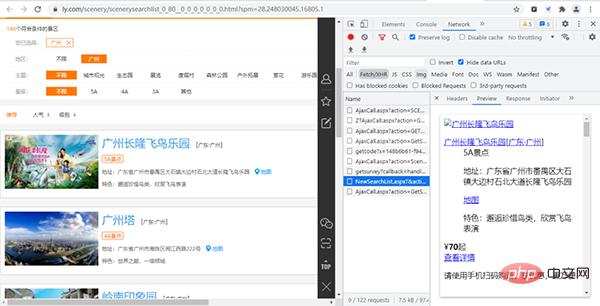
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
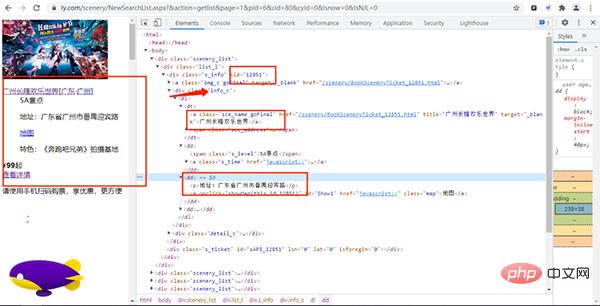
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
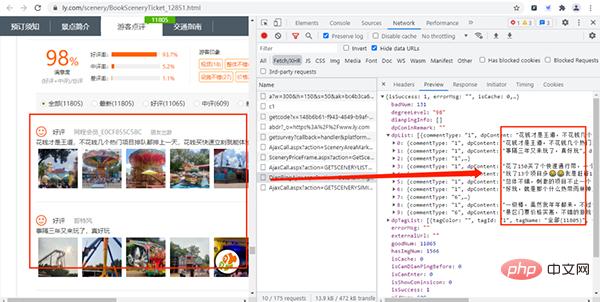
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
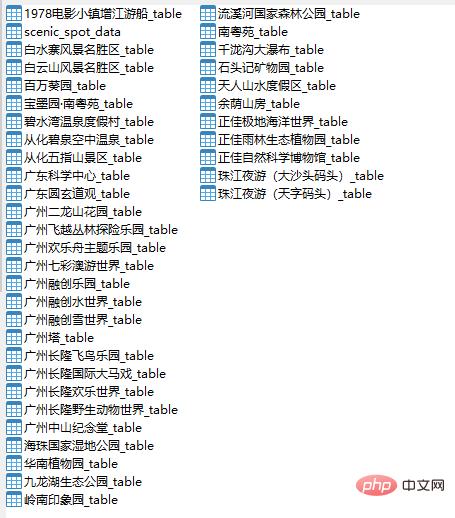
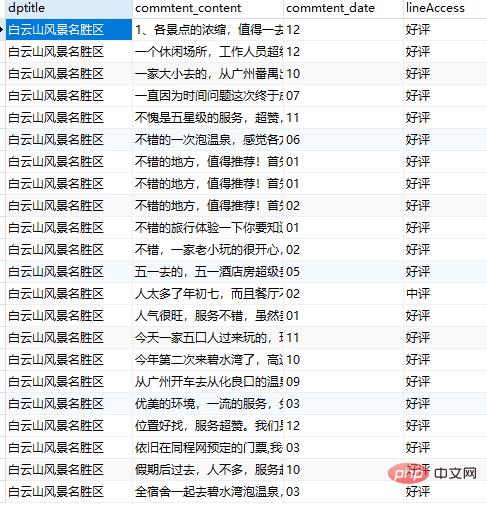
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
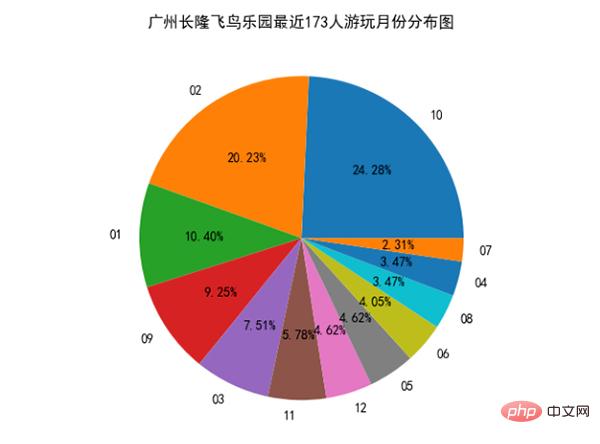
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
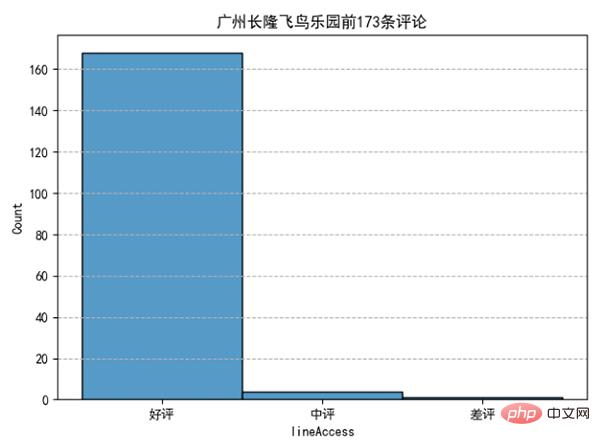
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
위 내용은 Python은 관광 명소 정보 및 리뷰를 획득하고 워드 클라우드 및 데이터 시각화를 생성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7517
7517
 15
1378
52
79
11
53
19
21
66
15
1378
52
79
11
53
19
21
66

 Python vs. C : 응용 및 사용 사례가 비교되었습니다
Apr 12, 2025 am 12:01 AM
Python vs. C : 응용 및 사용 사례가 비교되었습니다
Apr 12, 2025 am 12:01 AM
Python은 데이터 과학, 웹 개발 및 자동화 작업에 적합한 반면 C는 시스템 프로그래밍, 게임 개발 및 임베디드 시스템에 적합합니다. Python은 단순성과 강력한 생태계로 유명하며 C는 고성능 및 기본 제어 기능으로 유명합니다.
 어떤 유형의 파일이 Oracle 데이터베이스로 구성됩니까?
Apr 11, 2025 pm 03:03 PM
어떤 유형의 파일이 Oracle 데이터베이스로 구성됩니까?
Apr 11, 2025 pm 03:03 PM
Oracle 데이터베이스 파일 구조에는 다음이 포함됩니다. 데이터 파일 : 실제 데이터 저장. 제어 파일 : 데이터베이스 구조 정보를 기록합니다. 다시 로그 파일 : 데이터 일관성을 보장하기 위해 트랜잭션 작업을 기록합니다. 매개 변수 파일 : 성능을 최적화하기 위해 데이터베이스 실행 매개 변수를 포함합니다. 아카이브 로그 파일 : 재해 복구를위한 백업 레디 로그 파일.
 Oracle 데이터베이스에 로그인하는 방법
Apr 11, 2025 pm 02:39 PM
Oracle 데이터베이스에 로그인하는 방법
Apr 11, 2025 pm 02:39 PM
Oracle 데이터베이스 로그인에는 사용자 이름과 비밀번호뿐만 아니라 연결 문자열 (서버 정보 및 자격 증명 포함) 및 인증 방법도 포함됩니다. SQL*플러스 및 프로그래밍 언어 커넥터를 지원하며 사용자 이름 및 비밀번호, Kerberos 및 LDAP와 같은 인증 옵션을 제공합니다. 일반적인 오류에는 연결 문자열 오류 및 잘못된 사용자 이름/암호가 포함되며 모범 사례는 연결 풀링, 매개 변수화 쿼리, 인덱싱 및 보안 자격 증명 처리에 중점을 둡니다.
 웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
이 기사는 데비안 시스템에서 Apache Logs를 분석하여 웹 사이트 성능을 향상시키는 방법을 설명합니다. 1. 로그 분석 기본 사항 Apache Log는 IP 주소, 타임 스탬프, 요청 URL, HTTP 메소드 및 응답 코드를 포함한 모든 HTTP 요청의 자세한 정보를 기록합니다. 데비안 시스템 에서이 로그는 일반적으로 /var/log/apache2/access.log 및 /var/log/apache2/error.log 디렉토리에 있습니다. 로그 구조를 이해하는 것은 효과적인 분석의 첫 번째 단계입니다. 2. 로그 분석 도구 다양한 도구를 사용하여 Apache 로그를 분석 할 수 있습니다.
 파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
Python은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 C 디스크에 설치된 Oracle 데이터베이스는 무엇입니까?
Apr 11, 2025 pm 04:21 PM
C 디스크에 설치된 Oracle 데이터베이스는 무엇입니까?
Apr 11, 2025 pm 04:21 PM
C Drive : Registry : 레지스트리 편집기를 사용하여 "Oracle"을 검색하여 설치 경로, 서비스 이름 등을 포함한 정보를 찾기 위해 "Oracle"을 검색하기 위해 "Oracle"을 검색합니다. 파일 시스템 : Oracle 파일은 홈 디렉토리, 시스템 파일, 임시 파일 등을 포함하여 여러 위치에 흩어져 있습니다. 환경 변수 : Oracle_home, Oracle_home, Oracle_home과 같은 환경 변수. 신중한 조치 : Oracle을 제거하면 파일을 삭제해야 할뿐만 아니라 레지스트리 및 서비스를 정리해야합니다. 공식 제거 도구를 사용하거나 전문적인 도움을 구하는 것이 좋습니다. 공간 관리 : C 드라이브에 Oracle 설치를 피하기 위해 디스크 공간을 최적화합니다. 정기적으로 임시 파일을 청소하십시오
 Laravel (PHP) vs. Python : 개발 환경 및 생태계
Apr 12, 2025 am 12:10 AM
Laravel (PHP) vs. Python : 개발 환경 및 생태계
Apr 12, 2025 am 12:10 AM
개발 환경과 생태계에서 Laravel과 Python의 비교는 다음과 같습니다. 1. Laravel의 개발 환경은 간단하며 PHP와 작곡가 만 필요합니다. Laravelforge와 같은 풍부한 확장 패키지를 제공하지만 확장 패키지 유지 보수는시기 적절하지 않을 수 있습니다. 2. 파이썬의 개발 환경도 간단하며 파이썬과 PIP 만 필요합니다. 생태계는 거대하고 여러 분야를 다루지 만 버전 및 종속성 관리는 복잡 할 수 있습니다.
 PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP와 Python은 각각 고유 한 장점이 있으며 프로젝트 요구 사항에 따라 선택합니다. 1.PHP는 웹 개발, 특히 웹 사이트의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 간결한 구문을 가진 데이터 과학, 기계 학습 및 인공 지능에 적합하며 초보자에게 적합합니다.
