

10가지 Python 팁은 데이터 분석 요구 사항의 90%를 다룹니다!

데이터 분석가의 일상 업무에는 데이터 전처리, 데이터 분석, 기계 학습 모델 생성, 모델 배포 등 다양한 작업이 포함됩니다.
이 글에서는 데이터 분석 문제의 90%를 다룰 수 있는 10가지 Python 작업을 공유하겠습니다. 좋아요, 즐겨찾기 및 관심을 얻으세요.
1. 데이터 세트 읽기
데이터 읽기는 데이터 분석의 필수적인 부분입니다. 다양한 파일 형식의 데이터를 읽는 방법을 이해하는 것이 데이터 분석가의 첫 번째 단계입니다. 다음은 팬더를 사용하여 코로나19 데이터가 포함된 csv 파일을 읽는 방법의 예입니다.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
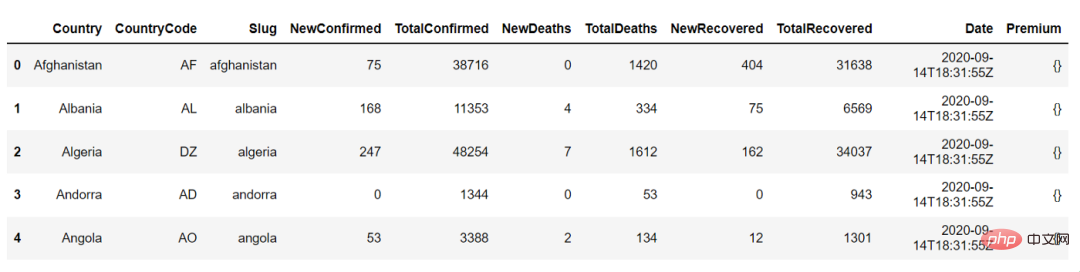
countries_df.head()
다음은 country_df.head()의 출력입니다. 이를 사용하여 데이터 프레임의 처음 5개 행을 볼 수 있습니다.
2. 요약 통계
다음 단계는 데이터를 이해하는 것입니다. NewConfirmed와 같은 데이터 요약, TotalConfirmed와 같은 숫자 열의 개수, 평균, 표준편차, 분위수, 국가 코드와 같은 범주형 열의 빈도 및 최고 발생 값을 볼 수 있습니다.
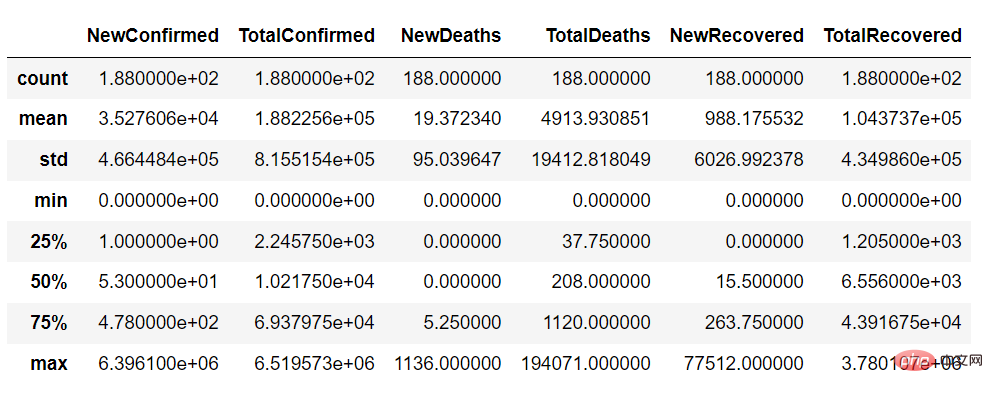
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
describe 함수를 사용하면 데이터 세트의 연속 변수 요약은 다음과 같습니다.
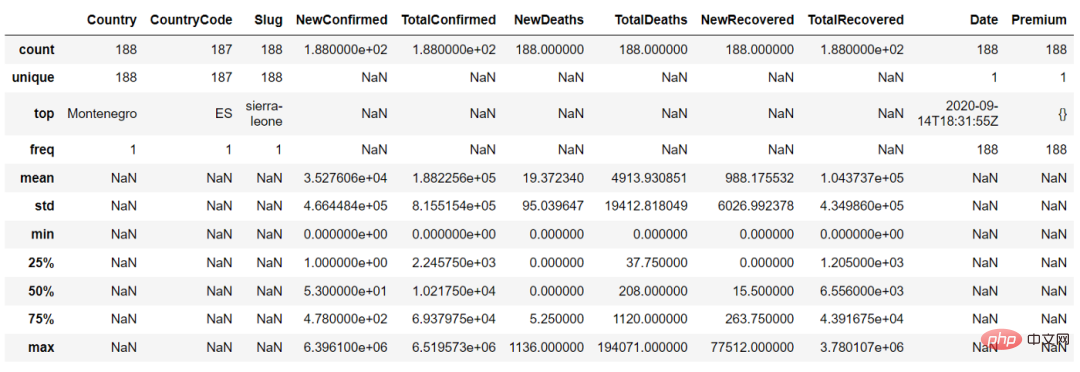
describe() 함수에서 "include = 'all'" 매개변수를 설정하여 연속 변수와 범주형 변수의 요약을 얻을 수 있습니다
countries_df.describe(include = 'all')
3. 데이터 선택 및 필터링
분석에는 실제로 모든 행과 열의 데이터 세트가 필요하지 않으며, 관심 있는 열을 선택하고 질문에 따라 일부 행을 필터링하면 됩니다.
예를 들어 다음 코드를 사용하여 Country 및 NewConfirmed 열을 선택할 수 있습니다.
countries_df[['Country','NewConfirmed']]
또한 loc를 사용하여 Country 데이터를 필터링할 수 있으며 아래와 같이 일부 값을 기반으로 열을 필터링할 수 있습니다.
countries_df.loc[countries_df['Country'] == 'United States of America']

4. 집계
개수, 합계, 평균 등의 데이터 집계는 데이터 분석에서 가장 일반적으로 수행되는 작업 중 하나입니다.
집계를 이용하면 국가별 신규확정 건수를 확인할 수 있습니다. groupby 및 agg 함수를 사용하여 집계를 수행합니다.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5. Join
2개의 데이터 세트를 하나의 데이터 세트로 결합하려면 Join 작업을 사용하세요.
예: 한 데이터 세트에는 여러 국가의 코로나19 사례 수가 포함될 수 있고, 다른 데이터 세트에는 여러 국가의 위도 및 경도 정보가 포함될 수 있습니다.
이제 이 두 정보를 결합해야 아래와 같이 연결 작업을 수행할 수 있습니다
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6. 내장 함수
min(), max(), 평균(), 합계() 등은 다양한 분석을 수행하는 데 매우 유용합니다.
이러한 함수를 호출하여 데이터프레임에 직접 적용할 수 있으며, 이 함수는 아래와 같이 열이나 집계 함수에서 독립적으로 사용할 수 있습니다.
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537. 사용자 정의 함수
우리가 직접 작성한 함수입니다. 사용자 정의 함수. 필요할 때 함수를 호출하여 이러한 함수의 코드를 실행할 수 있습니다. 예를 들어, 다음과 같이 2개의 숫자를 추가하는 함수를 만들 수 있습니다.
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
8, Pivot
Pivot은 열 행 내의 고유 값을 여러 개의 새 열로 변환하는 훌륭한 데이터 처리 기술입니다.
Covid-19 데이터세트에서 피벗_테이블() 함수를 사용하면 국가 이름을 별도의 새 열로 변환할 수 있습니다.
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
9. 데이터 프레임 탐색
데이터의 인덱스와 행을 탐색해야 하는 경우가 많습니다. iterrows 함수를 사용하여 데이터 프레임을 탐색할 수 있습니다:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10. 문자열 작업
데이터 세트의 문자열 열을 다루는 경우가 많으며, 이 경우 몇 가지 기본 문자열 작업을 이해하는 것이 중요합니다.
문자열을 대문자, 소문자로 변환하는 방법, 문자열의 길이를 찾는 방법 등.
아아아아위 내용은 10가지 Python 팁은 데이터 분석 요구 사항의 90%를 다룹니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7461
7461
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17

 PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS "로드"문제는 자원 액세스 또는 처리 문제로 인한 것입니다. 하드 디스크 판독 속도는 느리거나 나쁘다 : CrystalDiskinfo를 사용하여 하드 디스크 건강을 확인하고 문제가있는 하드 디스크를 교체하십시오. 불충분 한 메모리 : 고해상도 이미지 및 복잡한 레이어 처리에 대한 PS의 요구를 충족시키기 위해 메모리 업그레이드 메모리. 그래픽 카드 드라이버는 구식 또는 손상됩니다. 운전자를 업데이트하여 PS와 그래픽 카드 간의 통신을 최적화하십시오. 파일 경로는 너무 길거나 파일 이름에는 특수 문자가 있습니다. 짧은 경로를 사용하고 특수 문자를 피하십시오. PS 자체 문제 : PS 설치 프로그램을 다시 설치하거나 수리하십시오.
 PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
부팅 할 때 "로드"에 PS가 붙어있는 여러 가지 이유로 인해 발생할 수 있습니다. 손상되거나 충돌하는 플러그인을 비활성화합니다. 손상된 구성 파일을 삭제하거나 바꾸십시오. 불충분 한 메모리를 피하기 위해 불필요한 프로그램을 닫거나 메모리를 업그레이드하십시오. 하드 드라이브 독서 속도를 높이기 위해 솔리드 스테이트 드라이브로 업그레이드하십시오. 손상된 시스템 파일 또는 설치 패키지 문제를 복구하기 위해 PS를 다시 설치합니다. 시작 오류 로그 분석의 시작 과정에서 오류 정보를 봅니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
깃털 통제의 열쇠는 점진적인 성격을 이해하는 것입니다. PS 자체는 그라디언트 곡선을 직접 제어하는 옵션을 제공하지 않지만 여러 깃털, 일치하는 마스크 및 미세 선택으로 반경 및 구배 소프트를 유연하게 조정하여 자연스럽게 전이 효과를 달성 할 수 있습니다.
 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드의로드 인터페이스는 소프트웨어 자체 (파일 손상 또는 플러그인 충돌), 시스템 환경 (DIFE 드라이버 또는 시스템 파일 손상) 또는 하드웨어 (하드 디스크 손상 또는 메모리 스틱 고장)로 인해 발생할 수 있습니다. 먼저 컴퓨터 자원이 충분한 지 확인하고 배경 프로그램을 닫고 메모리 및 CPU 리소스를 릴리스하십시오. PS 설치를 수정하거나 플러그인의 호환성 문제를 확인하십시오. PS 버전을 업데이트하거나 폴백합니다. 그래픽 카드 드라이버를 확인하고 업데이트하고 시스템 파일 확인을 실행하십시오. 위의 문제를 해결하면 하드 디스크 감지 및 메모리 테스트를 시도 할 수 있습니다.
 PS 페더 링을 설정하는 방법?
Apr 06, 2025 pm 07:36 PM
PS 페더 링을 설정하는 방법?
Apr 06, 2025 pm 07:36 PM
PS 페더 링은 이미지 가장자리 블러 효과로, 가장자리 영역에서 픽셀의 가중 평균에 의해 달성됩니다. 깃털 반경을 설정하면 흐림 정도를 제어 할 수 있으며 값이 클수록 흐려집니다. 반경을 유연하게 조정하면 이미지와 요구에 따라 효과를 최적화 할 수 있습니다. 예를 들어, 캐릭터 사진을 처리 할 때 더 작은 반경을 사용하여 세부 사항을 유지하고 더 큰 반경을 사용하여 예술을 처리 할 때 흐릿한 느낌을줍니다. 그러나 반경이 너무 커서 가장자리 세부 사항을 쉽게 잃을 수 있으며 너무 작아 효과는 분명하지 않습니다. 깃털 효과는 이미지 해상도의 영향을받으며 이미지 이해 및 효과 파악에 따라 조정해야합니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
