
번역가 | Cui Hao
리뷰어 | Sun Shujuan
이 기사에서는 TypeDB가 과학자들이 의학의 차세대 혁신을 달성하는 데 어떻게 도움이 되는지 살펴보고 안내된 코드 예제와 시각 효과를 통해 결과를 보여줍니다.

생명공학 세계에는 혁신적인 약물 발견에 초점을 맞춘 과장된 광고가 많이 있습니다. 결국 지난 10년은 이 분야의 황금기였습니다. 지난 10년에 비해 2012년부터 2021년 사이에 신약이 73% 더 많이 승인되었으며, 이는 지난 10년보다 25% 증가한 수치입니다. 여기에는 암 치료를 위한 면역요법, 유전자 요법, 그리고 물론 코비드 백신이 포함됩니다. 이러한 측면에서 제약산업이 잘되고 있음을 알 수 있다.
그런데 추세가 점점 걱정스럽네요. 신약 발견의 비용과 위험은 엄청나게 커지고 있습니다. 현재까지 신약을 시장에 내놓는 데 드는 평균 비용은 10억~30억 달러이고, 평균 시간은 12~18년이다. 동시에 신약의 평균 가격은 2007년 2000달러에서 2021년 18만달러로 치솟았다.
이것이 바로 많은 사람들이 초기 표적 식별부터 임상시험까지 신약 개발을 가속화하는 데 도움이 되는 통계적 기계 학습 등 인공 지능(AI)에 기대를 걸고 있는 이유입니다. 다양한 기계 학습 알고리즘을 사용하여 일부 화합물이 식별되었지만 이러한 화합물은 아직 초기 발견 또는 전임상 개발 단계에 있습니다. 신약 발견에 혁명을 일으킬 인공지능의 약속은 여전히 흥미롭지만 실현되지 않은 약속입니다.
이 약속을 실현하려면 인공지능이 실제로 무엇을 의미하는지 이해하는 것이 중요합니다. 최근 몇 년간 인공지능이라는 용어는 별다른 기술적인 내용 없이 꽤 대중적인 용어가 됐다. 그렇다면 진짜 인공지능이란 무엇일까?
학문 분야로서 인공 지능은 1950년대부터 존재해 왔으며 시간이 지남에 따라 다양한 학습 스타일을 대표하는 다양한 유형으로 분기되었습니다. Pedro Domingos 교수는 자신의 저서 Masters of Algorithms: Connectionists, Symbolists, Evolutionists, Bayesians and Simulationist에서 이러한 유형(그는 이를 "부족"이라고 부름)을 설명합니다.
베이즈주의자들과 연결주의자들은 지난 10년 동안 많은 대중의 관심을 받았지만 상징주의자들은 그렇지 않았습니다. 기호학은 논리적 추론을 위한 일련의 규칙을 기반으로 세계를 사실적으로 표현합니다. 상징적 AI 시스템은 다른 유형의 AI가 누리는 것처럼 크게 유명하지는 않지만 다른 유형이 부족한 독특하고 중요한 기능, 즉 자동화된 추론 및 지식 표현을 보유하고 있습니다.
사실 지식 표현의 문제는 신약개발의 가장 큰 문제 중 하나입니다. 관계형 데이터베이스나 그래프 데이터베이스와 같은 기존 데이터베이스 소프트웨어는 생물학의 복잡성을 정확하게 표현하고 이해하는 데 어려움을 겪고 있습니다.
Drug Discovery가 공식화한 문제는 Uniprot 또는 Disgenet와 같은 다양한 생물의학 데이터 소스에 대한 통합 모델을 구축해야 하는 필요성을 보여주는 좋은 예입니다. 데이터베이스 수준에서 이는 단백질, 유전자, 약물, 질병, 상호 작용 등과 같은 수많은 복잡한 개체와 관계를 설명하는 데이터 모델(일부는 이러한 온톨로지라고도 함)을 생성하는 것을 의미합니다.
오픈 소스 데이터베이스 소프트웨어인 TypeDB의 목표는 개발자가 컴퓨터가 통찰력을 얻기 위해 활용할 수 있는 매우 복잡한 도메인을 현실적으로 표현할 수 있도록 하는 것입니다.
TypeDB의 타입 시스템은 TypeDB에 저장된 데이터를 나타내는 엔터티 관계 개념을 기반으로 합니다. 이를 통해 유형 추론, 중첩 관계, 초관계, 규칙 추론 등을 통해 복잡한 생물의학 도메인 지식을 포착할 수 있을 만큼 강력하므로 과학자는 통찰력을 얻고 약물 개발 시간을 가속화할 수 있습니다.
이는 시맨틱 웹 표준을 사용하여 질병 네트워크 모델링을 위해 5년 이상 고군분투했지만 TypeDB로 마이그레이션한 후 단 3주 만에 성공적으로 달성한 대형 제약회사의 예에서 설명됩니다.
예를 들어, TypeQL(TypeDB의 쿼리 언어)로 작성된 단백질, 유전자 및 질병을 설명하는 생의학 모델은 다음과 같습니다.
define protein sub entity, owns uniprot-id, plays protein-disease-association:protein, plays encode:encoded-protein; gene sub entity, owns entrez-id, plays gene-disease-association:gene, plays encode:encoding-gene; disease sub entity, owns disease-name, plays gene-disease-association:disease, plays protein-disease-association:disease; encode sub relation, relates encoded-protein, relates encoding-gene; protein-disease-association sub relation, relates protein, relates disease; gene-disease-association sub relation, relates gene, relates disease; uniprot-id sub attribute, value string; entrez-id sub attribute, value string; disease-name sub attribute, value string;
완전한 작업 예를 보려면 Github Knowledge 그래프에서 오픈 소스 생의학 모델을 찾을 수 있습니다. 이는 Uniprot, Disgenet, Reactome 등과 같은 잘 알려진 다양한 생의학 리소스의 데이터를 로드하여 수행됩니다.
TypeDB에 저장된 데이터를 사용하여 다음과 같은 질문을 묻는 쿼리를 실행할 수 있습니다. SARS 바이러스와 관련된 유전자와 상호 작용하는 약물은 무엇입니까?
이 질문에 답하기 위해 TypeQL에서 다음 쿼리를 사용할 수 있습니다.
match $virus isa virus, has virus-name "SARS"; $gene isa gene; $drug isa drug; ($virus, $gene) isa gene-virus-association; ($gene, $drug) isa drug-gene-interaction;
이를 실행하면 TypeDB가 쿼리 기준과 일치하는 데이터를 반환합니다. 아래와 같이 TypeDB Studio에서 시각화할 수 있으며, 이는 어떤 관련 약물이 추가 조사를 받을 가치가 있는지 이해하는 데 도움이 됩니다.
通过自动推理,TypeDB也可以推断出数据库中不存在的知识。这是通过编写规则来完成的,这些规则构成了TypeDB中模式的一部分。例如,一个规则可以推断出一个基因和一种疾病之间的关联,如果该基因编码的蛋白质与该疾病有关。这样的规则将被写成:
rule inference-example:
when {
(encoding-gene: $gene, encoded-protein: $protein) isa encode;
(protein: $protein, disease: $disease) isa protein-disease-association;
} then {
(gene: $gene, disease: $disease) isa gene-disease-association;
};然后,如果我们要插入以下数据:
TypeDB将能够推断出基因和疾病之间的联系,即使没有插入到数据库中。在这种情况下,以下关系基因-疾病-关联将被推断出来。
match $gene isa gene, has gene-id "2"; $disease isa disease, has disease-name $dn; ; (gene: $gene, disease:$disease) isa gene-disease-assocation;
有了TypeDB对生物医学数据(符号)进行表示,再加上机器学习的上下文知识就可以让整个系统变得更加强大,从而增强洞察力。例如,可以通过药物探索管道发现有希望的目标。
寻找有希望的目标的方法是使用链接预测算法。TypeDB的规则引擎允许这样的ML模型执行,该模型通过推理推断对事实进行学习。这意味着从对平面的、无背景的数据学习转向对推理的、有背景的知识学习。其中一个好处是,根据领域的逻辑规则,预测可以被概括到训练数据的范围之外,并减少所需的训练数据量。
这样一个药物发现的工作流程如下:
1. 查询TypeDB,创建上下文知识的子图,利用TypeDB的全部表达能力。
2. 将子图转化为嵌入(embedding),并将这些嵌入到图学习算法中。
3. 预测结果(例如,作为基因-疾病关联之间的概率分数)可以被插入TypeDB,并用于验证/优先考虑某些目标。
有了数据库中的这些预测,我们可以提出更高层次的问题,利用这些预测与数据库中更广泛的背景知识。比如说:什么是最有可能成为黑色素瘤的基因目标,这些基因编码的蛋白质在黑色素细胞中如何表达?
用TypeQL写,这个问题看起来如下:
match $gene isa gene, has gene-id $gene-id; $protein isa protein; $cell isa cell, has cell-type "melanocytes"; $disease isa disease, has disease-name "melanoma"; ($gene, $protein) isa encode; ($protein, $cell) isa expression; ($gene, $disease) isa gene-disease-association, has prob $p; get $gene-id; sort desc $p;
这个查询的结果将是一个按概率分数排序的基因列表(如图学习者预测的):
{$gid "TOPGENE" isa gene-id;}
{$gid "BESTGENE" isa gene-id;}
{$gid "OTHERTARGET" isa gene-id;}
...然后,我们可以进一步研究这些基因,例如通过了解每个基因的生物学背景。比方说,我们想知道TOPGENE基因编码的蛋白质所处的组织。我们可以写下面的查询。
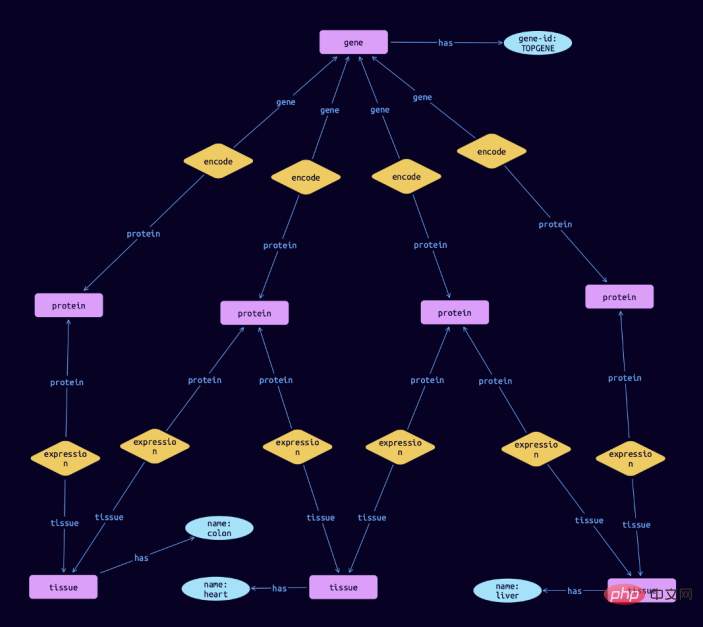
match $gene isa gene, has gene-id $gene-id; $gene-id "TOPGENE"; $protein isa protein; $tissue isa tissue, has name $name; $rel1 ($gene, $protein); $rel2 ($protein, $tissue);
在TypeDB Studio中可视化的结果,可以显示这个基因编码的蛋白质在结肠、心脏和肝脏中的表达:
世界迫切需要创造治疗破坏性疾病的解决方案,希望通过人工智能的创新建立一个更健康的世界,在这个世界中每种疾病都可以被治疗。人工智能作用于药物探索仍处于起步阶段,但是如果一旦实现将会让生物学释放出新的创新浪潮,并使21世纪真正成为属于它的纪元。
在这篇文章中,我们看了TypeDB是如何实现生物医学知识的符号化表示,以及如何改善ML来为药物探索做出贡献的。在药物探索中应用人工智能的科学家们使用TypeDB来分析疾病网络,更好地理解生物医学研究的复杂性,并发现新的和突破性的治疗方式。
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:Artificial Intelligence in Drug Discovery,作者:Tomás Sabat
위 내용은 의학발견의 인공지능의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



