

Python을 사용하여 주택 가격 예측 도구를 만들어보세요!


안녕하세요 여러분.
캐글 홈페이지에서 나온 집값 예측 사례입니다. 많은 알고리즘 초보자들이 겪는 첫 번째 경쟁 질문입니다.
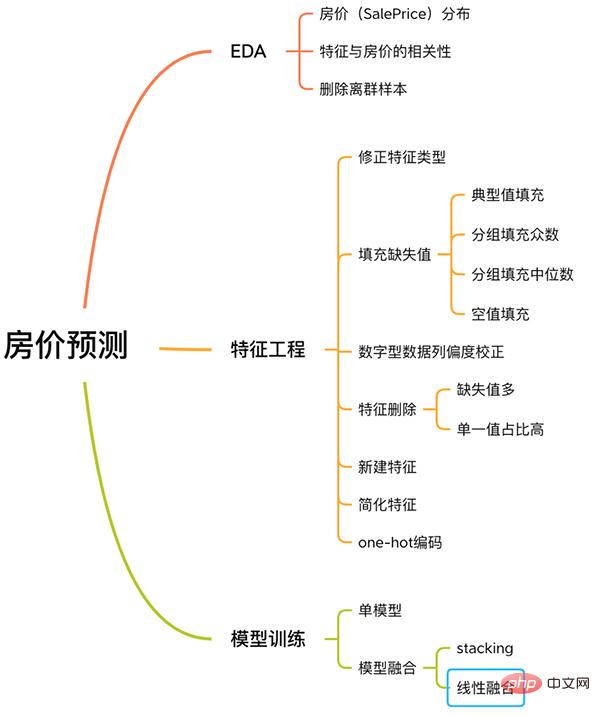
이 사례에는 EDA, 기능 엔지니어링, 모델 훈련, 모델 융합 등을 포함하여 기계 학습 문제를 해결하기 위한 완전한 프로세스가 포함되어 있습니다.
집값 예측 과정
이 사례에 대해 알아보려면 아래를 팔로우하세요.
긴 단어도, 중복된 코드도 없고, 간단한 설명만 있으면 됩니다.
1. EDA
탐색적 데이터 분석(EDA)의 목적은 데이터 세트에 대한 완전한 이해를 제공하는 것입니다. 이 단계에서 우리가 탐색하는 콘텐츠는 다음과 같습니다.

EDA 콘텐츠
1.1 입력 데이터 세트
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')

Training 샘플
train과 test는 각각 1460개의 샘플이 포함된 training set과 test set입니다. 각각 80개의 기능을 제공합니다.
SalePrice 열은 우리가 예측하려는 주택 가격을 나타냅니다.
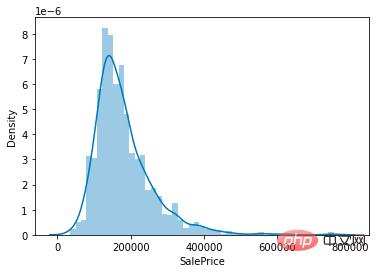
1.2 주택 가격 분포
우리의 임무는 주택 가격을 예측하는 것이므로 데이터 세트에서 핵심적으로 집중해야 할 것은 주택 가격(SalePrice) 열의 가치 분포입니다.
sns.distplot(train['SalePrice']);
집값 분포
그림에서 알 수 있듯이 SalePrice 열의 최고값이 상대적으로 가파르고, 최고값이 왼쪽으로 치우쳐 있습니다.
SlePrice의 특정 왜도 및 첨도 값을 계산하기 위해skew() 및 kurt() 함수를 직접 호출할 수도 있습니다.
왜도와 첨도가 상대적으로 큰 상황에서는 log()를 사용하여 SalePrice 열을 평활화하는 것이 좋습니다.
1.3 주택 가격과 관련된 특징
SalePrice의 분포를 이해한 후에는 80가지 특징과 SalePrice 간의 상관 관계를 계산할 수 있습니다.
SalePrice와 가장 강한 상관관계가 있는 10가지 기능에 집중하세요.
# 计算列之间相关性
corrmat = train.corr()
# 取 top10
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
# 绘图
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
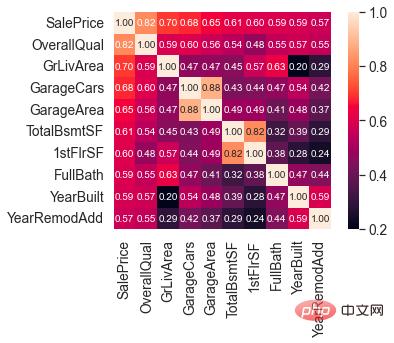
SalePrice와 높은 상관관계가 있는 기능
OverallQual(집 자재 및 마감재), GrLivArea(지상 생활 공간), GarageCars(차고 용량) 및 TotalBsmtSF(지하 공간)는 SalePrice와 높은 상관관계가 있습니다.
이러한 기능은 나중에 기능 엔지니어링을 수행할 때 중점적으로 다루겠습니다.
1.4 이상값 샘플 제거
데이터 세트의 샘플 크기가 매우 작기 때문에 이상값은 이후 모델 교육에 도움이 되지 않습니다.
따라서 각 수치 특성의 이상값을 계산하고 이상값이 가장 많은 샘플을 제거해야 합니다.
# 获取数值型特征 numeric_features = train.dtypes[train.dtypes != 'object'].index # 计算每个特征的离群样本 for feature in numeric_features: outs = detect_outliers(train[feature], train['SalePrice'],top=5, plot=False) all_outliers.extend(outs) # 输出离群次数最多的样本 print(Counter(all_outliers).most_common()) # 剔除离群样本 train = train.drop(train.index[outliers])
Detect_outliers()는 sklearn 라이브러리의 LocalOutlierFactor 알고리즘을 사용하여 이상값을 계산하는 사용자 정의 함수입니다.
이제 EDA가 완성되었습니다. 마지막으로 훈련 세트와 테스트 세트를 병합하여 다음과 같은 기능 엔지니어링을 수행합니다.
y = train.SalePrice.reset_index(drop=True) train_features = train.drop(['SalePrice'], axis=1) test_features = test features = pd.concat([train_features, test_features]).reset_index(drop=True)
features는 훈련 세트와 테스트 세트의 기능을 결합한 것으로, 아래에서 처리할 데이터입니다.
2. Feature Engineering
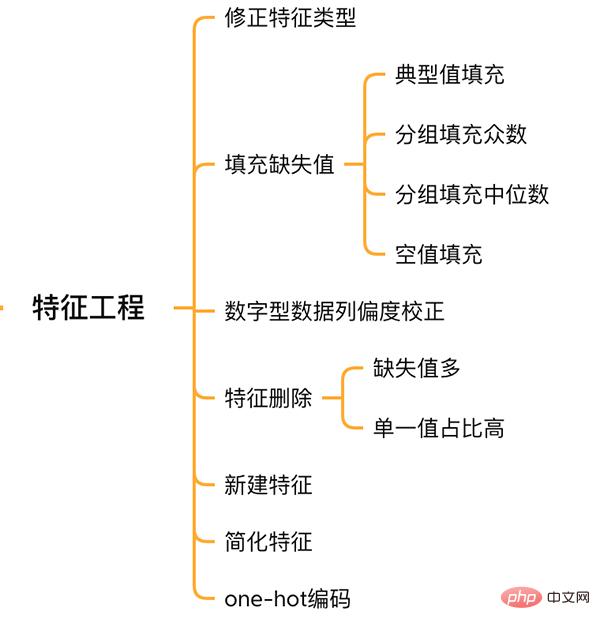
Feature Engineering
2.1 수정 특성 유형
MSSubClass(주택 유형), YrSold(판매 연도) 및 MoSold(판매 월)는 범주형 특성이지만 숫자로 표시됩니다. 텍스트 기능으로 변환해야 합니다.
features['MSSubClass'] = features['MSSubClass'].apply(str) features['YrSold'] = features['YrSold'].astype(str) features['MoSold'] = features['MoSold'].astype(str)
2.2 특성에 결측값 채우기
결측값 채우기에 대한 통일된 표준은 없습니다. 이를 어떤 방식으로 채울 것인지는 다양한 특성에 따라 결정되어야 합니다.
# Functional:文档提供了典型值 Typ
features['Functional'] = features['Functional'].fillna('Typ') #Typ 是典型值
# 分组填充需要按照相似的特征分组,取众数或中位数
# MSZoning(房屋区域)按照 MSSubClass(房屋)类型分组填充众数
features['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
#LotFrontage(到接到举例)按Neighborhood分组填充中位数
features['LotFrontage'] = features.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 车库相关的数值型特征,空代表无,使用0填充空值。
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
features[col] = features[col].fillna(0)
2.3 왜도 수정
은 SalePrice 열을 탐색하는 것과 유사하며 왜도가 높은 특징을 평활화합니다.
# skew()方法,计算特征的偏度(skewness)。 skew_features = features[numeric_features].apply(lambda x: skew(x)).sort_values(ascending=False) # 取偏度大于 0.15 的特征 high_skew = skew_features[skew_features > 0.15] skew_index = high_skew.index # 处理高偏度特征,将其转化为正态分布,也可以使用简单的log变换 for i in skew_index: features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
2.4 특성 삭제 및 추가
거의 모든 결측값이거나 단일값의 비율(99.94%)이 높은 특성은 직접 삭제할 수 있습니다.
features = features.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
동시에 여러 기능을 융합하여 새로운 기능을 생성할 수 있습니다.
모델이 특성 간의 관계를 학습하는 것이 어려울 때도 있습니다. 특성을 수동으로 융합하면 모델의 학습 난이도를 줄이고 효과를 높일 수 있습니다.
# 将原施工日期和改造日期融合 features['YrBltAndRemod']=features['YearBuilt']+features['YearRemodAdd'] # 将地下室面积、1楼、2楼面积融合 features['TotalSF']=features['TotalBsmtSF'] + features['1stFlrSF'] + features['2ndFlrSF']
우리가 융합한 기능은 모두 SalePrice와 밀접한 관련이 있는 기능임을 알 수 있습니다.
마지막으로 특성을 단순화하고 단조로운 분포를 갖는 특성에 대해 01 처리를 수행합니다(예: 100개 데이터 중 99개 데이터의 값은 0.9이고 다른 하나의 값은 0.1입니다).
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0) features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
2.6 生成最终训练数据
到这里特征工程就做完了, 我们需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :] X_sub = features.iloc[len(y):, :] X = np.array(X.copy()) y = np.array(y) X_sub = np.array(X_sub.copy())
三. 模型训练
因为SalePrice是数值型且是连续的,所以需要训练一个回归模型。
3.1 单一模型
首先以岭回归(Ridge) 为例,构造一个k折交叉验证模型。
from sklearn.linear_model import RidgeCV from sklearn.pipeline import make_pipeline from sklearn.model_selection import KFold kfolds = KFold(n_splits=10, shuffle=True, random_state=42) alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5] ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
岭回归模型有一个超参数alpha,而RidgeCV的参数名是alphas,代表输入一个超参数alpha数组。在拟合模型时,会从alpha数组中选择表现较好某个取值。
由于现在只有一个模型,无法确定岭回归是不是最佳模型。所以我们可以找一些出场率高的模型多试试。
# lasso lasso = make_pipeline( RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds)) #elastic net elasticnet = make_pipeline( RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio)) #svm svr = make_pipeline(RobustScaler(), SVR( C=20, epsilon=0.008, gamma=0.0003, )) #GradientBoosting(展开到一阶导数) gbr = GradientBoostingRegressor(...) #lightgbm lightgbm = LGBMRegressor(...) #xgboost(展开到二阶导数) xgboost = XGBRegressor(...)
有了多个模型,我们可以再定义一个得分函数,对模型评分。
#模型评分函数 def cv_rmse(model, X=X): rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=kfolds)) return (rmse)
以岭回归为例,计算模型得分。
score = cv_rmse(ridge)
print("Ridge score: {:.4f} ({:.4f})n".format(score.mean(), score.std()), datetime.now(), ) #0.1024
运行其他模型发现得分都差不多。
这时候我们可以任选一个模型,拟合,预测,提交训练结果。还是以岭回归为例
# 训练模型
ridge.fit(X, y)
# 模型预测
submission.iloc[:,1] = np.floor(np.expm1(ridge.predict(X_sub)))
# 输出测试结果
submission = pd.read_csv("./data/sample_submission.csv")
submission.to_csv("submission_single.csv", index=False)
submission_single.csv是岭回归预测的房价,我们可以把这个结果上传到 Kaggle 网站查看结果的得分和排名。
3.2 模型融合-stacking
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
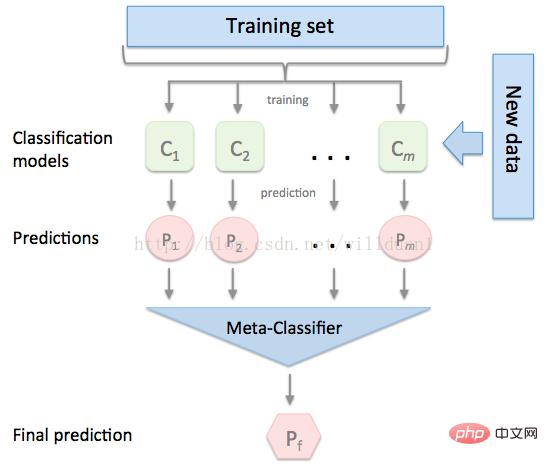
stacking
这里,我们用mlextend库中的StackingCVRegressor模块,对模型做stacking。
stack_gen = StackingCVRegressor( regressors=(ridge, lasso, elasticnet, gbr, xgboost, lightgbm), meta_regressor=xgboost, use_features_in_secondary=True)
训练、预测的过程与上面一样,这里不再赘述。
3.3 模型融合-线性融合
多模型线性融合的思想很简单,给每个模型分配一个权重(权重加和=1),最终的预测结果取各模型的加权平均值。
# 训练单个模型 ridge_model_full_data = ridge.fit(X, y) lasso_model_full_data = lasso.fit(X, y) elastic_model_full_data = elasticnet.fit(X, y) gbr_model_full_data = gbr.fit(X, y) xgb_model_full_data = xgboost.fit(X, y) lgb_model_full_data = lightgbm.fit(X, y) svr_model_full_data = svr.fit(X, y) models = [ ridge_model_full_data, lasso_model_full_data, elastic_model_full_data, gbr_model_full_data, xgb_model_full_data, lgb_model_full_data, svr_model_full_data, stack_gen_model ] # 分配模型权重 public_coefs = [0.1, 0.1, 0.1, 0.1, 0.15, 0.1, 0.1, 0.25] # 线性融合,取加权平均 def linear_blend_models_predict(data_x,models,coefs, bias): tmp=[model.predict(data_x) for model in models] tmp = [c*d for c,d in zip(coefs,tmp)] pres=np.array(tmp).swapaxes(0,1) pres=np.sum(pres,axis=1) return pres
到这里,房价预测的案例我们就讲解完了,大家可以自己运行一下,看看不同方式训练出来的模型效果。
回顾整个案例会发现,我们在数据预处理和特征工程上花费了很大心思,虽然机器学习问题模型原理比较难学,但实际过程中往往特征工程花费的心思最多。
위 내용은 Python을 사용하여 주택 가격 예측 도구를 만들어보세요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7554
7554
 15
1382
52
83
11
59
19
24
96
15
1382
52
83
11
59
19
24
96

 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 Composer를 사용하여 WordPress 설치 및 업데이트의 복잡성을 해결하는 방법
Apr 17, 2025 pm 10:54 PM
Composer를 사용하여 WordPress 설치 및 업데이트의 복잡성을 해결하는 방법
Apr 17, 2025 pm 10:54 PM
WordPress 웹 사이트를 관리 할 때는 종종 설치, 업데이트 및 다중 사이트 변환과 같은 복잡한 작업이 발생합니다. 이러한 작업은 시간이 많이 걸릴뿐만 아니라 오류가 발생하기 쉬우므로 웹 사이트를 마비시킵니다. WP-CLI Core 명령을 Composer와 결합하면 이러한 작업을 크게 단순화하고 효율성과 안정성을 향상시킬 수 있습니다. 이 기사는 작곡가를 사용하여 이러한 문제를 해결하고 WordPress 관리의 편의성을 향상시키는 방법을 소개합니다.
 PHP 코드 검사 가속화 : Overtrue/Phplint Library 사용 경험 및 실습
Apr 17, 2025 pm 11:06 PM
PHP 코드 검사 가속화 : Overtrue/Phplint Library 사용 경험 및 실습
Apr 17, 2025 pm 11:06 PM
개발 프로세스 중에는 종종 코드의 정확성과 유지 가능성을 보장하기 위해 PHP 코드에서 구문 검사를 수행해야합니다. 그러나 프로젝트가 커지면 단일 스레드 구문 검사 프로세스가 매우 느려질 수 있습니다. 최근에 저는 프로젝트 에서이 문제를 겪었습니다. 여러 가지 방법을 시도한 후 마침내 라이브러리 오버 트루/phplint를 발견하여 병렬 처리를 통해 코드 검사 속도를 크게 향상시킵니다.
 Laravel의 관계 문제에 대한 복잡한 소속 문제를 해결하는 방법은 무엇입니까? 작곡가를 사용하십시오!
Apr 17, 2025 pm 09:54 PM
Laravel의 관계 문제에 대한 복잡한 소속 문제를 해결하는 방법은 무엇입니까? 작곡가를 사용하십시오!
Apr 17, 2025 pm 09:54 PM
Laravel Development에서 복잡한 모델 관계를 다루는 것은 항상 어려운 관계와 관련하여 도전이되었습니다. 최근에, 나는 전통적인 Hasmanythrough 관계가 요구를 충족시키지 못해 데이터 쿼리가 복잡하고 비효율적이되는 다단계 모델 관계를 다루는 프로젝트 에서이 문제를 발견했습니다. 약간의 탐사 후, 나는 도서관 Staudenmeir/Sogle-Strough를 발견했으며, 이는 작곡가를 통해 내 문제를 쉽게 설치하고 해결했습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 SQL 구문 분석 문제를 해결하는 방법은 무엇입니까? Greenlion/PHP-SQL-Parser를 사용하십시오!
Apr 17, 2025 pm 09:15 PM
SQL 구문 분석 문제를 해결하는 방법은 무엇입니까? Greenlion/PHP-SQL-Parser를 사용하십시오!
Apr 17, 2025 pm 09:15 PM
SQL 문을 구문 분석 해야하는 프로젝트를 개발할 때 까다로운 문제가 발생했습니다. MySQL의 SQL 문을 효율적으로 구문 분석하고 주요 정보를 추출하는 방법. 많은 방법을 시도한 후 Greenlion/PHP-SQL-Parser 라이브러리가 내 요구를 완벽하게 해결할 수 있음을 발견했습니다.
 웹 사이트 성능을 최적화하는 방법 : 미니 라이브러리 사용에서 배운 경험 및 교훈
Apr 17, 2025 pm 11:18 PM
웹 사이트 성능을 최적화하는 방법 : 미니 라이브러리 사용에서 배운 경험 및 교훈
Apr 17, 2025 pm 11:18 PM
웹 사이트를 개발하는 과정에서 페이지 로딩을 개선하는 것은 항상 최우선 과제 중 하나였습니다. 일단 웹 사이트의 성능을 향상시키기 위해 CSS 및 JavaScript 파일을 압축하고 병합하기 위해 Miniify 라이브러리를 사용해 보았습니다. 그러나 사용 중에 많은 문제와 도전에 직면하여 결국 Miniify가 더 이상 최선의 선택이 아닐 수도 있음을 깨달았습니다. 아래에서는 내 경험과 작곡가를 통해 미수를 설치하고 사용하는 방법을 공유 할 것입니다.
