
기계 학습에 관한 한 오디오 자체는 음성 인식, 음악 분류, 소리 이벤트 감지 등을 포함하여 광범위한 응용 분야를 갖춘 완전한 분야입니다. 오디오 분류는 전통적으로 스펙트로그램 분석 및 은닉 마르코프 모델과 같은 방법을 사용했는데, 이는 효과적임이 입증되었지만 한계도 있습니다. 최근 VIT는 오디오 작업에 대한 유망한 대안으로 떠올랐으며 OpenAI의 Whisper가 좋은 예입니다.

GTZAN 데이터세트는 음악 장르 인식(MGR) 연구에서 가장 일반적으로 사용되는 공개 데이터세트입니다. 이 파일은 개인용 CD, 라디오, 마이크 녹음 등 다양한 소스에서 2000~2001년에 수집되었으며 다양한 녹음 조건에서 소리를 나타냅니다.
이 데이터 세트는 하위 폴더로 구성되며 각 하위 폴더는 유형입니다.
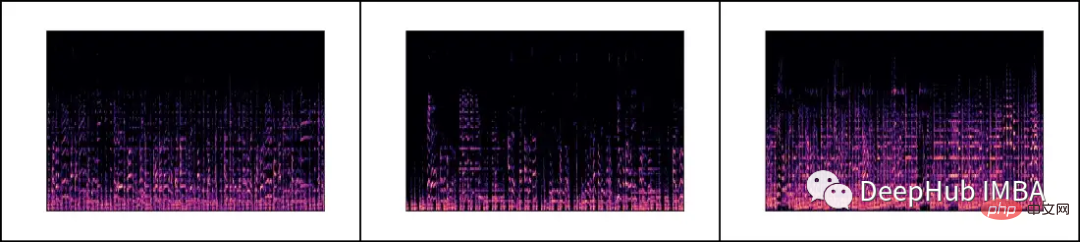
각 .wav 파일을 로드하고 librosa 라이브러리를 통해 해당 Mel 스펙트럼을 생성합니다.
멜 스펙트로그램은 소리 신호의 스펙트럼 내용을 시각적으로 표현한 것으로, 세로 축은 멜 스케일의 주파수를 나타내고 가로 축은 시간을 나타냅니다. 이는 오디오 신호 처리, 특히 음악 정보 검색 분야에서 일반적으로 사용되는 표현입니다.
멜 스케일(영어: mel scale)은 인간의 음높이 인식을 고려한 스케일입니다. 인간은 주파수의 선형 범위를 인식하지 못하기 때문에 이는 고주파수보다 저주파에서의 차이를 더 잘 감지한다는 것을 의미합니다. 예를 들어, 500Hz와 1000Hz의 차이는 쉽게 구분할 수 있지만, 10,000Hz와 10,500Hz 사이의 거리가 동일하더라도 차이를 구분하는 것은 더 어렵습니다. 따라서 멜 스케일은 이 문제를 해결합니다. 멜 스케일의 차이가 동일하다면 인간이 인식하는 음조 차이도 동일하다는 의미입니다.
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return img위 함수는 간단한 멜 스펙트로그램을 생성합니다.

이제 폴더에서 데이터 세트를 로드하고 변환을 이미지에 적용합니다.
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))ViT를 모델로 사용하겠습니다. Vision Transformer는 먼저 논문에서 16x16 단어에 해당하는 이미지를 소개했으며 이 방법이 CNN에 의존하지 않고 직접 적용된다는 것을 성공적으로 입증했습니다. 이미지 패치 시퀀스는 이미지 분류 작업을 잘 수행할 수 있습니다.
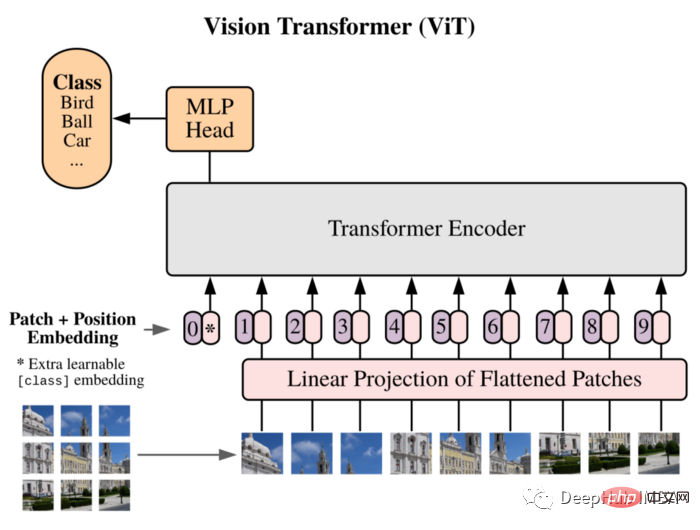
이미지를 패치로 분할하고 이러한 패치의 선형 임베딩 시퀀스를 변환기의 입력으로 사용합니다. 패치는 NLP 애플리케이션의 토큰(단어)과 동일한 방식으로 처리됩니다.
CNN 고유의 귀납적 편향(예: 지역성)이 부족하기 때문에 Transformer는 훈련 데이터의 양이 충분하지 않으면 일반화를 잘 할 수 없습니다. 그러나 대규모 데이터 세트에 대해 교육을 받으면 여러 이미지 인식 벤치마크에서 최첨단 기술을 충족하거나 능가합니다.
구현 구조는 다음과 같습니다:
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
훈련 루프도 전통적인 훈련 프로세스입니다:
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))Vision Transformer 아키텍처의 이 사용자 정의 구현은 PyTorch를 사용하여 처음부터 훈련되었습니다. 데이터 세트가 매우 작기 때문에(클래스당 샘플 100개) 이는 모델 성능에 영향을 미치며 정확도는 0.71에 불과합니다.
이것은 단순한 데모일 뿐입니다. 모델 성능을 향상해야 하는 경우 더 큰 데이터 세트를 사용하거나 아키텍처의 다양한 하이퍼 매개변수를 약간 조정할 수 있습니다.
여기에 사용된 vit 코드는 다음에서 가져옵니다.
https: //medium.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
위 내용은 비디오에서 오디오로: VIT를 사용한 오디오 분류의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



