

11가지 일반적인 분류 특징 인코딩 기술

기계 학습 알고리즘은 숫자 입력만 허용하므로 범주형 특성을 발견하면 범주형 특성을 인코딩합니다. 이 문서에서는 11가지 일반적인 범주형 변수 인코딩 방법을 요약합니다.

1. ONE HOT ENCODING
가장 널리 사용되고 일반적으로 사용되는 인코딩 방법은 One Hot Enoding입니다. n개의 관측값과 d개의 개별 값을 갖는 단일 변수는 n개의 관측값을 갖는 d개의 이진 변수로 변환되며, 각 이진 변수는 비트(0, 1)로 식별됩니다.
예:
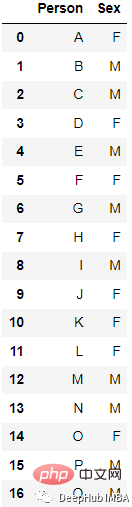
인코딩 후

가장 간단한 구현은 pandas의 get_dummies
new_df=pd.get_dummies(columns=[‘Sex’], data=df)
2, 라벨 인코딩을 사용하는 것입니다.
고유하게 식별되는 정수를 범주형 데이터 변수에 할당합니다. 이 방법은 매우 간단하지만 순서가 지정되지 않은 데이터를 나타내는 범주형 변수에 문제를 일으킬 수 있습니다. 예를 들어, 값이 높은 태그는 값이 낮은 태그보다 우선순위가 더 높을 수 있습니다.
예를 들어 위 데이터에서 인코딩 후 다음과 같은 결과를 얻었습니다.

sklearn의 LabelEncoder는 직접 변환할 수 있습니다.
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
3. Label Binarizer
LabelBinarizer는 다음에서 레이블 매트릭스를 생성하는 데 사용되는 도구입니다. 다중 카테고리 목록 목록을 입력 세트의 고유 값과 정확히 동일한 수의 열을 갖는 행렬로 변환하는 유틸리티 클래스입니다.
예를 들어, 이 데이터는
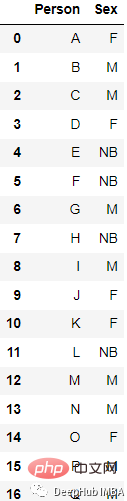
변환된 결과는

from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
4입니다. 인코딩을 하나만 남겨두면 대상 범주형 특성 변수에 대해 동일한 값을 갖는 모든 레코드가 됩니다. 평균을 구하여 목표 변수의 평균을 결정합니다. 인코딩 알고리즘은 훈련 데이터세트와 테스트 데이터세트 간에 약간 다릅니다. 분류 대상으로 고려되는 특징 레코드는 훈련 데이터 세트에서 제외되기 때문에 "Leave One Out"이라고 합니다.
특정 범주형 변수의 구체적인 값을 코딩하는 방법은 다음과 같습니다.
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
예를 들어 다음 데이터는 다음과 같습니다.
 인코딩 후:
인코딩 후:
 이 인코딩 프로세스를 보여주기 위해 데이터 세트
이 인코딩 프로세스를 보여주기 위해 데이터 세트
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
를 만든 다음 이를 인코딩합니다.
import category_encoders as ce
tenc=ce.TargetEncoder()
df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’])
df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1)
df_new = df.join(df_dep)이 방법으로 우리는 다음을 얻습니다. 위의 결과.
5. 해싱
해시 함수를 사용하면 문자열이 고유한 해시 값으로 변환됩니다. 메모리를 거의 사용하지 않고 더 많은 범주형 데이터를 처리할 수 있기 때문입니다. 기능 해싱은 기계 학습에서 희박한 고차원 기능을 관리하는 효과적인 방법입니다. 온라인 학습 시나리오에 적합하며 빠르고 간단하며 효율적이고 빠른 특성을 가지고 있습니다.
예를 들어 다음 데이터는
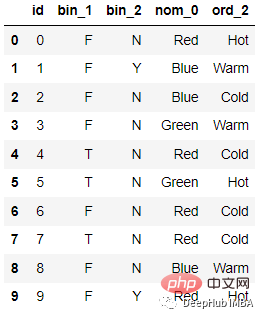 인코딩 후
인코딩 후
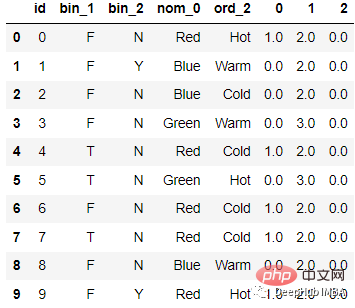 코드는 다음과 같습니다.
코드는 다음과 같습니다.
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
6. Weight of Evidence Encoding
(WoE) 개발의 주요 목표는 금융 산업의 신용 및 대출 불이행 위험을 평가하기 위한 예측 모델. 증거가 이론을 지지하거나 반박하는 정도는 증거의 가중치(WOE)에 따라 달라집니다.
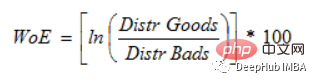 P(Goods) / P(Bads) = 1이면 WoE는 0입니다. 이 그룹의 결과가 무작위인 경우 P(나쁨) > P(좋음)이면 승산비는 1이고 증거의 가중치(WoE)는 0입니다. 그룹에서 P(Goods) > P(bad)인 경우 WoE는 0보다 큽니다.
P(Goods) / P(Bads) = 1이면 WoE는 0입니다. 이 그룹의 결과가 무작위인 경우 P(나쁨) > P(좋음)이면 승산비는 1이고 증거의 가중치(WoE)는 0입니다. 그룹에서 P(Goods) > P(bad)인 경우 WoE는 0보다 큽니다.
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据

会被编码为:

代码如下:
from category_encoders import WOEEncoder
df = pd.DataFrame({‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]})
woe = WOEEncoder(cols=[‘cat’], random_state=42)
X = df[‘cat’]
y = df.target
encoded_df = woe.fit_transform(X, y)7、Helmert Encoding
Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。

会被编码为

代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
8、Cat Boost Encoding
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。

TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。

编码后的结果如下:

代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
9、James Stein Encoding
James-Stein 为特征值提供以下加权平均值:
- 观察到的特征值的平均目标值。
- 平均期望值(与特征值无关)。
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
10、M Estimator Encoding:
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
11、 Sum Encoder
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
위 내용은 11가지 일반적인 분류 특징 인코딩 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7484
7484
 15
1377
52
77
11
51
19
19
37
15
1377
52
77
11
51
19
19
37

 이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
기계 학습 및 데이터 과학 분야에서 모델 해석 가능성은 항상 연구자와 실무자의 초점이었습니다. 딥러닝, 앙상블 방법 등 복잡한 모델이 널리 적용되면서 모델의 의사결정 과정을 이해하는 것이 특히 중요해졌습니다. explainable AI|XAI는 모델의 투명성을 높여 머신러닝 모델에 대한 신뢰와 확신을 구축하는 데 도움이 됩니다. 모델 투명성을 향상시키는 것은 여러 복잡한 모델의 광범위한 사용은 물론 모델을 설명하는 데 사용되는 의사 결정 프로세스와 같은 방법을 통해 달성할 수 있습니다. 이러한 방법에는 기능 중요도 분석, 모델 예측 간격 추정, 로컬 해석 가능성 알고리즘 등이 포함됩니다. 특성 중요도 분석은 모델이 입력 특성에 미치는 영향 정도를 평가하여 모델의 의사결정 과정을 설명할 수 있습니다. 모델 예측 구간 추정
 C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++의 기계 학습 알고리즘이 직면하는 일반적인 과제에는 메모리 관리, 멀티스레딩, 성능 최적화 및 유지 관리 가능성이 포함됩니다. 솔루션에는 스마트 포인터, 최신 스레딩 라이브러리, SIMD 지침 및 타사 라이브러리 사용은 물론 코딩 스타일 지침 준수 및 자동화 도구 사용이 포함됩니다. 실제 사례에서는 Eigen 라이브러리를 사용하여 선형 회귀 알고리즘을 구현하고 메모리를 효과적으로 관리하며 고성능 행렬 연산을 사용하는 방법을 보여줍니다.
 설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
번역기 | 검토자: Li Rui | Chonglou 인공 지능(AI) 및 기계 학습(ML) 모델은 오늘날 점점 더 복잡해지고 있으며 이러한 모델에서 생성되는 출력은 이해관계자에게 설명할 수 없는 블랙박스입니다. XAI(Explainable AI)는 이해관계자가 이러한 모델의 작동 방식을 이해할 수 있도록 하고, 이러한 모델이 실제로 의사 결정을 내리는 방식을 이해하도록 하며, AI 시스템의 투명성, 이 문제를 해결하기 위한 신뢰 및 책임을 보장함으로써 이 문제를 해결하는 것을 목표로 합니다. 이 기사에서는 기본 원리를 설명하기 위해 다양한 설명 가능한 인공 지능(XAI) 기술을 살펴봅니다. 설명 가능한 AI가 중요한 몇 가지 이유 신뢰와 투명성: AI 시스템이 널리 수용되고 신뢰되려면 사용자가 의사 결정 방법을 이해해야 합니다.
 탐지 알고리즘 개선: 고해상도 광학 원격탐사 이미지에서 표적 탐지용
Jun 06, 2024 pm 12:33 PM
탐지 알고리즘 개선: 고해상도 광학 원격탐사 이미지에서 표적 탐지용
Jun 06, 2024 pm 12:33 PM
01 전망 요약 현재로서는 탐지 효율성과 탐지 결과 간의 적절한 균형을 이루기가 어렵습니다. 우리는 광학 원격 탐사 이미지에서 표적 감지 네트워크의 효과를 향상시키기 위해 다층 특징 피라미드, 다중 감지 헤드 전략 및 하이브리드 주의 모듈을 사용하여 고해상도 광학 원격 감지 이미지에서 표적 감지를 위한 향상된 YOLOv5 알고리즘을 개발했습니다. SIMD 데이터 세트에 따르면 새로운 알고리즘의 mAP는 YOLOv5보다 2.2%, YOLOX보다 8.48% 우수하여 탐지 결과와 속도 간의 균형이 더 잘 이루어졌습니다. 02 배경 및 동기 원격탐사 기술의 급속한 발전으로 항공기, 자동차, 건물 등 지구 표면의 많은 물체를 묘사하기 위해 고해상도 광학 원격탐사 영상이 활용되고 있다. 원격탐사 이미지 해석에서 물체 감지
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 Flash Attention은 안정적인가요? Meta와 Harvard는 모델 중량 편차가 수십 배로 변동한다는 사실을 발견했습니다.
May 30, 2024 pm 01:24 PM
Flash Attention은 안정적인가요? Meta와 Harvard는 모델 중량 편차가 수십 배로 변동한다는 사실을 발견했습니다.
May 30, 2024 pm 01:24 PM
MetaFAIR는 대규모 기계 학습을 수행할 때 생성되는 데이터 편향을 최적화하기 위한 새로운 연구 프레임워크를 제공하기 위해 Harvard와 협력했습니다. 대규모 언어 모델을 훈련하는 데는 수개월이 걸리고 수백 또는 수천 개의 GPU를 사용하는 것으로 알려져 있습니다. LLaMA270B 모델을 예로 들면, 훈련에는 총 1,720,320 GPU 시간이 필요합니다. 대규모 모델을 교육하면 이러한 워크로드의 규모와 복잡성으로 인해 고유한 체계적 문제가 발생합니다. 최근 많은 기관에서 SOTA 생성 AI 모델을 훈련할 때 훈련 프로세스의 불안정성을 보고했습니다. 이는 일반적으로 손실 급증의 형태로 나타납니다. 예를 들어 Google의 PaLM 모델은 훈련 과정에서 최대 20번의 손실 급증을 경험했습니다. 수치 편향은 이러한 훈련 부정확성의 근본 원인입니다.
 C++의 기계 학습: C++의 일반적인 기계 학습 알고리즘 구현 가이드
Jun 03, 2024 pm 07:33 PM
C++의 기계 학습: C++의 일반적인 기계 학습 알고리즘 구현 가이드
Jun 03, 2024 pm 07:33 PM
C++에서 기계 학습 알고리즘의 구현에는 다음이 포함됩니다. 선형 회귀: 연속 변수를 예측하는 데 사용됩니다. 단계에는 데이터 로드, 가중치 및 편향 계산, 매개변수 업데이트 및 예측이 포함됩니다. 로지스틱 회귀: 이산형 변수를 예측하는 데 사용됩니다. 이 프로세스는 선형 회귀와 유사하지만 예측에 시그모이드 함수를 사용합니다. 지원 벡터 머신(Support Vector Machine): 지원 벡터 계산 및 레이블 예측을 포함하는 강력한 분류 및 회귀 알고리즘입니다.
 머신러닝 분야 Golang 기술의 향후 동향 전망
May 08, 2024 am 10:15 AM
머신러닝 분야 Golang 기술의 향후 동향 전망
May 08, 2024 am 10:15 AM
기계 학습 분야에서 Go 언어의 적용 가능성은 엄청납니다. 동시성: 병렬 프로그래밍을 지원하며 기계 학습 작업에서 계산 집약적인 작업에 적합합니다. 효율성: 가비지 수집기 및 언어 기능은 대규모 데이터 세트를 처리할 때에도 코드의 효율성을 보장합니다. 사용 용이성: 구문이 간결하므로 기계 학습 애플리케이션을 쉽게 배우고 작성할 수 있습니다.
