

Docker를 사용하여 AWS Lambda에 기계 학습 모델을 배포하는 방법

이 튜토리얼에서는 ML 모델을 Docker 컨테이너로 패키징하고 서버리스 컴퓨팅 서비스인 AWS Lambda에 배포하는 과정을 안내합니다.
이 튜토리얼이 끝나면 API를 통해 호출할 수 있는 작동하는 ML 모델을 갖게 되며 클라우드에 ML 모델을 배포하는 방법을 더 깊이 이해하게 됩니다. 기계 학습 엔지니어, 데이터 과학자, 개발자 등 이 튜토리얼은 ML 및 Docker에 대한 기본적인 이해가 있는 모든 사람이 액세스할 수 있도록 설계되었습니다. 자, 시작해 봅시다!
도커란 무엇인가요?
Docker는 컨테이너를 사용하여 애플리케이션을 더 쉽게 생성, 배포 및 실행할 수 있도록 설계된 도구입니다. 컨테이너를 사용하면 개발자는 라이브러리 및 기타 종속성 등 필요한 모든 부분과 함께 애플리케이션을 패키징하여 하나의 패키지로 보낼 수 있습니다. 컨테이너를 사용하면 개발자는 코드를 작성하고 테스트하는 데 사용된 컴퓨터와 다를 수 있는 컴퓨터의 사용자 지정 설정에 관계없이 애플리케이션이 다른 컴퓨터에서 실행되도록 할 수 있습니다. Docker는 애플리케이션과 해당 종속성을 한 환경에서 다른 환경으로 쉽게 이동할 수 있는 경량의 휴대용 컨테이너로 패키징하는 방법을 제공합니다. 이를 통해 일관된 개발, 테스트 및 프로덕션 환경을 쉽게 만들고 애플리케이션을 더 빠르고 안정적으로 배포할 수 있습니다. 여기에서 Docker를 설치하세요: https://docs.docker.com/get-docker/.
AWS Lambda란 무엇입니까?
Amazon 웹 서비스(AWS) Lambda는 이벤트에 대한 응답으로 코드를 실행하고 기본 컴퓨팅 리소스를 자동으로 관리하는 서버리스 컴퓨팅 플랫폼입니다. 개발자가 코드 실행에 필요한 인프라에 대해 걱정할 필요 없이 클라우드에서 코드를 실행할 수 있도록 AWS에서 제공하는 서비스입니다. AWS Lambda는 수신 요청 트래픽에 응답하여 애플리케이션을 자동으로 확장하며, 사용한 컴퓨팅 시간에 대해서만 비용을 지불합니다. 따라서 마이크로서비스, 실시간 데이터 처리, 이벤트 기반 애플리케이션을 구축하고 실행하는 데 매력적인 선택이 됩니다.
AWS ECR이란 무엇입니까?
Amazon 웹 서비스(AWS) Elastic Container Registry(ECR)는 개발자가 Docker 컨테이너 이미지를 쉽게 저장, 관리 및 배포할 수 있게 해주는 완전 관리형 Docker 컨테이너 레지스트리입니다. 이는 개발자가 AWS 클라우드에서 Docker 이미지를 저장 및 관리하고 Amazon Elastic Container Service(ECS) 또는 기타 클라우드 기반 컨테이너 오케스트레이션 플랫폼에 쉽게 배포할 수 있도록 지원하는 안전하고 확장 가능한 서비스입니다. ECR은 Amazon ECS 및 Amazon EKS와 같은 다른 AWS 서비스와 통합되며 Docker 명령줄 인터페이스(CLI)에 대한 기본 지원을 제공합니다. 이를 통해 익숙한 Docker 명령을 사용하여 ECR에서 Docker 이미지를 쉽게 푸시 및 풀하고 컨테이너화된 애플리케이션 구축, 테스트 및 배포 프로세스를 자동화할 수 있습니다.
AWS CLI 설치
이를 사용하여 시스템에 AWS CLI를 설치합니다. AWS 계정에서 IAM 사용자를 생성하여 AWS 액세스 키 ID와 AWS 보안 액세스 키를 얻으세요. 설치 후 다음 명령을 실행하여 AWS CLI를 구성하고 필수 필드를 삽입합니다.
aws configure
Docker를 사용하여 Lambda 함수 배포
이 튜토리얼에서는 OpenAI 클립 모델을 배포하여 입력 텍스트를 벡터화합니다. Lambda 함수를 사용하려면 Docker 컨테이너에 Amazon Linux 2가 필요하므로
public.ecr.aws/lambda/python:3.8을 사용합니다. 게다가 Lambda에는 읽기 전용 파일 시스템이 있기 때문에 내부적으로 모델을 다운로드할 수 없으므로 이미지 생성 시 모델을 다운로드하여 복사해야 합니다.
여기에서 작업 코드를 가져와서 추출하세요.
Dockerfile이 있는 작업 디렉터리를 변경하고 다음 명령을 실행합니다.
docker build -t lambda_image .
이제 Lambda에 배포할 이미지가 준비되었습니다. 로컬에서 확인하려면 다음 명령을 실행하세요.
docker run -p 9000:8080 lambda_image
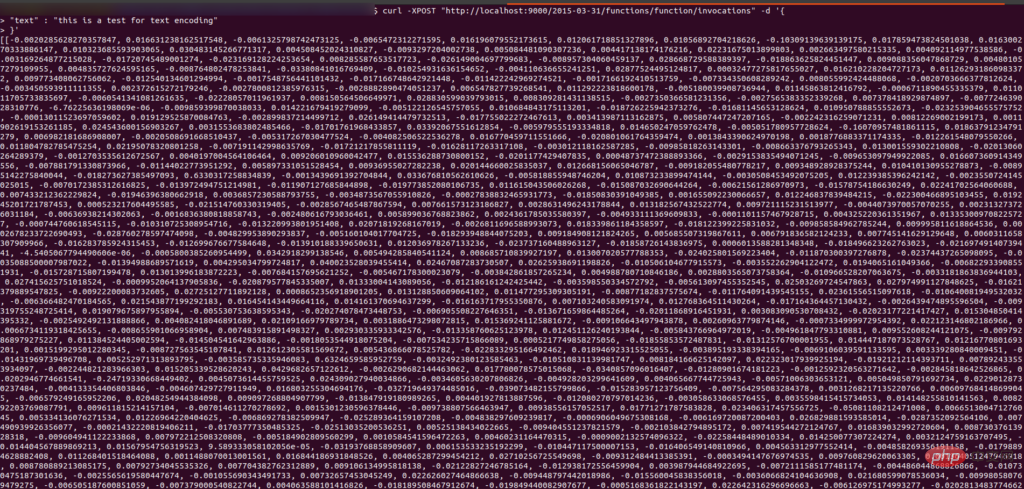
확인하려면 컬 요청을 보내면 입력 텍스트 벡터가 반환되어야 합니다.
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"text": "This is a test for text encoding"}'output
먼저 이미지를 Lambda에 배포하려면 다음이 필요합니다. ECR로 푸시하려면 AWS 계정에 로그인하고 ECR에 웨어하우스lambda_image를 생성하세요. 저장소를 생성한 후 생성된 저장소로 이동하면 view push 명령 옵션이 표시되고 이를 클릭하면 이미지를 저장소에 푸시하는 명령이 표시됩니다.
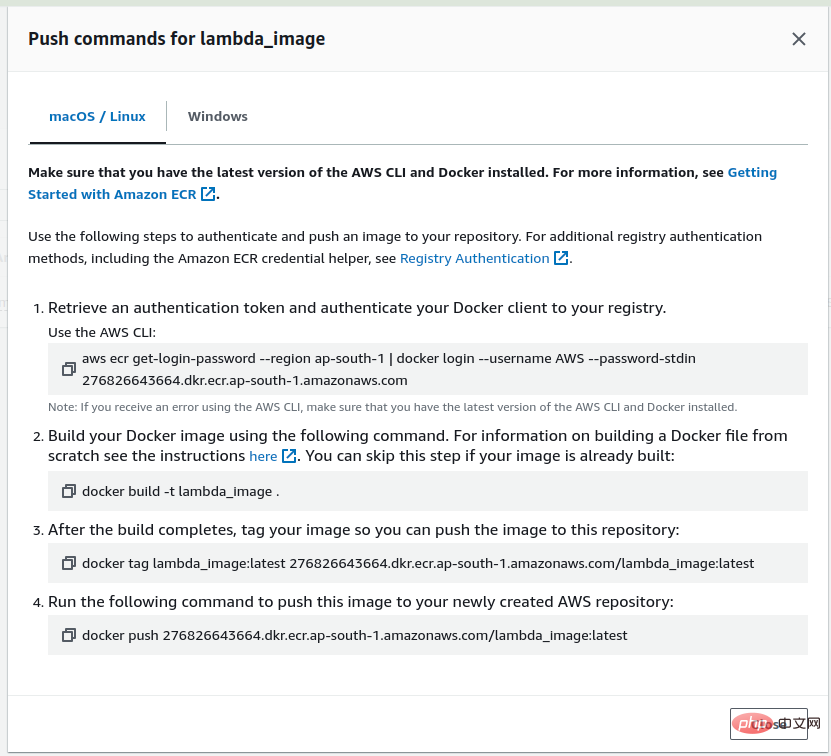
이제 첫 번째 명령을 실행하여 AWS CLI를 사용하여 Docker 클라이언트를 인증하세요.
우리는 이미 Docker 이미지를 생성했으므로 두 번째 단계를 건너뛰고 세 번째 명령을 실행하여 생성된 이미지에 태그를 지정합니다.
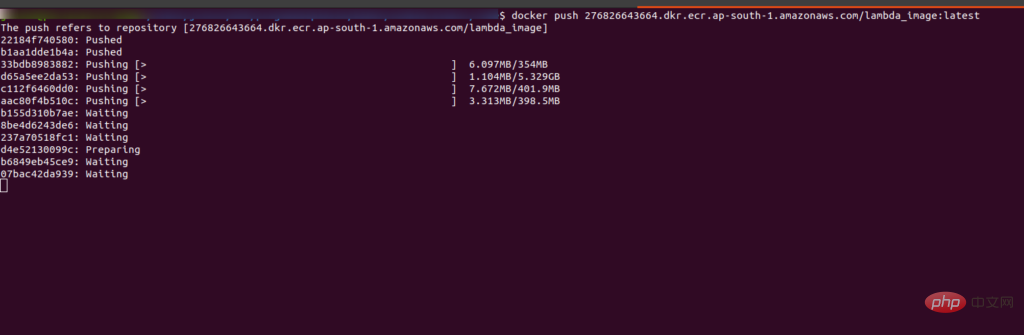
运行最后一条命令将镜像推送到 ECR 中。运行后你会看到界面是这样的:
推送完成后,您将在 ECR 的存储库中看到带有“:latest”标签的图像。
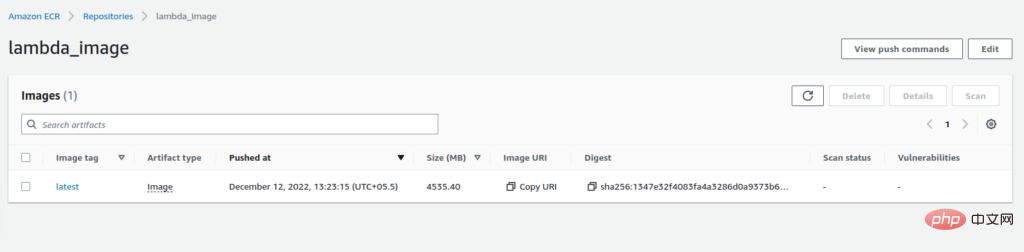
复制图像的 URI。我们在创建 Lambda 函数时需要它。
现在转到 Lambda 函数并单击“创建函数”选项。我们正在从图像创建一个函数,因此选择容器图像的选项。添加函数名称并粘贴我们从 ECR 复制的 URI,或者您也可以浏览图像。选择architecture x84_64,最后点击create_image选项。
构建 Lambda 函数可能需要一些时间,请耐心等待。执行成功后,你会看到如下界面:

Lambda 函数默认有 3 秒的超时限制和 128 MB 的 RAM,所以我们需要增加它,否则它会抛出错误。为此,请转到配置选项卡并单击“编辑”。
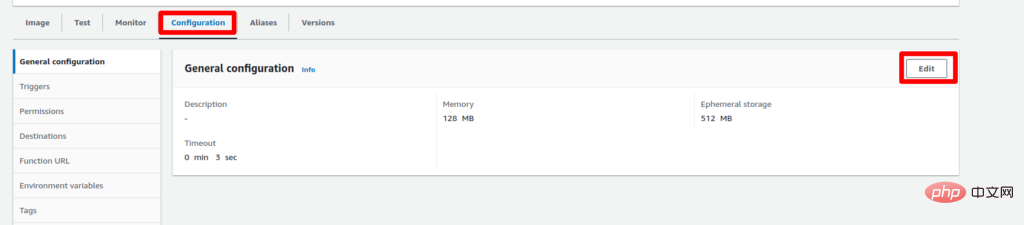
现在将超时设置为 5-10 分钟(最大限制为 15 分钟)并将 RAM 设置为 2-3 GB,然后单击保存按钮。更新 Lambda 函数的配置需要一些时间。
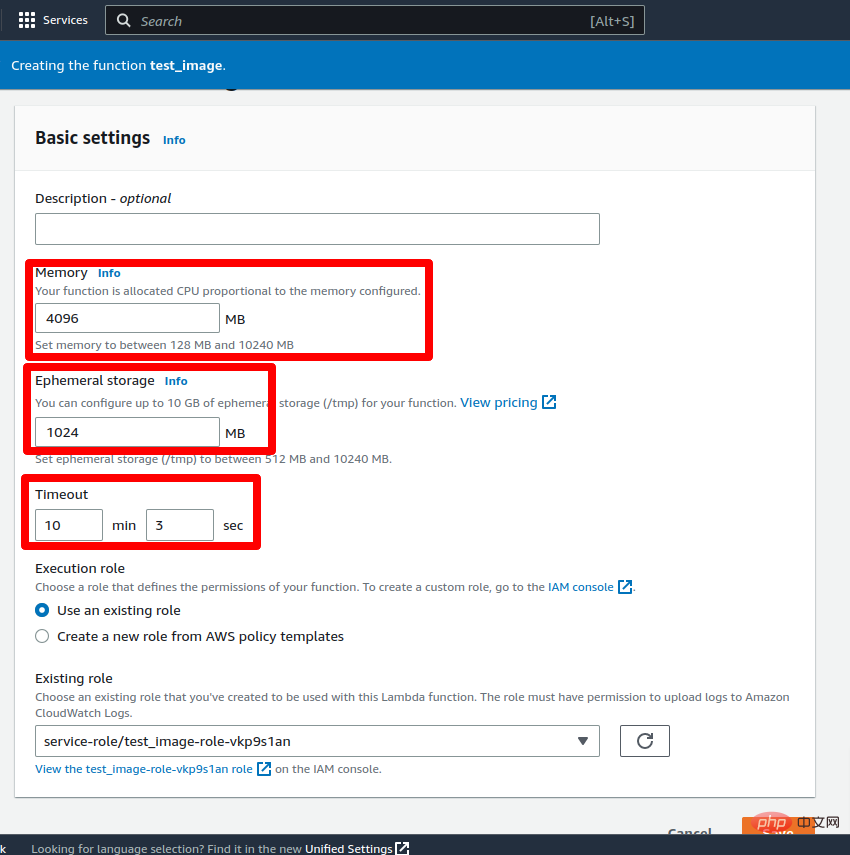
更新更改后,该功能就可以进行测试了。要测试 lambda 函数,请转到“测试”选项卡并将键值添加到事件 JSON 中作为文本:“这是文本编码测试。” 然后点击测试按钮。
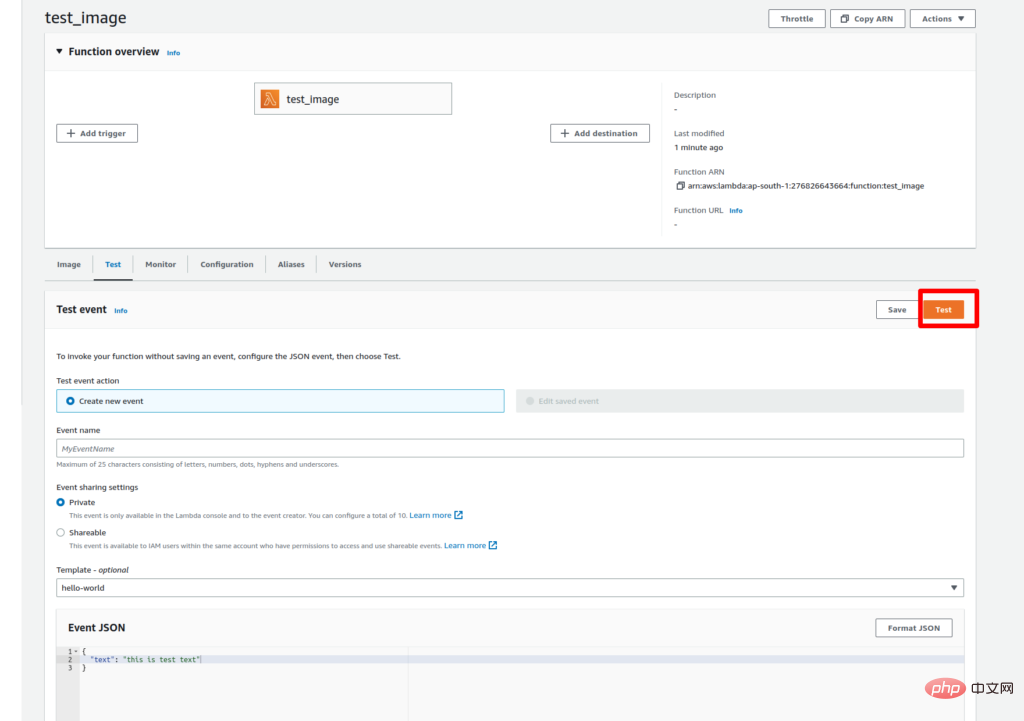
由于我们是第一次执行 Lambda 函数,因此执行可能需要一些时间。成功执行后,您将在执行日志中看到输入文本的向量。
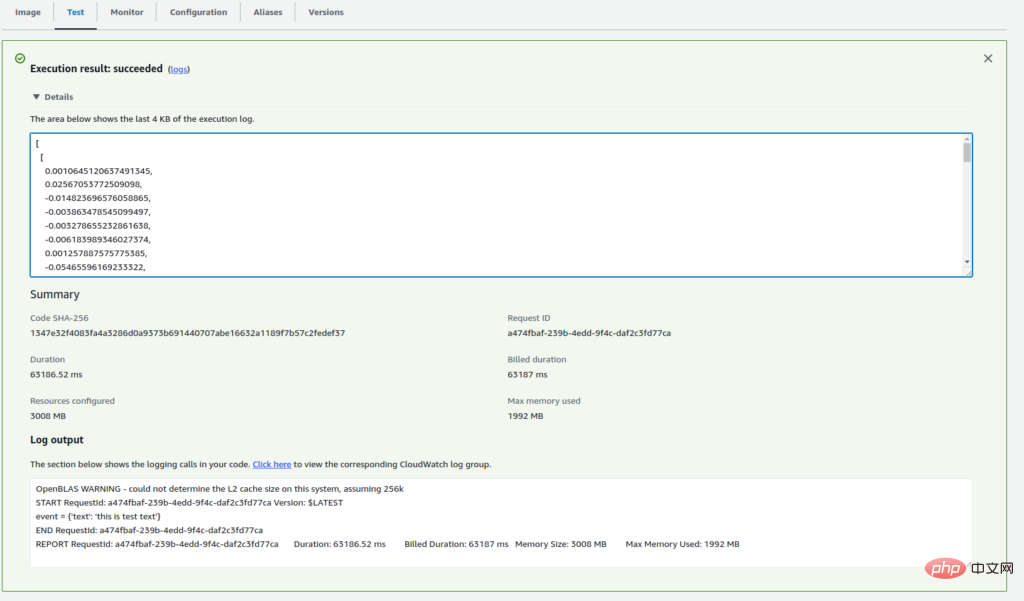
现在我们的 Lambda 函数已部署并正常工作。要通过 API 访问它,我们需要创建一个函数 URL。
要为 Lambda 函数创建 URL,请转到 Configuration 选项卡并选择 Function URL 选项。然后单击创建函数 URL 选项。

现在,保留身份验证 None 并单击 Save。
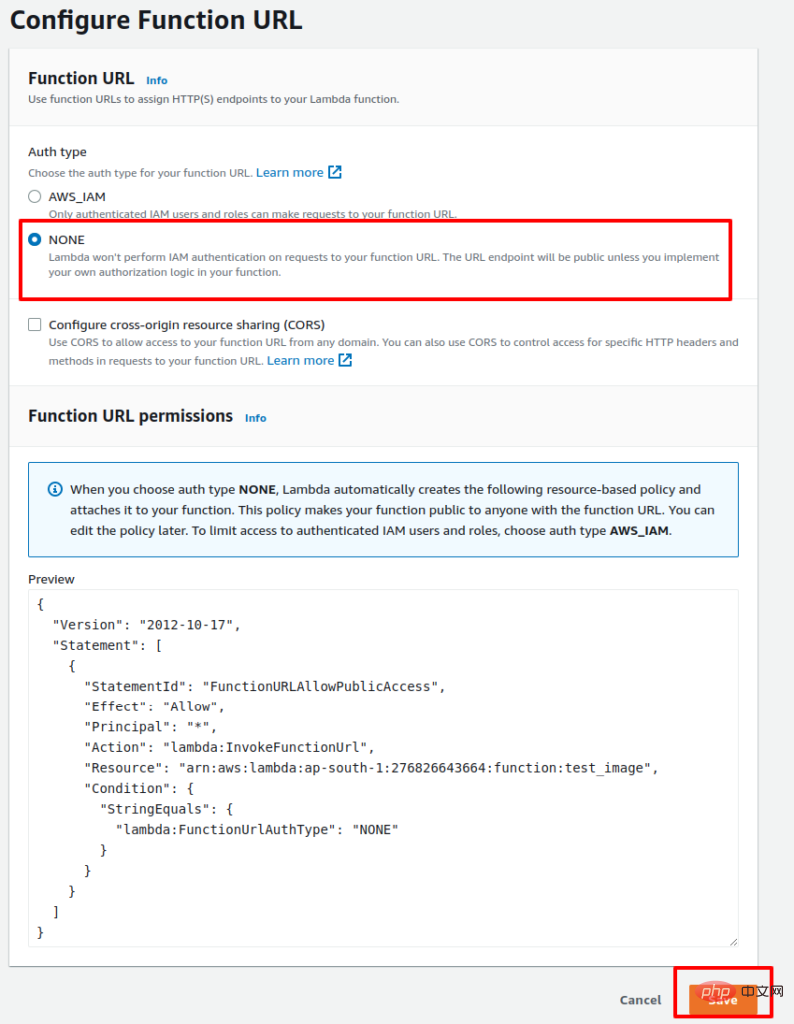
该过程完成后,您将获得用于通过 API 访问 Lambda 函数的 URL。以下是使用 API 访问 Lambda 函数的示例 Python 代码:
import requests function_url = ""url = f"{function_url}?text=this is test text" payload={}headers = {} response = requests.request("GET", url, headers=headers, data=payload) print(response.text)成功执行代码后,您将获得输入文本的向量。

所以这是一个如何使用 Docker 在 AWS Lambda 上部署 ML 模型的示例。如果您有任何疑问,请告诉我们。
위 내용은 Docker를 사용하여 AWS Lambda에 기계 학습 모델을 배포하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7476
7476
 15
1377
52
77
11
49
19
19
31
15
1377
52
77
11
49
19
19
31

 이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
기계 학습 및 데이터 과학 분야에서 모델 해석 가능성은 항상 연구자와 실무자의 초점이었습니다. 딥러닝, 앙상블 방법 등 복잡한 모델이 널리 적용되면서 모델의 의사결정 과정을 이해하는 것이 특히 중요해졌습니다. explainable AI|XAI는 모델의 투명성을 높여 머신러닝 모델에 대한 신뢰와 확신을 구축하는 데 도움이 됩니다. 모델 투명성을 향상시키는 것은 여러 복잡한 모델의 광범위한 사용은 물론 모델을 설명하는 데 사용되는 의사 결정 프로세스와 같은 방법을 통해 달성할 수 있습니다. 이러한 방법에는 기능 중요도 분석, 모델 예측 간격 추정, 로컬 해석 가능성 알고리즘 등이 포함됩니다. 특성 중요도 분석은 모델이 입력 특성에 미치는 영향 정도를 평가하여 모델의 의사결정 과정을 설명할 수 있습니다. 모델 예측 구간 추정
 C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++의 기계 학습 알고리즘이 직면하는 일반적인 과제에는 메모리 관리, 멀티스레딩, 성능 최적화 및 유지 관리 가능성이 포함됩니다. 솔루션에는 스마트 포인터, 최신 스레딩 라이브러리, SIMD 지침 및 타사 라이브러리 사용은 물론 코딩 스타일 지침 준수 및 자동화 도구 사용이 포함됩니다. 실제 사례에서는 Eigen 라이브러리를 사용하여 선형 회귀 알고리즘을 구현하고 메모리를 효과적으로 관리하며 고성능 행렬 연산을 사용하는 방법을 보여줍니다.
 설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
번역기 | 검토자: Li Rui | Chonglou 인공 지능(AI) 및 기계 학습(ML) 모델은 오늘날 점점 더 복잡해지고 있으며 이러한 모델에서 생성되는 출력은 이해관계자에게 설명할 수 없는 블랙박스입니다. XAI(Explainable AI)는 이해관계자가 이러한 모델의 작동 방식을 이해할 수 있도록 하고, 이러한 모델이 실제로 의사 결정을 내리는 방식을 이해하도록 하며, AI 시스템의 투명성, 이 문제를 해결하기 위한 신뢰 및 책임을 보장함으로써 이 문제를 해결하는 것을 목표로 합니다. 이 기사에서는 기본 원리를 설명하기 위해 다양한 설명 가능한 인공 지능(XAI) 기술을 살펴봅니다. 설명 가능한 AI가 중요한 몇 가지 이유 신뢰와 투명성: AI 시스템이 널리 수용되고 신뢰되려면 사용자가 의사 결정 방법을 이해해야 합니다.
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
Pinetwork 노드에 대한 자세한 설명 및 설치 안내서이 기사에서는 Pinetwork Ecosystem을 자세히 소개합니다. Pi 노드, Pinetwork 생태계의 주요 역할을 수행하고 설치 및 구성을위한 전체 단계를 제공합니다. Pinetwork 블록 체인 테스트 네트워크가 출시 된 후, PI 노드는 다가오는 주요 네트워크 릴리스를 준비하여 테스트에 적극적으로 참여하는 많은 개척자들의 중요한 부분이되었습니다. 아직 Pinetwork를 모른다면 Picoin이 무엇인지 참조하십시오. 리스팅 가격은 얼마입니까? PI 사용, 광업 및 보안 분석. Pinetwork 란 무엇입니까? Pinetwork 프로젝트는 2019 년에 시작되었으며 독점적 인 Cryptocurrency Pi Coin을 소유하고 있습니다. 이 프로젝트는 모든 사람이 참여할 수있는 사람을 만드는 것을 목표로합니다.
 Flash Attention은 안정적인가요? Meta와 Harvard는 모델 중량 편차가 수십 배로 변동한다는 사실을 발견했습니다.
May 30, 2024 pm 01:24 PM
Flash Attention은 안정적인가요? Meta와 Harvard는 모델 중량 편차가 수십 배로 변동한다는 사실을 발견했습니다.
May 30, 2024 pm 01:24 PM
MetaFAIR는 대규모 기계 학습을 수행할 때 생성되는 데이터 편향을 최적화하기 위한 새로운 연구 프레임워크를 제공하기 위해 Harvard와 협력했습니다. 대규모 언어 모델을 훈련하는 데는 수개월이 걸리고 수백 또는 수천 개의 GPU를 사용하는 것으로 알려져 있습니다. LLaMA270B 모델을 예로 들면, 훈련에는 총 1,720,320 GPU 시간이 필요합니다. 대규모 모델을 교육하면 이러한 워크로드의 규모와 복잡성으로 인해 고유한 체계적 문제가 발생합니다. 최근 많은 기관에서 SOTA 생성 AI 모델을 훈련할 때 훈련 프로세스의 불안정성을 보고했습니다. 이는 일반적으로 손실 급증의 형태로 나타납니다. 예를 들어 Google의 PaLM 모델은 훈련 과정에서 최대 20번의 손실 급증을 경험했습니다. 수치 편향은 이러한 훈련 부정확성의 근본 원인입니다.
 C++의 기계 학습: C++의 일반적인 기계 학습 알고리즘 구현 가이드
Jun 03, 2024 pm 07:33 PM
C++의 기계 학습: C++의 일반적인 기계 학습 알고리즘 구현 가이드
Jun 03, 2024 pm 07:33 PM
C++에서 기계 학습 알고리즘의 구현에는 다음이 포함됩니다. 선형 회귀: 연속 변수를 예측하는 데 사용됩니다. 단계에는 데이터 로드, 가중치 및 편향 계산, 매개변수 업데이트 및 예측이 포함됩니다. 로지스틱 회귀: 이산형 변수를 예측하는 데 사용됩니다. 이 프로세스는 선형 회귀와 유사하지만 예측에 시그모이드 함수를 사용합니다. 지원 벡터 머신(Support Vector Machine): 지원 벡터 계산 및 레이블 예측을 포함하는 강력한 분류 및 회귀 알고리즘입니다.
 DeepSeek을 설치하는 방법
Feb 19, 2025 pm 05:48 PM
DeepSeek을 설치하는 방법
Feb 19, 2025 pm 05:48 PM
Docker 컨테이너를 사용하여 사전 컴파일 된 패키지 (Windows 사용자의 경우)를 사용하여 소스 (숙련 된 개발자)를 컴파일하는 것을 포함하여 DeepSeek를 설치하는 방법에는 여러 가지가 있습니다. 공식 문서는 신중하게 문서를 작성하고 불필요한 문제를 피하기 위해 완전히 준비합니다.
