
CLIP(Contrastive Language-Image Pre-training)은 이미지와 언어 처리에 지대한 영향을 미치는 이미지와 자연어 텍스트를 정확하게 이해하고 분류할 수 있는 머신러닝 기술로 대중적인 확산 모델로 활용되어 왔습니다. DALL-E의 메커니즘. 이 게시물에서는 CLIP을 적용하여 비디오 검색을 지원하는 방법을 다룹니다.
이 기사에서는 CLIP 모델의 기술적 세부 사항을 다루지는 않지만 확산 모델 외에 CLIP의 또 다른 실제 적용을 보여줍니다.
먼저 알아야 할 점: CLIP은 이미지 디코더와 텍스트 인코더를 사용하여 데이터세트의 어떤 이미지가 어떤 텍스트와 일치하는지 예측합니다.

껴안은 얼굴에서 사전 훈련된 CLIP 모델을 사용하면 기능 엔지니어링 없이도 자연어 기능을 갖춘 간단하고 강력한 동영상 검색 엔진을 구축할 수 있습니다.
다음 소프트웨어를 사용해야 합니다
Python≥= 3.8,ffmpeg,opencv
텍스트로 비디오를 검색하는 데는 여러 가지 기술이 있습니다. 검색 엔진은 인덱싱과 검색이라는 두 부분으로 구성되어 있다고 생각할 수 있습니다.
동영상 인덱싱에는 일반적으로 수동 프로세스와 기계 프로세스가 결합됩니다. 인간은 제목, 태그, 설명에 관련 키워드를 추가하여 비디오를 전처리하는 반면, 자동화된 프로세스는 객체 감지 및 오디오 전사와 같은 시각 및 청각 기능을 추출합니다. 사용자 상호 작용 측정항목 등을 통해 동영상의 어느 부분이 가장 관련성이 높은지, 해당 부분이 얼마나 오랫동안 관련성을 유지하는지 기록합니다. 이 모든 단계는 비디오 콘텐츠의 검색 가능한 색인을 생성하는 데 도움이 됩니다.
인덱싱 프로세스 개요는 다음과 같습니다.
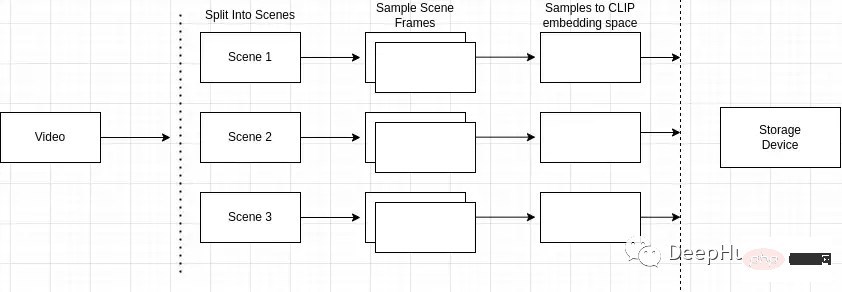
장면 감지가 왜 중요한가요? 동영상은 장면으로 구성되고, 장면은 유사한 프레임으로 구성됩니다. 비디오에서 임의의 장면만 샘플링하면 전체 비디오에서 키프레임을 놓칠 수 있습니다.
그래서 우리는 영상 속 특정 사건이나 행동을 정확하게 식별하고 위치를 찾아야 합니다. 예를 들어, "공원에 있는 개"를 검색하고 검색 중인 비디오에 자전거를 타는 남자의 장면, 공원에 있는 개가 있는 장면 등 여러 장면이 포함되어 있는 경우 장면 감지를 통해 다음을 수행할 수 있습니다. 검색어와 가장 관련성이 높은 항목을 식별합니다.
"장면 감지" Python 패키지를 사용하여 이 작업을 수행할 수 있습니다.
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
그런 다음 cv2를 사용하여 비디오의 프레임을 만들어야 합니다.
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
샘플을 수집한 후 CLIP 모델에서 사용할 수 있는 것으로 계산해야 합니다.
먼저 각 샘플을 이미지 텐서 임베딩으로 변환해야 합니다.
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)다음 단계는 동일한 장면의 모든 샘플을 평균화하는 것입니다. 이를 통해 샘플의 차원을 줄이고 단일 샘플의 노이즈 문제를 해결할 수도 있습니다.
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))이런 방식으로 동영상 콘텐츠를 나타내는 CLIP 내장 텐서 목록을 얻습니다.
기본 인덱스 저장소로는 LevelDB를 사용합니다(LevelDB는 Google에서 관리하는 키/값 라이브러리입니다). 검색 엔진의 아키텍처는 3개의 개별 인덱스로 구성됩니다.
먼저 계산된 동영상의 모든 메타데이터와 동영상의 고유 식별자를 메타데이터 인덱스에 삽입합니다. 이 단계는 모두 이미 만들어져 있으며 매우 간단합니다.
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})그런 다음 장면 임베딩 인덱스에 새 항목을 만들어 비디오의 각 픽셀 임베딩을 유지하고 각 장면을 식별하기 위한 고유 식별자도 필요합니다.
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)마지막으로 어떤 장면이 어떤 영상에 속하는지 저장해야 합니다.
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)이제 동영상 색인이 있으므로 모델 출력을 기준으로 동영상을 검색하고 정렬할 수 있습니다.
첫 번째 단계에서는 장면 인덱스의 모든 레코드를 순회해야 합니다. 그런 다음 모든 비디오 목록과 비디오의 일치하는 장면 ID를 만듭니다.
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)다음 단계는 각 동영상에 존재하는 모든 장면 임베딩 텐서를 수집하는 것입니다.
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]비디오를 구성하는 모든 텐서를 확보한 후 이를 모델에 전달할 수 있습니다. 모델에 대한 입력은 비디오 장면을 나타내는 텐서인 "pixel_values"입니다.
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)그런 다음 모델 출력의 "logits_per_image"에 액세스하여 모델의 출력을 가져옵니다.
로지트는 기본적으로 네트워크에 대한 정규화되지 않은 원시 예측입니다. 비디오의 장면을 나타내는 텍스트 문자열과 텐서만 제공하므로 로짓의 구조는 단일 값 예측이 됩니다.
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
각 반복의 확률을 더하고 작업이 끝나면 총 텐서 수로 나누어 동영상의 평균 확률을 구하세요.
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
위 내용은 CLIP을 사용하여 비디오 검색 엔진 구축의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



