

Python은 멋진 Sankey 다이어그램을 그립니다. 배워 보셨나요?

Sankey 다이어그램 소개
엔티티 간에 데이터가 어떻게 흐르는지 시각화해야 하는 상황이 필요한 경우가 많습니다. 예를 들어, 주민들이 한 국가에서 다른 국가로 이동하는 방법을 생각해 보세요. 다음은 영국에서 북아일랜드, 스코틀랜드, 웨일즈로 얼마나 많은 주민이 이주했는지를 보여줍니다.
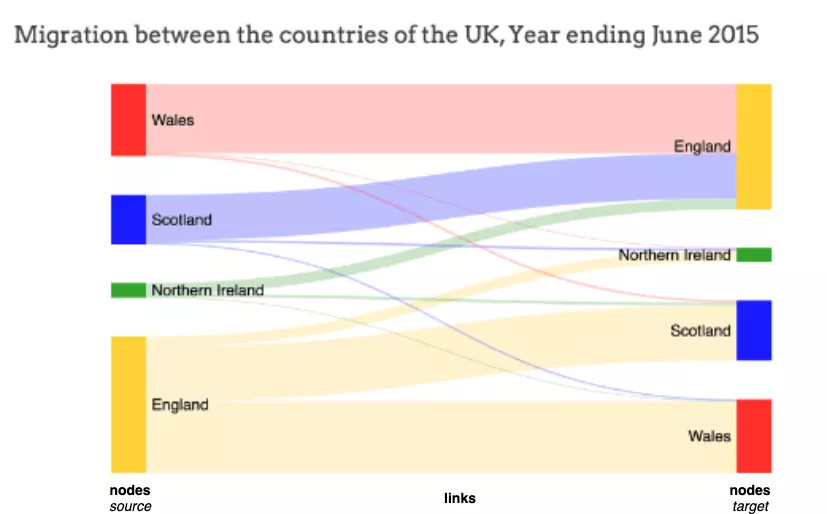
이 Sankey 시각화를 보면 스코틀랜드나 북아일랜드보다 잉글랜드에서 웨일스로 이주한 주민이 더 많다는 것이 분명합니다.
Sankey 다이어그램이란 무엇입니까?
Sankey 다이어그램은 일반적으로 한 엔터티(또는 노드)에서 다른 엔터티(또는 노드)로의 데이터 흐름을 묘사합니다.
데이터가 흐르는 엔터티를 노드라고 합니다. 데이터 흐름이 시작되는 노드는 소스 노드(예: 왼쪽의 England)이고, 흐름이 끝나는 노드는 대상 노드(예: 오른쪽의 Wales)입니다. ). 소스 및 대상 노드는 일반적으로 레이블이 지정된 직사각형으로 표시됩니다.
흐름 자체는 링크라고 불리는 직선 또는 곡선 경로로 표현됩니다. 스트림/링크의 폭은 스트림의 양/수에 정비례합니다. 위의 예에서 잉글랜드에서 웨일즈로의 이동(즉, 거주자의 이주)은 잉글랜드에서 스코틀랜드나 북아일랜드로의 이동(즉, 거주자의 이주)보다 더 광범위하며(즉, 거주자의 이주), 이는 더 많은 거주자가 있음을 나타냅니다. 다른 나라보다 웨일즈로 이주하세요.
Sankey 다이어그램은 흐름 개념을 사용하여 에너지, 돈, 비용 등 모든 것의 흐름을 나타내는 데 사용할 수 있습니다.
미나드의 나폴레옹의 러시아 침공에 관한 고전 차트는 아마도 Sankey 차트의 가장 유명한 예일 것입니다. Sankey 다이어그램을 사용한 이 시각화는 프랑스 군대가 러시아로 이동하는 동안 어떻게 진행(또는 감소?)했는지 매우 효과적으로 보여줍니다.

이 기사에서는 Python의 플롯을 사용하여 Sankey 다이어그램을 그립니다.
Sankey 다이어그램을 그리는 방법?
이 기사에서는 2021년 올림픽 게임 데이터 세트를 사용하여 Sankey 다이어그램을 그립니다. 데이터세트에는 국가, 총 메달 수, 개인의 금, 은, 동메달 합계 등 총 메달 수에 대한 자세한 정보가 포함되어 있습니다. 우리는 한 국가가 얼마나 많은 금, 은, 동메달을 획득했는지 알아보기 위해 Sankey 차트를 그립니다.
df_medals = pd.read_excel("data/Medals.xlsx")
print(df_medals.info())
df_medals.rename(columns={'Team/NOC':'Country', 'Total': 'Total Medals', 'Gold':'Gold Medals', 'Silver': 'Silver Medals', 'Bronze': 'Bronze Medals'}, inplace=True)
df_medals.drop(columns=['Unnamed: 7','Unnamed: 8','Rank by Total'], inplace=True)
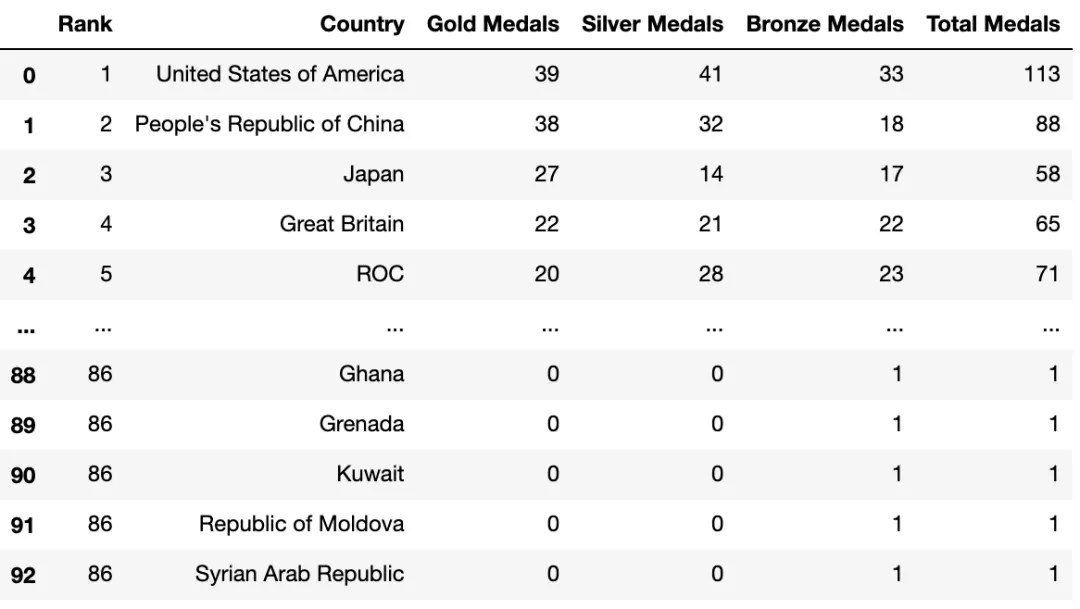
df_medals<class 'pandas.core.frame.DataFrame'> RangeIndex: 93 entries, 0 to 92 Data columns (total 9 columns): # Column Non-Null CountDtype --------- ------------------- 0 Rank 93 non-null int64 1 Team/NOC 93 non-null object 2 Gold 93 non-null int64 3 Silver 93 non-null int64 4 Bronze 93 non-null int64 5 Total93 non-null int64 6 Rank by Total93 non-null int64 7 Unnamed: 7 0 non-nullfloat64 8 Unnamed: 8 1 non-nullfloat64 dtypes: float64(2), int64(6), object(1) memory usage: 6.7+ KB None
Sankey 다이어그램 그리기의 기본
plotly의 go.Sankey를 사용하세요. 이 방법은 노드와 링크(노드와 링크)라는 2개의 매개변수를 사용합니다.
참고: 모든 노드(소스 및 대상)에는 고유 식별자가 있어야 합니다.
이 기사의 올림픽 메달 데이터세트의 경우:
출처는 국가입니다. 처음 3개 국가(미국, 중국, 일본)를 소스 노드로 간주합니다. 다음과 같은 (고유) 식별자, 레이블 및 색상으로 이러한 소스 노드에 레이블을 지정합니다.
- 0: 미국: 녹색
- 1: 중국: 파란색
- 2: 일본: 주황색
대상은 금, 은 또는 동메달. 다음과 같은 (고유) 식별자, 레이블 및 색상으로 이러한 대상 노드에 레이블을 지정합니다.
- 3: 금: 금
- 4: 은: 은
- 5: 청동: 갈색
링크(소스 노드 및 대상 노드) 각 유형의 메달 수입니다. 각 소스에는 3개의 링크가 있으며, 각 링크는 골드, 실버, 브론즈라는 목표로 끝납니다. 그래서 총 9개의 링크가 있습니다. 각 링크의 폭은 금, 은, 동메달의 개수로 한다. 다음 소스를 사용하여 이러한 링크에 대상, 값 및 색상 레이블을 지정합니다.
- 0(미국) ~ 3,4,5 : 39, 41, 33
- 1(중국) ~ 3,4,5 : 38, 32, 18
- 2(일본) ~ 3,4,5 : 27, 14, 17
- 노드(소스 및 대상)를 나타내려면 2개의 Python dict 객체 인스턴스화가 필요합니다. 라벨과 색상을 별도의 목록으로,
- 링크: 링크의 소스 노드, 대상 노드, 값(너비) 및 색상을 별도의 목록으로
플롯리의 go.Sankey에 전달합니다.
목록의 각 인덱스(레이블, 소스, 대상, 값 및 색상)는 노드 또는 링크에 해당합니다.
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) LINKS = dict( source = [0,0,0,1,1,1,2,2,2], # 链接的起点或源节点 target = [3,4,5,3,4,5,3,4,5], # 链接的目的地或目标节点 value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17], # 链接的宽度(数量) # 链接的颜色 # 目标节点: 3-Gold4-Silver5-Bronze color = [ "lightgreen", "lightgreen", "lightgreen",# 源节点:0 - 美国 States of America "lightskyblue", "lightskyblue", "lightskyblue",# 源节点:1 - 中华人民共和国China "bisque", "bisque", "bisque"],)# 源节点:2 - 日本 data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.show()

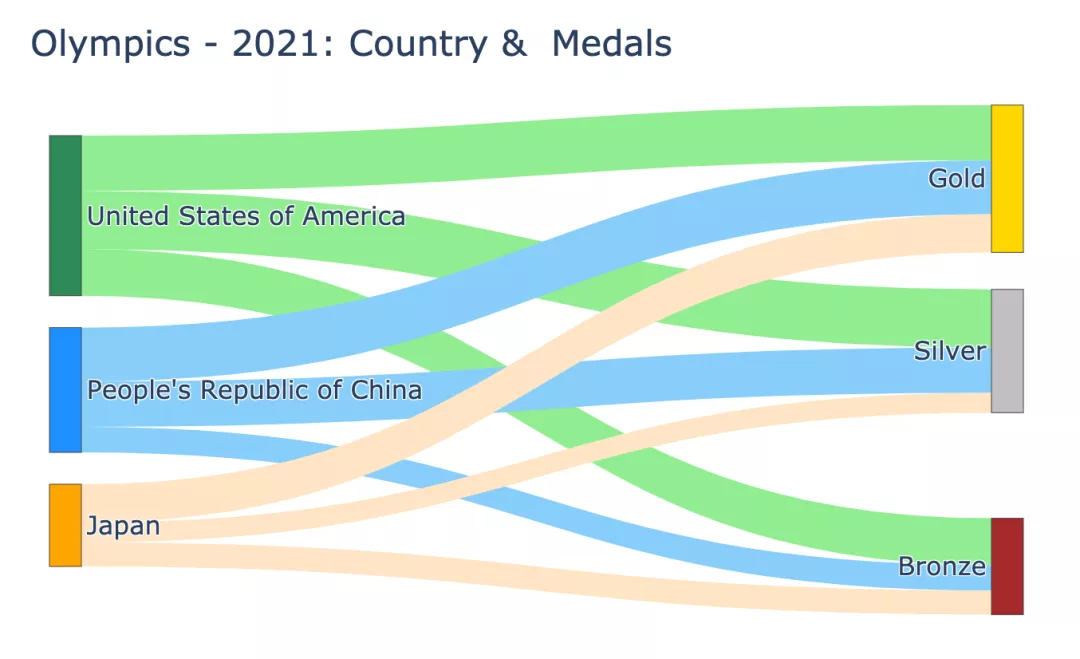
이것은 매우 기본적인 Sankey 다이어그램입니다. 그런데 차트가 너무 넓어서 은메달이 금메달보다 먼저 나타나는 것을 본 적이 있나요?
노드의 위치와 너비를 조정하는 방법은 다음과 같습니다.
노드 위치 및 차트 너비 조정
노드 위치를 명시적으로 지정하려면 노드의 x 및 y 위치를 추가하세요. 값은 0에서 1 사이여야 합니다.
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) x = [ 0,0,0,0.5,0.5,0.5], y = [ 0,0.5,1,0.1,0.5,1],) data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.update_layout(title="Olympics - 2021: Country &Medals",font_size=16) fig.show()
그래서 우리는 간결한 Sankey 다이어그램을 얻었습니다.
코드에 전달된 다양한 매개 변수가 그래프의 노드와 링크에 어떻게 매핑되는지 살펴보겠습니다.
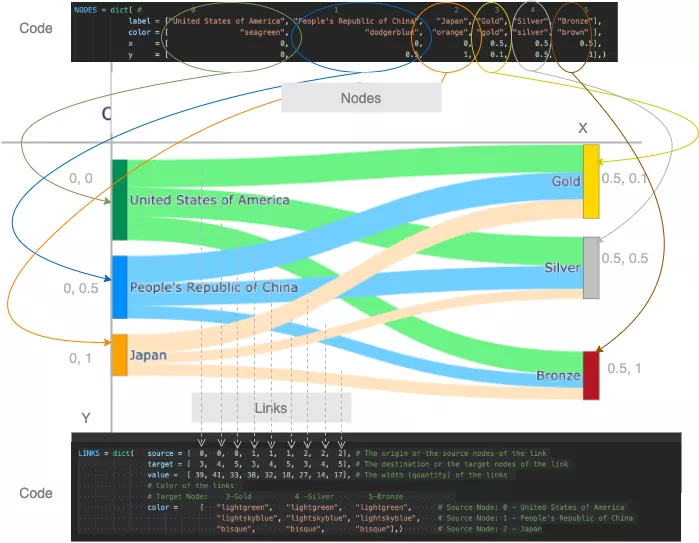
代码如何映射到桑基图
添加有意义的悬停标签
我们都知道plotly绘图是交互的,我们可以将鼠标悬停在节点和链接上以获取更多信息。
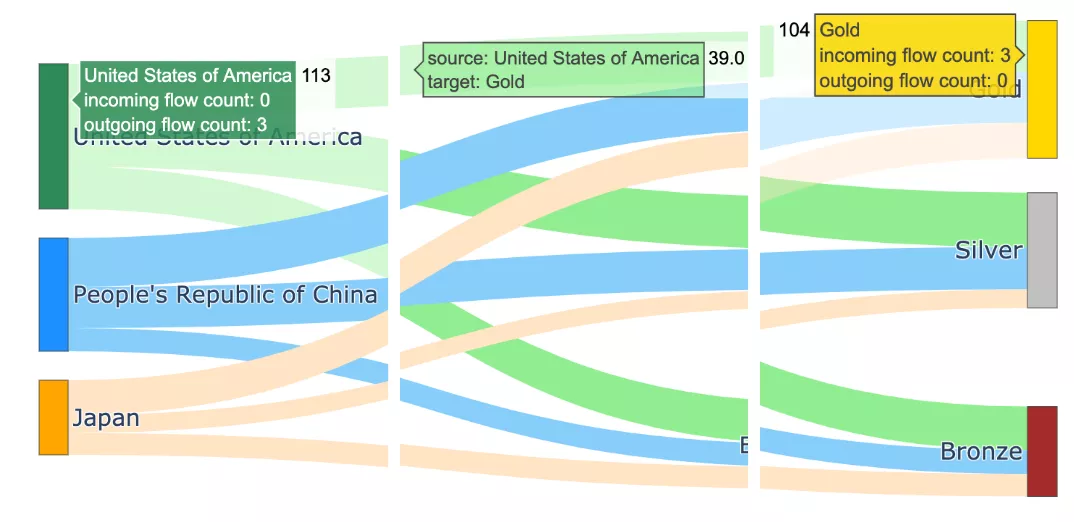
带有默认悬停标签的桑基图
当将鼠标悬停在图上,将会显示详细信息。悬停标签中显示的信息是默认文本:节点、节点名称、传入流数、传出流数和总值。
例如:
- 节点美国共获得11枚奖牌(=39金+41银+33铜)
- 节点金牌共有104枚奖牌(=美国39枚,中国38枚,日本27枚)
如果我们觉得这些标签太冗长了,我们可以对此进程改进。使用hovertemplate参数改进悬停标签的格式
- 对于节点,由于hoverlabels 没有提供新信息,通过传递一个空hovertemplate = ""来去掉hoverlabel
- 对于链接,可以使标签简洁,格式为-
- 对于节点和链接,让我们使用后缀"Medals"显示值。例如 113 枚奖牌而不是 113 枚。这可以通过使用具有适当valueformat和valuesuffix的update_traces函数来实现。
NODES = dict(
# 0 1 23 4 5
label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"],
color = ["seagreen", "dodgerblue","orange", "gold", "silver", "brown" ],
x = [ 0,0, 0,0.5,0.5,0.5],
y = [ 0,0.5, 1,0.1,0.5,1],
hovertemplate=" ",)
LINK_LABELS = []
for country in ["USA","China","Japan"]:
for medal in ["Gold","Silver","Bronze"]:
LINK_LABELS.append(f"{country}-{medal}")
LINKS = dict(source = [0,0,0,1,1,1,2,2,2],
# 链接的起点或源节点
target = [3,4,5,3,4,5,3,4,5],
# 链接的目的地或目标节点
value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17],
# 链接的宽度(数量)
# 链接的颜色
# 目标节点:3-Gold4 -Silver5-Bronze
color = ["lightgreen", "lightgreen", "lightgreen", # 源节点:0 - 美国
"lightskyblue", "lightskyblue", "lightskyblue", # 源节点:1 - 中国
"bisque", "bisque", "bisque"],# 源节点:2 - 日本
label = LINK_LABELS,
hovertemplate="%{label}",)
data = go.Sankey(node = NODES, link = LINKS)
fig = go.Figure(data)
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16, width=1200, height=500,)
fig.update_traces(valueformat='3d',
valuesuffix='Medals',
selector=dict(type='sankey'))
fig.update_layout(hoverlabel=dict(bgcolor="lightgray",
font_size=16,
font_family="Rockwell"))
fig.show("png") #fig.show()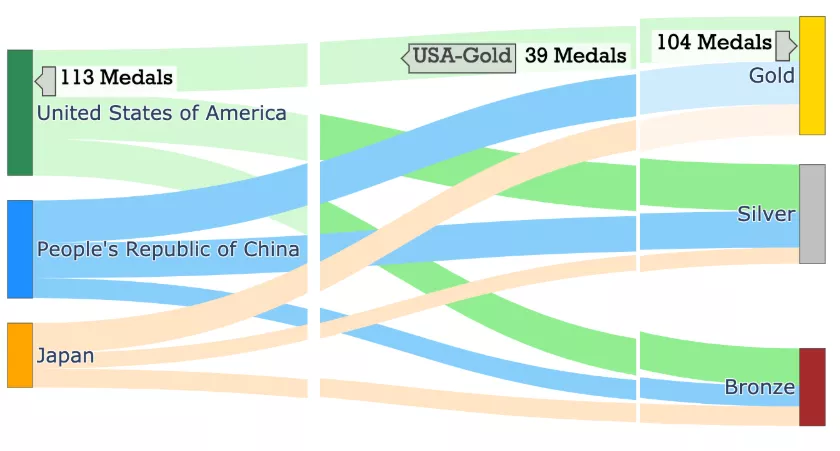
带有改进的悬停标签的桑基图
对多个节点和级别进行泛化相对于链接,节点被称为源和目标。作为一个链接目标的节点可以是另一个链接的源。
该代码可以推广到处理数据集中的所有国家。
还可以将图表扩展到另一个层次,以可视化各国的奖牌总数。
NUM_COUNTRIES = 5
X_POS, Y_POS = 0.5, 1/(NUM_COUNTRIES-1)
NODE_COLORS = ["seagreen", "dodgerblue", "orange", "palevioletred", "darkcyan"]
LINK_COLORS = ["lightgreen", "lightskyblue", "bisque", "pink", "lightcyan"]
source = []
node_x_pos, node_y_pos = [], []
node_labels, node_colors = [], NODE_COLORS[0:NUM_COUNTRIES]
link_labels, link_colors, link_values = [], [], []
# 第一组链接和节点
for i in range(NUM_COUNTRIES):
source.extend([i]*3)
node_x_pos.append(0.01)
node_y_pos.append(round(i*Y_POS+0.01,2))
country = df_medals['Country'][i]
node_labels.append(country)
for medal in ["Gold", "Silver", "Bronze"]:
link_labels.append(f"{country}-{medal}")
link_values.append(df_medals[f"{medal} Medals"][i])
link_colors.extend([LINK_COLORS[i]]*3)
source_last = max(source)+1
target = [ source_last, source_last+1, source_last+2] * NUM_COUNTRIES
target_last = max(target)+1
node_labels.extend(["Gold", "Silver", "Bronze"])
node_colors.extend(["gold", "silver", "brown"])
node_x_pos.extend([X_POS, X_POS, X_POS])
node_y_pos.extend([0.01, 0.5, 1])
# 最后一组链接和节点
source.extend([ source_last, source_last+1, source_last+2])
target.extend([target_last]*3)
node_labels.extend(["Total Medals"])
node_colors.extend(["grey"])
node_x_pos.extend([X_POS+0.25])
node_y_pos.extend([0.5])
for medal in ["Gold","Silver","Bronze"]:
link_labels.append(f"{medal}")
link_values.append(df_medals[f"{medal} Medals"][:i+1].sum())
link_colors.extend(["gold", "silver", "brown"])
print("node_labels", node_labels)
print("node_x_pos", node_x_pos); print("node_y_pos", node_y_pos)node_labels ['United States of America', "People's Republic of China", 'Japan', 'Great Britain', 'ROC', 'Gold', 'Silver', 'Bronze', 'Total Medals'] node_x_pos [0.01, 0.01, 0.01, 0.01, 0.01, 0.5, 0.5, 0.5, 0.75] node_y_pos [0.01, 0.26, 0.51, 0.76, 1.01, 0.01, 0.5, 1, 0.5]
# 显示的图
NODES = dict(pad= 20, thickness = 20,
line = dict(color = "lightslategrey",
width = 0.5),
hovertemplate=" ",
label = node_labels,
color = node_colors,
x = node_x_pos,
y = node_y_pos, )
LINKS = dict(source = source,
target = target,
value = link_values,
label = link_labels,
color = link_colors,
hovertemplate="%{label}",)
data = go.Sankey(arrangement='snap',
node = NODES,
link = LINKS)
fig = go.Figure(data)
fig.update_traces(valueformat='3d',
valuesuffix=' Medals',
selector=dict(type='sankey'))
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16,
width=1200,
height=500,)
fig.update_layout(hoverlabel=dict(bgcolor="grey",
font_size=14,
font_family="Rockwell"))
fig.show("png") 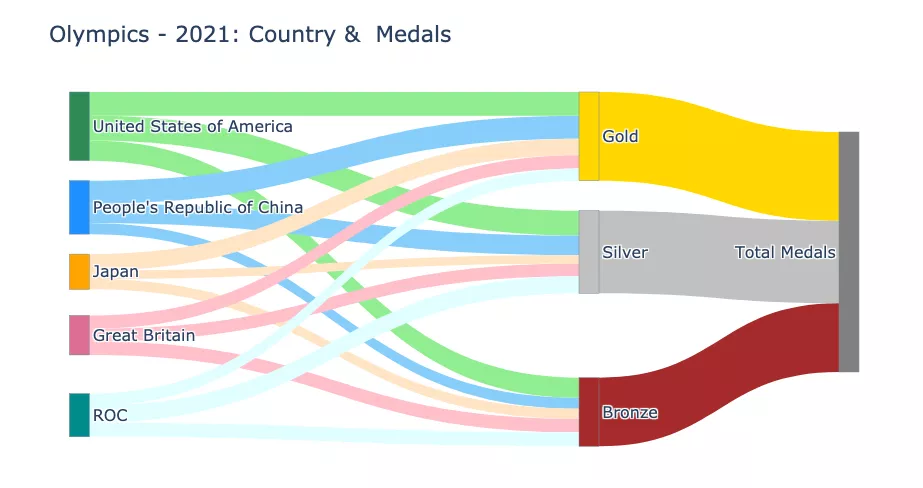
위 내용은 Python은 멋진 Sankey 다이어그램을 그립니다. 배워 보셨나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7536
7536
 15
1379
52
82
11
55
19
21
86
15
1379
52
82
11
55
19
21
86

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
CentOS 시스템에서 Pytorch 모델을 효율적으로 교육하려면 단계가 필요 하며이 기사는 자세한 가이드를 제공합니다. 1. 환경 준비 : 파이썬 및 종속성 설치 : CentOS 시스템은 일반적으로 파이썬을 사전 설치하지만 버전은 더 오래 될 수 있습니다. YUM 또는 DNF를 사용하여 Python 3 및 Upgrade Pip : Sudoyumupdatepython3 (또는 SudodnfupdatePython3), PIP3INSTALL-UPGRADEPIP를 설치하는 것이 좋습니다. CUDA 및 CUDNN (GPU 가속도) : NVIDIAGPU를 사용하는 경우 Cudatool을 설치해야합니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택할 때 다음과 같은 주요 요소를 고려해야합니다. 1. Cuda 버전 호환성 GPU 지원 : NVIDIA GPU가 있고 GPU 가속도를 사용하려면 해당 CUDA 버전을 지원하는 Pytorch를 선택해야합니다. NVIDIA-SMI 명령을 실행하여 지원되는 CUDA 버전을 볼 수 있습니다. CPU 버전 : GPU가 없거나 GPU를 사용하지 않으려면 Pytorch의 CPU 버전을 선택할 수 있습니다. 2. 파이썬 버전 Pytorch
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
