

색인이 미리 정렬되어 있어 검색 시 이진 검색 등 효율적인 알고리즘을 적용할 수 있습니다. 일반 순차 검색의 복잡도는 O(n)인 반면, 이진 검색의 복잡도는 O(log2n)입니다. n이 매우 클 경우 둘 사이의 효율성 차이는 엄청납니다.

이 튜토리얼의 운영 환경: windows7 시스템, mysql8 버전, Dell G3 컴퓨터.
Mysql은 인터넷에서 매우 인기 있는 데이터베이스입니다. 특히, Mysql 데이터의 저장 형식과 인덱스의 디자인이 Mysql의 전체 데이터 검색 성능을 결정합니다. .
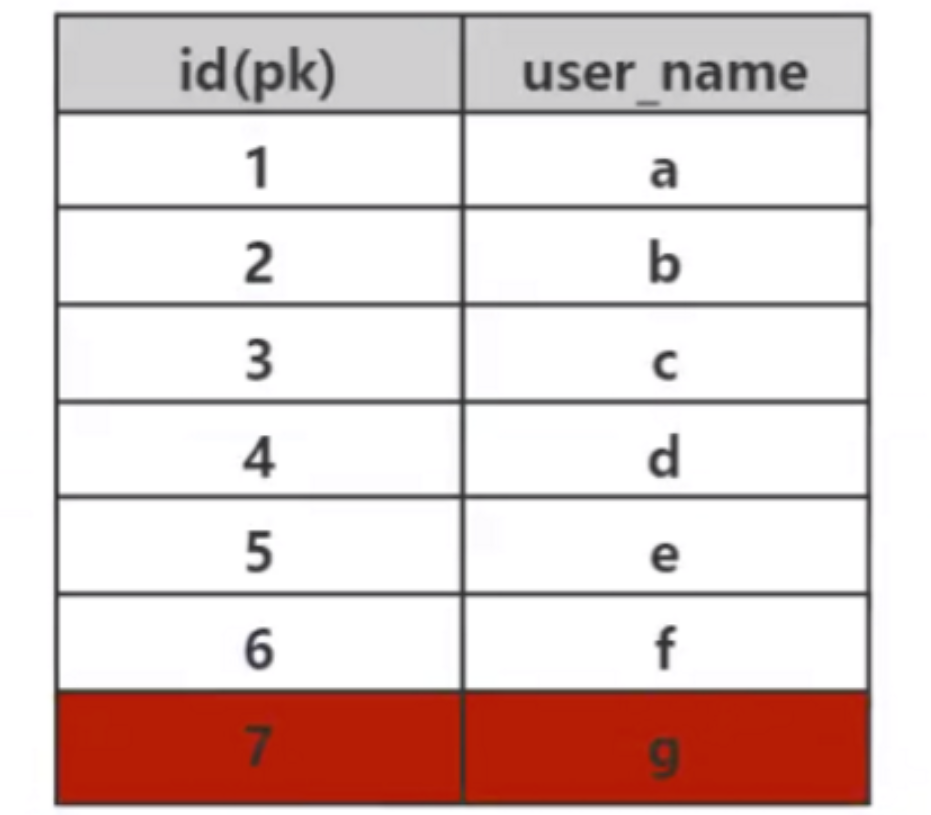
인덱스의 기능은 데이터를 빠르게 검색하는 것이고, 빠른 검색의 핵심은 데이터 구조라는 것을 알고 있습니다. 다양한 데이터 구조를 선택함으로써 다양한 데이터를 신속하게 검색할 수 있습니다. 데이터베이스에는 많은 양의 데이터가 저장되어 있고 효율적인 인덱스를 사용하면 엄청난 시간을 절약할 수 있기 때문에 효율적인 검색 알고리즘이 매우 중요합니다. 예를 들어, 다음 데이터 테이블에서 Mysql이 인덱스 알고리즘을 구현하지 않은 경우 id=7인 데이터를 찾으려면 폭력적인 순차 탐색을 통해서만 id=7인 데이터를 찾을 수 있습니다. 7번 비교해야 합니다. 이 테이블에 1,000만 개의 데이터가 저장되어 있다면 id=1000W인 데이터를 검색하려면 1000W를 비교해야 합니다.
해시 테이블(Hash)
해시 테이블은 빠른 데이터 검색에 효과적인 도구입니다.
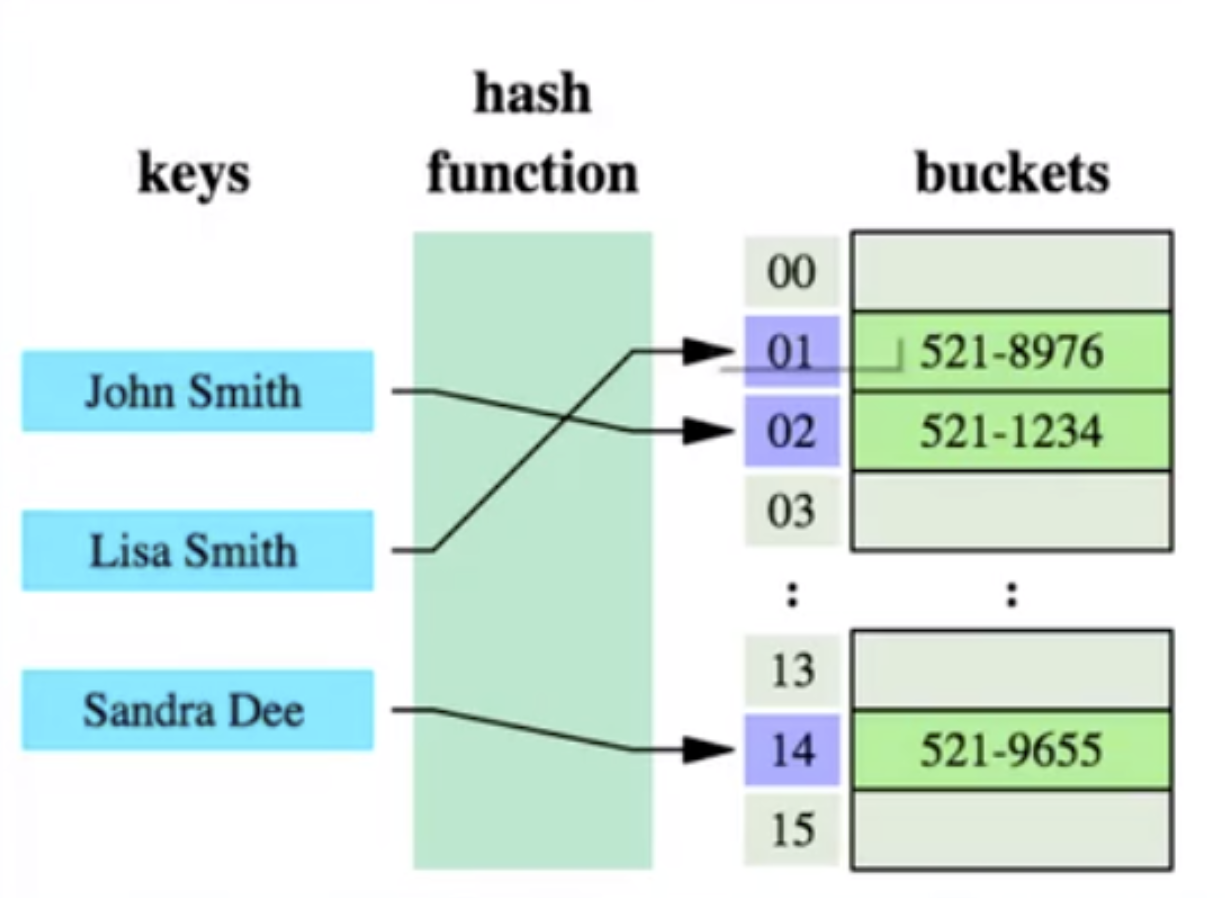
해시 알고리즘: 해시 알고리즘이라고도 하며 해시 함수를 통해 모든 값(키)을 고정 길이 키 주소로 변환하고 이 주소를 사용하여 특정 데이터에 대한 데이터 구조를 만듭니다.
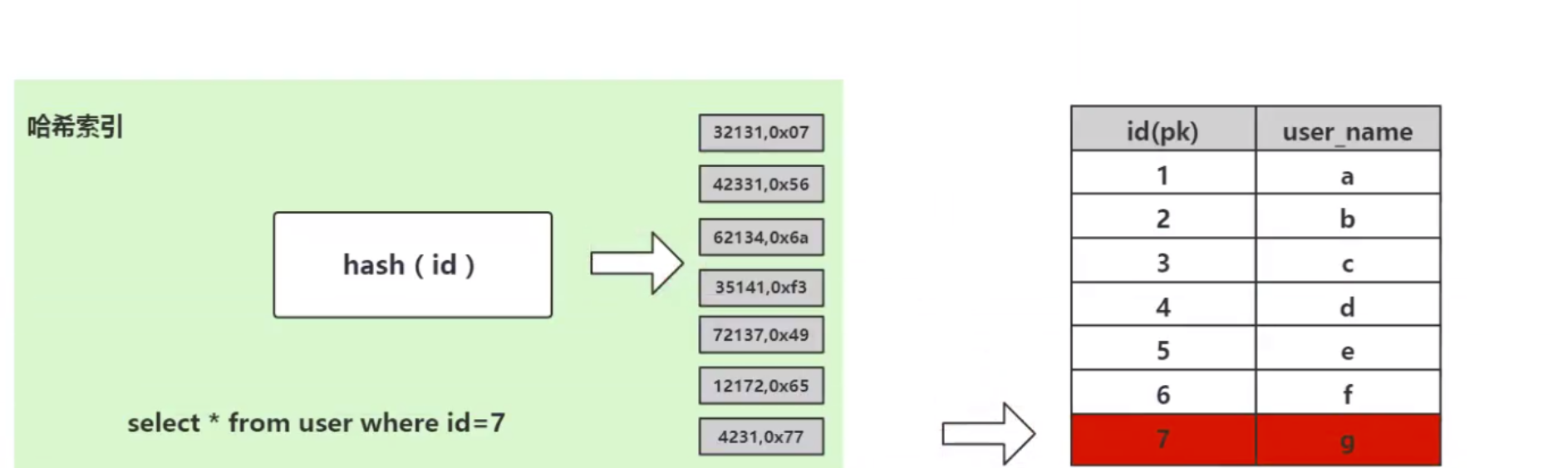
이 데이터베이스 테이블 사용자를 고려하십시오. 테이블에 id=7인 데이터를 검색해야 합니다. SQL 구문은 다음과 같습니다.
select * from user where id=7;
해시 알고리즘이 먼저 계산하고 저장합니다. data with id=7 물리 주소 addr=hash(7)=4231이고, 4231로 매핑된 물리 주소는 0x77입니다. id=7로 저장된 데이터의 물리 주소입니다. 이 독립된 주소를 통해 만나보실 수 있습니다. 이는 해시 알고리즘이 데이터를 빠르게 검색하기 위해 사용하는 계산 프로세스입니다.
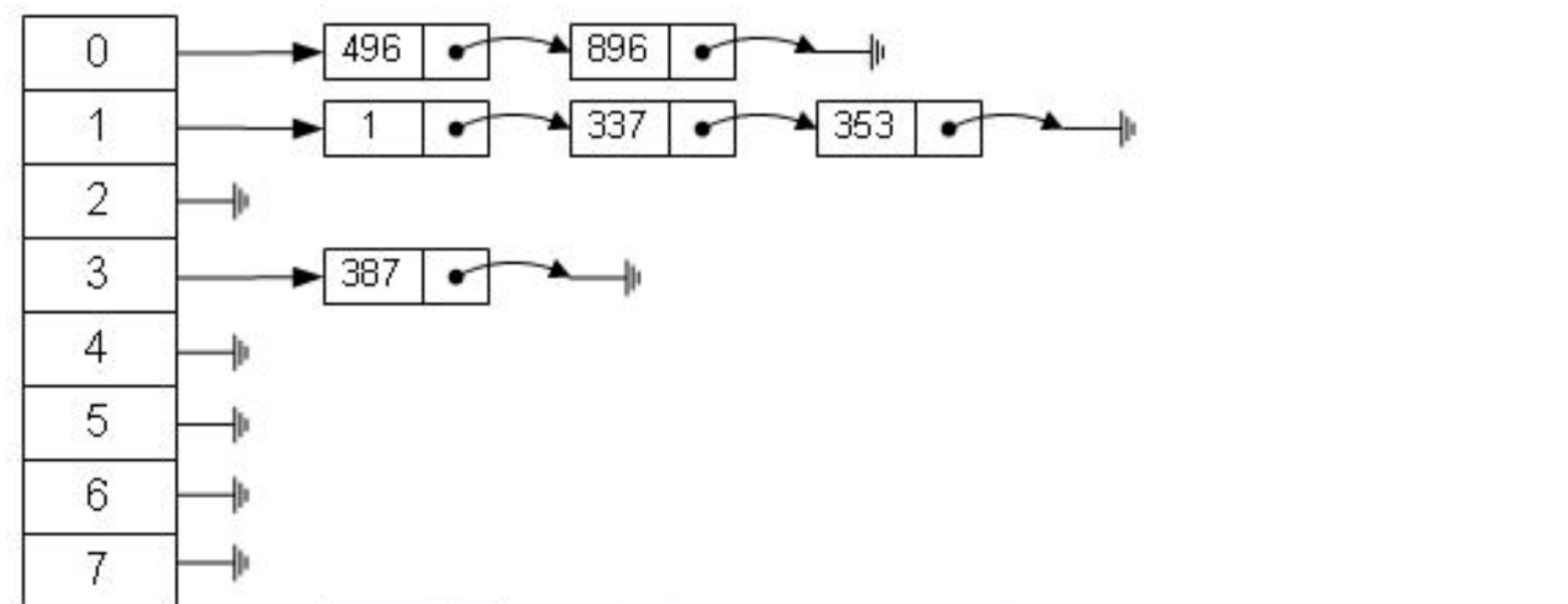
하지만 해시 알고리즘에는 데이터 충돌 문제가 있습니다. 즉, 해시 함수는 서로 다른 키에 대해 동일한 결과를 계산할 수 있습니다. 예를 들어 hash(7)은 hash(199)와 동일한 결과를 계산할 수 있지만 이는 키가 다릅니다. 동일한 결과로 매핑되는데, 이는 충돌 문제입니다. 충돌 문제를 해결하는 일반적인 방법은 링크드 리스트를 사용하여 충돌하는 데이터를 연결하는 체인 주소 방법입니다. 해시 값을 계산한 후에는 데이터 연결 리스트에서 해시 값이 충돌하는지 여부도 확인해야 하며, 충돌이 있으면 실제 키에 해당하는 데이터를 찾을 때까지 연결 리스트 끝까지 순회해야 합니다.
从算法时间复杂度分析来看,哈希算法时间复杂度为 O(1),检索速度非常快。比如查找 id=7 的数据,哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?
因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
select * from user where id \>3;
针对以上这个语句,我们希望做的是找出 id>3 的数据,这是很典型的范围查找。如果使用哈希算法实现的索引,范围查找怎么做呢?一个简单的思路就是一次把所有数据找出来加载到内存,然后再在内存里筛选筛选目标范围内的数据。但是这个范围查找的方法也太笨重了,没有一点效率而言。
所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构。
二叉查找树(BST)
二叉查找树是一种支持数据快速查找的数据结构,如图下所示:
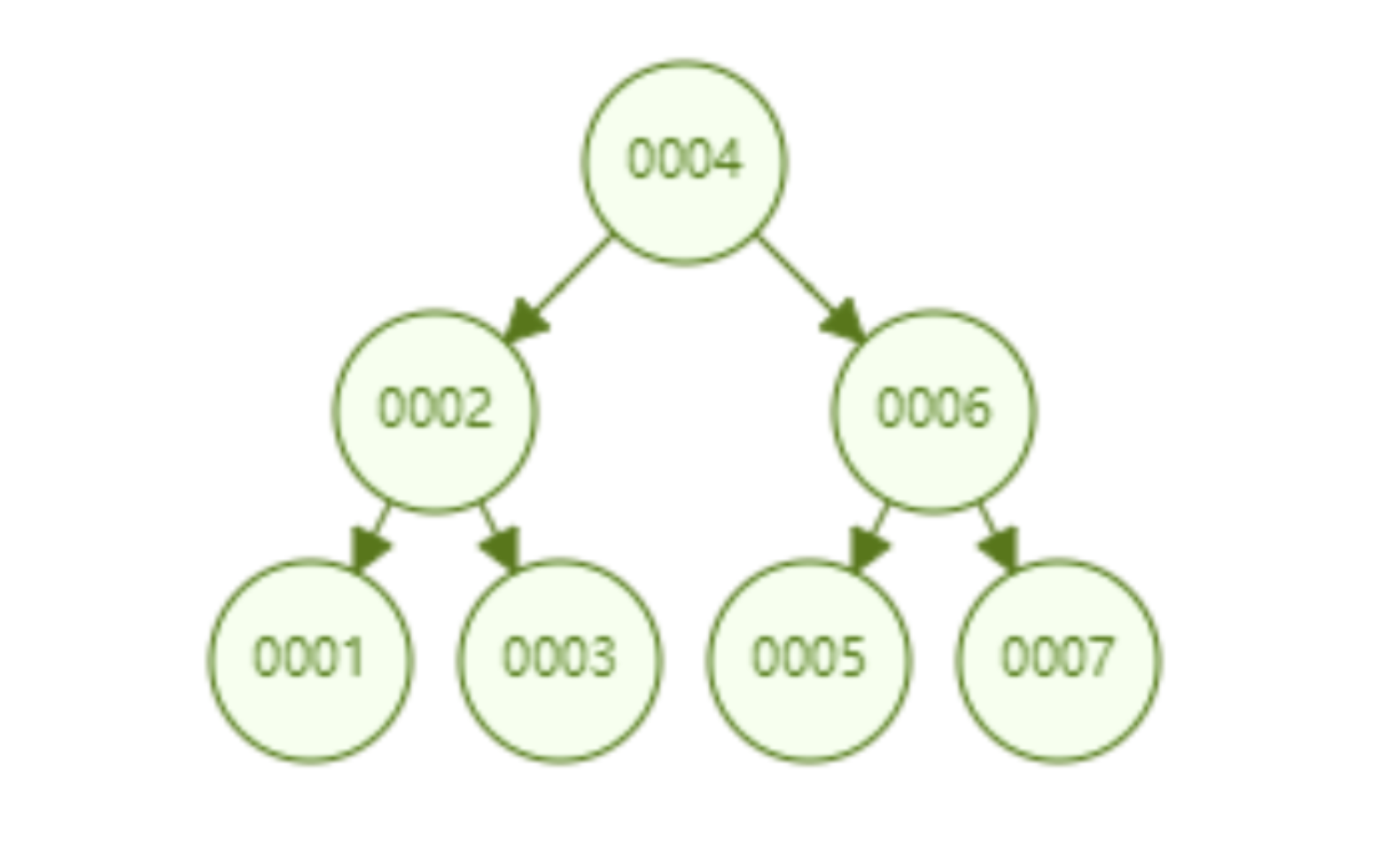
二叉查找树的时间复杂度是 O(lgn),比如针对上面这个二叉树结构,我们需要计算比较 3 次就可以检索到 id=7 的数据,相对于直接遍历查询省了一半的时间,从检索效率上看来是能做到高速检索的。此外二叉树的结构能不能解决哈希索引不能提供的范围查找功能呢?
答案是可以的。观察上面的图,二叉树的叶子节点都是按序排列的,从左到右依次升序排列,如果我们需要找 id>5 的数据,那我们取出节点为 6 的节点以及其右子树就可以了,范围查找也算是比较容易实现。
但是普通的二叉查找树有个致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为 O(N),检索性能急剧下降。比如以下这个情况,二叉树已经极度不平衡了,已经退化为链表了,检索速度大大降低。此时检索 id=7 的数据的所需要计算的次数已经变为 7 了。
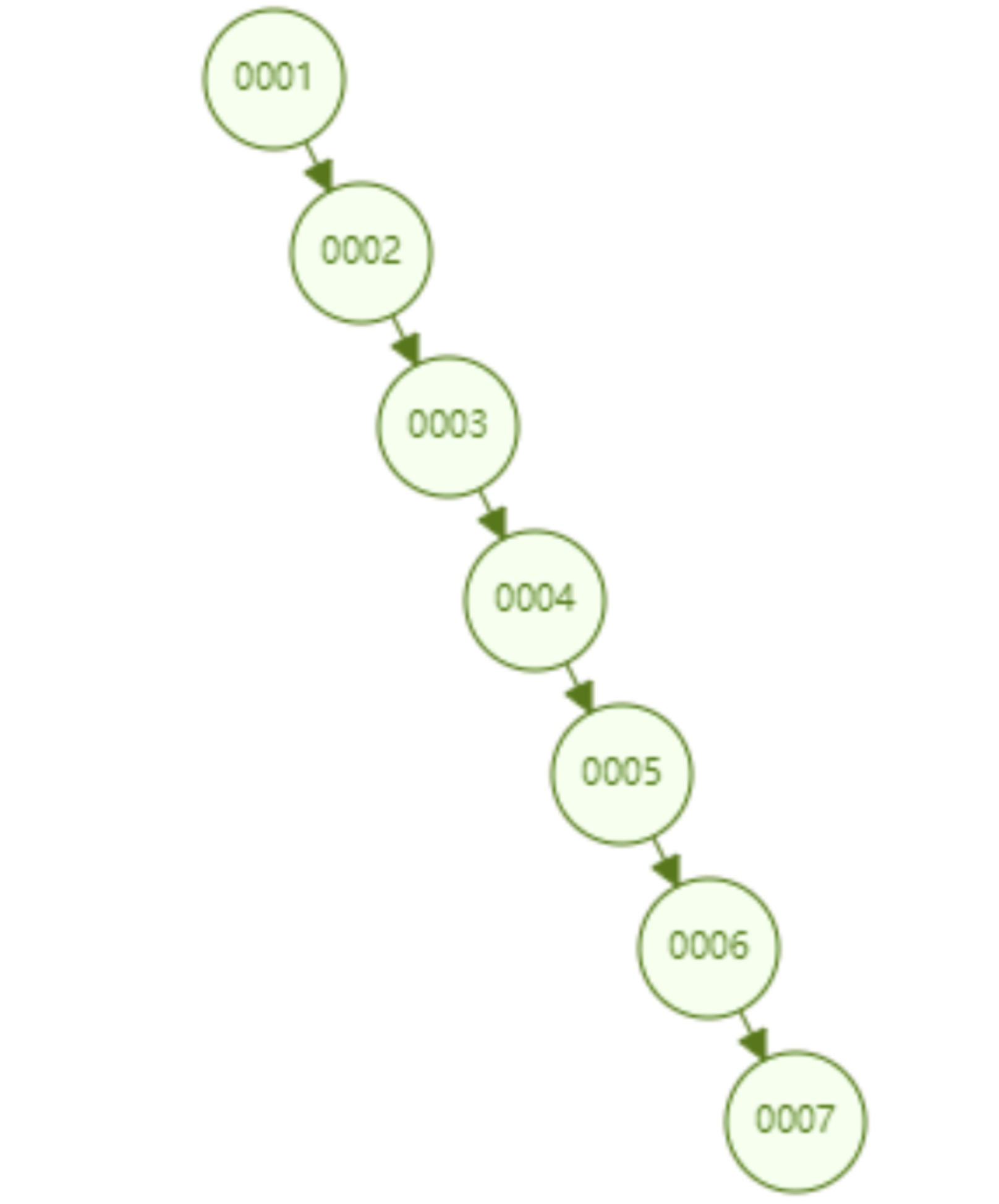
데이터베이스에서 데이터 자동 증가는 매우 일반적인 형태입니다. 예를 들어 테이블의 기본 키는 id이고 기본 키는 일반적으로 기본적으로 자동 증가입니다. 이진 트리를 인덱스로 사용하면 위에서 소개한 불균형 상태로 인해 발생하는 선형 검색 문제가 필연적으로 발생합니다. 따라서 단순 이진 검색 트리는 불균형으로 인해 검색 성능이 저하되는 문제가 있으며, Mysql의 기본 인덱스를 구현하는 데 직접 사용할 수 없습니다.
AVL 트리와 레드-블랙 트리
이진 검색 트리에는 불균형 문제가 있습니다. 따라서 학자들은 트리 노드의 자동 회전 및 조정을 통해 이진 트리가 항상 기본적으로 균형 잡힌 상태를 유지할 수 있다고 제안합니다. 이진 검색 트리는 최적의 검색 성능을 위해 검색 트리를 유지 관리할 수 있습니다. 이 아이디어를 기반으로 한 자체 조정 평형 상태 이진 트리에는 AVL 트리와 레드-블랙 트리가 포함됩니다.
먼저 레드-블랙 트리에 대해 간단히 소개하겠습니다. 이는 자동으로 트리 모양을 조정하는 트리 구조입니다. 예를 들어 이진 트리가 불균형 상태에 있을 때 레드-블랙 트리는 자동으로 왼쪽으로 회전하고 올바른 노드와 노드는 트리의 모양을 조정하기 위해 색상을 변경하여 기본 평형 상태(시간 복잡도는 O(logn))를 유지하므로 검색 효율성이 크게 감소하지 않습니다. 예를 들어, 데이터 노드를 1부터 7까지 오름차순으로 삽입하면 일반적인 이진 검색 트리는 연결리스트로 퇴화되지만, 레드-블랙 트리는 그림과 같이 기본 균형을 유지하기 위해 지속적으로 트리의 모양을 조정합니다. 아래 그림에서. 아래 레드-블랙 트리에서 id=7을 검색할 때 비교되는 노드 수는 4개로 여전히 이진 트리의 좋은 검색 효율성을 유지하고 있다.
레드-블랙 트리는 평균 검색 효율이 좋고 극단적인 O(n) 상황이 없습니다. 그렇다면 레드-블랙 트리를 MySQL의 기본 인덱스 구현으로 사용할 수 있을까요? 사실, 레드-블랙 트리에도 몇 가지 문제가 있습니다. 다음 예를 살펴보세요.
레드-블랙 트리는 1~7개의 노드를 순차적으로 삽입하며, id=7을 검색할 때 계산해야 하는 노드 수는 4개입니다.
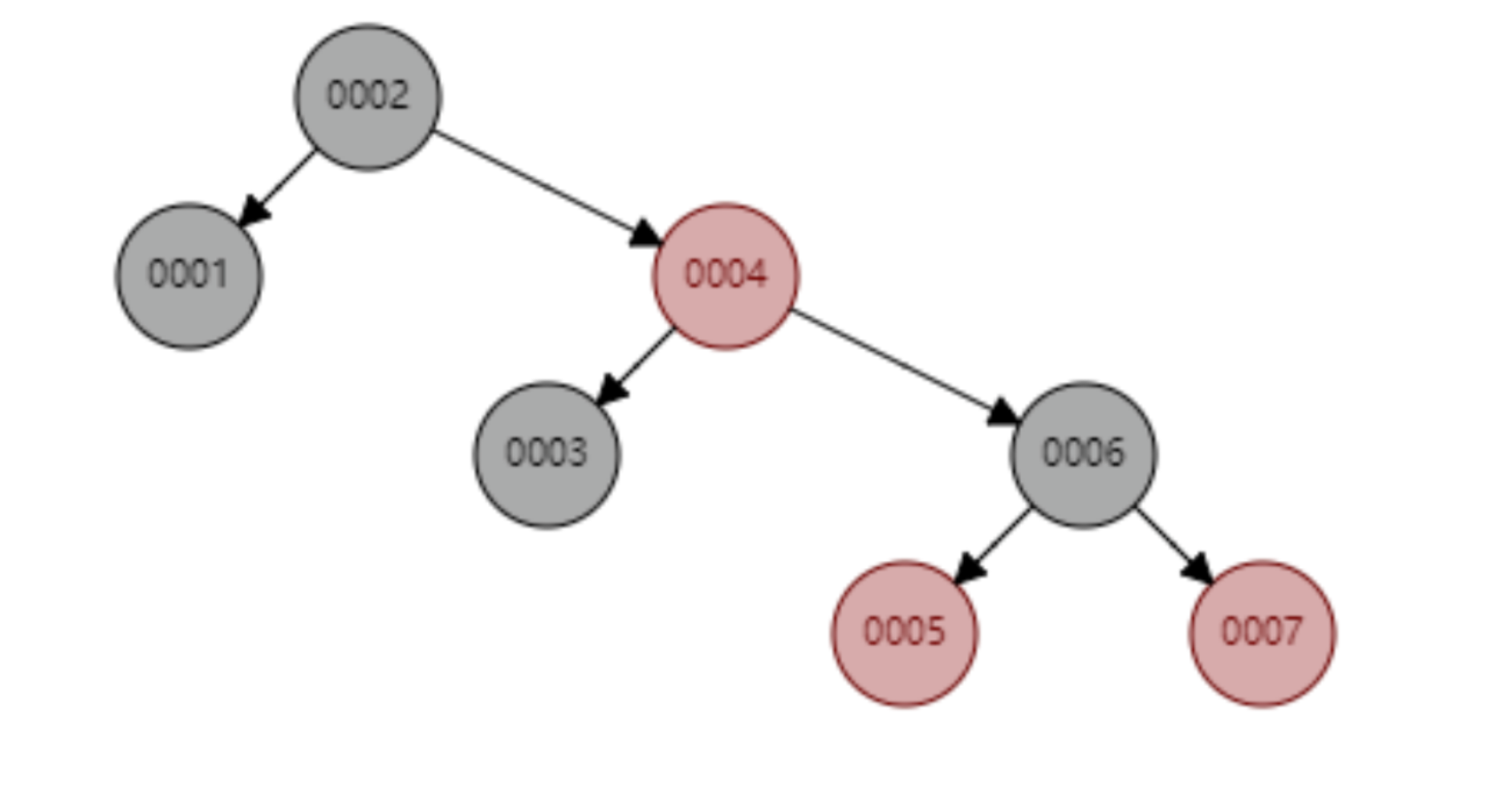
레드-블랙 트리는 1~16개의 노드를 순차적으로 삽입하는데, id=16을 찾기 위해 비교해야 하는 노드의 개수는 6번이다. 이 나무의 모양을 관찰해 보세요. 데이터를 순차적으로 삽입하면 나무의 모양이 항상 "오른쪽으로 기울어지는" 추세를 보였습니다. 맞습니까? 근본적으로 레드-블랙 트리는 이진 검색 트리를 완전히 해결하지 못합니다. 비록 이러한 "오른쪽으로 기울어지는" 추세가 선형 연결 목록으로 변질되는 이진 검색 트리보다 훨씬 덜 과장되어 있음에도 불구하고 기본 기본 키 자동 증가 작업은 다음과 같습니다. 데이터베이스의 기본 키는 일반적으로 수백만, 수천만 개입니다. 레드-블랙 트리에 이런 문제가 있으면 엄청난 양의 검색 성능도 소모하게 됩니다. 우리 데이터베이스는 이러한 무의미한 대기를 견딜 수 없습니다.
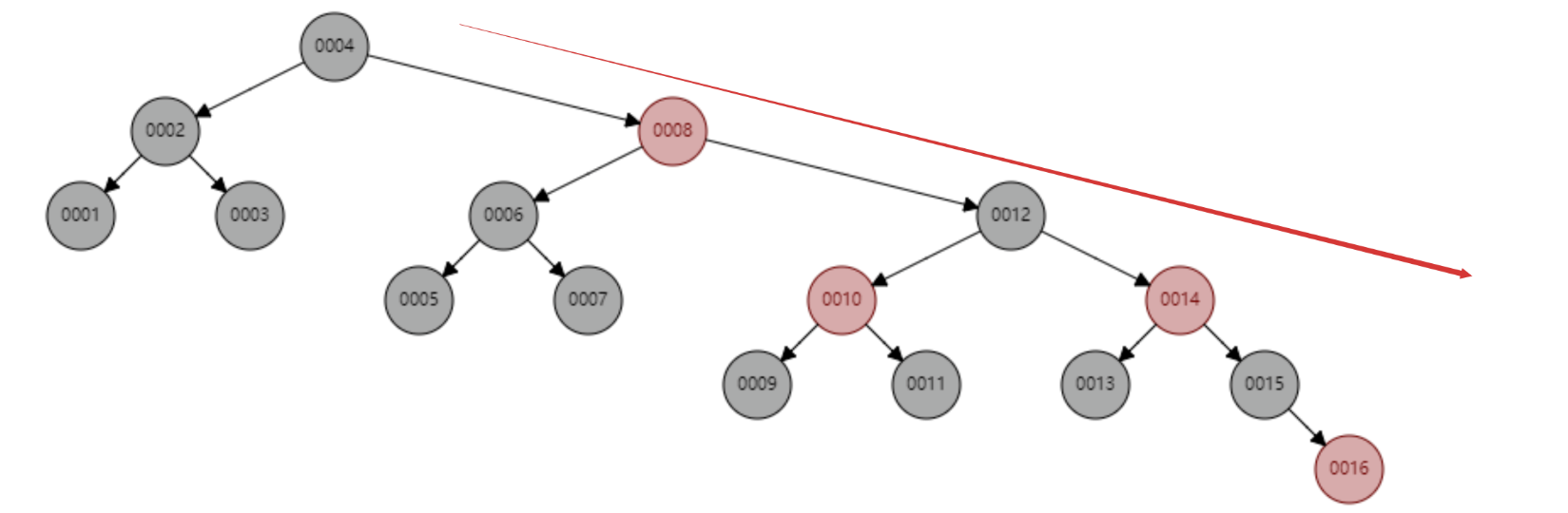
이제 더 엄격한 또 다른 자체 균형 이진 트리인 AVL 트리를 고려해 보세요. AVL 트리는 절대적으로 균형 잡힌 이진 트리이기 때문에 이진 트리의 모양을 조정하는 데 더 많은 성능을 소비합니다.
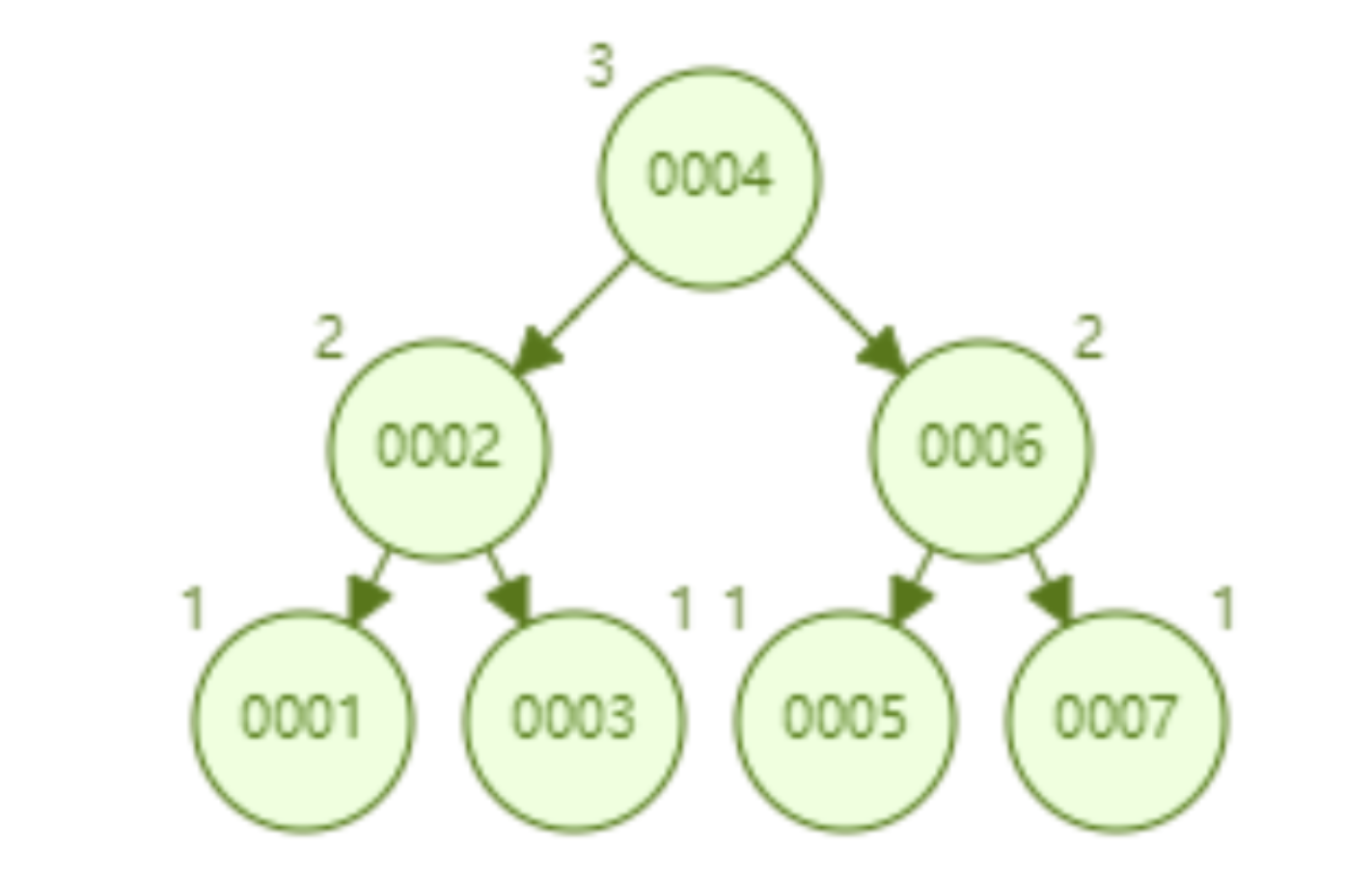
AVL 트리는 1~7개의 노드를 순차적으로 삽입하며, id=7을 찾기 위해 노드를 비교하는 횟수는 3회입니다.
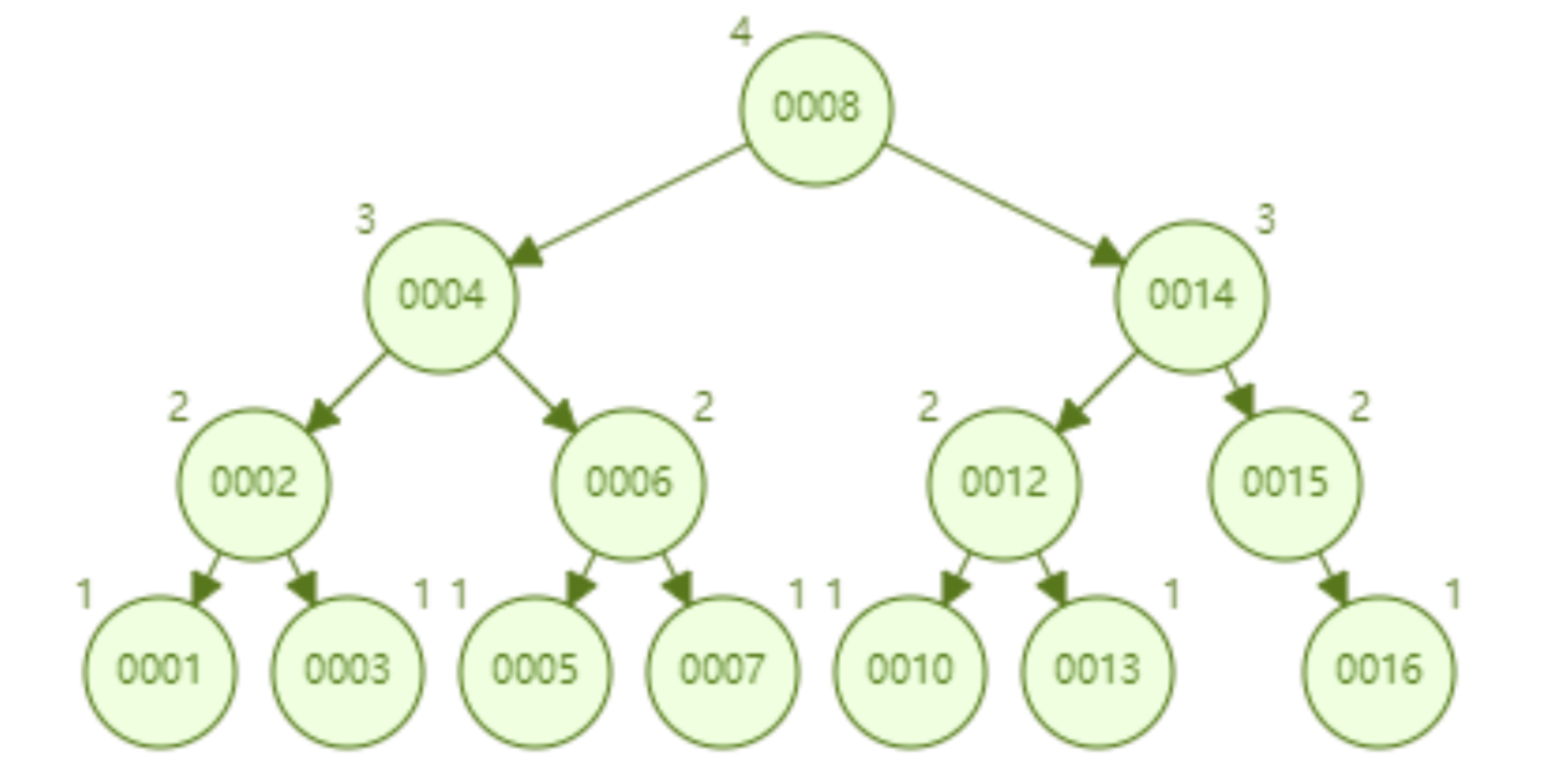
AVL 트리는 1~16개의 노드를 순차적으로 삽입하는데, id=16을 찾기 위해 비교해야 하는 노드의 개수는 4개입니다. 검색 효율성 측면에서 AVL 트리의 검색 속도는 레드-블랙 트리(AVL 트리는 4개 비교, 레드-블랙 트리는 6개 비교)보다 빠릅니다. 나무의 모양으로 볼 때 AVL 나무에는 레드-블랙 나무의 "오른쪽으로 기울어짐" 문제가 없습니다. 즉, 순차적 삽입을 많이 해도 쿼리 성능 저하로 이어지지 않아 레드-블랙 트리 문제가 근본적으로 해결된다.
AVL 트리의 장점을 요약하면
AVL 트리는 데이터 검색을 위한 데이터 구조로 정말 좋은 것 같지만, AVL 트리는 MySQL 데이터베이스의 인덱스 데이터 구조에는 적합하지 않습니다. 왜냐하면 다음과 같은 문제를 고려하기 때문입니다.
데이터베이스 쿼리의 병목 현상 데이터는 디스크 IO입니다. AVL 트리를 사용하고 각 트리 노드는 하나의 데이터만 저장하고 하나의 디스크 IO로 데이터를 메모리에 로드할 수 있습니다. ID=7로 데이터를 쿼리하려면 디스크 IO를 세 번 수행해야 합니다. 따라서 데이터베이스 인덱스를 설계할 때 디스크 IO 수를 최대한 줄이는 방법을 먼저 고려해야 합니다.
디스크 IO의 한 가지 특징은 디스크에서 1B 데이터와 1KB 데이터를 읽는 데 걸리는 시간이 기본적으로 동일하다는 것입니다. 이 아이디어를 바탕으로 트리 노드에 최대한 많은 데이터를 저장할 수 있으며, 하나의 디스크 IO가 로드됩니다. 이것이 B-트리와 B+-트리의 설계 원리입니다.
B-tree
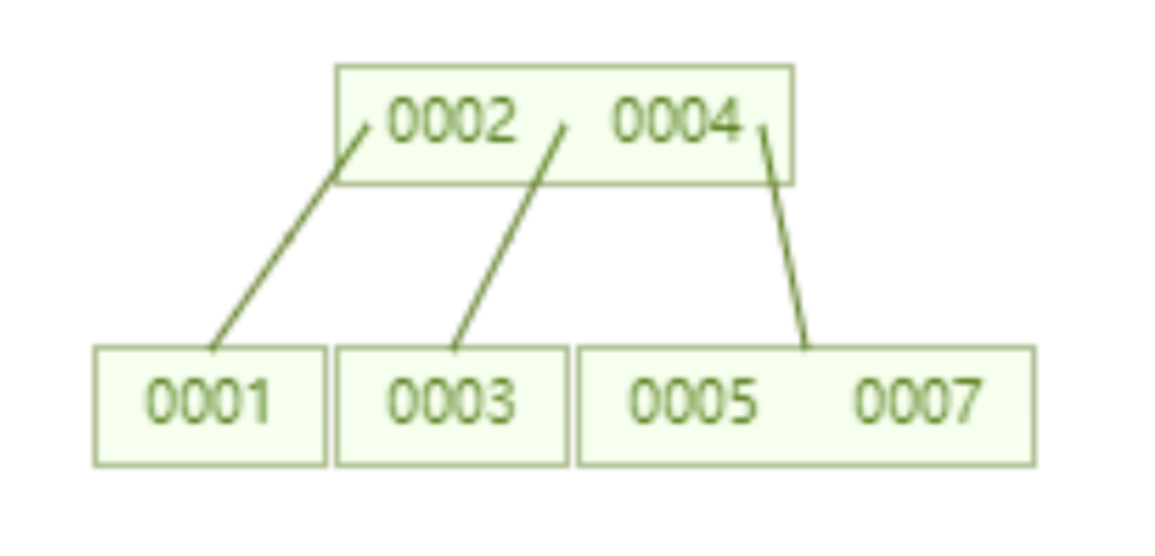
아래 B-트리는 노드당 최대 2개의 키를 저장하도록 제한됩니다. 노드에 키가 2개 이상 있으면 자동으로 분할됩니다. 예를 들어, 다음 B-트리는 7개의 데이터를 저장합니다. id=7인 데이터의 특정 위치를 확인하려면 두 개의 노드만 쿼리하면 됩니다. 즉, 두 개의 디스크 IO로 지정된 데이터를 쿼리할 수 있습니다. AVL 트리.
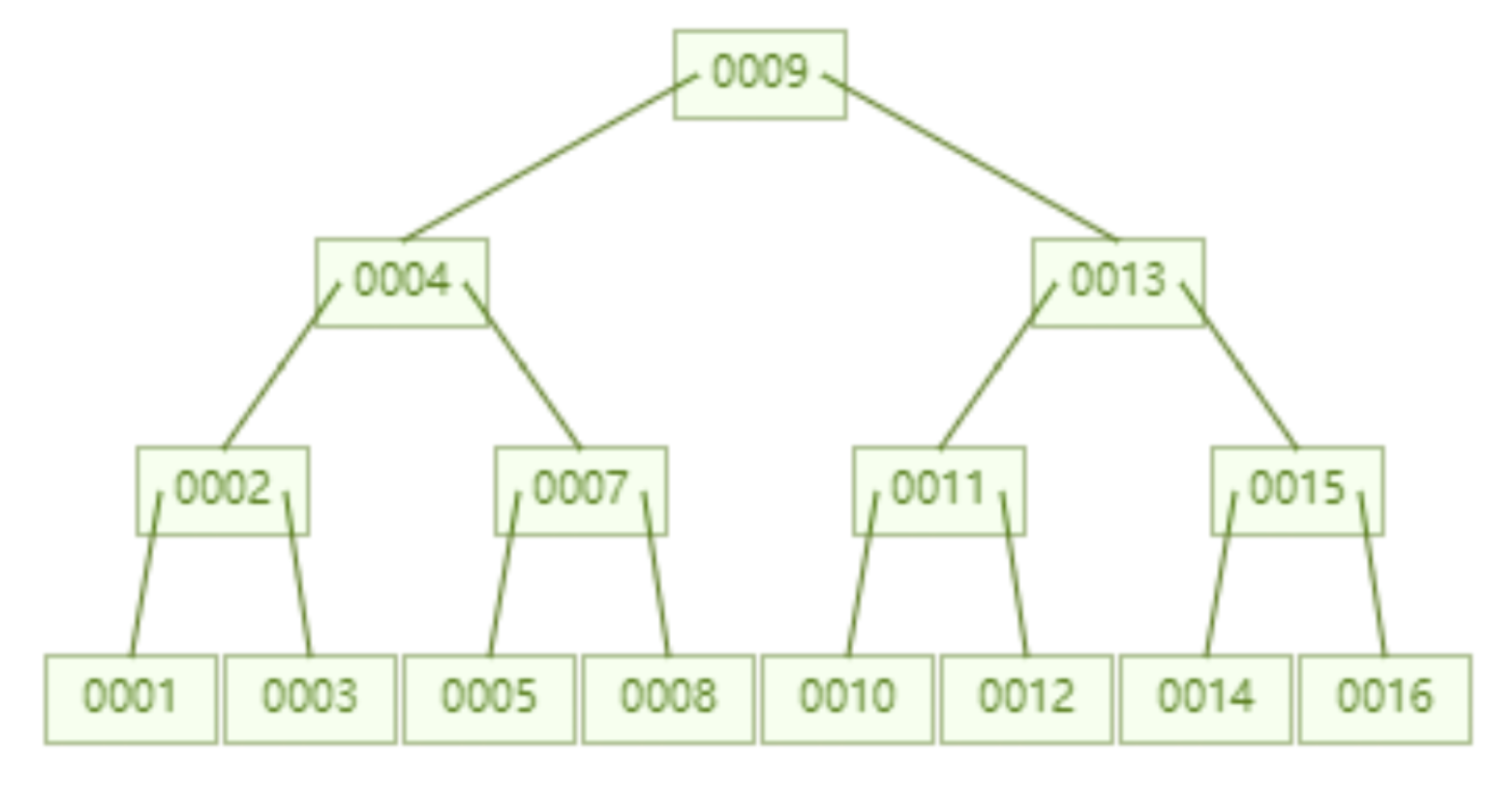
다음은 16개의 데이터를 저장하는 B-트리입니다. 마찬가지로 각 노드는 id=16인 데이터를 쿼리하고 비교해야 합니다. 이는 4개를 의미합니다. 디스크가 통과합니다. 쿼리 성능은 AVL 트리와 동일한 것 같습니다.
그러나 디스크 IO가 데이터 1개를 읽는 데 소요되는 시간이 기본적으로 데이터 100개를 읽는 시간과 동일하다는 점을 고려하면 최적화 아이디어는 다음과 같이 변경될 수 있습니다. 하나의 디스크 IO에서 가능합니다. 이는 트리의 구조에 직접적으로 반영되는데, 즉 각 노드가 저장할 수 있는 키를 적절하게 늘릴 수 있다.
단일 노드에 제한된 키 수를 6개로 설정하면 7개의 데이터를 저장하는 B-트리의 경우 id=7인 데이터를 쿼리하는 데 필요한 디스크 IO는 2배입니다.
16개의 데이터를 저장하는 B-트리에는 id=7인 데이터를 쿼리하려면 2개의 디스크 IO가 필요합니다. AVL 트리에 비해 디스크 IO 수가 절반으로 줄어듭니다.

그래서 데이터베이스 인덱스 데이터 구조 선택 측면에서 B-tree는 매우 좋은 선택입니다. 정리하자면, B-트리를 데이터베이스 인덱스로 사용할 경우 다음과 같은 장점이 있습니다.
B트리와 B+트리의 차이점은 무엇인가요?
첫 번째, B 트리는 하나의 노드에 데이터를 저장하고, B+ 트리는 인덱스(주소)를 저장하므로 B 트리의 한 노드는 많은 데이터를 저장할 수 없지만 B+ 트리의 한 노드는 많은 인덱스를 저장할 수 있습니다. B+ 트리 리프 노드는 모든 데이터를 저장합니다.
둘째, B+ 트리의 리프 노드는 범위 검색을 용이하게 하기 위해 데이터 단계의 연결 리스트를 사용하여 직렬로 연결됩니다.

B 트리와 B+ 트리를 비교해보면 B+ 트리 노드는 단일 노드의 저장 용량이 제한되어 있을 때 많은 수의 인덱스를 저장할 수도 있음을 알 수 있습니다. 인덱스 전체를 B+로 만듭니다. 트리 높이가 줄어들어 디스크 IO가 줄어듭니다. 둘째, B+ 트리의 리프 노드는 실제 데이터가 저장되는 곳입니다. 리프 노드는 연결 리스트를 사용하여 연결됩니다. 연결 리스트 자체가 정렬되어 있어 데이터 범위에서 검색할 때 더 효율적입니다. 따라서 MySQL의 인덱스는 B+ 트리를 사용합니다. B+ 트리는 검색 효율성과 범위 검색에서 매우 좋은 성능을 발휘합니다.
Mysql 기반 데이터 엔진은 플러그인 형태로 설계되었습니다. 가장 일반적인 엔진은 Innodb 엔진과 Myisam 엔진입니다. MySQL 데이터 테이블의 기본 엔진입니다. 방금 B+ 트리가 Mysql 인덱스의 데이터 구조로 매우 적합하다고 분석했지만, 데이터와 인덱스를 구성하는 방법에도 약간의 설계가 필요했습니다. 서로 다른 디자인 개념으로 인해 각각 고유한 성능을 나타내는 Innodb와 Myisam이 등장하게 되었습니다.
MyISAM 데이터 조회 성능은 우수하지만 트랜잭션 처리를 지원하지 않습니다. Innodb의 가장 큰 특징은 ACID 호환 트랜잭션 기능을 지원하고, 행 수준 잠금을 지원한다는 점입니다. Mysql이 테이블을 생성할 때 엔진을 지정할 수 있습니다. 예를 들어 다음 예에서는 Myisam과 Innodb가 각각 user 테이블과 user2 테이블에 대한 데이터 엔진으로 지정됩니다.

이 두 명령을 실행하면 다음 파일이 시스템에 나타나 두 엔진의 데이터와 인덱스가 다르게 구성되었음을 나타냅니다.
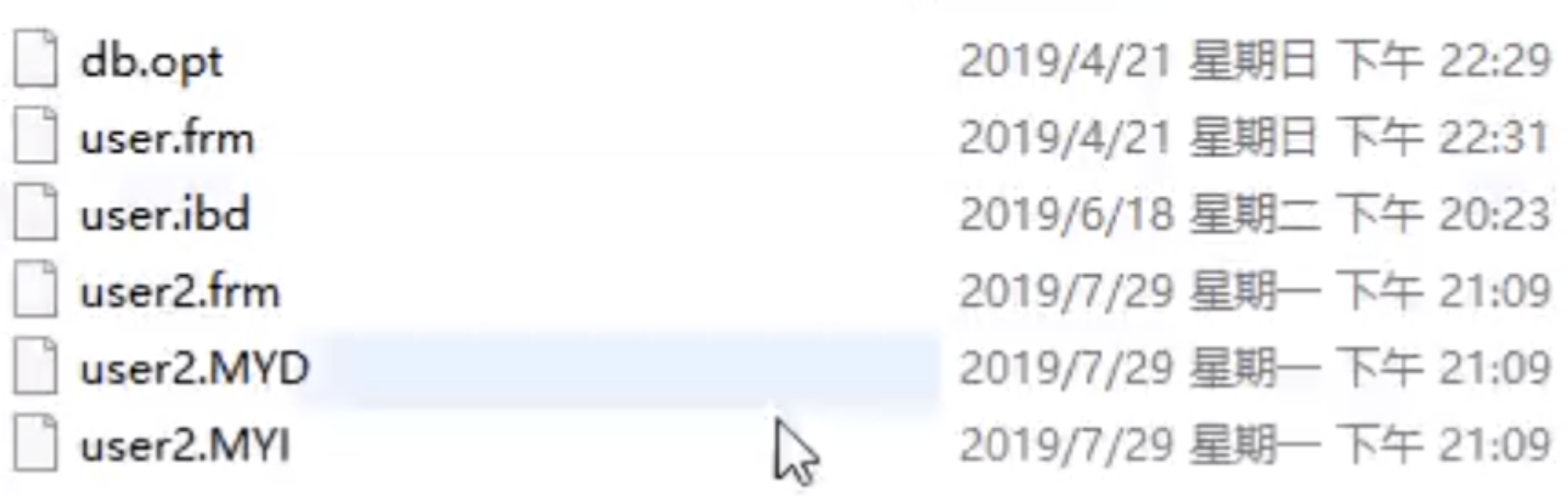
테이블 생성 후 Innodb에서 생성된 파일은 다음과 같습니다.
Myisam은 이후에 생성됩니다. 테이블 생성 파일에는
심사 생성된 파일에서 두 엔진의 기본 데이터와 인덱스는 서로 다른 방식으로 구성됩니다. MyISAM 엔진은 데이터와 인덱스를 분리하고 각 사람은 하나의 파일을 가지며 이를 Innodb 엔진이 넣습니다. 데이터와 인덱스를 동일한 파일에 포함하는 것을 클러스터형 인덱스 모드라고 합니다. 다음에서는 이 두 엔진이 B+ 트리 데이터 구조를 사용하여 기본 구현의 관점에서 엔진 구현을 구성하는 방법을 분석합니다.
MyISAM 엔진의 기본 구현(비클러스터형 인덱스 방법)
MyISAM은 비클러스터형 인덱스 방법을 사용합니다. 즉, 데이터와 인덱스가 두 개의 서로 다른 파일에 있습니다. MyISAM은 테이블을 생성할 때 기본 키를 KEY로 사용하여 기본 인덱스 B+ 트리를 생성합니다. 트리의 리프 노드는 해당 데이터의 물리적 주소를 저장합니다. 이 물리적 주소를 얻은 후에는 MyISAM 데이터 파일에서 특정 데이터 레코드를 직접 찾을 수 있습니다.
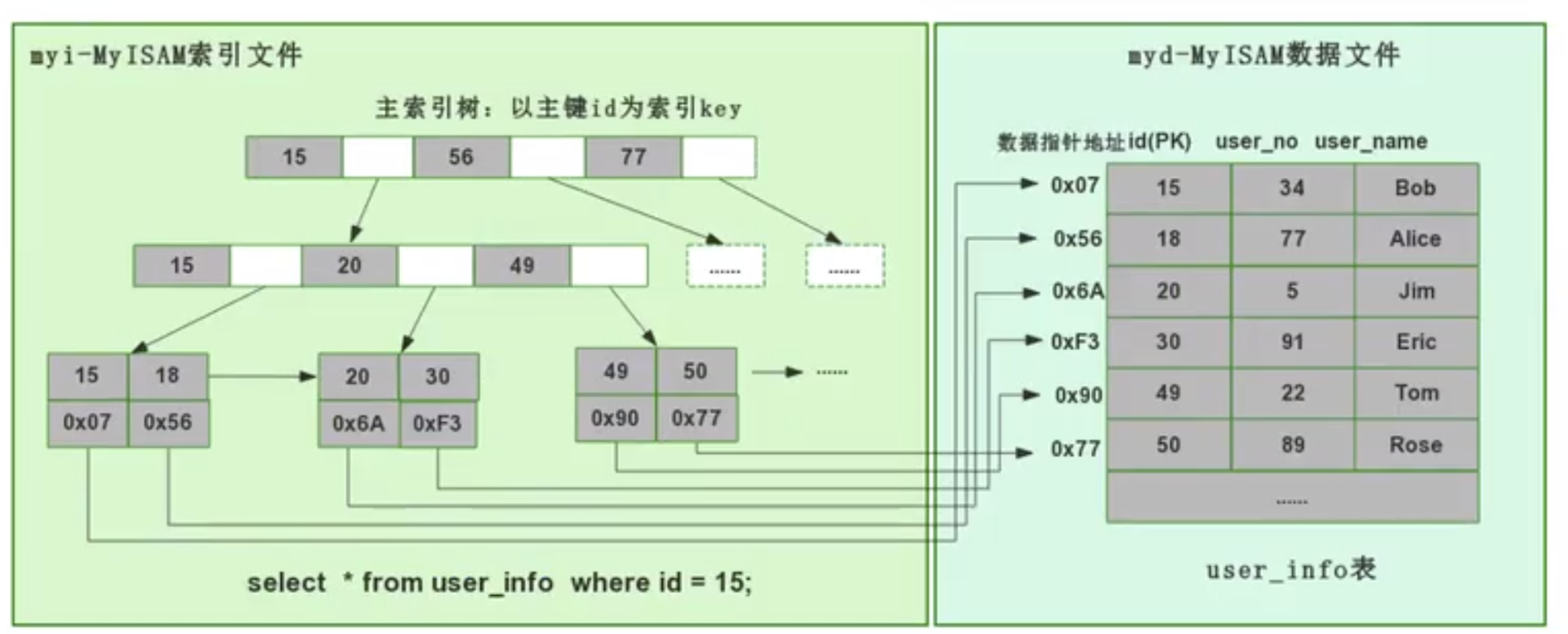
필드에 인덱스를 추가하면 해당 필드에 대한 인덱스 트리도 생성됩니다. 해당 필드에 대한 인덱스 트리의 리프 노드에도 해당 데이터의 물리적 주소가 기록됩니다. 그런 다음 이 물리적 주소를 사용하여 데이터 파일에서 특정 데이터 레코드를 찾습니다.
Innodb 엔진의 기본 구현(클러스터형 인덱스 방식)
InnoDB는 클러스터형 인덱스 방식이므로 데이터와 인덱스가 동일한 파일에 저장됩니다. 먼저 InnoDB는 아래 그림과 같이 기본 키 ID를 KEY로 기준으로 인덱스 B+ 트리를 생성하고 B+ 트리의 리프 노드에는 예를 들어 명령문을 실행할 때 기본 키 ID에 해당하는 데이터가 저장됩니다. select * from user_info where id=15, InnoDB 기본 키 ID 인덱스 B+ 트리를 쿼리하고 해당 user_name='Bob'을 찾습니다.
이것은 InnoDB가 테이블을 생성할 때 기본 키 ID 인덱스 트리를 자동으로 구축하는 경우입니다. 이것이 바로 Mysql이 테이블을 생성할 때 기본 키를 지정하도록 요구하는 이유입니다. 테이블의 필드에 인덱스를 추가할 때 InnoDB는 어떻게 인덱스 트리를 구축합니까? 예를 들어 user_name 필드에 인덱스를 추가하려는 경우 InnoDB는 user_name 인덱스 B+ 트리를 생성합니다. user_name의 KEY는 노드에 저장되고 리프 노드에 저장된 데이터는 기본 키 KEY입니다. 나뭇잎은 기본 키 KEY를 저장합니다! 기본 키 KEY를 얻은 후 InnoDB는 기본 키 인덱스 트리로 이동하여 user_name 인덱스 트리에서 방금 찾은 기본 키 KEY를 기반으로 해당 데이터를 찾습니다.
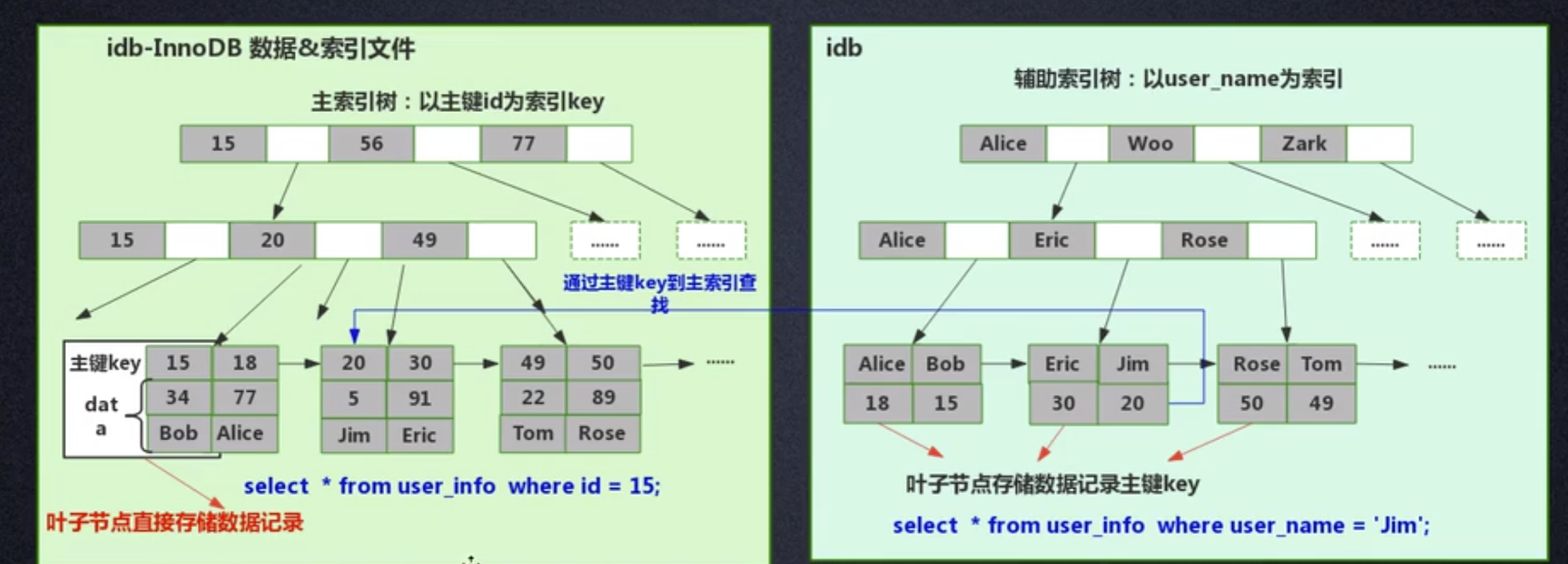
질문은 왜 InnoDB는 기본키 인덱스 트리의 리프 노드에만 특정 데이터를 저장하는데, 다른 인덱스 트리들은 특정 데이터를 저장하지 않고, 기본키를 먼저 찾을 필요가 없느냐는 것입니다. , 그리고 기본 키 인덱스 트리에서 해당 데이터를 찾아보면 어떨까요?
InnoDB는 저장 공간을 절약해야 하기 때문에 실제로는 매우 간단합니다. 테이블에 많은 인덱스가 있을 수 있습니다. InnoDB는 각 인덱스 필드에 대해 인덱스 트리를 생성합니다. 각 필드의 인덱스 트리에 특정 데이터가 저장되면 이 테이블의 인덱스 데이터 파일이 매우 커집니다(데이터가 극도로 중복됨). 디스크 공간 절약의 관점에서 보면 실제로 각 필드 인덱스 트리에 특정 데이터를 저장할 필요가 없습니다. 겉보기에 "불필요한" 단계를 통해 쿼리 성능을 저하시키는 대신 막대한 디스크 공간이 절약되는 것은 매우 가치 있는 일입니다.
InnoDB와 MyISAM의 기능을 비교할 때 MyISAM이 쿼리 성능이 더 좋다고 언급되었습니다. 그 이유는 위의 인덱스 파일 데이터 파일의 설계에서 알 수 있습니다. MyISAM은 물리적 주소를 직접 찾은 후 데이터 레코드를 직접 찾을 수 있습니다. 그러나 InnoDB는 리프 노드를 쿼리한 후 특정 데이터를 찾기 위해 기본 키 인덱스 트리를 다시 쿼리해야 합니다. 이는 MyISAM이 한 단계로 데이터를 찾을 수 있지만 InnoDB는 두 단계가 필요하다는 것을 의미합니다. 물론 MyISAM의 쿼리 성능이 더 높습니다.
이 기사에서는 먼저 Mysql의 기본 인덱스 구현으로 어떤 데이터 구조가 더 적합한지 논의한 다음 MySQL의 두 가지 클래식 데이터 엔진인 MyISAM 및 InnoDB의 기본 구현을 소개합니다. 마지막으로, 테이블의 필드를 인덱싱해야 하는 경우를 요약해 보겠습니다.
【관련 추천: mysql 비디오 튜토리얼】
위 내용은 mysql 인덱스가 빠른 이유는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



