

데이터 엔지니어링을 위한 30가지 필수 Python 패키지

Python은 시작하기 가장 쉬운 프로그래밍 언어라고 할 수 있습니다. numpy 및 scipy와 같은 기본 패키지의 도움으로 Python은 현재 데이터 처리 및 기계 학습에 가장 적합한 언어라고 할 수 있습니다. 기술 개발을 지원하는 대규모 커뮤니티를 보유한 Python의 도움으로 데이터 과학자의 작업을 지원하기 위해 두 가지 다양한 Python 패키지가 개발되었습니다.

이 기사에서는 다양한 측면에서 데이터 워크플로를 구축하는 데 도움이 될 수 있는 매우 독특하고 사용하기 쉬운 Python 패키지를 소개합니다.
1. Knockknock
Knockknock은 기계 학습 모델 훈련이 종료되거나 충돌할 때 알려주는 간단한 Python 패키지입니다. 이메일, Slack, Microsoft Teams 등과 같은 여러 채널을 통해 알림을 받을 수 있습니다.
패키지를 설치하기 위해 다음 코드를 사용합니다.
pip install knockknock
예를 들어 다음 코드를 사용하여 기계 학습 모델링 훈련 상태를 지정된 이메일 주소로 알릴 수 있습니다.
from knockknock import email_senderfrom sklearn.linear_model import LinearRegressionimport numpy as np@email_sender(recipient_emails=["<your_email@address.com>", "<your_second_email@address.com>"], sender_email="<sender_email@gmail.com>")def train_linear_model(your_nicest_parameters):x = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])y = np.dot(x, np.array([1, 2])) + 3 regression = LinearRegression().fit(x, y)return regression.score(x, y)
이렇게 하면 문제가 발생하거나 기능이 완료될 때 알림을 받을 수 있습니다.
2. tqdm
반복이나 반복이 필요할 때, 진행률 표시줄을 표시해야 한다면 tqdm이 필요할까요? 이 패키지는 노트북이나 명령 프롬프트에 간단한 진행률 표시기를 제공합니다.
패키지 설치부터 시작해 보겠습니다.
pip install tqdm
그런 다음 다음 코드를 사용하여 루프 중에 진행률 표시줄을 표시할 수 있습니다.
from tqdm import tqdmq = 0for i in tqdm(range(10000000)):q = i +1
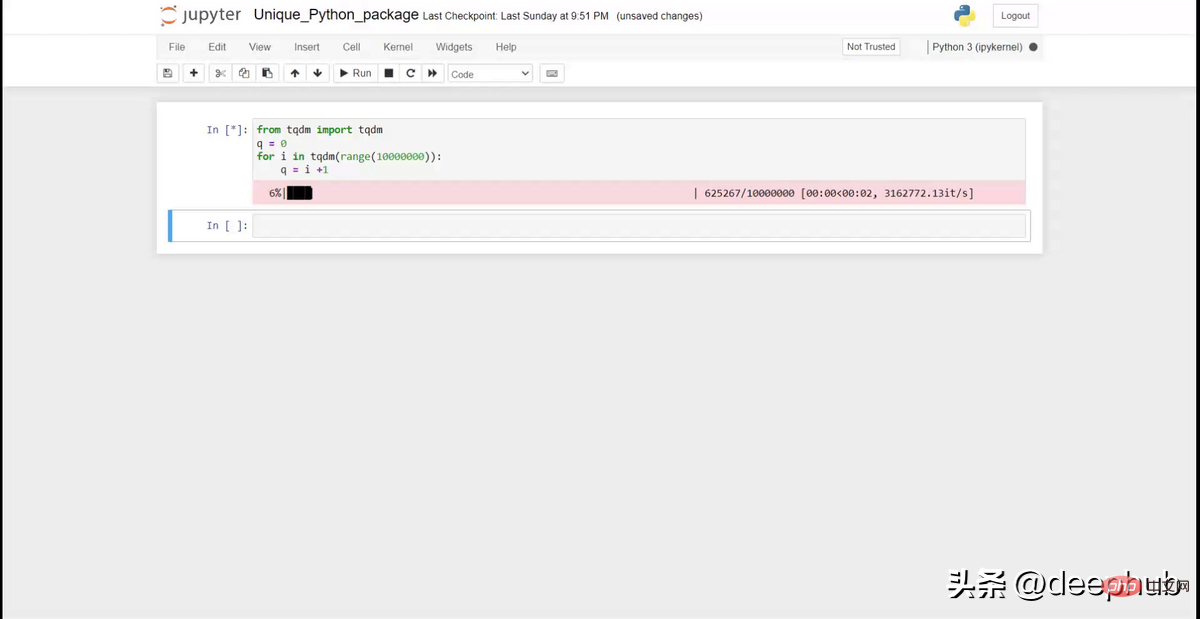
위의 gifg처럼 노트북에 멋진 진행률 표시줄을 표시할 수 있습니다. 반복이 복잡하고 진행 상황을 추적하려는 경우에 유용합니다.
3. Pandas-log
Panda -log는 .query, .drop, .merge 등 Panda의 기본 작업에 대한 피드백을 제공할 수 있습니다. R의 Tidyverse를 기반으로 하며, 데이터 분석의 모든 단계를 이해하는 데 사용할 수 있습니다.
패키지 설치
pip install pandas-log
패키지 설치 후 아래 예시를 살펴보세요.
import pandas as pdimport numpy as npimport pandas_logdf = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],"toy": [np.nan, 'Batmobile', 'Bullwhip'],"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})그럼 다음 코드를 사용하여 간단한 팬더 작업 기록을 만들어 보겠습니다.
with pandas_log.enable():res = (df.drop("born", axis = 1).groupby('name'))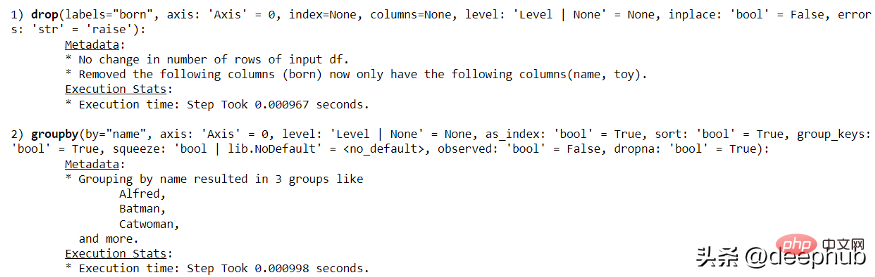
pandas-log를 통해 모든 실행 정보를 얻을 수 있습니다.
4. Emoji
이름에서 알 수 있듯이 Emoji는 이모티콘 텍스트 구문 분석을 지원하는 Python 패키지입니다. 일반적으로 Python에서는 이모티콘을 처리하기가 어렵지만 Emoji 패키지는 변환에 도움이 될 수 있습니다.
Emoji 패키지를 설치하려면 다음 코드를 사용하세요.
pip install emoji
아래 코드를 보세요.
import emojiprint(emoji.emojize('Python is :thumbs_up:'))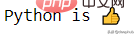
이 패키지를 사용하면 쉽게 이모티콘을 출력할 수 있습니다.
5. TheFuzz
TheFuzz는 Levenshtein 거리를 사용하여 텍스트를 일치시켜 유사성을 계산합니다.
pip install thefuzz
다음 코드는 유사성 텍스트 일치를 위해 TheFuzz를 사용하는 방법을 설명합니다.
from thefuzz import fuzz, process#Testing the score between two sentencesfuzz.ratio("Test the word", "test the Word!")
TheFuzz는 여러 단어의 유사성 점수를 동시에 추출할 수도 있습니다.
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]process.extract("new york jets", choices, limit=2)
TheFuzz는 모든 텍스트 데이터 유사성 감지에 적합하며 이 작업은 nlp에서 매우 중요합니다.
6. Numerizer
Numerizer는 작성된 숫자 텍스트를 해당 정수 또는 부동 소수점 숫자로 변환할 수 있습니다.
pip install numerizer
그럼 몇 가지 입력을 사용해 변환해 보겠습니다.
from numerizer import numerizenumerize('forty two')
다른 글쓰기 스타일을 사용해도 괜찮습니다.
numerize('forty-two')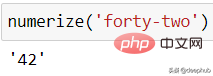
numerize('nine and three quarters')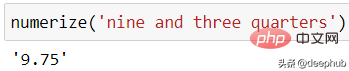
입력이 숫자 표현식이 아닌 경우 유지됩니다.
numerize('maybe around nine and three quarters')
7、PyAutoGUI
PyAutoGUI 可以自动控制鼠标和键盘。
pip install pyautogui
然后我们可以使用以下代码测试。
import pyautoguipyautogui.moveTo(10, 15)pyautogui.click()pyautogui.doubleClick()pyautogui.press('enter')上面的代码会将鼠标移动到某个位置并单击鼠标。 当需要重复操作(例如下载文件或收集数据)时,非常有用。
8、Weightedcalcs
Weightedcalcs 用于统计计算。 用法从简单的统计数据(例如加权平均值、中位数和标准变化)到加权计数和分布等。
pip install weightedcalcs
使用可用数据计算加权分布。
import seaborn as snsdf = sns.load_dataset('mpg')import weightedcalcs as wccalc = wc.Calculator("mpg")然后我们通过传递数据集并计算预期变量来进行加权计算。
calc.distribution(df, "origin")

9、scikit-posthocs
scikit-posthocs 是一个用于“事后”测试分析的 python 包,通常用于统计分析中的成对比较。 该软件包提供了简单的类似 scikit-learn API 来进行分析。
pip install scikit-posthocs
然后让我们从简单的数据集开始,进行 ANOVA 测试。
import statsmodels.api as saimport statsmodels.formula.api as sfaimport scikit_posthocs as spdf = sa.datasets.get_rdataset('iris').datadf.columns = df.columns.str.replace('.', '')lm = sfa.ols('SepalWidth ~ C(Species)', data=df).fit()anova = sa.stats.anova_lm(lm)print(anova)
获得了 ANOVA 测试结果,但不确定哪个变量类对结果的影响最大,可以使用以下代码进行原因的查看。
sp.posthoc_ttest(df, val_col='SepalWidth', group_col='Species', p_adjust='holm')

使用 scikit-posthoc,我们简化了事后测试的成对分析过程并获得了 P 值
10、Cerberus
Cerberus 是一个用于数据验证的轻量级 python 包。
pip install cerberus
Cerberus 的基本用法是验证类的结构。
from cerberus import Validatorschema = {'name': {'type': 'string'}, 'gender':{'type': 'string'}, 'age':{'type':'integer'}}v = Validator(schema)定义好需要验证的结构后,可以对实例进行验证。
document = {'name': 'john doe', 'gender':'male', 'age': 15}v.validate(document)
如果匹配,则 Validator 类将输出True 。 这样我们可以确保数据结构是正确的。
11、ppscore
ppscore 用于计算与目标变量相关的变量的预测能力。 该包计算可以检测两个变量之间的线性或非线性关系的分数。 分数范围从 0(无预测能力)到 1(完美预测能力)。
pip install ppscore
使用 ppscore 包根据目标计算分数。
import seaborn as snsimport ppscore as ppsdf = sns.load_dataset('mpg')pps.predictors(df, 'mpg')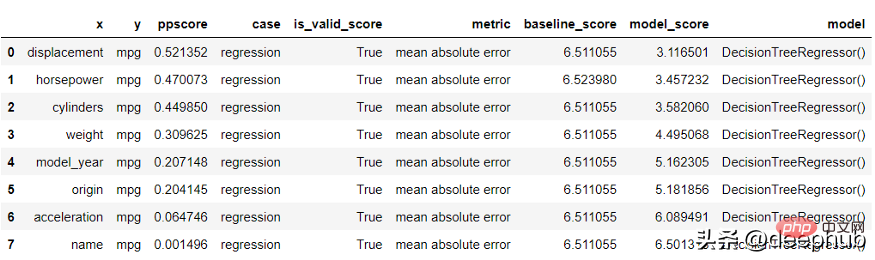
结果进行了排序。 排名越低变量对目标的预测能力越低。
12、Maya
Maya 用于尽可能轻松地解析 DateTime 数据。
pip install maya
然后我们可以使用以下代码轻松获得当前日期。
import mayanow = maya.now()print(now)
还可以为明天日期。
tomorrow = maya.when('tomorrow')tomorrow.datetime()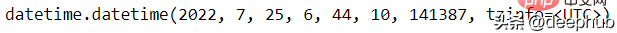
13、Pendulum
Pendulum 是另一个涉及 DateTime 数据的 python 包。 它用于简化任何 DateTime 分析过程。
pip install pendulum
我们可以对实践进行任何的操作。
import pendulumnow = pendulum.now("Europe/Berlin")now.in_timezone("Asia/Tokyo")now.to_iso8601_string()now.add(days=2)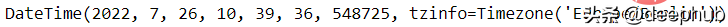
14、category_encoders
category_encoders 是一个用于类别数据编码(转换为数值数据)的python包。 该包是各种编码方法的集合,我们可以根据需要将其应用于各种分类数据。
pip install category_encoders
可以使用以下示例应用转换。
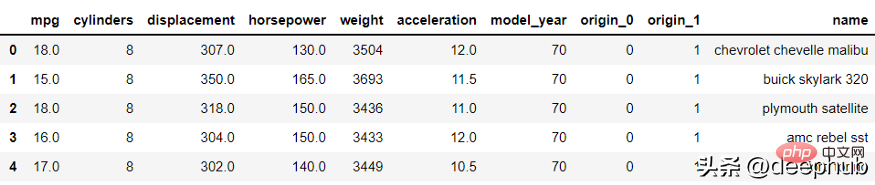
from category_encoders import BinaryEncoderimport pandas as pdenc = BinaryEncoder(cols=['origin']).fit(df)numeric_dataset = enc.transform(df)numeric_dataset.head()
15、scikit-multilearn
scikit-multilearn 可以用于特定于多类分类模型的机器学习模型。 该软件包提供 API 用于训练机器学习模型以预测具有两个以上类别目标的数据集。
pip install scikit-multilearn
利用样本数据集进行多标签KNN来训练分类器并度量性能指标。
from skmultilearn.dataset import load_datasetfrom skmultilearn.adapt import MLkNNimport sklearn.metrics as metricsX_train, y_train, feature_names, label_names = load_dataset('emotions', 'train')X_test, y_test, _, _ = load_dataset('emotions', 'test')classifier = MLkNN(k=3)prediction = classifier.fit(X_train, y_train).predict(X_test)metrics.hamming_loss(y_test, prediction)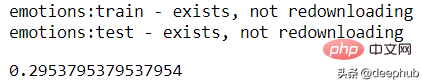
16、Multiset
Multiset类似于内置的set函数,但该包允许相同的字符多次出现。
pip install multiset
可以使用下面的代码来使用 Multiset 函数。
from multiset import Multisetset1 = Multiset('aab')set1
17、Jazzit
Jazzit 可以在我们的代码出错或等待代码运行时播放音乐。
pip install jazzit
使用以下代码在错误情况下尝试示例音乐。
from jazzit import error_track@error_track("curb_your_enthusiasm.mp3", wait=5)def run():for num in reversed(range(10)):print(10/num)这个包虽然没什么用,但是它的功能是不是很有趣,哈
18、handcalcs
handcalcs 用于简化notebook中的数学公式过程。 它将任何数学函数转换为其方程形式。
pip install handcalcs
使用以下代码来测试 handcalcs 包。 使用 %%render 魔术命令来渲染 Latex 。
import handcalcs.renderfrom math import sqrt
%%rendera = 4b = 6c = sqrt(3*a + b/7)
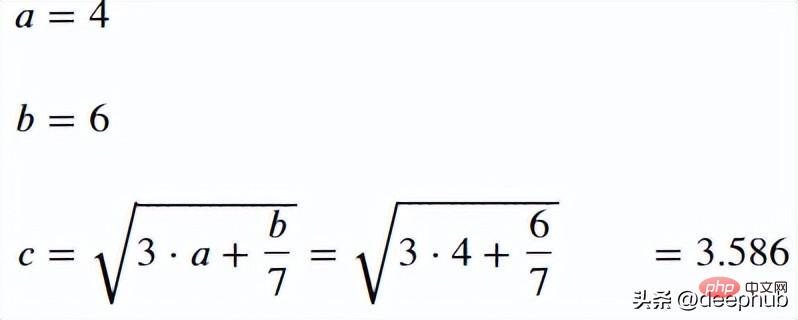
19、NeatText
NeatText 可简化文本清理和预处理过程。 它对任何 NLP 项目和文本机器学习项目数据都很有用。
pip install neattext
使用下面的代码,生成测试数据
import neattext as nt mytext = "This is the word sample but ,our WEBSITE is https://exaempleeele.com ✨."docx = nt.TextFrame(text=mytext)
TextFrame 用于启动 NeatText 类然后可以使用各种函数来查看和清理数据。
docx.describe()
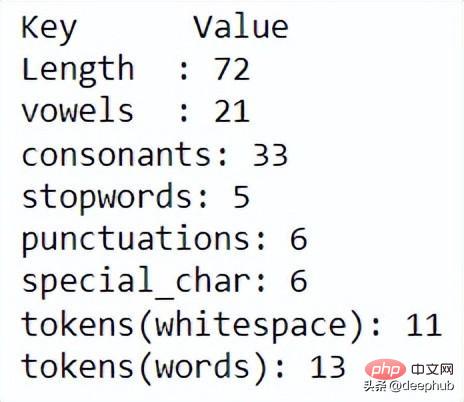
使用 describe 函数,可以显示每个文本统计信息。进一步清理数据,可以使用以下代码。
docx.normalize()
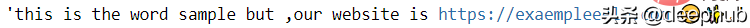
20、Combo
Combo 是一个用于机器学习模型和分数组合的 python 包。 该软件包提供了一个工具箱,允许将各种机器学习模型训练成一个模型。 也就是可以对模型进行整合。
pip install combo
使用来自 scikit-learn 的乳腺癌数据集和来自 scikit-learn 的各种分类模型来创建机器学习组合。
from sklearn.tree import DecisionTreeClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfrom combo.models.classifier_stacking import Stackingfrom combo.utils.data import evaluate_print
接下来,看一下用于预测目标的单个分类器。
# Define data file and read X and yrandom_state = 42X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,random_state=random_state)# initialize a group of clfsclassifiers = [DecisionTreeClassifier(random_state=random_state),LogisticRegression(random_state=random_state),KNeighborsClassifier(),RandomForestClassifier(random_state=random_state),GradientBoostingClassifier(random_state=random_state)]clf_names = ['DT', 'LR', 'KNN', 'RF', 'GBDT']for i, clf in enumerate(classifiers):clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print(clf_names[i] + ' | ', y_test, y_test_predict)print()

使用 Combo 包的 Stacking 模型。
clf = Stacking(classifiers, n_folds=4, shuffle_data=False,keep_original=True, use_proba=False,random_state=random_state)clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print('Stacking | ', y_test, y_test_predict)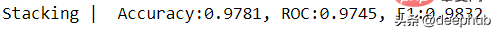
21、PyAztro
你是否需要星座数据或只是对今天的运气感到好奇? 可以使用 PyAztro 来获得这些信息! 这个包有幸运数字、幸运标志、心情等等。 这是我们人工智能算命的基础数据,哈
pip install pyaztro
使用以下代码访问今天的星座信息。
import pyaztropyaztro.Aztro(sign='gemini').description
22、Faker
Faker 可用于简化生成合成数据。 许多开发人员使用这个包来创建测试的数据。
pip install Faker
要使用 Faker 包生成合成数据
from faker import Fakerfake = Faker()
生成名字
fake.name()

每次从 Faker 类获取 .name 属性时,Faker 都会随机生成数据。
23、Fairlearn
Fairlearn 用于评估和减轻机器学习模型中的不公平性。 该软件包提供了许多查看偏差所必需的 API。
pip install fairlearn
然后可以使用 Fairlearn 的数据集来查看模型中有多少偏差。
from fairlearn.metrics import MetricFrame, selection_ratefrom fairlearn.datasets import fetch_adultdata = fetch_adult(as_frame=True)X = data.datay_true = (data.target == '>50K') * 1sex = X['sex']selection_rates = MetricFrame(metrics=selection_rate,y_true=y_true,y_pred=y_true,sensitive_features=sex)fig = selection_rates.by_group.plot.bar(legend=False, rot=0,title='Fraction earning over $50,000')
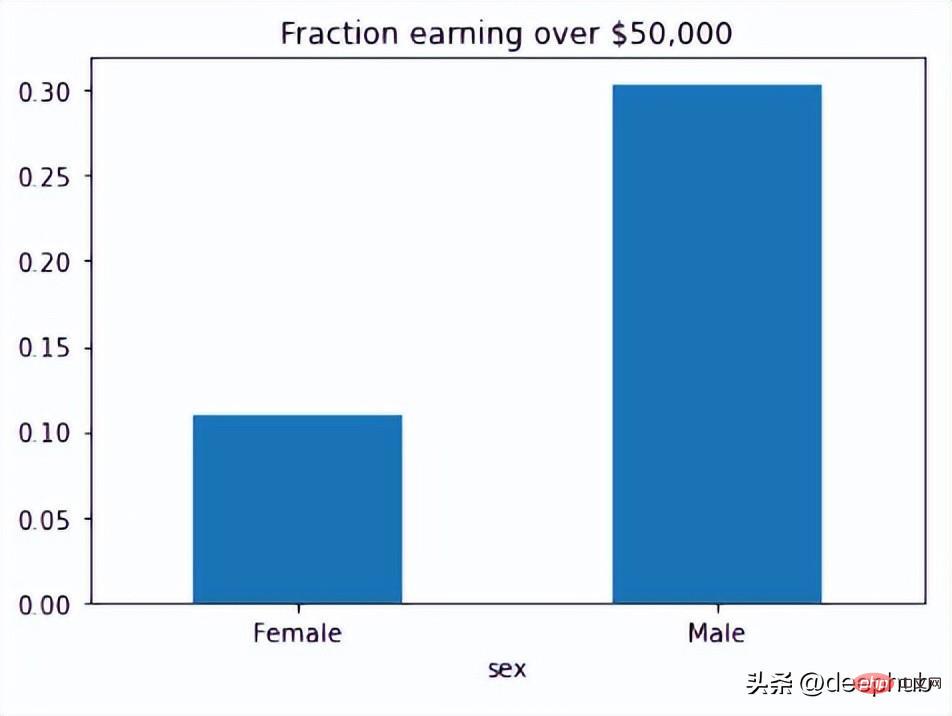
Fairlearn API 有一个 selection_rate 函数,可以使用它来检测组模型预测之间的分数差异,以便我们可以看到结果的偏差。
24、tiobeindexpy
tiobeindexpy 用于获取 TIOBE 索引数据。 TIOBE 指数是一个编程排名数据,对于开发人员来说是非常重要的因为我们不想错过编程世界的下一件大事。
pip install tiobeindexpy
可以通过以下代码获得当月前 20 名的编程语言排名。
from tiobeindexpy import tiobeindexpy as tbdf = tb.top_20()

25、pytrends
pytrends 可以使用 Google API 获取关键字趋势数据。如果想要了解当前的网络趋势或与我们的关键字相关的趋势时,该软件包非常有用。这个需要访问google,所以你懂的。
pip install pytrends
假设我想知道与关键字“Present Gift”相关的当前趋势,
from pytrends.request import TrendReqimport pandas as pdpytrend = TrendReq()keywords = pytrend.suggestions(keyword='Present Gift')df = pd.DataFrame(keywords)df
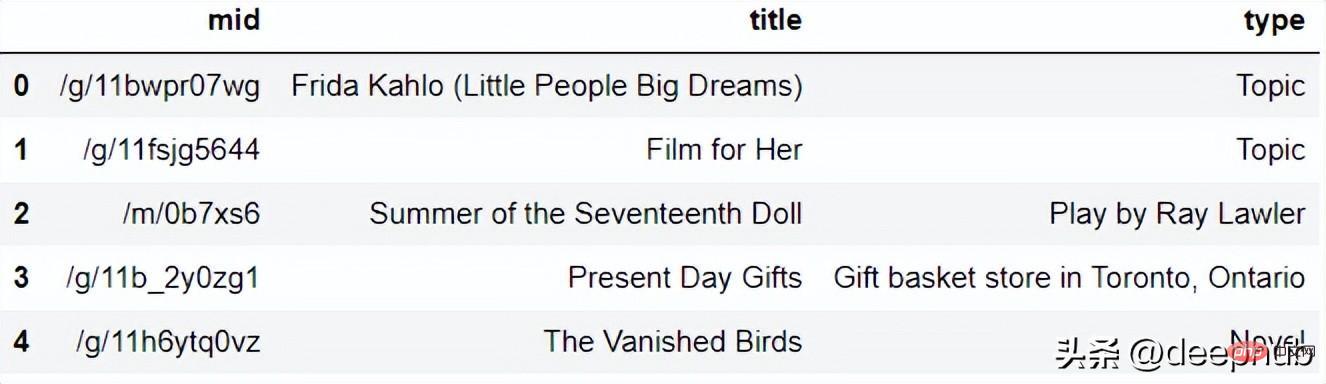
该包将返回与关键字相关的前 5 个趋势。
26、visions
visions 是一个用于语义数据分析的 python 包。 该包可以检测数据类型并推断列的数据应该是什么。
pip install visions
可以使用以下代码检测数据中的列数据类型。 这里使用 seaborn 的 Titanic 数据集。
import seaborn as snsfrom visions.functional import detect_type, infer_typefrom visions.typesets import CompleteSetdf = sns.load_dataset('titanic')typeset = CompleteSet()converting everything to stringsprint(detect_type(df, typeset))
27、Schedule
Schedule 可以为任何代码创建作业调度功能
pip install schedule
例如,我们想10 秒工作一次:
import scheduleimport timedef job():print("I'm working...")schedule.every(10).seconds.do(job)while True:schedule.run_pending()time.sleep(1)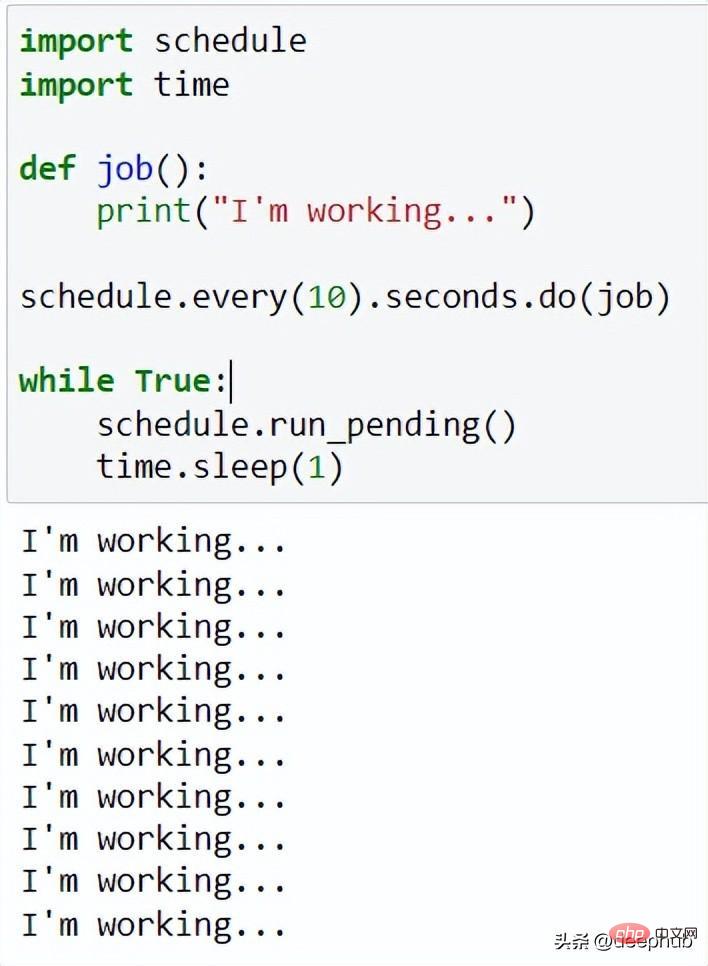
28、autocorrect
autocorrect 是一个用于文本拼写更正的 python 包,可应用于多种语言。 用法很简单,并且对数据清理过程非常有用。
pip install autocorrect
可以使用类似于以下代码进行自动更正。
from autocorrect import Spellerspell = Speller()spell("I'm not sleaspy and tehre is no place I'm giong to.")
29、funcy
funcy 包含用于日常数据分析使用的精美实用功能。 包中的功能太多了,我无法全部展示出来,有兴趣的请查看他的文档。
pip install funcy
这里只展示一个示例函数,用于从可迭代变量中选择一个偶数,如下面的代码所示。
from funcy import select, evenselect(even, {i for i in range (20)})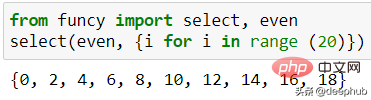
30、IceCream
IceCream 可以使调试过程更容易。该软件包在打印/记录过程中提供了更详细的输出。
pip install icecream
可以使用下面代码
from icecream import icdef some_function(i):i = 4 + (1 * 2)/ 10 return i + 35ic(some_function(121))

也可以用作函数检查器。
def foo():ic()if some_function(12):ic()else:ic()foo()
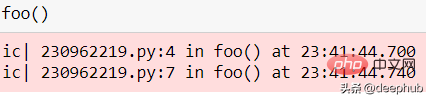
인쇄된 세부 수준은 분석에 이상적입니다.
요약
이 글에는 데이터 작업에 유용한 독특한 Python 패키지 30개가 요약되어 있습니다. 대부분의 소프트웨어 패키지는 사용하기 쉽고 간단하지만 일부는 더 많은 기능을 가지고 있으며 해당 설명서를 더 읽어야 할 수도 있습니다. 관심이 있으시면 pypi 웹 사이트로 이동하여 패키지의 홈페이지와 설명서를 검색하고 보십시오. 이 기사가 당신에게 도움이 되기를 바랍니다.
위 내용은 데이터 엔지니어링을 위한 30가지 필수 Python 패키지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7554
7554
 15
1382
52
83
11
59
19
24
96
15
1382
52
83
11
59
19
24
96

 HTML : 프로그래밍 언어입니까 아니면 다른 것입니까?
Apr 15, 2025 am 12:13 AM
HTML : 프로그래밍 언어입니까 아니면 다른 것입니까?
Apr 15, 2025 am 12:13 AM
Htmlisnotaprogramminglanguage; itisamarkuplanguage.1) htmlstructuresandformatswebcontentusingtags.2) itworksporstylingandjavaScriptOfforIncincivity, WebDevelopment 향상.
 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 PHP : 서버 측 스크립팅 언어 소개
Apr 16, 2025 am 12:18 AM
PHP : 서버 측 스크립팅 언어 소개
Apr 16, 2025 am 12:18 AM
PHP는 동적 웹 개발 및 서버 측 응용 프로그램에 사용되는 서버 측 스크립팅 언어입니다. 1.PHP는 편집이 필요하지 않으며 빠른 발전에 적합한 해석 된 언어입니다. 2. PHP 코드는 HTML에 포함되어 웹 페이지를 쉽게 개발할 수 있습니다. 3. PHP는 서버 측 로직을 처리하고 HTML 출력을 생성하며 사용자 상호 작용 및 데이터 처리를 지원합니다. 4. PHP는 데이터베이스와 상호 작용하고 프로세스 양식 제출 및 서버 측 작업을 실행할 수 있습니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
 PHP를 사용하는 이유는 무엇입니까? 설명 된 장점과 혜택
Apr 16, 2025 am 12:16 AM
PHP를 사용하는 이유는 무엇입니까? 설명 된 장점과 혜택
Apr 16, 2025 am 12:16 AM
PHP의 핵심 이점에는 학습 용이성, 강력한 웹 개발 지원, 풍부한 라이브러리 및 프레임 워크, 고성능 및 확장 성, 크로스 플랫폼 호환성 및 비용 효율성이 포함됩니다. 1) 배우고 사용하기 쉽고 초보자에게 적합합니다. 2) 웹 서버와 우수한 통합 및 여러 데이터베이스를 지원합니다. 3) Laravel과 같은 강력한 프레임 워크가 있습니다. 4) 최적화를 통해 고성능을 달성 할 수 있습니다. 5) 여러 운영 체제 지원; 6) 개발 비용을 줄이기위한 오픈 소스.
