
음성 인식은 컴퓨터가 인간의 말을 이해하고 이를 텍스트로 변환할 수 있도록 하는 인공 지능 분야입니다. 이 기술은 Alexa 및 다양한 챗봇 애플리케이션과 같은 장치에 사용됩니다. 우리가 하는 가장 일반적인 일은 음성 전사인데, 이를 전사나 자막으로 변환할 수 있습니다.

wav2vec2, Conformer 및 Hubert와 같은 최첨단 모델의 최근 개발로 음성 인식 분야가 크게 발전했습니다. 이러한 모델은 사람이 레이블을 지정한 데이터 없이 원시 오디오에서 학습하는 기술을 사용하므로 레이블이 지정되지 않은 음성의 대규모 데이터 세트를 효율적으로 사용할 수 있습니다. 또한 학술 지도 데이터 세트에서 사용되는 기존의 1,000시간을 훨씬 넘어 최대 1,000,000시간의 교육 데이터를 사용하도록 확장되었지만, 여러 데이터 세트 및 도메인에 걸쳐 지도 방식으로 사전 교육된 모델이 더 나은 견고성과 일반화를 수행하는 것으로 나타났습니다. 따라서 음성 인식과 같은 작업을 수행하려면 여전히 미세 조정이 필요하므로 잠재력을 최대한 발휘할 수 없습니다. 이 문제를 해결하기 위해 OpenAI는 약한 감독 방법을 활용하는 모델인 Whisper를 개발했습니다.
이 기사에서는 훈련에 사용되는 데이터 세트의 유형과 모델의 훈련 방법 및 Whisper 사용 방법에 대해 설명합니다.
Whisper 모델은 다음 데이터 세트에 있습니다. 96개 언어로 된 117,000시간의 음성과 "모든 언어"에서 영어로의 125,000시간의 번역 데이터를 포함하는 680,000시간의 라벨링된 오디오 데이터 교육. 이 모델은 인간이 생성한 텍스트가 아닌 다른 자동 음성 인식 시스템(ASR)을 통해 생성된 인터넷 생성 텍스트를 활용합니다. 또한 데이터세트에는 YouTube 동영상에서 추출하고 동영상 제목 및 설명의 언어를 기반으로 태그가 지정된 짧은 음성 클립 모음인 VoxLingua107에서 훈련된 언어 감지기가 포함되어 있으며 오탐지를 제거하기 위한 추가 단계도 포함되어 있습니다.
사용된 주요 구조는 인코더-디코더 구조입니다.
리샘플링: 16000Hz
특징 추출 방법: 25ms 창과 10ms 스트라이드를 사용하여 80채널 로그 Mel 스펙트로그램 표현을 계산합니다.
특성 정규화: 입력은 전역적으로 -1과 1 사이로 조정되며 사전 훈련된 데이터세트의 평균은 대략 0입니다.
인코더/디코더: 이 모델의 인코더와 디코더는 트랜스포머를 채택합니다.
인코더는 먼저 GELU 활성화 함수를 사용하여 두 개의 컨벌루션 레이어(필터 너비 3)가 포함된 스템을 사용하여 입력 표현을 처리합니다.
두 번째 컨벌루션 레이어의 스트라이드는 2입니다.
그런 다음 스템 출력에 정현파 위치 임베딩을 추가한 다음 인코더 변압기 블록을 적용합니다.
Transformers는 사전 활성화된 잔여 블록을 사용하고 인코더의 출력은 정규화 레이어를 사용하여 정규화됩니다.

디코더에서는 학습 위치 임베딩 및 바인딩 입력 및 출력 마크 표현이 사용됩니다.
인코더와 디코더의 너비와 트랜스포머 블록 수는 동일합니다.
모델의 크기 조정 속성을 개선하기 위해 다양한 입력 크기에 대해 학습합니다.
FP16, 동적 손실 확장 및 데이터 병렬 처리로 모델을 교육합니다.
AdamW 및 그래디언트 노름 클리핑을 사용하면 첫 번째 2048 업데이트를 준비한 후 선형 학습률이 0으로 감소합니다.
배치 크기 256을 사용하고 220개의 업데이트에 대해 모델을 훈련합니다. 이는 데이터 세트에 대한 2~3개의 정방향 전달에 해당합니다.
모델은 몇 epoch 동안만 훈련되었기 때문에 과적합은 중요한 문제가 아니었고 데이터 증대나 정규화 기술은 사용되지 않았습니다. 대신 일반화와 견고성을 촉진하기 위해 대규모 데이터 세트 내의 다양성에 의존합니다.
Whisper는 이전에 사용된 데이터 세트에서 우수한 정확성을 입증했으며 다른 최첨단 모델에 대해 테스트되었습니다.
Whisper를 다양한 데이터 세트에서 비교한 결과, wav2vec과 비교하여 지금까지 가장 낮은 단어 오류율을 달성했습니다

모델은 timit 데이터세트에서 테스트되지 않았으므로 단어 오류율을 확인하기 위해 여기에서 Whisper를 사용하여 timit 데이터세트를 자체 검증하는 방법, 즉 Whisper를 사용하여 자체 음성 인식 애플리케이션을 구축하는 방법을 보여드리겠습니다.
TIMIT Reading Speech Corpus는 음향 음성 연구와 자동 음성 인식 시스템의 개발 및 평가에 특별히 사용되는 음성 데이터 모음입니다. 여기에는 미국 영어의 8개 주요 방언에서 온 630명의 화자가 녹음된 내용이 포함되어 있으며, 각 화자는 음성적으로 풍부한 10개의 문장을 읽습니다. 코퍼스에는 각 음성에 대한 16비트, 16kHz 음성 파형 파일뿐만 아니라 시간 정렬된 철자법, 발음 기호 및 단어 표기가 포함되어 있습니다. 이 코퍼스는 MIT(매사추세츠 공과대학), SRI International(SRI) 및 Texas Instruments(TI)가 개발했습니다. TIMIT 코퍼스 전사본은 음성 및 방언 범위의 균형을 맞추기 위해 지정된 테스트 및 교육 하위 집합을 사용하여 수동으로 확인되었습니다.
설치:
!pip install git+https://github.com/openai/whisper.git !pip install jiwer !pip install datasets==1.18.3
첫 번째 명령은 속삭임 모델에 필요한 모든 종속성을 설치합니다. jiwer는 텍스트 오류율 패키지를 다운로드하는 데 사용됩니다. 데이터 세트는 Hugface에서 제공됩니다.
라이브러리 가져오기
import whisper from pytube import YouTube from glob import glob import os import pandas as pd from tqdm.notebook import tqdm
timit 데이터 세트 로드
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")영어 데이터와 영어가 아닌 데이터를 필터링해야 하는 필요성을 고려하여 여기에서는 대신 다중 언어 모델을 사용하기로 선택합니다. 영어 디자인 모델을 위해 특별히 제작되었습니다.
하지만 TIMIT 데이터 세트는 순수 영어이기 때문에 동일한 언어 감지 및 인식 프로세스를 적용해야 합니다. 또한 TIMIT 데이터 세트는 훈련 세트와 검증 세트로 나누어져 있어 직접 사용할 수 있습니다.
Whisper를 사용하려면 먼저 다양한 모델의 매개변수, 크기 및 속도를 이해해야 합니다.

Loading model
model = whisper.load_model('tiny')tiny는 위에서 언급한 모델명으로 대체 가능합니다.
언어 감지기를 정의하는 함수
def lan_detector(audio_file):
print('reading the audio file')
audio = whisper.load_audio(audio_file)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
if max(probs, key=probs.get) == 'en':
return True
return False음성을 텍스트로 변환하는 함수
def speech2text(audio_file): text = model.transcribe(audio_file) return text["text"]
위 함수를 다양한 모델 크기에서 실행했을 때, timit training과 test를 통해 얻은 단어 오류율은 다음과 같습니다.
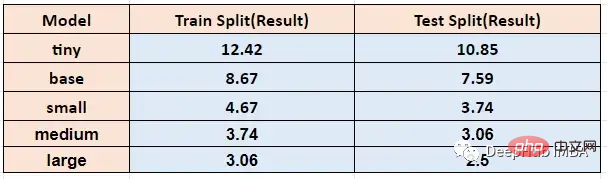
에서 번역됨 다른 음성 인식 모델과 비교하여 Whisper는 음성을 인식할 수 있을 뿐만 아니라 사람의 음성에 있는 구두점과 억양을 해석하고 적절한 구두점을 삽입할 수 있습니다. 아래 테스트에 u2b의 영상을 사용하겠습니다.
여기에는 오디오를 쉽게 다운로드하고 추출하는 데 도움이 되는 pytube 패키지가 필요합니다.
def youtube_audio(link):
youtube_1 = YouTube(link)
videos = youtube_1.streams.filter(only_audio=True)
name = str(link.split('=')[-1])
out_file = videos[0].download(name)
link = name.split('=')[-1]
new_filename = link+".wav"
print(new_filename)
os.rename(out_file, new_filename)
print(name)
return new_filename,linkwav 파일을 얻은 후 위 기능을 적용하여 텍스트를 추출할 수 있습니다.
이 글의 코드는 여기에 있습니다
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view
Whisper로 완료할 수 있는 작업은 많습니다. 직접 시도해 볼 수 있습니다. 이 기사의 코드에.
위 내용은 OpenAI의 Whisper 모델을 이용한 음성인식의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



