

그래디언트 부스팅 알고리즘의 의사결정 과정을 단계별로 시각화

그라디언트 부스팅 알고리즘은 가장 일반적으로 사용되는 앙상블 기계 학습 기술 중 하나입니다. 이 모델은 일련의 약한 결정 트리를 사용하여 강력한 학습자를 구축합니다. 이는 XGBoost 및 LightGBM 모델의 이론적 기반이기도 하므로 이 기사에서는 처음부터 그래디언트 부스팅 모델을 구축하고 이를 시각화하겠습니다.
그라디언트 부스팅 알고리즘 소개
그라디언트 부스팅 알고리즘은 여러 개의 약한 분류기를 구축한 다음 이를 강력한 분류기로 결합하여 모델의 예측 정확도를 향상시키는 앙상블 학습 알고리즘입니다.
그라디언트 부스팅 알고리즘의 원리는 다음 단계로 나눌 수 있습니다.
- 모델 초기화: 일반적으로 초기 분류자로 간단한 모델(예: 의사결정 트리)을 사용할 수 있습니다.
- 손실 함수의 음의 기울기 계산: 각 샘플 포인트에 대해 현재 모델에서 손실 함수의 음의 기울기를 계산합니다. 이는 새 분류기에 현재 모델의 오류를 맞추도록 요청하는 것과 같습니다.
- 새 분류기 학습: 이러한 음의 기울기를 대상 변수로 사용하여 새로운 약한 분류기를 학습합니다. 이 약한 분류기는 의사결정 트리, 선형 모델 등과 같은 모든 분류기가 될 수 있습니다.
- 모델 업데이트: 원래 모델에 새 분류자를 추가하고 가중 평균 또는 기타 방법을 사용하여 결합합니다.
- 반복 반복: 미리 설정된 반복 횟수에 도달하거나 미리 설정된 정확도에 도달할 때까지 위 단계를 반복합니다.
그라디언트 부스팅 알고리즘은 직렬 알고리즘이므로 훈련 속도가 느릴 수 있습니다. 실제 예를 들어 소개하겠습니다.
특성 세트 Xi와 값 Yi가 있고 y를 계산하려고 한다고 가정합니다.

우리는 y

F_m(x)가 y|x에 더 가까워지기를 원하는 모든 단계에서 y의 평균부터 시작합니다.

각 단계에서 우리는 F_m(x)가 주어진 x에 대해 더 나은 근사치가 되기를 원합니다.
먼저 손실 함수를 정의합니다.
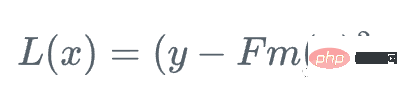
그런 다음 학습자에 대해 손실 함수가 가장 빠르게 감소하는 방향으로 이동합니다. Fm:
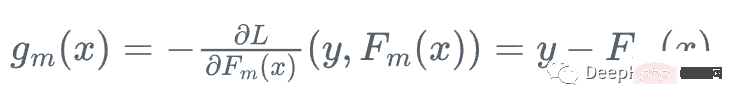
y를 계산할 수 없기 때문입니다. 모든 x에 대해 이 기울기의 정확한 값은 알 수 없지만 훈련 데이터의 각 x_i에 대해 기울기는 단계 m의 잔차와 정확히 같습니다: r_i!
그래서 우리는 약한 회귀 트리 h_m을 사용하여 다음을 수행할 수 있습니다. 잔여 수행 훈련에 대해 그래디언트 함수 g_m을 근사화합니다.
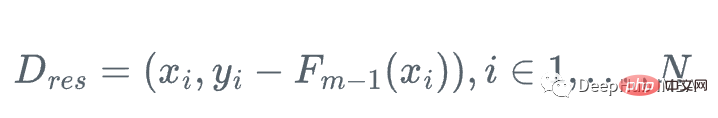
그런 다음 학습자를 업데이트합니다.
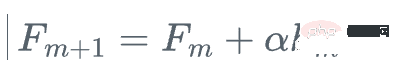
이것은 손실 함수의 실제 그래디언트 g_m을 사용하는 대신에 관련됩니다. 현재 학습자는 현재 학습자 F_{m }을 업데이트하는 대신 약한 회귀 트리 h_m을 사용하여 업데이트합니다.

즉, 다음 단계를 반복합니다.
1. 잔차를 계산합니다.

2 회귀 트리 h_m을 훈련 표본과 잔차(x_i, r_i)에 맞춥니다. 단계 크기 알파 업데이트 모델
 복잡해 보이죠? 프로세스를 시각화하면 매우 명확해집니다. 고전적인 비선형 범주형 데이터
복잡해 보이죠? 프로세스를 시각화하면 매우 명확해집니다. 고전적인 비선형 범주형 데이터
import numpy as np import sklearn.datasets as ds import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from itertools import product,islice import seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16) moon = moonDS[0] color = -1*(moonDS[1]*2-1) df =pd.DataFrame(moon, columns = ['x','y']) df['z'] = color df['f0'] =df.y.mean() df['r0'] = df['z'] - df['f0'] df.head(10)
데이터를 시각화해 보겠습니다.
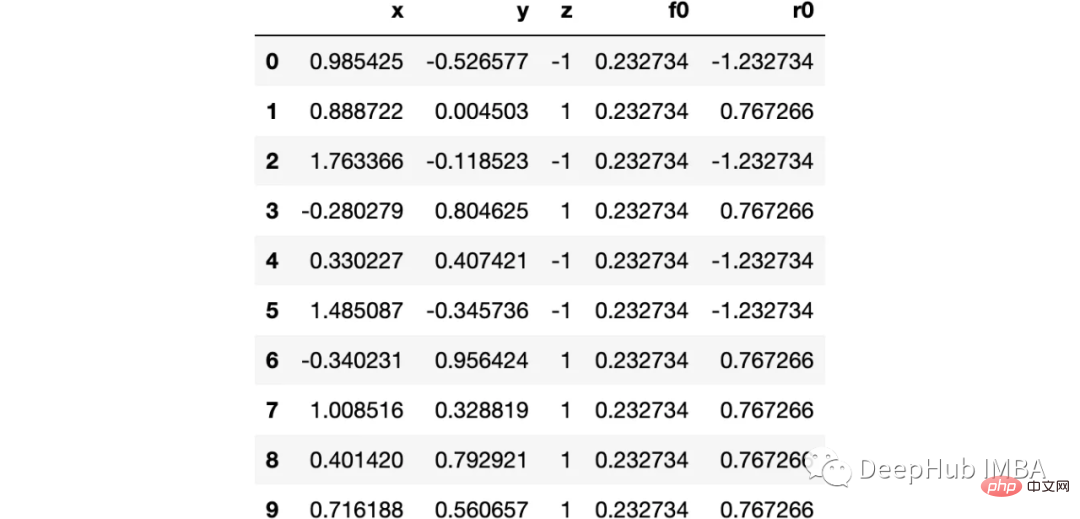
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。
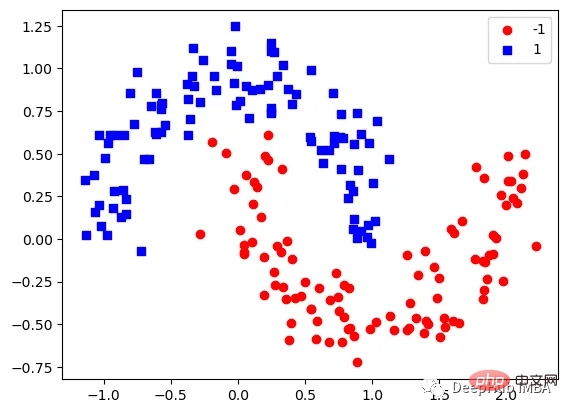
那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):
"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""
clf = tree.DecisionTreeRegressor(max_depth=1)
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
eta = 0.9
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
df[f'r{i}'] = df['z'] - df[f'f{i}']
rmse = (df[f'r{i}']**2).sum()
clfs.append(clf)
rmses.append(rmse)上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策
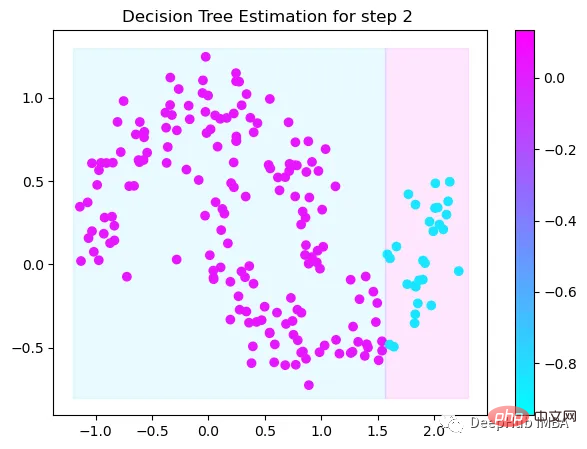
Tree Split for 1 and level 0.5143677890300751
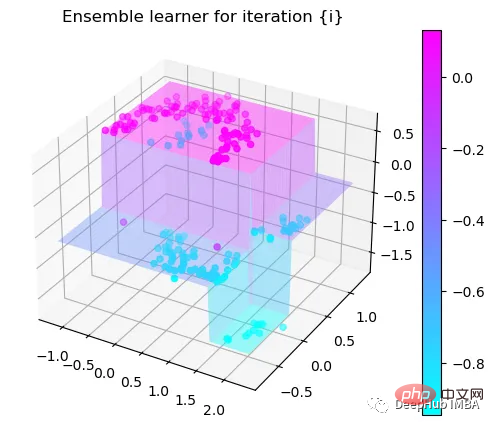
第3次决策
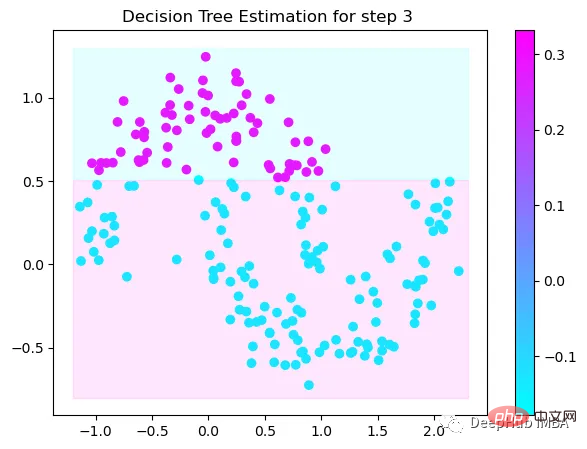
Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://www.php.cn/link/bfc89c3ee67d881255f8b097c4ed2d67
위 내용은 그래디언트 부스팅 알고리즘의 의사결정 과정을 단계별로 시각화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7469
7469
 15
1376
52
77
11
48
19
19
29
15
1376
52
77
11
48
19
19
29

 15가지 추천 오픈 소스 무료 이미지 주석 도구
Mar 28, 2024 pm 01:21 PM
15가지 추천 오픈 소스 무료 이미지 주석 도구
Mar 28, 2024 pm 01:21 PM
이미지 주석은 이미지 콘텐츠에 더 깊은 의미와 설명을 제공하기 위해 이미지에 레이블이나 설명 정보를 연결하는 프로세스입니다. 이 프로세스는 비전 모델을 훈련하여 이미지의 개별 요소를 보다 정확하게 식별하는 데 도움이 되는 기계 학습에 매우 중요합니다. 이미지에 주석을 추가함으로써 컴퓨터는 이미지 뒤의 의미와 맥락을 이해할 수 있으므로 이미지 내용을 이해하고 분석하는 능력이 향상됩니다. 이미지 주석은 컴퓨터 비전, 자연어 처리, 그래프 비전 모델 등 다양한 분야를 포괄하여 차량이 도로의 장애물을 식별하도록 지원하는 등 광범위한 애플리케이션을 보유하고 있습니다. 의료영상인식을 통한 질병진단. 이 기사에서는 주로 더 나은 오픈 소스 및 무료 이미지 주석 도구를 권장합니다. 1.마케센스
 이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
이 기사에서는 SHAP: 기계 학습을 위한 모델 설명을 이해하도록 안내합니다.
Jun 01, 2024 am 10:58 AM
기계 학습 및 데이터 과학 분야에서 모델 해석 가능성은 항상 연구자와 실무자의 초점이었습니다. 딥러닝, 앙상블 방법 등 복잡한 모델이 널리 적용되면서 모델의 의사결정 과정을 이해하는 것이 특히 중요해졌습니다. explainable AI|XAI는 모델의 투명성을 높여 머신러닝 모델에 대한 신뢰와 확신을 구축하는 데 도움이 됩니다. 모델 투명성을 향상시키는 것은 여러 복잡한 모델의 광범위한 사용은 물론 모델을 설명하는 데 사용되는 의사 결정 프로세스와 같은 방법을 통해 달성할 수 있습니다. 이러한 방법에는 기능 중요도 분석, 모델 예측 간격 추정, 로컬 해석 가능성 알고리즘 등이 포함됩니다. 특성 중요도 분석은 모델이 입력 특성에 미치는 영향 정도를 평가하여 모델의 의사결정 과정을 설명할 수 있습니다. 모델 예측 구간 추정
 투명한! 주요 머신러닝 모델의 원리를 심층적으로 분석!
Apr 12, 2024 pm 05:55 PM
투명한! 주요 머신러닝 모델의 원리를 심층적으로 분석!
Apr 12, 2024 pm 05:55 PM
일반인의 관점에서 보면 기계 학습 모델은 입력 데이터를 예측된 출력에 매핑하는 수학적 함수입니다. 보다 구체적으로, 기계 학습 모델은 예측 출력과 실제 레이블 사이의 오류를 최소화하기 위해 훈련 데이터로부터 학습하여 모델 매개변수를 조정하는 수학적 함수입니다. 기계 학습에는 로지스틱 회귀 모델, 의사결정 트리 모델, 지원 벡터 머신 모델 등 다양한 모델이 있습니다. 각 모델에는 적용 가능한 데이터 유형과 문제 유형이 있습니다. 동시에, 서로 다른 모델 간에는 많은 공통점이 있거나 모델 발전을 위한 숨겨진 경로가 있습니다. 연결주의 퍼셉트론을 예로 들면, 퍼셉트론의 은닉층 수를 늘려 심층 신경망으로 변환할 수 있습니다. 퍼셉트론에 커널 함수를 추가하면 SVM으로 변환할 수 있다. 이 하나
 학습 곡선을 통해 과적합과 과소적합 식별
Apr 29, 2024 pm 06:50 PM
학습 곡선을 통해 과적합과 과소적합 식별
Apr 29, 2024 pm 06:50 PM
이 글에서는 학습 곡선을 통해 머신러닝 모델에서 과적합과 과소적합을 효과적으로 식별하는 방법을 소개합니다. 과소적합 및 과적합 1. 과적합 모델이 데이터에 대해 과도하게 훈련되어 데이터에서 노이즈를 학습하는 경우 모델이 과적합이라고 합니다. 과적합된 모델은 모든 예를 너무 완벽하게 학습하므로 보이지 않거나 새로운 예를 잘못 분류합니다. 과대적합 모델의 경우 완벽/거의 완벽에 가까운 훈련 세트 점수와 형편없는 검증 세트/테스트 점수를 얻게 됩니다. 약간 수정됨: "과적합의 원인: 복잡한 모델을 사용하여 간단한 문제를 해결하고 데이터에서 노이즈를 추출합니다. 훈련 세트로 사용되는 작은 데이터 세트는 모든 데이터를 올바르게 표현하지 못할 수 있기 때문입니다."
 우주탐사 및 인간정주공학 분야 인공지능의 진화
Apr 29, 2024 pm 03:25 PM
우주탐사 및 인간정주공학 분야 인공지능의 진화
Apr 29, 2024 pm 03:25 PM
1950년대에는 인공지능(AI)이 탄생했다. 그때 연구자들은 기계가 사고와 같은 인간과 유사한 작업을 수행할 수 있다는 것을 발견했습니다. 이후 1960년대에 미국 국방부는 인공 지능에 자금을 지원하고 추가 개발을 위해 실험실을 설립했습니다. 연구자들은 우주 탐사, 극한 환경에서의 생존 등 다양한 분야에서 인공지능의 응용 분야를 찾고 있습니다. 우주탐험은 지구를 넘어 우주 전체를 포괄하는 우주에 대한 연구이다. 우주는 지구와 조건이 다르기 때문에 극한 환경으로 분류됩니다. 우주에서 생존하려면 많은 요소를 고려해야 하며 예방 조치를 취해야 합니다. 과학자와 연구자들은 우주를 탐험하고 모든 것의 현재 상태를 이해하는 것이 우주가 어떻게 작동하는지 이해하고 잠재적인 환경 위기에 대비하는 데 도움이 될 수 있다고 믿습니다.
 C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++에서 기계 학습 알고리즘 구현: 일반적인 과제 및 솔루션
Jun 03, 2024 pm 01:25 PM
C++의 기계 학습 알고리즘이 직면하는 일반적인 과제에는 메모리 관리, 멀티스레딩, 성능 최적화 및 유지 관리 가능성이 포함됩니다. 솔루션에는 스마트 포인터, 최신 스레딩 라이브러리, SIMD 지침 및 타사 라이브러리 사용은 물론 코딩 스타일 지침 준수 및 자동화 도구 사용이 포함됩니다. 실제 사례에서는 Eigen 라이브러리를 사용하여 선형 회귀 알고리즘을 구현하고 메모리를 효과적으로 관리하며 고성능 행렬 연산을 사용하는 방법을 보여줍니다.
 설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
설명 가능한 AI: 복잡한 AI/ML 모델 설명
Jun 03, 2024 pm 10:08 PM
번역기 | 검토자: Li Rui | Chonglou 인공 지능(AI) 및 기계 학습(ML) 모델은 오늘날 점점 더 복잡해지고 있으며 이러한 모델에서 생성되는 출력은 이해관계자에게 설명할 수 없는 블랙박스입니다. XAI(Explainable AI)는 이해관계자가 이러한 모델의 작동 방식을 이해할 수 있도록 하고, 이러한 모델이 실제로 의사 결정을 내리는 방식을 이해하도록 하며, AI 시스템의 투명성, 이 문제를 해결하기 위한 신뢰 및 책임을 보장함으로써 이 문제를 해결하는 것을 목표로 합니다. 이 기사에서는 기본 원리를 설명하기 위해 다양한 설명 가능한 인공 지능(XAI) 기술을 살펴봅니다. 설명 가능한 AI가 중요한 몇 가지 이유 신뢰와 투명성: AI 시스템이 널리 수용되고 신뢰되려면 사용자가 의사 결정 방법을 이해해야 합니다.
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
