

문서 구문 분석에는 문서의 데이터를 검사하고 유용한 정보를 추출하는 작업이 포함됩니다. 자동화를 통해 수작업을 많이 줄일 수 있습니다. 널리 사용되는 구문 분석 전략은 문서를 이미지로 변환하고 인식을 위해 컴퓨터 비전을 사용하는 것입니다. 문서 이미지 분석은 문서 이미지의 픽셀 데이터로부터 정보를 얻는 기술을 말하며, 어떤 경우에는 기대되는 결과(텍스트, 이미지, 차트, 숫자, 표, 수식)가 무엇인지에 대한 명확한 답이 없습니다. ..).

OCR(Optical Character Recognition, 광학 문자 인식)은 컴퓨터 비전을 통해 이미지 속 텍스트를 감지하고 추출하는 프로세스입니다. 이는 제1차 세계대전 중에 이스라엘 과학자 에마누엘 골드버그(Emanuel Goldberg)가 문자를 읽고 이를 전신 코드로 변환할 수 있는 기계를 만들면서 발명되었습니다. 이제 이 분야는 이미지 처리, 텍스트 위치 파악, 문자 분할 및 문자 인식이 혼합된 매우 정교한 수준에 도달했습니다. 기본적으로 텍스트에 대한 객체 감지 기술입니다.
이 기사에서는 문서 구문 분석에 OCR을 사용하는 방법을 보여 드리겠습니다. 다른 유사한 상황(복사, 붙여넣기, 실행)에서 쉽게 사용할 수 있는 몇 가지 유용한 Python 코드를 보여주고 전체 소스 코드 다운로드를 제공하겠습니다.
여기에서는 상장 회사의 PDF 형식 재무제표를 예로 들어 보겠습니다(아래 링크).
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

이 PDF에서 텍스트 감지 및 추출 , 그래프 및 표
문서 구문 분석에서 성가신 부분은 다양한 유형의 데이터(텍스트, 그래프, 표)를 위한 도구가 너무 많고 그 중 어느 것도 완벽하게 작동하지 않는다는 것입니다. 가장 널리 사용되는 방법과 패키지는 다음과 같습니다.
"PDF 파일을 직접 처리하지 않고 페이지를 이미지로 변환할 수 있는 이유는 무엇입니까?"라고 질문하실 수도 있습니다. 이 전략의 가장 큰 단점은 인코딩 문제입니다. 문서는 여러 인코딩(예: UTF-8, ASCII, 유니코드)으로 될 수 있으므로 텍스트로 변환하면 데이터가 손실될 수 있습니다. 따라서 이 문제를 피하기 위해 OCR을 사용하고 PDF2image를 사용하여 페이지를 이미지로 변환하겠습니다. PDF 렌더링 라이브러리 Poppler가 필요합니다.
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
파일을 쉽게 읽을 수 있습니다.
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page스크린샷과 똑같이 페이지 이미지를 로컬에 저장하려면 다음 코드를 사용할 수 있습니다.
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
마지막으로 CV 엔진을 설정해야 합니다. 사용. LayoutParser는 딥러닝을 기반으로 한 최초의 OCR용 범용 패키지인 것으로 보입니다. 작업을 수행하기 위해 두 가지 잘 알려진 모델을 사용합니다.
Detection: Facebook의 가장 진보된 개체 감지 라이브러리(여기서는 두 번째 버전 Detectron2가 사용됩니다).
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract: 1985년 Hewlett-Packard가 만들고 현재 Google이 개발한 가장 유명한 OCR 시스템입니다.
pip install "layoutparser[ocr]"
이제 정보 감지 및 추출을 위한 OCR 프로그램을 시작할 준비가 되었습니다.
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
(대상) 감지는 사진에서 정보 조각을 찾아 직사각형 테두리로 둘러싸는 과정입니다. 문서 구문 분석의 경우 정보는 제목, 텍스트, 그래픽, 표입니다...
몇 가지 항목이 포함된 복잡한 페이지를 살펴보겠습니다.
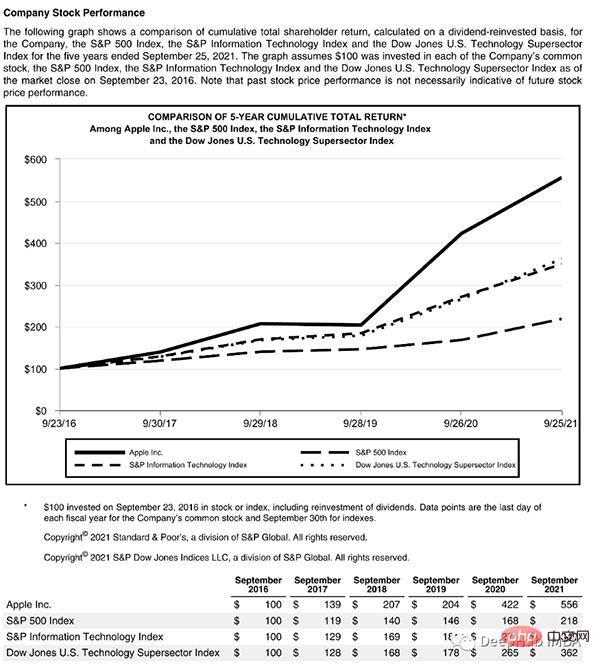
이 페이지는 제목으로 시작하고 텍스트 블록이 있습니다. 그런 다음 그래프와 테이블이 있으므로 이러한 객체를 인식하려면 훈련된 모델이 필요합니다. 운 좋게도 Detectron이 이를 수행할 수 있으므로 여기에서 모델을 선택하고 코드에서 해당 경로를 지정하기만 하면 됩니다.
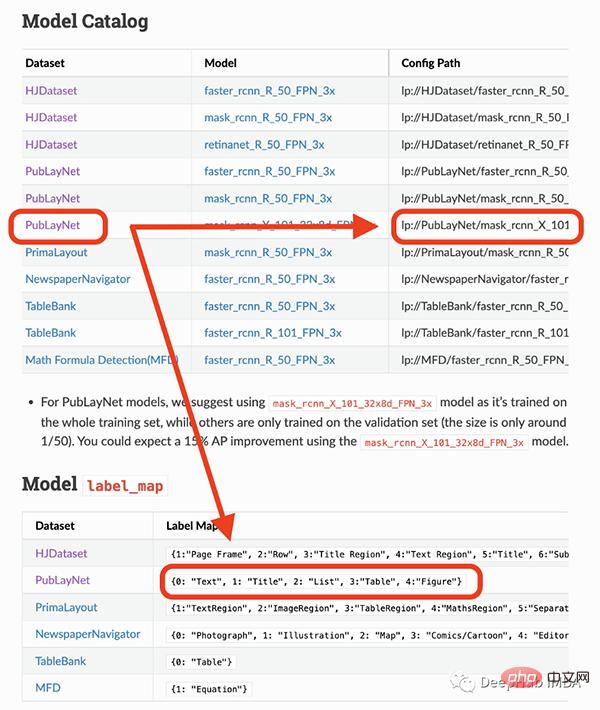
제가 사용할 모델은 4개의 객체(텍스트, 제목, 목록, 표, 그래프)만 감지할 수 있습니다. 따라서 방정식과 같은 다른 항목을 식별해야 하는 경우 다른 모델을 사용해야 합니다.
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)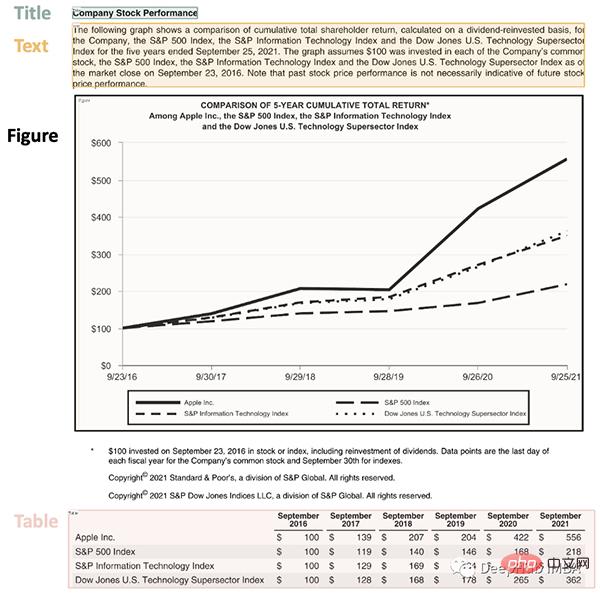
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
위 내용은 Python 및 OCR을 사용한 문서 구문 분석의 전체 코드 데모(코드 첨부)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



