

Python을 사용하여 처음부터 필기 회귀 트리

간단함을 위해 재귀는 트리 노드를 만드는 데 사용됩니다. 비록 재귀가 완벽한 구현은 아니지만 원리를 설명하는 데 가장 직관적입니다.
먼저 라이브러리를 가져옵니다
import pandas as pd import numpy as np import matplotlib.pyplot as plt
먼저 훈련 데이터를 만들어야 합니다. 데이터에는 독립 변수(x)와 상관 변수(y)가 있고 numpy를 사용하여 상관 값에 가우스 노이즈를 추가합니다. 수학적으로

여기에 노이즈가 있습니다. 코드는 아래와 같습니다.
def f(x): mu, sigma = 0, 1.5 return -x**2 + x + 5 + np.random.normal(mu, sigma, 1) num_points = 300 np.random.seed(1) x = np.random.uniform(-2, 5, num_points) y = np.array( [f(i) for i in x] ) plt.scatter(x, y, s = 5)

회귀 트리
회귀 트리에서는 여러 노드로 구성된 트리를 생성하여 수치 데이터를 예측합니다. 아래 그림은 회귀 트리의 트리 구조 예를 보여줍니다. 각 노드에는 데이터를 나누는 데 사용되는 임계값이 있습니다.

데이터 집합이 주어지면 입력 값은 해당 사양을 통해 리프 노드에 도달합니다. 노드 M에 도달하는 모든 입력값은 X의 부분집합으로 표현될 수 있습니다. 수학적으로 이 상황을 주어진 입력 값이 노드 M에 도달하면 1을 주고 그렇지 않으면 0을 주는 함수로 표현해 보겠습니다.

데이터를 분할하는 임계값 찾기: 각 단계에서 2개의 연속 포인트를 선택하고 평균을 계산하여 훈련 데이터를 반복합니다. 계산된 평균은 데이터를 두 개의 임계값으로 나눕니다.
먼저 주어진 상황을 보여주기 위해 임의의 임계값을 고려해 보겠습니다.
threshold = 1.5 low = np.take(y, np.where(x < threshold)) high = np.take(y, np.where(x > threshold)) plt.scatter(x, y, s = 5, label = 'Data') plt.plot([threshold]*2, [-16, 10], 'b--', label = 'Threshold line') plt.plot([-2, threshold], [low.mean()]*2, 'r--', label = 'Left child prediction line') plt.plot([threshold, 5], [high.mean()]*2, 'r--', label = 'Right child prediction line') plt.plot([-2, 5], [y.mean()]*2, 'g--', label = 'Node prediction line') plt.legend()

파란색 수직선은 단일 임계값을 나타내며, 이는 두 점의 평균이며 나중에 데이터를 나누는 데 사용된다고 가정합니다.
이 문제에 대한 첫 번째 예측은 모든 훈련 데이터(y축)의 평균(녹색 가로선)입니다. 그리고 두 개의 빨간색 선은 생성될 자식 노드에 대한 예측입니다.
분명히 이러한 평균 중 어느 것도 데이터를 잘 나타내지 않지만 차이점도 분명합니다. 마스터 노드 예측(녹색 선)은 모든 교육 데이터의 평균을 가져오며, 이를 2개의 하위 노드로 나누고 2개의 하위 노드에 자체 노드가 있습니다. 예측(빨간색 선). 녹색 선과 비교할 때 이 두 하위 노드는 해당 훈련 데이터를 더 잘 나타냅니다. 회귀 트리는 데이터를 지속적으로 두 부분으로 분할합니다. 즉, 지정된 중지 값(노드가 가질 수 있는 최소 데이터 양)에 도달할 때까지 각 노드에서 2개의 하위 노드를 생성합니다. 이는 우리가 미리 가지치기한 나무라고 부르는 나무 형성 과정을 조기에 중단합니다.
조기 중지 메커니즘이 있는 이유는 무엇인가요? 노드에 하나의 값만 있을 때까지 계속 할당하면 각 교육 데이터가 자체적으로만 예측할 수 있는 과적합 시나리오가 생성됩니다.
참고: 모델이 완료되면 루트 노드나 중간 노드를 사용하여 값을 예측하지 않고 회귀 트리(트리의 마지막 노드가 됨)의 잎을 사용하여 예측합니다.
주어진 임계값 데이터를 가장 잘 나타내는 임계값을 얻기 위해 잔차 제곱합을 사용합니다. 수학적으로 다음과 같이 정의할 수 있습니다.

이 단계가 어떻게 작동하는지 살펴보겠습니다.

이제 임계값의 SSR 값이 계산되었으므로 최소 SSR 값을 갖는 임계값을 채택할 수 있습니다. 이 임계값을 사용하여 교육 데이터를 두 개(낮은 부분과 높은 부분)로 분할합니다. 여기서 낮은 부분은 왼쪽 자식 노드를 만드는 데 사용되고 높은 부분은 오른쪽 자식 노드를 만드는 데 사용됩니다.
def SSR(r, y):
return np.sum( (r - y)**2 )
SSRs, thresholds = [], []
for i in range(len(x) - 1):
threshold = x[i:i+2].mean()
low = np.take(y, np.where(x < threshold))
high = np.take(y, np.where(x > threshold))
guess_low = low.mean()
guess_high = high.mean()
SSRs.append(SSR(low, guess_low) + SSR(high, guess_high))
thresholds.append(threshold)
print('Minimum residual is: {:.2f}'.format(min(SSRs)))
print('Corresponding threshold value is: {:.4f}'.format(thresholds[SSRs.index(min(SSRs))]))
在进入下一步之前,我将使用pandas创建一个df,并创建一个用于寻找最佳阈值的方法。所有这些步骤都可以在没有pandas的情况下完成,这里使用他是因为比较方便。
df = pd.DataFrame(zip(x, y.squeeze()), columns = ['x', 'y']) def find_threshold(df, plot = False): SSRs, thresholds = [], [] for i in range(len(df) - 1): threshold = df.x[i:i+2].mean() low = df[(df.x <= threshold)] high = df[(df.x > threshold)] guess_low = low.y.mean() guess_high = high.y.mean() SSRs.append(SSR(low.y.to_numpy(), guess_low) + SSR(high.y.to_numpy(), guess_high)) thresholds.append(threshold) if plot: plt.scatter(thresholds, SSRs, s = 3) plt.show() return thresholds[SSRs.index(min(SSRs))]
创建子节点
在将数据分成两个部分后就可以为低值和高值找到单独的阈值。需要注意的是这里要增加一个停止条件;因为对于每个节点,属于该节点的数据集中的点会变少,所以我们为每个节点定义了最小数据点数量。如果不这样做,每个节点将只使用一个训练值进行预测,会导致过拟合。
可以递归地创建节点,我们定义了一个名为TreeNode的类,它将存储节点应该存储的每一个值。使用这个类我们首先创建根,同时计算它的阈值和预测值。然后递归地创建它的子节点,其中每个子节点类都存储在父类的left或right属性中。
在下面的create_nodes方法中,首先将给定的df分成两部分。然后检查是否有足够的数据单独创建左右节点。如果(对于其中任何一个)有足够的数据点,我们计算阈值并使用它创建一个子节点,用这个新节点作为树再次调用create_nodes方法。
class TreeNode(): def __init__(self, threshold, pred): self.threshold = threshold self.pred = pred self.left = None self.right = None def create_nodes(tree, df, stop): low = df[df.x <= tree.threshold] high = df[df.x > tree.threshold] if len(low) > stop: threshold = find_threshold(low) tree.left = TreeNode(threshold, low.y.mean()) create_nodes(tree.left, low, stop) if len(high) > stop: threshold = find_threshold(high) tree.right = TreeNode(threshold, high.y.mean()) create_nodes(tree.right, high, stop) threshold = find_threshold(df) tree = TreeNode(threshold, df.y.mean()) create_nodes(tree, df, 5)
这个方法在第一棵树上进行了修改,因为它不需要返回任何东西。虽然递归函数通常不是这样写的(不返回),但因为不需要返回值,所以当没有激活if语句时,不做任何操作。
在完成后可以检查此树结构,查看它是否创建了一些可以拟合数据的节点。 这里将手动选择第一个节点及其对根阈值的预测。
plt.scatter(x, y, s = 0.5, label = 'Data') plt.plot([tree.threshold]*2, [-16, 10], 'r--', label = 'Root threshold') plt.plot([tree.right.threshold]*2, [-16, 10], 'g--', label = 'Right node threshold') plt.plot([tree.threshold, tree.right.threshold], [tree.right.left.pred]*2, 'g', label = 'Right node prediction') plt.plot([tree.left.threshold]*2, [-16, 10], 'm--', label = 'Left node threshold') plt.plot([tree.left.threshold, tree.threshold], [tree.left.right.pred]*2, 'm', label = 'Left node prediction') plt.plot([tree.left.left.threshold]*2, [-16, 10], 'k--', label = 'Second Left node threshold') plt.legend()

这里看到了两个预测:
- 第一个左节点对高值的预测(高于其阈值)
- 第一个右节点对低值(低于其阈值)的预测
这里我手动剪切了预测线的宽度,因为如果给定的x值达到了这些节点中的任何一个,则将以属于该节点的所有x值的平均值表示,这也意味着没有其他x值参与 在该节点的预测中(希望有意义)。
这种树形结构远不止两个节点那么简单,所以我们可以通过如下调用它的子节点来检查一个特定的叶子节点。
tree.left.right.left.left
这当然意味着这里有一个向下4个子结点长的分支,但它可以在树的另一个分支上深入得多。
预测
我们可以创建一个预测方法来预测任何给定的值。
def predict(x): curr_node = tree result = None while True: if x <= curr_node.threshold: if curr_node.left: curr_node = curr_node.left else: break elif x > curr_node.threshold: if curr_node.right: curr_node = curr_node.right else: break return curr_node.pred
预测方法做的是沿着树向下,通过比较我们的输入和每个叶子的阈值。如果输入值大于阈值,则转到右叶,如果小于阈值,则转到左叶,以此类推,直到到达任何底部叶子节点。然后使用该节点自身的预测值进行预测,并与其阈值进行最后的比较。
使用x = 3进行测试(在创建数据时,可以使用上面所写的函数计算实际值。-3**2+3+5 = -1,这是期望值),我们得到:
predict(3) # -1.23741
计算误差
这里用相对平方误差验证数据

def RSE(y, g):
return sum(np.square(y - g)) / sum(np.square(y - 1 / len(y)*sum(y)))
x_val = np.random.uniform(-2, 5, 50)
y_val = np.array( [f(i) for i in x_val] ).squeeze()
tr_preds = np.array( [predict(i) for i in df.x] )
val_preds = np.array( [predict(i) for i in x_val] )
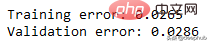
print('Training error: {:.4f}'.format(RSE(df.y, tr_preds)))
print('Validation error: {:.4f}'.format(RSE(y_val, val_preds)))可以看到误差并不大,结果如下

概括的步骤

更深入的模型
一个更适合回归树模型的数据:因为我们的数据是多项式生成的数据,所以使用多项式回归模型可以更好地拟合。我们更换一下训练数据,把新函数设为

def f(x): mu, sigma = 0, 0.5 if x < 3: return 1 + np.random.normal(mu, sigma, 1) elif x >= 3 and x < 6: return 9 + np.random.normal(mu, sigma, 1) elif x >= 6: return 5 + np.random.normal(mu, sigma, 1) np.random.seed(1) x = np.random.uniform(0, 10, num_points) y = np.array( [f(i) for i in x] ) plt.scatter(x, y, s = 5)

在此数据集上运行了上面的所有相同过程,结果如下
比我们从多项式数据中获得的误差低。
最后共享一下上面动图的代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
#===================================================Create Data
def f(x):
mu, sigma = 0, 1.5
return -x**2 + x + 5 + np.random.normal(mu, sigma, 1)
np.random.seed(1)
x = np.random.uniform(-2, 5, 300)
y = np.array( [f(i) for i in x] )
p = x.argsort()
x = x[p]
y = y[p]
#===================================================Calculate Thresholds
def SSR(r, y): #send numpy array
return np.sum( (r - y)**2 )
SSRs, thresholds = [], []
for i in range(len(x) - 1):
threshold = x[i:i+2].mean()
low = np.take(y, np.where(x < threshold))
high = np.take(y, np.where(x > threshold))
guess_low = low.mean()
guess_high = high.mean()
SSRs.append(SSR(low, guess_low) + SSR(high, guess_high))
thresholds.append(threshold)
#===================================================Animated Plot
fig, (ax1, ax2) = plt.subplots(2,1, sharex = True)
x_data, y_data = [], []
x_data2, y_data2 = [], []
ln, = ax1.plot([], [], 'r--')
ln2, = ax2.plot(thresholds, SSRs, 'ro', markersize = 2)
line = [ln, ln2]
def init():
ax1.scatter(x, y, s = 3)
ax1.title.set_text('Trying Different Thresholds')
ax2.title.set_text('Threshold vs SSR')
ax1.set_ylabel('y values')
ax2.set_xlabel('Threshold')
ax2.set_ylabel('SSR')
return line
def update(frame):
x_data = [x[frame:frame+2].mean()] * 2
y_data = [min(y), max(y)]
line[0].set_data(x_data, y_data)
x_data2.append(thresholds[frame])
y_data2.append(SSRs[frame])
line[1].set_data(x_data2, y_data2)
return line
ani = FuncAnimation(fig, update, frames = 298,
init_func = init, blit = True)
plt.show()위 내용은 Python을 사용하여 처음부터 필기 회귀 트리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7543
7543
 15
1381
52
83
11
55
19
21
87
15
1381
52
83
11
55
19
21
87

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
CentOS 시스템에서 Pytorch 모델을 효율적으로 교육하려면 단계가 필요 하며이 기사는 자세한 가이드를 제공합니다. 1. 환경 준비 : 파이썬 및 종속성 설치 : CentOS 시스템은 일반적으로 파이썬을 사전 설치하지만 버전은 더 오래 될 수 있습니다. YUM 또는 DNF를 사용하여 Python 3 및 Upgrade Pip : Sudoyumupdatepython3 (또는 SudodnfupdatePython3), PIP3INSTALL-UPGRADEPIP를 설치하는 것이 좋습니다. CUDA 및 CUDNN (GPU 가속도) : NVIDIAGPU를 사용하는 경우 Cudatool을 설치해야합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 02:51 PM
Centos에서 Pytorch 버전을 선택할 때 다음과 같은 주요 요소를 고려해야합니다. 1. Cuda 버전 호환성 GPU 지원 : NVIDIA GPU가 있고 GPU 가속도를 사용하려면 해당 CUDA 버전을 지원하는 Pytorch를 선택해야합니다. NVIDIA-SMI 명령을 실행하여 지원되는 CUDA 버전을 볼 수 있습니다. CPU 버전 : GPU가 없거나 GPU를 사용하지 않으려면 Pytorch의 CPU 버전을 선택할 수 있습니다. 2. 파이썬 버전 Pytorch
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
