

실용적인 Excel 기술 공유: 조건에 따라 순위를 매기는 수식 루틴

엑셀에서 데이터 순위를 정할 때 가장 먼저 떠오르는 것이 순위 함수인데, 조건에 따라 데이터의 순위를 매기고 싶다면 어떻게 해야 할까요? 친구들, 갑자기 헷갈리셨나요? 조건에 따른 순위 기능을 들어본 적이 없는 것 같습니다. 그래서 오늘은 엑셀의 조건에 따른 순위 계산 공식을 알려드리겠습니다.

엑셀 함수 중에는 조건에 따라 합을 구하는 SUMIF, 조건에 따라 평균을 구하는 AVERAGEIF, 조건에 따라 개수를 구하는 COUNTIF가 있는데, 최신 버전에는 조건에 따라 최대값을 구하는 MAXIFS 함수도 있습니다. 조건에 따라 최소값을 찾는 MINIFS 함수입니다. 하지만 조건에 따라 순위를 매길 수 있는 기능은 없습니다.
그러나 조건에 따른 순위 지정과 같은 문제가 자주 발생합니다. 예를 들어 다음 문제가 대표적인 문제입니다.
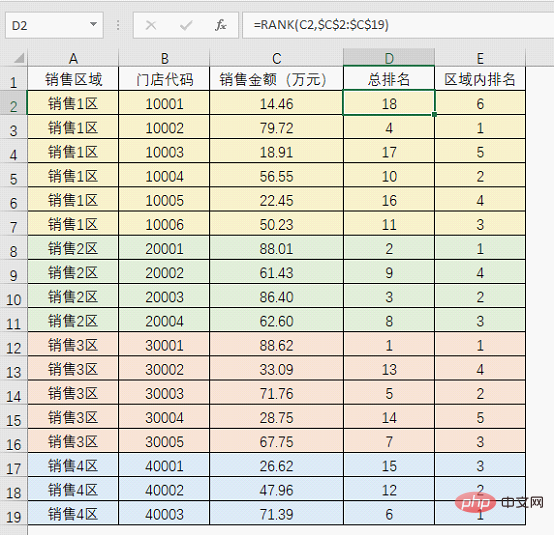
우리 모두는 RANK 함수를 사용하면 집합에 있는 숫자의 수를 얻을 수 있다는 것을 알고 있습니다. 순위. 이 예에서 총 순위는 =RANK(C2,$C$2:$C$19) 공식을 사용하여 구합니다.
그런데 지역별 매장별 매출 순위를 알고 싶다면 RANK 기능을 이용해 지역별로 순위를 매겨야 하나요?
이것도 아이디어이긴 하지만 효율성이 낮다고 생각할 수 있습니다. 사실 엑셀 기능 중에 조건에 따라 순위를 매길 수 있는 기능이 있는데, 바로 SUMPRODUCT 입니다.
조건별 순위 공식을 정식으로 소개하기에 앞서 조건별 순위의 작동원리를 먼저 이해해 보도록 하겠습니다.
10004번 매장을 예로 들면 지역 순위는 2이고 전체 순위는 10입니다. 그림에 표시된 대로:

지역 순위가 2인 이유는 동일하기 때문에 이해하기 쉽습니다. 판매 지역(조건)에는 이 6개의 숫자 중 단 하나의 숫자만이 56.55, 즉 79.72보다 크므로 해당 영역에서의 순위는 2입니다.
다른 순위의 계산 원리도 이와 같습니다. 이렇게 생각하면 조건별 순위를 달성하는 데에는 실제로 조건 판단과 규모 판단이라는 두 가지 과정이 필요합니다.
수식을 사용하여 이 두 프로세스를 작성하세요: $A$2:$A$19=A2 및 $C$2:$C$19>C2 이 두 부분은 예제를 통해 이해할 수 있습니다. $A:$A=A2和$C:$C>C2,可以结合实例来理解这两部分。
首先看第一个,$A:$A=A2会得到一组逻辑值:
{TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}
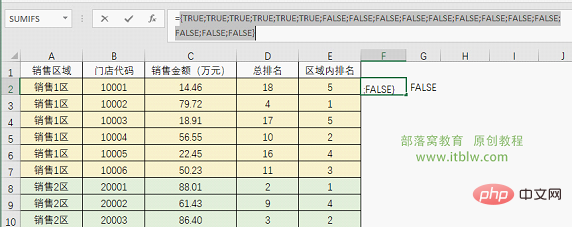
从这个结果中可以看出,与要统计的门店在同一个区域的数据都是TRUE。
$C:$C>C2同样也会得到一组逻辑值:
{FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE}
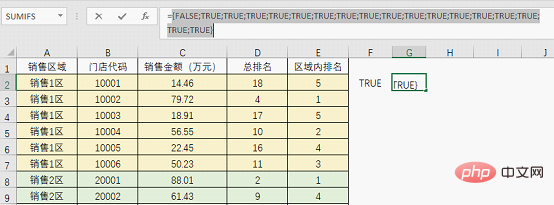
这个结果表示销售额大于要统计门店时也会得到TRUE。
现在的问题是如何将这两个部分合并起来,因为这是对一个数据同时进行的两个判断,所以将两组逻辑值相乘,来看看得到了什么结果:

图中的这一组由0和1构成的数据,是($A:$A=A2)*($C:$C>C2)计算得到的结果,表示10001这个门店所在的区域中,销售额高于14.46的有4个门店(4个1),只需要对这个结果求和,基本上就实现了排名的目的,因此公式套路也就有了:
=SUMPRODUCT(($A:$A=A2)*($C:$C>C2))
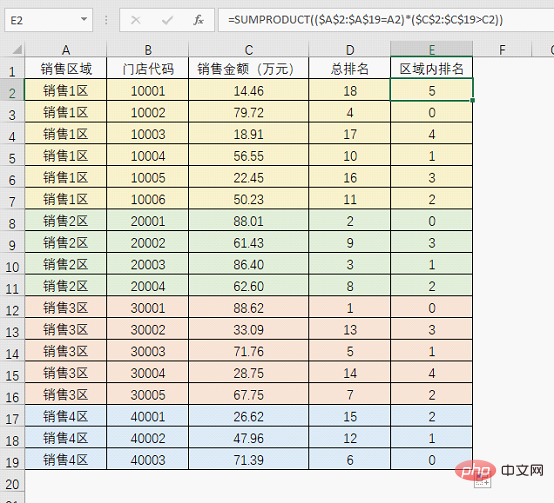
不过这样得到的结果有个问题,名次是从0开始的,要解决也很简单,有两个方法。
方法1:直接在公式后加1,结果如图所示。

方法2::将大于号改成大于等于,结果如图所示。

这两个方法,通常情况下并没有什么区别,使用哪个公式都可以。
以上是针对一个条件进行排名的公式,如果条件是两个或者更多,将公式套路进行扩展就行:
=SUMPRODUCT((条件区域1=条件1)* (条件区域2=条件2)* (数据区域>数据))
$A$2:$A$19=A2는 일련의 논리 값을 얻습니다.
{TRUE;TRUE;TRUE;TRUE;TRUE;TRUE ;FALSE ;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}🎜🎜🎜🎜이 결과를 보면 계산할 매장과 동일한 영역의 데이터가 모두 TRUE임을 알 수 있습니다. 🎜🎜$C$2:$C$19>C2는 다음과 같은 논리 값 집합도 가져옵니다. 🎜🎜{FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE; 참;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE}🎜🎜🎜🎜이 결과는 판매량이 계산할 매장보다 큰 경우에도 TRUE를 얻음을 의미합니다. 🎜🎜이제 질문은 이 두 부분을 결합하는 방법입니다. 이는 동시에 하나의 데이터에 대한 두 가지 판단이므로 두 논리값 세트를 곱하여 어떤 결과가 나오는지 확인하세요. 🎜🎜🎜🎜사진 속 이 그룹은 0개로 구성되어 있습니다. 데이터 1과 1로 구성된 것은 ($A$2:$A$19=A2)*($C$2:$C$19>C2)의 결과로, 10001번 매장이 위치한 지역의 판매량은 14.46 이상 4개 매장(4 1)이 있으며 기본적으로 순위 목적을 달성하려면 결과만 합산하면 됩니다. 따라서 공식은 다음과 같습니다. 🎜🎜=SUMPRODUCT(($A$2:$ A$19= A2)*($C$2:$C$19>C2))🎜🎜 🎜🎜그런데 이렇게 얻은 결과에는 문제가 있습니다. 순위는 0부터 시작됩니다. 푸는 방법은 매우 간단합니다. 방법은 2가지가 있습니다. 🎜🎜방법 1: 수식 바로 뒤에 1을 추가하면 결과는 그림과 같습니다. 🎜🎜🎜🎜방법 2: :보다 큼 기호를 크거나 같음으로 변경하면 결과는 그림과 같습니다. 🎜🎜🎜🎜이 두 가지 방법 , 일반적으로 차이가 없으며 어떤 수식이라도 사용할 수 있습니다. 🎜🎜위는 조건이 2개 이상인 경우 수식을 확장하면 됩니다. 🎜🎜=SUMPRODUCT((조건부 1=조건 1)* (조건부 2=조건 2) * (데이터 영역>데이터))🎜🎜구체적인 예를 나열하지는 않겠습니다. 모두가 공식의 원리를 이해한 후에는 구체적인 문제에 따라 직접 적용해도 문제가 없다고 생각합니다. 🎜
🎜🎜그런데 이렇게 얻은 결과에는 문제가 있습니다. 순위는 0부터 시작됩니다. 푸는 방법은 매우 간단합니다. 방법은 2가지가 있습니다. 🎜🎜방법 1: 수식 바로 뒤에 1을 추가하면 결과는 그림과 같습니다. 🎜🎜🎜🎜방법 2: :보다 큼 기호를 크거나 같음으로 변경하면 결과는 그림과 같습니다. 🎜🎜🎜🎜이 두 가지 방법 , 일반적으로 차이가 없으며 어떤 수식이라도 사용할 수 있습니다. 🎜🎜위는 조건이 2개 이상인 경우 수식을 확장하면 됩니다. 🎜🎜=SUMPRODUCT((조건부 1=조건 1)* (조건부 2=조건 2) * (데이터 영역>데이터))🎜🎜구체적인 예를 나열하지는 않겠습니다. 모두가 공식의 원리를 이해한 후에는 구체적인 문제에 따라 직접 적용해도 문제가 없다고 생각합니다. 🎜관련 학습 권장사항: excel 튜토리얼
위 내용은 실용적인 Excel 기술 공유: 조건에 따라 순위를 매기는 수식 루틴의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 엑셀 인쇄 시 테두리 선이 사라지면 어떻게 해야 하나요?
Mar 21, 2024 am 09:50 AM
엑셀 인쇄 시 테두리 선이 사라지면 어떻게 해야 하나요?
Mar 21, 2024 am 09:50 AM
인쇄해야 하는 파일을 열 때 인쇄 미리보기에서 어떤 이유로 인해 테이블 프레임 선이 사라진 것을 발견할 수 있습니다. 이러한 상황이 발생하면 인쇄에도 나타나는 경우 제때에 처리해야 합니다. file 이런 질문이 있으시면 에디터에 가입하여 다음 강좌를 배워보세요. Excel에서 표를 인쇄할 때 테두리 선이 사라지면 어떻게 해야 하나요? 1. 아래 그림과 같이 인쇄할 파일을 엽니다. 2. 아래 그림과 같이 필요한 콘텐츠 영역을 모두 선택합니다. 3. 아래 그림과 같이 마우스 오른쪽 버튼을 클릭하고 "셀 서식" 옵션을 선택합니다. 4. 아래 그림과 같이 창 상단의 "테두리" 옵션을 클릭하세요. 5. 아래 그림과 같이 왼쪽 선 스타일에서 가는 실선 패턴을 선택합니다. 6. '외부 테두리'를 선택하세요.
 Excel에서 동시에 3개 이상의 키워드를 필터링하는 방법
Mar 21, 2024 pm 03:16 PM
Excel에서 동시에 3개 이상의 키워드를 필터링하는 방법
Mar 21, 2024 pm 03:16 PM
엑셀은 일상적인 사무에서 데이터를 처리하는 데 자주 사용되며, "필터" 기능을 사용해야 하는 경우가 많습니다. Excel에서 "필터링"을 수행하도록 선택하면 동일한 열에 대해 최대 2개의 조건만 필터링할 수 있습니다. 그러면 Excel에서 동시에 3개 이상의 키워드를 필터링하는 방법을 알고 계십니까? 다음으로 여러분에게 보여드리겠습니다. 첫 번째 방법은 필터에 조건을 점진적으로 추가하는 것입니다. 세 가지 적격 세부정보를 동시에 필터링하려면 먼저 그 중 하나를 단계별로 필터링해야 합니다. 처음에는 조건에 따라 "Wang"이라는 직원을 먼저 필터링할 수 있습니다. 그런 다음 [확인]을 클릭한 후 필터 결과에서 [현재 선택 항목을 필터에 추가]를 선택하세요. 단계는 다음과 같습니다. 마찬가지로 다시 별도로 필터링을 수행합니다.
 Excel 테이블 호환 모드를 일반 모드로 변경하는 방법
Mar 20, 2024 pm 08:01 PM
Excel 테이블 호환 모드를 일반 모드로 변경하는 방법
Mar 20, 2024 pm 08:01 PM
일상 업무나 공부를 하다 보면 다른 사람의 엑셀 파일을 복사해서 열어서 내용을 추가하거나 다시 편집하고 저장하는 경우가 가끔 있는데, 엑셀을 잘 몰라서 가끔 호환성 확인 대화 상자가 뜨는 경우가 있습니다. 소프트웨어, 일반 모드로 변경할 수 있나요? 따라서 아래에서 편집자가 이 문제를 해결하기 위한 자세한 단계를 알려드릴 것입니다. 함께 배워보겠습니다. 마지막으로 저장하는 것을 잊지 마세요. 1. 워크시트를 열고 그림과 같이 워크시트 이름에 추가 호환성 모드를 표시합니다. 2. 이 워크시트에서는 내용을 수정하고 저장하면 항상 호환성 검사 대화상자가 팝업되는데, 그림과 같이 이 페이지를 보는 것이 매우 번거롭습니다. 3. Office 버튼을 클릭하고 다른 이름으로 저장을 클릭한 다음
 Excel에서 위 첨자를 설정하는 방법
Mar 20, 2024 pm 04:30 PM
Excel에서 위 첨자를 설정하는 방법
Mar 20, 2024 pm 04:30 PM
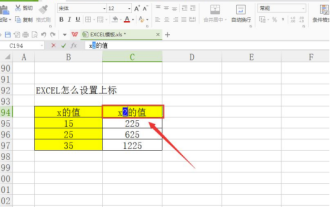
데이터를 처리하다 보면 배수, 온도 등 다양한 기호가 포함된 데이터를 접하게 되는 경우가 있습니다. Excel에서 위 첨자를 설정하는 방법을 알고 계시나요? Excel을 사용하여 데이터를 처리할 때 위 첨자를 설정하지 않으면 많은 양의 데이터를 입력하는 것이 더 번거로워집니다. 오늘은 에디터가 엑셀 위 첨자의 구체적인 설정 방법을 알려드리겠습니다. 1. 먼저, 그림과 같이 바탕 화면에서 Microsoft Office Excel 문서를 열고 위 첨자로 수정해야 할 텍스트를 선택하겠습니다. 2. 그런 다음 그림과 같이 마우스 오른쪽 버튼을 클릭하고 클릭 후 나타나는 메뉴에서 "셀 서식"옵션을 선택하십시오. 3. 다음으로 자동으로 나타나는 “셀 서식” 대화 상자에서
 엑셀에서 아래 첨자를 입력하는 방법
Mar 20, 2024 am 11:31 AM
엑셀에서 아래 첨자를 입력하는 방법
Mar 20, 2024 am 11:31 AM
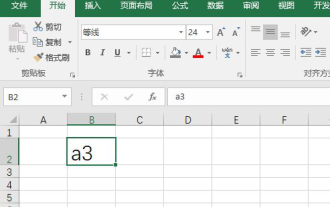
e우리는 데이터 테이블 등을 만들기 위해 종종 엑셀을 사용합니다. 때로는 매개변수 값을 입력할 때 특정 숫자를 위 첨자나 아래 첨자로 입력해야 할 때가 있습니다. 예를 들어, 엑셀에서는 아래 첨자를 어떻게 입력합니까? 자세한 단계를 살펴보세요: 1. 위 첨자 방법: 1. 먼저 Excel에 a3(3은 위 첨자)를 입력합니다. 2. 숫자 "3"을 선택하고 마우스 오른쪽 버튼을 클릭한 후 "셀 서식"을 선택합니다. 3. "위첨자"를 클릭한 후 "확인"을 클릭하세요. 4. 보세요, 효과는 이렇습니다. 2. 아래 첨자 방법: 1. 위 첨자 설정 방법과 유사하게 셀에 "ln310"(3은 아래 첨자)을 입력하고 숫자 "3"을 선택한 후 마우스 오른쪽 버튼을 클릭하고 "셀 서식 지정"을 선택합니다. 2. "아래 첨자"를 체크하고 "확인"을 클릭하세요.
 Excel에서 iif 함수를 사용하는 방법
Mar 20, 2024 pm 06:10 PM
Excel에서 iif 함수를 사용하는 방법
Mar 20, 2024 pm 06:10 PM
대부분의 사용자는 테이블 데이터를 처리하기 위해 Excel을 사용합니다. 실제로 Excel에도 VBA 프로그램이 있습니다. 전문가를 제외하고는 이 기능을 사용하는 사용자가 많지 않습니다. iif 함수는 실제로 VBA와 유사합니다. iif 함수의 사용법을 소개하겠습니다. SQL 문에는 iif 함수가 있고 Excel에는 VBA 코드가 있습니다. iif 함수는 Excel 워크시트의 IF 함수와 유사하며 참과 거짓 값을 판단하고 논리적으로 계산된 참과 거짓 값을 기반으로 서로 다른 결과를 반환합니다. IF 함수 사용법은 (조건, 예, 아니오)입니다. VBA의 IF문과 IIF 함수 전자의 IF문은 조건에 따라 다른 명령문을 실행할 수 있는 제어문인 반면 후자는
 Excel 읽기 모드를 설정하는 위치
Mar 21, 2024 am 08:40 AM
Excel 읽기 모드를 설정하는 위치
Mar 21, 2024 am 08:40 AM
소프트웨어 공부에 있어서 우리는 엑셀을 사용하는데 익숙해져 있는데, 편리할 뿐만 아니라 실제 업무에 필요한 다양한 형식을 충족할 수 있고, 엑셀은 사용하기에 매우 유연하며, 읽기에 편리합니다. 오늘은 모두를 위한 엑셀 읽기 모드 설정 위치를 가져왔습니다. 1. 컴퓨터를 켠 다음 Excel 응용 프로그램을 열고 대상 데이터를 찾습니다. 2. Excel에서 읽기 모드를 설정하는 방법에는 두 가지가 있습니다. 첫 번째: Excel에는 Excel 레이아웃에 배포된 편리한 처리 방법이 많이 있습니다. 엑셀 오른쪽 하단에 읽기 모드 설정 바로가기가 있습니다. 십자 표시 패턴을 찾아 클릭하면 십자 표시 오른쪽에 작은 입체 표시가 있습니다. .
 PPT 슬라이드에 엑셀 아이콘을 삽입하는 방법
Mar 26, 2024 pm 05:40 PM
PPT 슬라이드에 엑셀 아이콘을 삽입하는 방법
Mar 26, 2024 pm 05:40 PM
1. PPT를 열고 엑셀 아이콘을 삽입해야 하는 페이지로 페이지를 넘깁니다. 삽입 탭을 클릭합니다. 2. [개체]를 클릭하세요. 3. 다음과 같은 대화상자가 나타납니다. 4. [파일에서 생성]을 클릭한 후 [찾아보기]를 클릭하세요. 5. 삽입할 엑셀 표를 선택하세요. 6. 확인을 클릭하면 다음 페이지가 나타납니다. 7. [아이콘으로 표시]를 체크하세요. 8. 확인을 클릭합니다.
