
컴퓨터 과학 및 기계 학습(ML) 분야의 많은 응용 프로그램에서는 좌표계 전반에 걸쳐 다차원 데이터 세트를 처리해야 하며 단일 데이터 세트에 테라바이트 또는 페타바이트 규모의 데이터를 저장해야 할 수도 있습니다. 반면에, 사용자가 불규칙한 간격과 다양한 규모로 데이터를 읽고 쓸 수 있으며 종종 광범위한 병렬 작업을 수행할 수 있기 때문에 이러한 데이터세트로 작업하는 것도 어려울 수 있습니다.
위 문제를 해결하기 위해 Google은 n차원 데이터를 저장하고 운영하도록 설계된 오픈 소스 C++ 및 Python 소프트웨어 라이브러리인 TensorStore를 개발했습니다. Google AI 책임자인 Jeff Dean도 TensorStore가 이제 공식 오픈 소스라고 트윗했습니다.
TensorStore의 주요 기능은 다음과 같습니다.
TensorStore는 과학 컴퓨팅의 엔지니어링 과제를 해결하는 데 사용되었으며 분산 학습 중에 PaLM의 모델 매개변수(체크포인트)를 관리하는 등 대규모 기계 학습 모델을 만드는 데에도 사용되었습니다.
GitHub 주소: https://github.com/google/tensorstore
TensorStore는 대규모 배열 데이터를 로드하고 조작하기 위한 간단한 Python API를 제공합니다. 예를 들어, 다음 코드는 파리 뇌의 56조 복셀 3D 이미지를 나타내고 NumPy 배열의 100x100 이미지 패치 데이터에 대한 액세스를 허용하는 TensorStore 개체를 생성합니다.
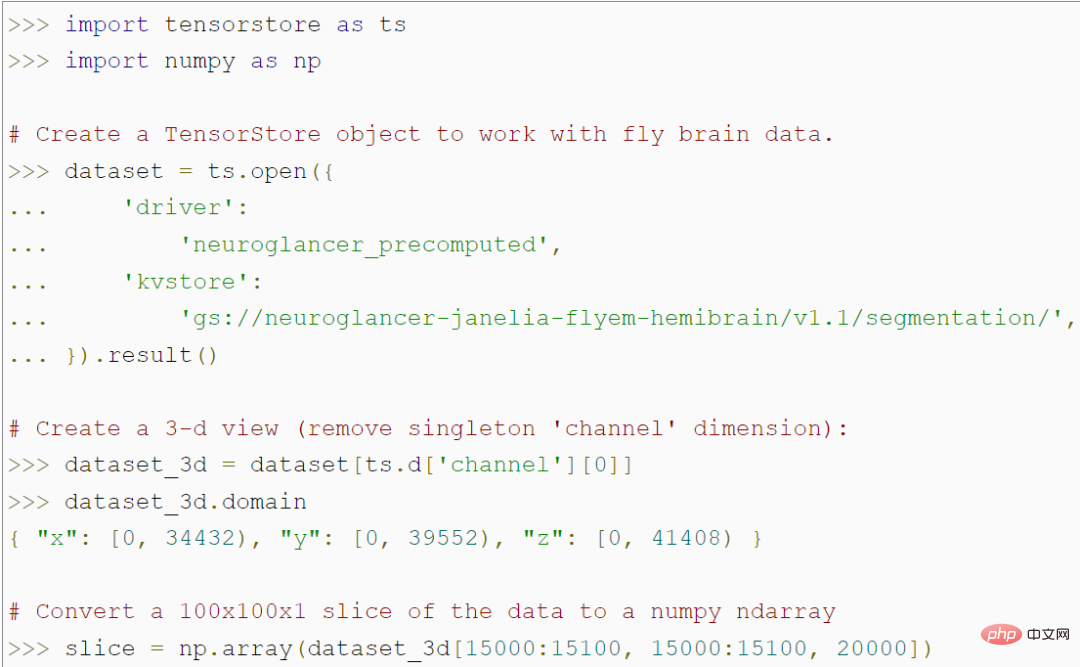
특히, 프로그램은 액세스하지 않습니다 특정 100x100 패치에 액세스할 때까지 실제 데이터를 메모리에 저장하므로 전체 데이터 세트를 메모리에 저장하지 않고도 임의로 큰 기본 데이터 세트를 로드하고 조작할 수 있습니다. TensorStore는 기본적으로 표준 NumPy와 동일한 인덱싱 및 작업 구문을 사용합니다.
또한 TensorStore는 정렬, 가상 보기 등을 포함한 고급 색인 기능에 대한 광범위한 지원을 제공합니다.
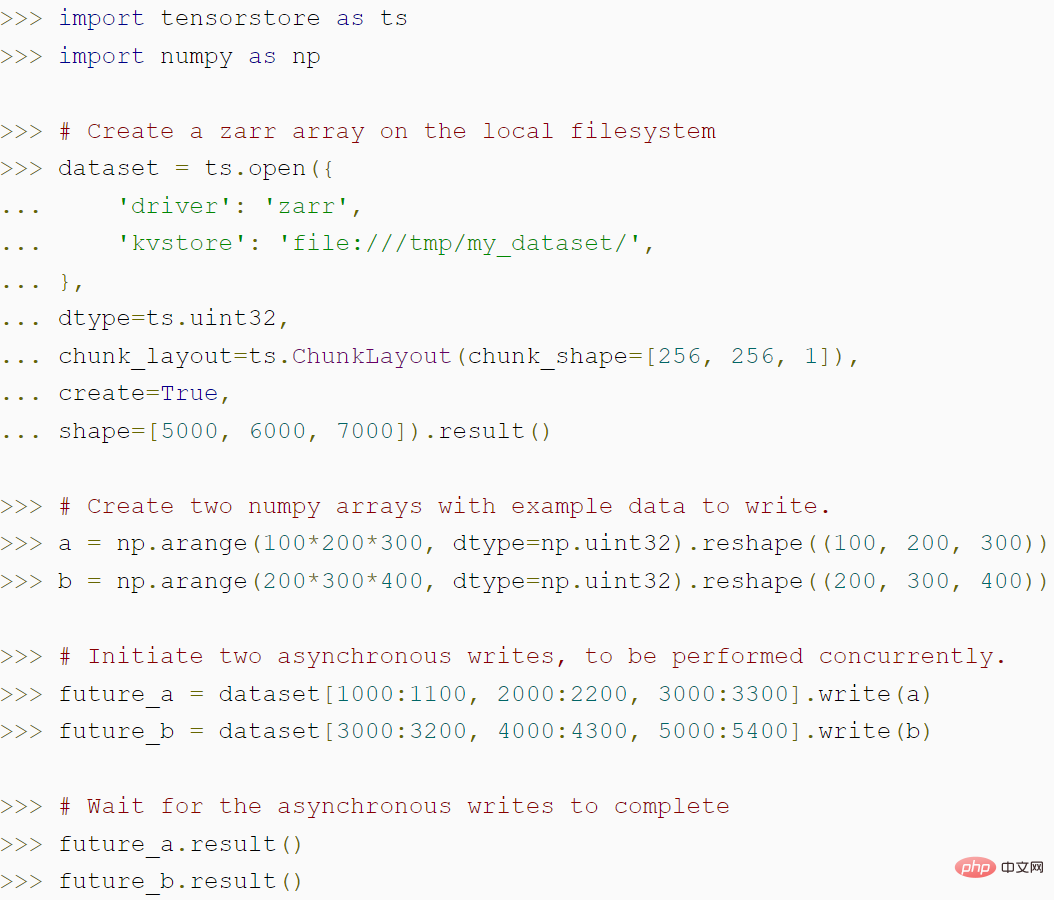
다음 코드는 TensorStore를 사용하여 zarr 배열을 생성하는 방법과 TensorStore의 비동기 API가 어떻게 더 높은 처리량을 달성할 수 있는지 보여줍니다.
우리 모두 알고 있듯이 대용량 데이터 분석 및 처리 세트에는 상당한 컴퓨팅 리소스가 필요하며, 종종 여러 시스템에 분산된 CPU 또는 가속기 코어의 병렬화가 필요합니다. 따라서 TensorStore의 기본 목표는 병렬 처리를 구현하여 안전성과 고성능을 모두 달성하는 것입니다. 실제로 Google 데이터 센터의 테스트에서 CPU 수가 증가함에 따라 TensorStore 읽기 및 쓰기 성능이 거의 선형적으로 증가한다는 사실을 발견했습니다. Google Cloud Storage(GCS)의 zarr 형식에서
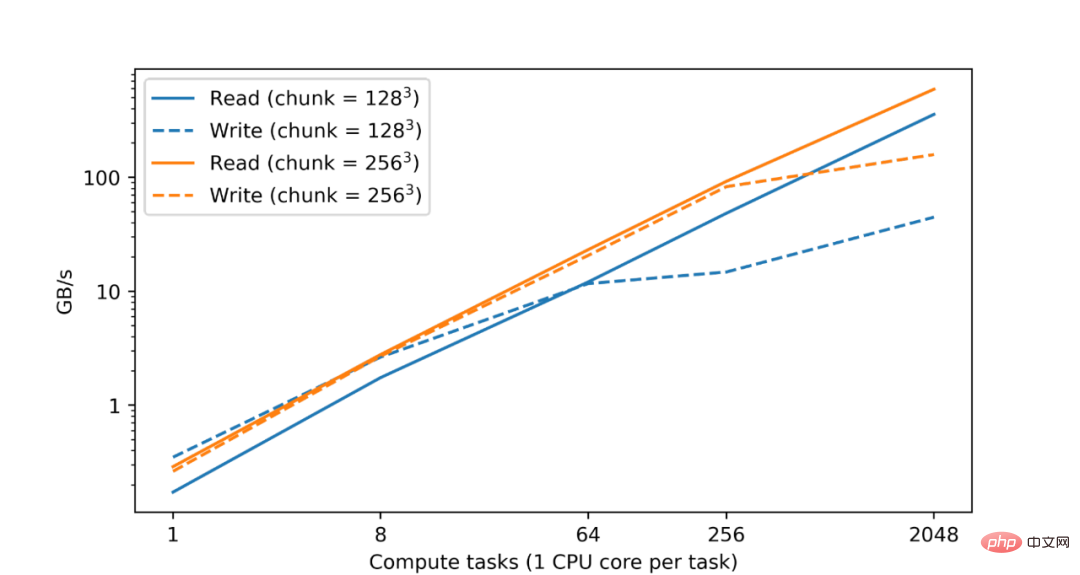
데이터 세트의 쓰기 성능은 컴퓨팅 작업 수에 따라 거의 선형적으로 증가합니다.
TensorStore는 프로그램이 다른 작업을 완료하는 동안 백그라운드에서 읽기 및 쓰기 작업을 계속할 수 있도록 구성 가능한 메모리 캐시와 비동기 API도 제공합니다. TensorStore의 분산 컴퓨팅이 데이터 처리 워크플로와 호환되도록 하기 위해 Google은 TensorStore를 Apache Beam과 같은 병렬 컴퓨팅 라이브러리와 통합합니다.
예 1 언어 모델: 최근에는 PaLM과 같은 일부 고급 언어 모델이 기계 학습 분야에 등장했습니다. 이러한 모델에는 수천억 개의 매개변수가 포함되어 있으며 자연어 이해 및 생성 분야에서 놀라운 기능을 보여줍니다. 그러나 이러한 모델은 컴퓨팅 시설에 문제를 야기합니다. 특히 PaLM과 같은 언어 모델을 교육하려면 수천 개의 TPU가 병렬로 작동해야 합니다.
모델 매개변수를 효율적으로 읽고 쓰는 것은 훈련 과정에서 직면하는 문제입니다. 예를 들어 훈련은 여러 기계에 분산되지만 매개변수는 정기적으로 체크포인트에 저장되어야 합니다. 예를 들어 단일 훈련은 특정 매개변수 세트만 읽어야 합니다. 전체 모델 매개변수 세트(수백 GB 가능)를 로드하는 데 필요한 오버헤드를 방지합니다.
TensorStore는 위의 문제를 해결할 수 있습니다. 대형(멀티포드) 모델과 관련된 체크포인트를 관리하는 데 사용되었으며, T5X, Pathways 등의 프레임워크와 통합되었습니다. TensorStore는 체크포인트를 zarr 형식 저장소로 변환하고 각 TPU의 파티션을 병렬 및 독립적으로 읽고 쓸 수 있도록 블록 구조를 선택합니다.

체크포인트가 저장되면 매개변수는 zarr 형식으로 작성되고 블록 그리드는 TPU에서 매개변수 그리드를 분할하기 위해 더 분할됩니다. 호스트는 호스트의 TPU에 할당된 각 파티션에 대해 zarr 블록을 병렬로 씁니다. TensorStore의 비동기 API를 사용하면 데이터가 영구 저장소에 기록되는 동안에도 학습이 계속됩니다. 검사점에서 복구할 때 각 호스트는 해당 호스트에 할당된 파티션 블록만 읽습니다.
예 2 뇌 3D 매핑: 시냅스 분해 커넥토믹스는 개별 시냅스 연결 수준에서 동물과 인간 두뇌의 배선을 매핑하는 것을 목표로 합니다. 이를 달성하려면 밀리미터 이상의 시야에 걸쳐 극도로 높은 해상도(나노 규모)로 뇌를 이미징해야 하며, 그 결과 페타바이트 규모의 데이터가 생성됩니다. 그러나 지금도 데이터 세트는 저장, 처리 등의 문제에 직면해 있습니다. 단 하나의 뇌 샘플이라도 수백만 기가바이트의 공간이 필요할 수 있습니다.
Google은 TensorStore를 사용하여 대규모 커넥토믹스 데이터 세트와 관련된 계산 문제를 해결했습니다. 특히 TensorStore는 일부 Connectomics 데이터 세트를 관리하기 시작했으며 Google Cloud Storage를 기본 객체 스토리지 시스템으로 사용합니다.
현재 TensorStore는 인간 대뇌 피질 데이터 세트 H01에 사용되었으며 원본 이미징 데이터는 1.4PB(약 500000 * 350000 * 5000픽셀)입니다. 그런 다음 원시 데이터는 128x128x16 픽셀의 독립적인 블록으로 세분화되고 TensorStore에서 쉽게 조작할 수 있는 "Neuroglancer 사전 계산" 형식으로 저장됩니다.

TensorStore를 사용하면 기본 데이터에 쉽게 액세스하고 조작할 수 있습니다(빠른 두뇌 재구성)
시작하려는 친구는 다음 방법을 사용하여 TensorStore PyPI 패키지를 설치할 수 있습니다.
rreee위 내용은 구글, 오픈소스 소프트웨어 라이브러리로 n차원 데이터 저장 및 조작 문제 해결의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



