

안녕하세요 여러분 신인입니다!
데이터는 온라인에서 찾은 판매 데이터입니다.
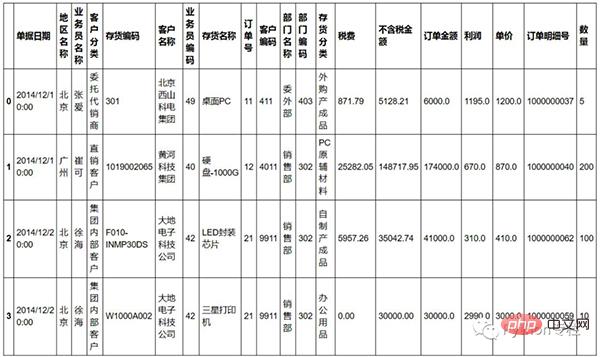
Vlookup은 Excel에서 거의 가장 많이 사용되는 공식으로, 일반적으로 둘 사이의 관련 쿼리에 사용됩니다. 테이블. 그래서 먼저 이 테이블을 두 개의 테이블로 나누었습니다.
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
Demand: df1의 각 주문에 해당하는 수익을 알고 싶습니다.
df2의 테이블에 수익 열이 존재하므로 df1의 각 주문에 해당하는 수익을 알고 싶습니다. Excel을 사용할 때 먼저 주문 세부 번호가 고유한 값인지 확인한 다음 df1에 새 열을 추가하고 =vlookup(a2,df2!a:h,6,0)이라고 쓴 다음 아래로 당기면 괜찮아요. (나머지 13개는 엑셀은 쓰지 않겠습니다.)
파이썬으로 어떻게 구현하나요?
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")
요구 사항: 각 지역 영업사원의 총 수익과 평균 수익을 알고 싶습니다.
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
이 테이블의 각 열의 데이터 차원이 다르기 때문에 비교하는 것은 의미가 없으므로 먼저 주문 세부 사항에 차이를 두고 비교했습니다.
요구사항: 주문상세번호와 주문상세번호 2의 차이를 비교하여 표시합니다.
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
요구사항: 영업사원이 코딩한 중복값 제거
sale.drop_duplicates("业务员编码",inplace=True)먼저 판매 데이터 중 어떤 열에 결측값이 있는지 확인하세요.
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

요구 사항: 누락된 값을 0으로 채우거나 고객이 코딩한 누락된 값이 있는 행을 삭제하세요. 실제로 결측값을 처리하는 방법은 매우 복잡합니다. 여기서는 간단한 처리 방법만 소개합니다. 수치변수인 경우 가장 일반적으로 사용되는 방법은 평균, 중간값 또는 모드입니다. 포리스트 모델은 다른 차원을 기반으로 예측하는 데 사용될 수 있습니다. 범주형 변수인 경우 비즈니스 로직에 따라 채우는 것이 더 정확합니다. 예를 들어 여기서 요구사항은 고객 이름의 결측값을 채우는 것인데, 이는 재고 분류에서 발생 빈도가 가장 높은 재고에 해당하는 고객 이름에 따라 채울 수 있습니다.
여기에서는 간단한 솔루션을 사용합니다. 누락된 값을 0으로 채우거나 고객이 코딩한 누락된 값이 있는 행을 삭제합니다.
#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])
수요: 베이징 지역에서 주문 금액이 6,000개 이상인 상품을 판매하는 판매원 장애씨에 대한 정보를 알고 싶습니다.
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
요구 사항: 인벤토리 이름에 "Samsung" 또는 "Sony"가 포함된 정보를 필터링합니다.
sale.loc[sale["存货名称"].str.contains("三星|索尼")]요건: 베이징 지역 판매원 1인당 총 수익입니다.
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
수요: 인벤토리 이름에 "Samsung"이 있고 세금이 1,000보다 높은 주문은 몇 개입니까? 이 주문의 합계와 평균 이익은 얼마입니까? (또는 최소값, 최대값, 사분위수, 라벨 차이)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()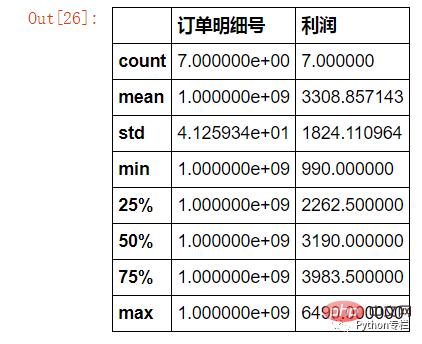
요구사항: 인벤토리 이름 양쪽의 공백을 삭제하세요.
sale["인벤토리 이름"].map(lambda s:s.strip(""))
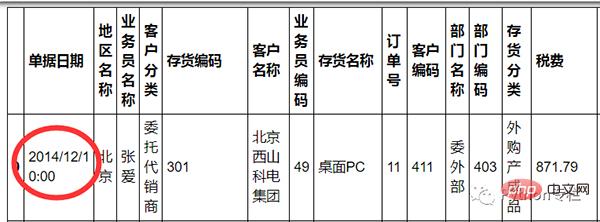
요구 사항: 날짜와 시간을 정렬하세요.
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True) 먼저, explain() 함수를 사용하여 데이터에 이상값이 있는지 간단히 확인합니다.
#매출세가 음수임을 알 수 있습니다. 이는 일반적으로 그렇지 않으며 이상값으로 간주됩니다.
sale.describe()
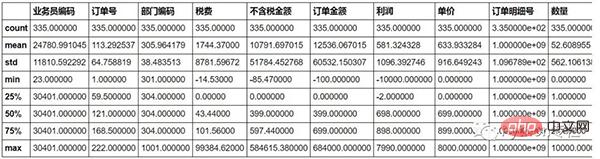
요구 사항: 이상값을 0으로 바꿉니다.
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
요구 사항: 수익 데이터 분포에 따라 지역을 그룹화합니다: "나쁨", "보통", "더 좋음", "매우 좋음"
우선, 물론 이익 데이터 분포, 여기서는 사분위수를 사용하여 판단합니다.
sale.groupby("地区名称")["利润"].sum().describe()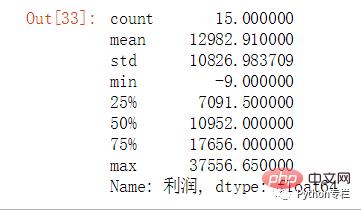
지역별 총 수익은 사분위수에 따라 [-9,7091] 범위에서 "나쁨"으로 그룹화되고, (7091,10952) 범위는 "중간"(10952,17656) 범위로 그룹화됩니다. ] 그룹화가 더 좋고, (17656,37556]이 매우 좋음으로 그룹화됩니다.
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)요구 사항: 판매 이익률(예: 이익/주문 금액)이 30% 이상인 제품 정보 및 고급제품의 경우 일반제품은 5%미만입니다.
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品" sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
실제로 엑셀에서 자주 사용하는 연산이 있는데 그 중 제가 자주 사용하는 연산을 14개 나열해봤습니다. , 같이 댓글 달고 토론할 수도 있습니다. 게다가 저도 알고 있습니다. 제가 파이썬으로 쓴 글은 간결하지 않아서 loc를 사용합니다. (사실 쿼리는 더 간결하게 작성하실 수 있을 겁니다.) 이러한 작업은 댓글로 알려주세요. 감사합니다!
마지막으로, 어느 것이 더 사용하기 쉬운지 연구하기 위해 Excel과 Python을 비교하지 않는 것이 가장 좋다고 말씀드리고 싶습니다. 사실 둘 다 가장 널리 사용되는 데이터 처리 도구로서 Excel이 독점되어 왔습니다. 수년이 지났고 데이터 처리의 편의성 측면에서 상당히 우수할 것입니다. Python에서는 실제로 일부 작업이 더 간단하지만 Excel에는 Python보다 간단한 작업도 많이 있습니다.
예를 들어 매우 간단한 작업은 각 열을 합산하여 맨 아래 행에 표시하는 것입니다. Excel에서는 각 열에 sum() 함수를 추가한 다음 이를 해결하기 위해 왼쪽으로 끌어오지만 Python에서는 정의해야 합니다. 함수(파이썬은 형식을 결정해야 하기 때문에 숫자 값이 아닌 경우 오류를 직접 보고합니다)
.위 내용은 Python을 사용한 Excel의 14가지 일반적인 작업의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



