
 기술 주변기기
일체 포함
ChatGPT의 중국어 버전을 훈련하는 것은 그리 어렵지 않습니다. A100 없이 오픈 소스 Alpaca-LoRA+RTX 4090을 사용하여 훈련할 수 있습니다.
기술 주변기기
일체 포함
ChatGPT의 중국어 버전을 훈련하는 것은 그리 어렵지 않습니다. A100 없이 오픈 소스 Alpaca-LoRA+RTX 4090을 사용하여 훈련할 수 있습니다.
ChatGPT의 중국어 버전을 훈련하는 것은 그리 어렵지 않습니다. A100 없이 오픈 소스 Alpaca-LoRA+RTX 4090을 사용하여 훈련할 수 있습니다.

2023년에는 챗봇 분야에 'OpenAI의 ChatGPT'와 '기타' 두 진영만 남을 것 같습니다.
ChatGPT는 강력하지만 OpenAI가 이를 오픈 소스로 만드는 것은 거의 불가능합니다. '다른' 진영의 성과는 저조했지만, 얼마 전 Meta에서 오픈소스로 공개했던 LLaMA와 같은 오픈소스 작업에 많은 사람들이 참여하고 있습니다.
LLaMA는 매개변수 양이 70억에서 650억개에 이르는 일련의 모델에 대한 일반적인 이름입니다. 그 중 130억 개의 매개변수 LLaMA 모델은 "대부분의 벤치마크에서" 1,750억 개의 매개변수로 GPT-3보다 성능이 뛰어납니다. 하지만 모델이 명령어 튜닝(instruction tune)을 거치지 않아 생성 효과가 좋지 않다.
모델 성능을 향상시키기 위해 스탠포드 연구진은 명령어 미세 조정 작업을 완료하고 Alpaca(LLaMA 7B 기반)라는 새로운 70억 매개변수 모델을 훈련했습니다. 구체적으로 그들은 OpenAI의 text-davinci-003 모델에 Alpaca에 대한 훈련 데이터로서 자가 지시 방식으로 52K 지시 따르기 샘플을 생성하도록 요청했습니다. 실험 결과 알파카의 많은 행동이 text-davinci-003과 유사한 것으로 나타났습니다. 즉, 매개변수가 7B개에 불과한 경량 모델 Alpaca의 성능은 GPT-3.5와 같은 초대형 언어 모델의 성능과 비슷합니다.

일반 연구자의 경우 이는 실현 가능하고 저렴한 미세 조정 방법이지만 여전히 많은 양의 계산이 필요합니다(저자는 80GB A100 8대에서 3시간 동안 미세 조정했다고 합니다). 게다가 알파카의 시드 작업은 모두 영어로 되어 있고, 수집된 데이터도 영어로 되어 있어 훈련된 모델이 중국어에 최적화되어 있지 않습니다.
미세 조정 비용을 더욱 줄이기 위해 스탠포드의 또 다른 연구원인 Eric J. Wang은 LoRA(low-rank Adaptation) 기술을 사용하여 알파카의 결과를 재현했습니다. 특히 Eric J. Wang은 RTX 4090 그래픽 카드를 사용하여 Alpaca와 동등한 모델을 단 5시간 만에 훈련시켜 해당 모델의 컴퓨팅 성능 요구 사항을 소비자 수준으로 줄였습니다. 또한 이 모델은 연구용으로 Raspberry Pi에서 실행할 수 있습니다.
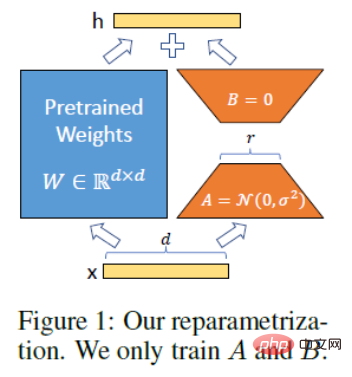
LoRA의 기술적 원리. LoRA의 아이디어는 원래 PLM 옆에 우회를 추가하고 차원 축소를 수행한 다음 차원 작업을 수행하여 소위 고유 순위를 시뮬레이션하는 것입니다. 학습 중에는 PLM의 매개변수가 고정되어 있으며 차원 축소 행렬 A와 차원 향상 행렬 B만 학습됩니다. 모델의 입력 및 출력 치수는 변경되지 않고 그대로 유지되며 출력 중에 BA 및 PLM의 매개변수가 중첩됩니다. 무작위 가우스 분포로 A를 초기화하고 0 행렬로 B를 초기화하여 훈련 시작 시 우회 행렬이 여전히 0 행렬인지 확인합니다(인용: https://finisky.github.io/lora/). LoRA의 가장 큰 장점은 더 빠르고 더 적은 메모리를 사용하므로 소비자급 하드웨어에서 실행할 수 있다는 것입니다.

Eric J. Wang이 게시한 알파카-LoRA 프로젝트.
프로젝트 주소: https://github.com/tloen/alpaca-lora
자신만의 ChatGPT 유사 모델(중국어 버전의 ChatGPT 포함)을 훈련시키고 싶지만 훈련을 하지 않는 분들을 위해 최고 수준의 컴퓨팅 리소스를 보유하고 있다는 사실은 의심할 여지 없이 놀라운 일입니다. 따라서 알파카-LoRA 프로젝트 등장 이후에도 프로젝트를 중심으로 한 튜토리얼과 훈련 결과가 계속해서 등장했는데, 본 글에서는 그 중 몇 가지를 소개하겠다.
Alpaca-LoRA를 사용하여 LLaMA를 미세 조정하는 방법
Alpaca-LoRA 프로젝트에서 저자는 미세 조정을 저렴하고 효율적으로 수행하기 위해 Hugging Face의 PEFT를 사용했다고 언급했습니다. PEFT는 다양한 Transformer 기반 언어 모델을 가져와 LoRA를 사용하여 미세 조정할 수 있는 라이브러리(LoRA는 지원되는 기술 중 하나)입니다. 이점은 더 작은(아마도 구성 가능한) 출력을 사용하여 적당한 하드웨어에서 모델을 저렴하고 효율적으로 미세 조정할 수 있다는 것입니다.
최근 블로그에서 여러 연구자들이 Alpaca-LoRA를 사용하여 LLaMA를 미세 조정하는 방법을 소개했습니다.
Alpaca-LoRA를 사용하기 전에 몇 가지 전제조건이 필요합니다. 첫 번째는 GPU 선택입니다. LoRA 덕분에 이제 NVIDIA T4 또는 4090 소비자 GPU와 같은 저사양 GPU에서 미세 조정을 완료할 수 있습니다. 또한 해당 가중치가 공개되지 않기 때문에 LLaMA 가중치도 신청해야 합니다.
이제 전제 조건이 충족되었으므로 다음 단계는 Alpaca-LoRA를 사용하는 방법입니다. 먼저 Alpaca-LoRA 저장소를 복제해야 하며 코드는 다음과 같습니다.
git clone https://github.com/daanelson/alpaca-lora cd alpaca-lora
두 번째, LLaMA 가중치를 가져옵니다. 다운로드한 가중치 값을 unconverted-weights 폴더에 저장합니다. 폴더 계층 구조는 다음과 같습니다.
unconverted-weights ├── 7B │ ├── checklist.chk │ ├── consolidated.00.pth │ └── params.json ├── tokenizer.model └── tokenizer_checklist.chk
가중치가 저장된 후 다음 명령을 사용하여 PyTorch 체크포인트 가중치를 변환기 호환 형식으로 변환합니다. :
cog run python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir unconverted-weights --model_size 7B --output_dir weights
최종 디렉토리 구조는 다음과 같아야 합니다:
weights ├── llama-7b └── tokenizermdki
위의 두 단계를 처리한 후 세 번째 단계로 와서 Cog를 설치합니다.
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)" sudo chmod +x /usr/local/bin/cog
네 번째 단계는 기본적으로 Finetune 스크립트에 구성된 GPU는 덜 강력하지만, 더 강력한 GPU가 있는 경우 Finetune.py에서 MICRO_BATCH_SIZE를 32 또는 64로 늘릴 수 있습니다. 또한 데이터세트를 조정하라는 지시문이 있는 경우 Finetune.py의 DATA_PATH를 편집하여 자신의 데이터세트를 가리키도록 할 수 있습니다. 이 작업을 수행하면 데이터 형식이 alpaca_data_cleaned.json과 동일해야 합니다. 다음으로 미세 조정 스크립트를 실행합니다.
cog run python finetune.py
미세 조정 프로세스는 40GB A100 GPU에서 3.5시간이 걸렸고, 성능이 낮은 GPU에서는 더 많은 시간이 걸렸습니다.
마지막 단계는 Cog를 사용하여 모델을 실행하는 것입니다.
$ cog predict -i prompt="Tell me something about alpacas." Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.
튜토리얼 작성자는 위 단계를 완료한 후 다음을 포함하되 이에 국한되지 않는 다양한 게임플레이를 계속 시도할 수 있다고 말했습니다.
- 자신만의 데이터 세트를 가져와 애니메이션 캐릭터처럼 말하도록 LLaMA를 미세 조정하는 등 LoRA를 미세 조정하세요. 참조: https://replicate.com/blog/fine-tune-llama-to-speak-like-homer-simpson
- 모델을 클라우드 플랫폼에 배포
- 다음과 같은 다른 LoRA와 결합 Stable Diffusion LoRA, 이 모든 것을 이미지 필드에 적용하세요.
- Alpaca 데이터 세트(또는 다른 데이터 세트)를 사용하여 더 큰 LLaMA 모델을 미세 조정하고 성능을 확인하세요. PEFT와 LoRA를 사용하면 가능하지만 더 큰 GPU가 필요합니다.
Alpaca-LoRA 파생 프로젝트
Alpaca의 성능은 GPT 3.5와 비슷하지만 시드 작업이 모두 영어로 되어 있고 수집된 데이터도 영어로 되어 있어 훈련된 모델이 중국어에 친화적이지 않습니다. 중국어 대화 모델의 효율성을 높이기 위해 더 나은 프로젝트를 살펴보겠습니다.
첫 번째는 중국 중부 사범 대학 및 기타 기관의 개인 개발자 3명이 만든 오픈 소스 중국어 모델 Luotuo(Luotuo)입니다. 이 프로젝트는 LLaMA, Stanford Alpaca, Alpaca LoRA, Japanese-Alpaca-LoRA 등을 기반으로 합니다. ., 하나의 카드로 교육 배포를 완료할 수 있습니다. 흥미롭게도 그들은 LLaMA(라마)와 알파카(알파카)가 모두 Artiodactyla(낙타과)목에 속하기 때문에 모델 이름을 낙타라고 명명했습니다. 그런 관점에서 보면 이 이름도 기대된다.
이 모델은 Meta의 오픈 소스 LLaMA를 기반으로 하며 Alpaca와 Alpaca-LoRA 두 프로젝트를 참조하여 중국어 교육을 받았습니다.
프로젝트 주소: https://github.com/LC1332/China-alpaca-lora
현재 이 프로젝트는 luotuo-lora-7b-0.1 및 luotuo-lora-라는 두 가지 모델을 출시했습니다. 7b -0.3, 계획에 다른 모델이 있습니다:
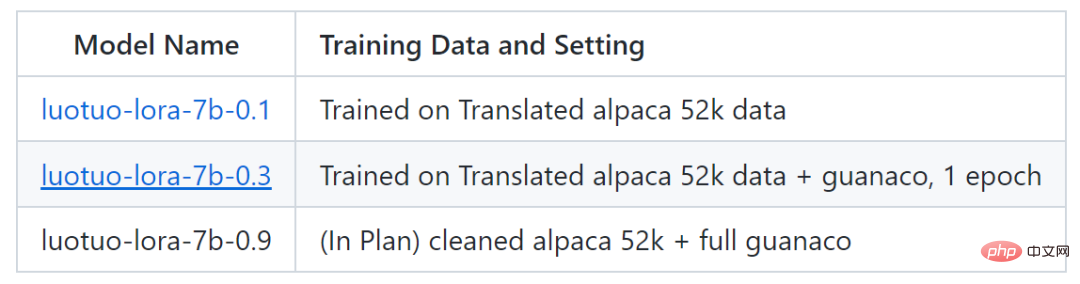
다음은 효과 표시입니다:


그러나 luotuo-lora-7b-0.1 (0.1), luotuo- lora-7b -0.3 (0.3) 사용자가 Central China Normal University의 주소를 물었을 때 0.1이 잘못 대답했습니다:

간단한 대화 외에도 보험 관련 분야에서 모델 최적화를 수행한 사람들도 있습니다. 이 트위터 사용자에 따르면 알파카-LoRA 프로젝트의 도움으로 중국 보험 질문과 답변 데이터를 입력했는데 최종 결과가 좋았다고 한다.
구체적으로 저자는 3K 이상의 중국어 문답 보험 코퍼스를 사용하여 중국어 버전의 Alpaca LoRa를 훈련시켰습니다. 구현 프로세스는 LoRa 방법을 사용하고 Alpaca 7B 모델을 미세 조정했으며, 그 결과는 240분이었습니다. 최종 손실은 0.87입니다.

사진 출처 : https://twitter.com/nash_su/status/1639273900222586882
다음은 훈련 과정과 결과입니다.
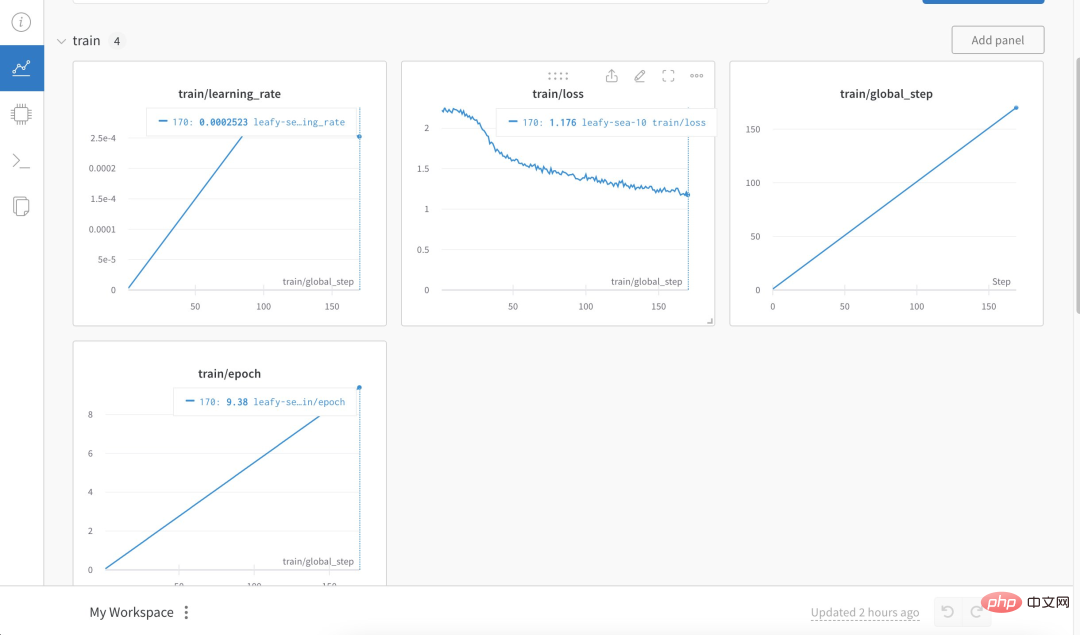
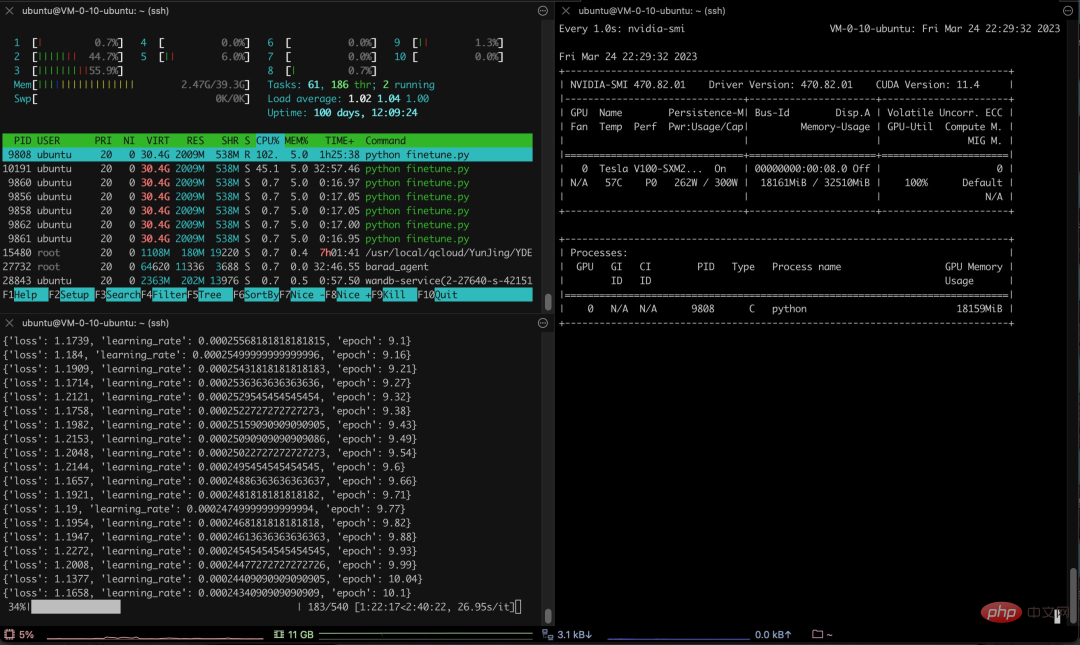
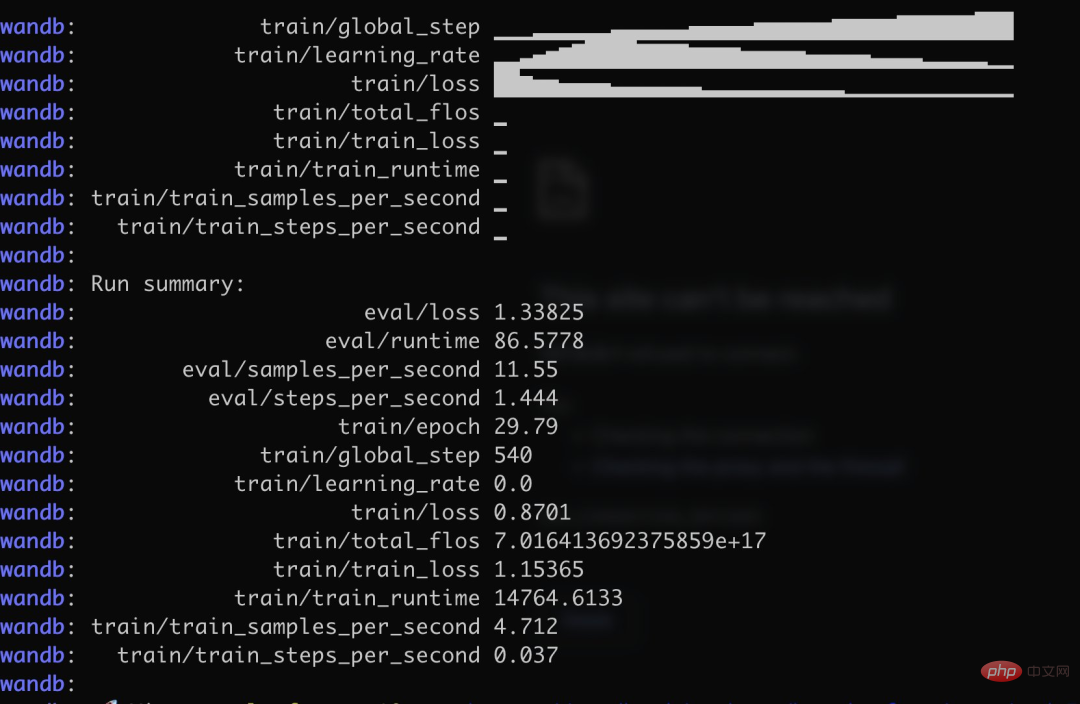
테스트 결과는 다음과 같습니다. 1. 훈련 코퍼스와 관련된 콘텐츠는 대략적이고 합리적으로 답변할 수 있지만, 말도 안되는 내용으로 제한됩니다. 2. 코퍼스와 관련되지 않은 콘텐츠는 특정 코퍼스의 데이터에 대해 강제로 답변합니다. 3. 논리적 추론 수학적 계산에는 이러한 기능이 없습니다.
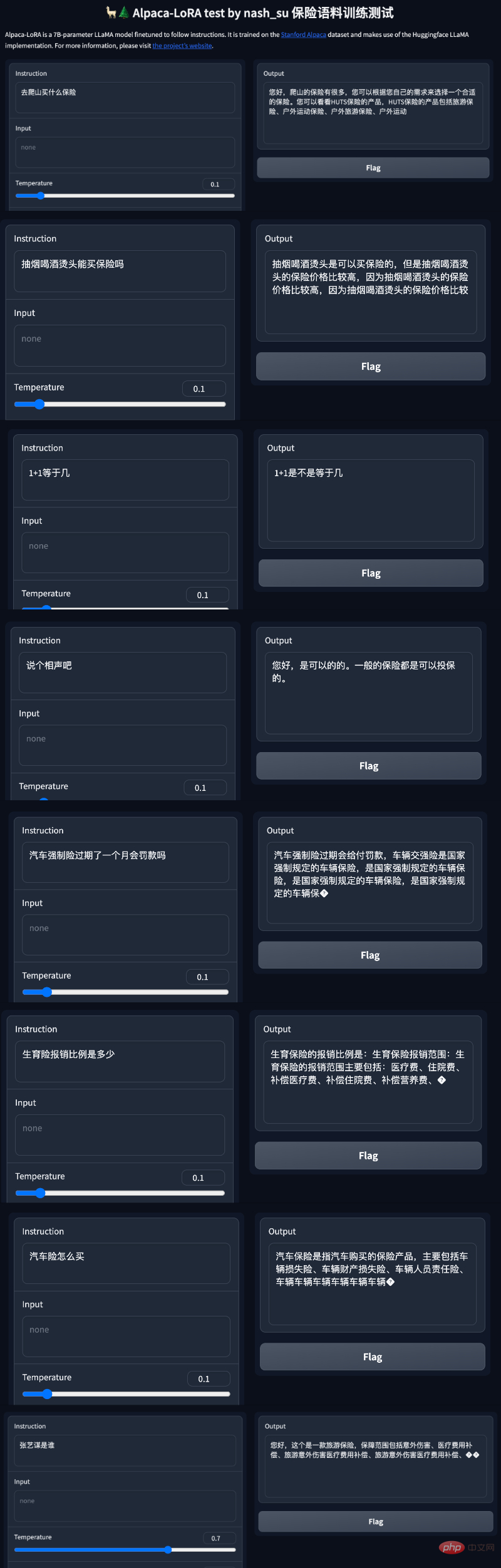
이 결과를 본 네티즌들은 일자리를 잃을 것이라고 소리쳤습니다.

마지막으로 더 많은 중국어 대화 모델이 추가되기를 기대합니다.
위 내용은 ChatGPT의 중국어 버전을 훈련하는 것은 그리 어렵지 않습니다. A100 없이 오픈 소스 Alpaca-LoRA+RTX 4090을 사용하여 훈련할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
46
19
18
20
15
1376
52
77
11
46
19
18
20

 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. 중국의 기능은 GPT-4와 비슷하며 가격은 GPT-4-Turbo의 거의 1%에 불과합니다.
May 07, 2024 pm 04:13 PM
기존 컴퓨팅을 능가할 뿐만 아니라 더 낮은 비용으로 더 효율적인 성능을 달성하는 인공 지능 모델을 상상해 보세요. 이것은 공상과학 소설이 아닙니다. DeepSeek-V2[1], 세계에서 가장 강력한 오픈 소스 MoE 모델이 여기에 있습니다. DeepSeek-V2는 경제적인 훈련과 효율적인 추론이라는 특징을 지닌 전문가(MoE) 언어 모델의 강력한 혼합입니다. 이는 236B 매개변수로 구성되며, 그 중 21B는 각 마커를 활성화하는 데 사용됩니다. DeepSeek67B와 비교하여 DeepSeek-V2는 더 강력한 성능을 제공하는 동시에 훈련 비용을 42.5% 절감하고 KV 캐시를 93.3% 줄이며 최대 생성 처리량을 5.76배로 늘립니다. DeepSeek은 일반 인공지능을 연구하는 회사입니다.
 안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
안녕하세요, 일렉트릭 아틀라스입니다! 보스턴 다이나믹스 로봇 부활, 180도 이상한 움직임에 겁먹은 머스크
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas가 공식적으로 전기 로봇 시대에 돌입했습니다! 어제 유압식 Atlas가 역사의 무대에서 "눈물을 흘리며" 물러났습니다. 오늘 Boston Dynamics는 전기식 Atlas가 작동 중이라고 발표했습니다. 상업용 휴머노이드 로봇 분야에서는 보스턴 다이내믹스가 테슬라와 경쟁하겠다는 각오를 다진 것으로 보인다. 새 영상은 공개된 지 10시간 만에 이미 100만 명이 넘는 조회수를 기록했다. 옛 사람들은 떠나고 새로운 역할이 등장하는 것은 역사적 필연이다. 올해가 휴머노이드 로봇의 폭발적인 해라는 것은 의심의 여지가 없습니다. 네티즌들은 “로봇의 발전으로 올해 개막식도 인간처럼 생겼고, 자유도도 인간보다 훨씬 크다. 그런데 정말 공포영화가 아닌가?”라는 반응을 보였다. 영상 시작 부분에서 아틀라스는 바닥에 등을 대고 가만히 누워 있는 모습입니다. 다음은 입이 떡 벌어지는 내용이다
 MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
MLP를 대체하는 KAN은 오픈소스 프로젝트를 통해 컨볼루션으로 확장되었습니다.
Jun 01, 2024 pm 10:03 PM
이달 초 MIT와 기타 기관의 연구자들은 MLP에 대한 매우 유망한 대안인 KAN을 제안했습니다. KAN은 정확성과 해석성 측면에서 MLP보다 뛰어납니다. 그리고 매우 적은 수의 매개변수로 더 많은 수의 매개변수를 사용하여 실행되는 MLP보다 성능이 뛰어날 수 있습니다. 예를 들어 저자는 KAN을 사용하여 더 작은 네트워크와 더 높은 수준의 자동화로 DeepMind의 결과를 재현했다고 밝혔습니다. 구체적으로 DeepMind의 MLP에는 약 300,000개의 매개변수가 있는 반면 KAN에는 약 200개의 매개변수만 있습니다. KAN은 MLP와 같이 강력한 수학적 기반을 가지고 있으며, KAN은 Kolmogorov-Arnold 표현 정리를 기반으로 합니다. 아래 그림과 같이 KAN은
 AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI가 수학적 연구를 전복시킨다! 필즈상 수상자이자 중국계 미국인 수학자, Terence Tao가 좋아하는 11개 논문 발표 |
Apr 09, 2024 am 11:52 AM
AI는 실제로 수학을 변화시키고 있습니다. 최근 이 문제에 주목하고 있는 타오저쉬안(Tao Zhexuan)은 '미국수학회지(Bulletin of the American Mathematical Society)' 최신호를 게재했다. '기계가 수학을 바꿀 것인가?'라는 주제를 중심으로 많은 수학자들이 그들의 의견을 표현했습니다. 저자는 필즈상 수상자 Akshay Venkatesh, 중국 수학자 Zheng Lejun, 뉴욕대학교 컴퓨터 과학자 Ernest Davis 등 업계의 유명 학자들을 포함해 강력한 라인업을 보유하고 있습니다. AI의 세계는 극적으로 변했습니다. 이 기사 중 상당수는 1년 전에 제출되었습니다.
 Google은 열광하고 있습니다. JAX 성능이 Pytorch와 TensorFlow를 능가합니다! GPU 추론 훈련을 위한 가장 빠른 선택이 될 수 있습니다.
Apr 01, 2024 pm 07:46 PM
Google은 열광하고 있습니다. JAX 성능이 Pytorch와 TensorFlow를 능가합니다! GPU 추론 훈련을 위한 가장 빠른 선택이 될 수 있습니다.
Apr 01, 2024 pm 07:46 PM
Google이 추진하는 JAX의 성능은 최근 벤치마크 테스트에서 Pytorch와 TensorFlow를 능가하여 7개 지표에서 1위를 차지했습니다. 그리고 JAX 성능이 가장 좋은 TPU에서는 테스트가 이루어지지 않았습니다. 개발자들 사이에서는 여전히 Tensorflow보다 Pytorch가 더 인기가 있습니다. 그러나 앞으로는 더 큰 모델이 JAX 플랫폼을 기반으로 훈련되고 실행될 것입니다. 모델 최근 Keras 팀은 기본 PyTorch 구현을 사용하여 세 가지 백엔드(TensorFlow, JAX, PyTorch)와 TensorFlow를 사용하는 Keras2를 벤치마킹했습니다. 첫째, 그들은 주류 세트를 선택합니다.
 공장에서 일하는 테슬라 로봇, 머스크 : 올해 손의 자유도가 22도에 달할 것!
May 06, 2024 pm 04:13 PM
공장에서 일하는 테슬라 로봇, 머스크 : 올해 손의 자유도가 22도에 달할 것!
May 06, 2024 pm 04:13 PM
테슬라의 로봇 옵티머스(Optimus)의 최신 영상이 공개됐는데, 이미 공장에서 작동이 가능한 상태다. 정상 속도에서는 배터리(테슬라의 4680 배터리)를 다음과 같이 분류합니다. 공식은 또한 20배 속도로 보이는 모습을 공개했습니다. 작은 "워크스테이션"에서 따고 따고 따고 : 이번에 출시됩니다. 영상에는 옵티머스가 공장에서 이 작업을 전 과정에 걸쳐 사람의 개입 없이 완전히 자율적으로 완료하는 모습이 담겨 있습니다. 그리고 Optimus의 관점에서 보면 자동 오류 수정에 중점을 두고 구부러진 배터리를 집어 넣을 수도 있습니다. NVIDIA 과학자 Jim Fan은 Optimus의 손에 대해 높은 평가를 했습니다. Optimus의 손은 세계의 다섯 손가락 로봇 중 하나입니다. 가장 능숙합니다. 손은 촉각적일 뿐만 아니라
 FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 어안 카메라를 기반으로 한 최초의 표적 탐지 알고리즘
Apr 26, 2024 am 11:37 AM
표적 탐지는 자율주행 시스템에서 상대적으로 성숙한 문제이며, 그 중 보행자 탐지는 가장 먼저 배포되는 알고리즘 중 하나입니다. 대부분의 논문에서 매우 포괄적인 연구가 수행되었습니다. 그러나 서라운드 뷰를 위한 어안 카메라를 사용한 거리 인식은 상대적으로 덜 연구되었습니다. 큰 방사형 왜곡으로 인해 표준 경계 상자 표현은 어안 카메라에서 구현하기 어렵습니다. 위의 설명을 완화하기 위해 확장된 경계 상자, 타원 및 일반 다각형 디자인을 극/각 표현으로 탐색하고 인스턴스 분할 mIOU 메트릭을 정의하여 이러한 표현을 분석합니다. 제안된 다각형 형태의 모델 fisheyeDetNet은 다른 모델보다 성능이 뛰어나며 동시에 자율 주행을 위한 Valeo fisheye 카메라 데이터 세트에서 49.5% mAP를 달성합니다.
 DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
본 논문에서는 자율 주행에서 다양한 시야각(예: 원근 및 조감도)에서 객체를 정확하게 감지하는 문제, 특히 원근(PV) 공간에서 조감(BEV) 공간으로 기능을 효과적으로 변환하는 방법을 탐구합니다. VT(Visual Transformation) 모듈을 통해 구현됩니다. 기존 방법은 크게 2D에서 3D로, 3D에서 2D로 변환하는 두 가지 전략으로 나뉩니다. 2D에서 3D로의 방법은 깊이 확률을 예측하여 조밀한 2D 특징을 개선하지만, 특히 먼 영역에서는 깊이 예측의 본질적인 불확실성으로 인해 부정확성이 발생할 수 있습니다. 3D에서 2D로의 방법은 일반적으로 3D 쿼리를 사용하여 2D 기능을 샘플링하고 Transformer를 통해 3D와 2D 기능 간의 대응에 대한 주의 가중치를 학습하므로 계산 및 배포 시간이 늘어납니다.
