

프로그래밍에서 객체 모듈 생성은 주로 객체 생성을 통해 이루어집니다. 객체가 사용되면 더 이상 필요하지 않은 모듈이 되어 폐기됩니다.
시스템이 객체를 생성하고 파괴하면 메모리 소비가 크게 증가합니다. 동시에 객체 파괴는 종종 잔여 정보를 남기며 메모리 누수 문제를 동반합니다.
실제 프로그램 개발 과정에서는 다수의 중복된 객체를 생성하고 파기해야 하는 경우가 많습니다. 이로 인해 메모리 누수로 인해 생성된 정보가 너무 많아 시스템에서 재활용할 수 없게 되어 시스템의 메모리를 더 많이 차지하게 됩니다. , 너무 많은 객체가 생성되면 어떤 모듈이 인스턴스화되고 구현되는지 확인할 수 없으므로 시스템에 부담을 주고 장기적으로 관리 및 후속 작업에 도움이 되지 않으며 결국 프로그램 속도가 느려지게 됩니다. 다운되거나 충돌할 수도 있습니다.
객체 풀은 생성된 객체를 일괄적으로 저장하는 풀입니다. 객체를 유지하는 데 사용되는 구조입니다. 프로그램이 개체를 사용해야 하는 경우 새 개체를 인스턴스화하는 대신 풀에서 직접 개체를 얻을 수 있습니다.
프로그래밍 과정에서 대부분의 사람들은 객체의 사용과 효과의 구현에만 집중하는 경향이 있습니다. 실제로 생성과 사용 사이에는 초기화 과정이 있지만 시스템은 초기화와 효과의 두 단계를 결합합니다. 생성 또한 이는 디자이너가 시스템에서 객체를 생성하고 파괴하는 프로세스의 영향을 무시하게 만듭니다.
일반적으로 객체를 생성하고 삭제하는 데 드는 비용은 매우 적으므로 무시할 수 있습니다. 그러나 프로그램이 객체를 여러 번 생성하고 생성 시간이 상대적으로 길면 이에 대한 소비가 분명해집니다. 부분은 시스템 속도를 제한합니다.
객체 풀은 GC 압력을 줄이는 데 선호되는 방법이라고 할 수 있으며 가장 간단한 방법이기도 합니다.
Pond는 우수한 성능, 작은 메모리 공간 및 높은 적중률을 특징으로 하는 Python의 효율적인 일반 개체 풀입니다. 대략적인 통계를 바탕으로 빈도에 따라 자동으로 재활용하는 기능을 통해 각 개체 풀의 사용 가능한 개체 수를 자동으로 조정할 수 있습니다.
현재 Python에는 완전한 테스트 사례, 완전한 코드 주석 및 완전한 문서를 갖춘 더 나은 개체 풀링 라이브러리가 없기 때문입니다. 동시에 현재 주류 개체 풀링 라이브러리에는 스마트 자동 재활용 메커니즘이 없습니다.
Pond는 커뮤니티에서 공개한 완전한 테스트 사례, 90%가 넘는 적용률, 완전한 코드 주석 및 완전한 문서를 갖춘 Python의 최초 개체 풀링 라이브러리일 수 있습니다.
Pond는 Apache Commons Pool, Netty Recycler, HikariCP 및 Caffeine에서 영감을 받아 이들 중 많은 장점을 통합했습니다.
둘째, Pond는 아주 작은 메모리 공간에서 대략적인 계산법을 사용하여 각 개체 풀의 사용 빈도를 계산하고 자동으로 재활용합니다.
트래픽이 상대적으로 무작위적이고 평균적인 경우 기본 전략과 가중치를 사용하면 메모리 사용량을 48.85% 줄일 수 있으며 차용 적중률은 100%입니다.
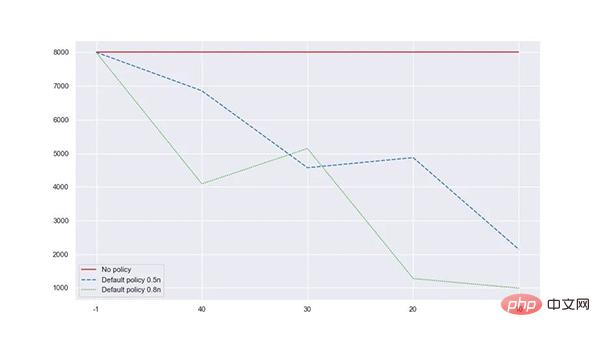
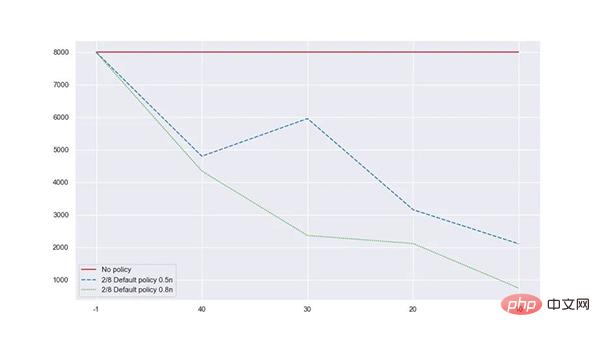
트래픽이 2/8 법칙에 더 부합할 때 기본 전략과 가중치를 사용하면 메모리 사용량을 45.7% 줄일 수 있으며 차용 적중률은 100%입니다.
Pond는 주로 FactoryDict, Counter, PooledObjectTree 및 별도의 재활용 스레드로 구성됩니다.
Pond를 사용하려면 객체 팩토리 PooledObjectFactory를 구현해야 합니다. PooledObjectFactory는 객체 생성, 초기화, 파괴, 확인 및 기타 작업을 제공하며 Pond에서 호출됩니다.
따라서 객체 풀이 완전히 다른 객체 저장을 지원하기 위해 Pond는 사전을 사용하여 각 팩토리 클래스의 이름과 구현하는 팩토리 클래스의 인스턴스화된 객체를 기록합니다.
각 PooledObjectFactory에는 객체 생성, 객체 파괴, 객체가 여전히 사용 가능한지 확인, 객체 재설정의 네 가지 기능이 있어야 합니다.
특별한 점은 Pond가 객체의 자동 재설정을 지원한다는 점입니다. 일부 시나리오에서는 오염을 방지하기 위해 객체에 먼저 값을 할당하고 전달한 다음 전달한 후 재활용해야 하는 상황이 있을 수 있기 때문입니다. 이 시나리오에서는 이 기능을 구현하는 것이 좋습니다.
Counter는 대략적인 카운터를 저장합니다.
PooleedObjectTree는 사전입니다. 각 키는 선입 선출 대기열에 해당합니다.
각 대기열에는 여러 PooleedObject가 있습니다. PooledObject는 생성 시간, 마지막 대출 시간, 실제 필요한 객체를 저장합니다.
Pond의 대여 및 재활용은 모두 스레드로부터 안전합니다. Python의 큐 모듈은 멀티스레드 프로그래밍에 적합한 FIFO(선입선출) 데이터 구조를 제공합니다. 생산자 스레드와 소비자 스레드 간에 메시지나 기타 데이터를 안전하게 전달하는 데 사용할 수 있습니다.
잠금은 호출자가 처리하며 모든 다중 스레드는 동일한 Queue 인스턴스를 사용하여 안전하고 쉽게 작업할 수 있습니다. Pond의 대여와 재활용은 모두 대기열에서 수행되므로 기본적으로 스레드로부터 안전한 것으로 간주될 수 있습니다.
Pond를 사용하여 객체를 빌려줄 때 먼저 빌려주려는 객체 유형이 PooledObjectTree에 이미 있는지 확인합니다. 존재하는 경우 이 객체의 객체 풀이 비어 있는지 확인합니다. . 그렇다면 비어 있으면 새 항목이 생성됩니다.
개체 풀에 초과 개체가 있는 경우 대기열을 사용하여 개체를 팝업하고 이 개체가 사용 가능한지 확인합니다. 사용할 수 없는 경우 해당 Factory가 자동으로 호출되어 객체를 정리하고 파괴합니다. 동시에 Python의 GC 카운트가 지워져 GC에서 더 빨리 재활용될 수 있고 다음 항목이 사용됩니다. 사용할 수 있을 때까지 계속해서.
이 개체를 사용할 수 있으면 직접 반환됩니다. 물론, 개체 풀에서 개체를 꺼내거나 새 개체를 생성하면 Counter를 사용하여 개수를 증가시킵니다.
객체를 재활용할 때 대상 객체 풀이 존재하는지 확인합니다. 객체 풀이 가득 차면 반환할 객체가 자동으로 반환됩니다. 파괴됨.
그런 다음 객체가 너무 오랫동안 대여되었는지 확인합니다. 구성된 최대 시간을 초과하는 경우에도 삭제됩니다.
자동 재활용은 가끔씩 실행되며 기본값은 300초입니다. 자주 사용하지 않는 개체 풀의 개체를 자동으로 정리합니다.
먼저 Pond 라이브러리를 설치하고 프로젝트에서 참조할 수 있습니다.
pip install pondpond
from pond import Pond, PooledObjectFactory, PooledObject
먼저 넣으려는 객체 유형에 대한 팩토리 클래스를 선언해야 합니다. 예를 들어 아래 예에서는 풀링된 객체가 Dog가 되기를 원하므로 먼저 PooledDogFactory 클래스를 선언하고 PooledObjectFactory를 구현합니다.
class Dog: name: str validate_result:bool = True class PooledDogFactory(PooledObjectFactory): def creatInstantce(self) -> PooledObject: dog = Dog() dog.name = "puppy" return PooledObject(dog) def destroy(self, pooled_object: PooledObject): del pooled_object def reset(self, pooled_object: PooledObject) -> PooledObject: pooled_object.keeped_object.name = "puppy" return pooled_object def validate(self, pooled_object: PooledObject) -> bool: return pooled_object.keeped_object.validate_result
그런 다음 Pond 객체를 생성해야 합니다.
pond = Pond(borrowed_timeout=2, time_between_eviction_runs=-1, thread_daemon=True, eviction_weight=0.8)
Pond는 다음을 나타내는 일부 매개변수를 전달할 수 있습니다.
borrowed_timeout: 단위는 초이며, 대여된 객체의 최대 기간이며, 기간을 초과하는 객체는 반환 시 자동으로 삭제되며 개체 풀에 포함되지 않습니다.
time_between_eviction_runs: 단위는 초, 자동 재활용 간격입니다.
thread_daemon: 데몬 스레드, True이면 기본 스레드가 닫힐 때 자동으로 재활용되는 스레드가 닫힙니다.
eviction_weight: 자동 재활용 중 가중치에 최대 사용 빈도를 곱합니다. 사용 빈도가 이 값보다 작은 개체 풀의 개체는 정리 단계로 들어갑니다.
인스턴스화된 팩토리 클래스:
factory = PooledDogFactory(pooled_maxsize=10, least_one=False)
PooledObjectFactory를 상속하는 모든 것에는 pooled_maxsize 및 최소_1 매개변수를 전달할 수 있는 자체 생성자가 있습니다.
pooled_maxsize: 이 팩토리 클래스에서 생성된 개체 풀에 배치할 수 있는 최대 개체 수입니다.
least_one: True인 경우 자동 정리를 시작할 때 이 팩토리 클래스에서 생성된 개체의 개체 풀은 최소한 하나의 개체를 유지합니다.
Pond에 이 팩토리 객체를 등록합니다. 기본적으로 팩토리의 클래스 이름은 PooledObjectTree의 키로 사용됩니다.
pond.register(factory)
물론 이름을 사용자 정의할 수도 있으며 이름은 PooledObjectTree의 키:
pond.register(factory, name="PuppyFactory")
등록이 성공적으로 완료되면 Pond는 객체 풀이 채워질 때까지 공장에서 설정된 pooled_maxsize에 따라 자동으로 객체 생성을 시작합니다.
객체 대여 및 반환:
pooled_object: PooledObject = pond.borrow(factory) dog: Dog = pooled_object.use() pond.recycle(pooled_object, factory)
물론 이름으로 객체를 빌리고 반환할 수 있습니다:
pooled_object: PooledObject = pond.borrow(name="PuppyFactory") dog: Dog = pooled_object.use() pond.recycle(pooled_object, name="PuppyFactory")
객체 풀 완전히 지우기:
pond.clear(factory)
이름으로 객체 풀 정리:
pond.clear(name="PuppyFactory")
일반적으로 귀하만 위의 방법을 사용해야 하며 객체 생성 및 객체 재활용은 완전 자동입니다.
위 내용은 최신 오픈 소스: 효율적인 Python 범용 개체 풀링 라이브러리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



