
실제 작업 프로젝트에서 캐시는 높은 동시성, 고성능 아키텍처의 핵심 구성 요소가 되었습니다. 그렇다면 왜 Redis를 캐시로 사용할 수 있을까요? 우선 캐시의 두 가지 주요 특징으로 사용할 수 있습니다.
계층 시스템에서는 메모리/CPU의 액세스 성능이 좋고,
캐시 데이터가 포화되어 있고 좋은 데이터가 있습니다. 제거 메커니즘
Redis는 당연히 이 두 가지 특성을 가지고 있으므로 Redis는 메모리 작업을 기반으로 하며 완전한 데이터 제거 메커니즘을 갖추고 있어 캐시 구성 요소로 매우 적합합니다.
그 중 메모리 연산 기준으로 용량은 32~96GB까지 가능하고, 연산 시간은 평균 100ns로 연산 효율이 높다. 또한 Redis 4.0 이후에는 8가지 유형의 데이터 제거 메커니즘이 있으므로 Redis를 캐시로 다양한 시나리오에 적용할 수 있습니다.
그러면 Redis 캐시에 데이터 제거 메커니즘이 필요한 이유는 무엇일까요? 8가지 데이터 제거 메커니즘은 무엇입니까?
Redis 캐시는 메모리 기반으로 구현되므로 캐시 용량이 제한됩니다. 캐시가 가득 차면 Redis는 어떻게 처리해야 할까요?
Redis 캐시가 가득 차면 Redis는 캐시 서비스를 다시 사용할 수 있도록 특정 제거 규칙을 통해 일부 데이터를 선택하고 삭제하는 캐시 데이터 제거 메커니즘이 필요합니다. 그렇다면 Redis는 데이터를 삭제하기 위해 어떤 제거 전략을 사용합니까?
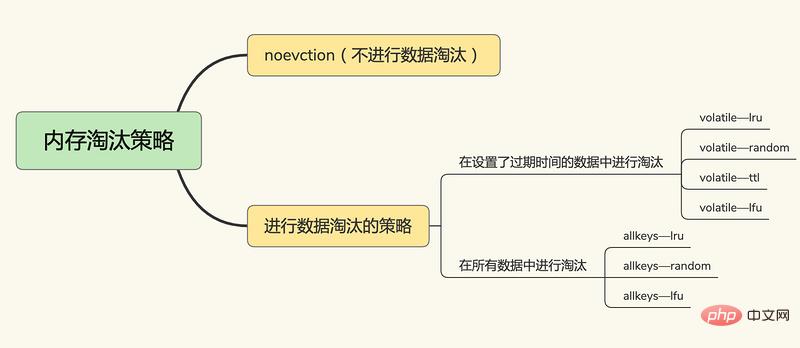
Redis 4.0 이후에는 6+2 Redis 캐시 제거 전략이 있으며 이는 세 가지 범주로 나뉩니다.
데이터 제거 없음
noeviction, 데이터 제거 없음, 캐시가 가득 차면 Redis는 그렇지 않습니다. 서비스를 직접 제공하면 오류가 반환됩니다.
만료 시간을 설정하는 키-값 쌍에서
휘발성-random, 만료 시간을 설정하는 키-값 쌍에서
휘발성-ttl을 무작위로 삭제합니다. 만료 시간을 설정하는 키-값 쌍 네, 만료 날짜가 빠를수록 빨리 삭제됩니다.
휘발성-lru, 만료 시간이 있는 키-값 쌍을 필터링하는 LRU(최근 최소 사용) 알고리즘 기반, 가장 최근에 사용된 원칙을 기반으로 데이터 필터링
휘발성-lfu, LFU( 가장 적게 사용되는) 알고리즘 만료 시간이 설정된 키-값 쌍과 가장 적게 사용되는 키-값 쌍을 선택하여 데이터를 필터링합니다.
모든 키-값 쌍에서
allkeys-random, 모든 키-값 쌍에서 데이터를 무작위로 선택 및 삭제
allkeys-lru, LRU 알고리즘을 사용하여 모든 데이터 간 필터링
allkeys-lfu는 LFU 알고리즘을 사용하여 모든 데이터를 필터링합니다
Note: LRU(Least Recent Used) 알고리즘, LRU는 양방향 연결 목록, 연결 목록 헤드 및 tail은 각각 MRU 끝과 LRU 끝을 나타내며, 각각 가장 최근에 사용된 데이터와 가장 최근에 가장 적게 사용된 데이터를 나타냅니다.
실제 구현에서 LRU 알고리즘은 연결된 목록을 사용하여 캐시된 모든 데이터를 관리해야 하므로 추가 공간 오버헤드가 발생합니다. 또한 데이터에 접근할 때 연결된 목록의 MRU로 데이터를 이동해야 하므로 많은 양의 데이터에 접근할 경우 연결 목록 이동 작업이 많이 발생하므로 시간이 많이 걸리고 Redis 캐시 성능이 저하됩니다. .
그 중 LRU와 LFU는 Redis의 객체 구조인 redisObject의 lru 및 refcount 속성을 기반으로 구현됩니다.
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
// 引用计数 * and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;Redis의 LRU는 redisObject의 lru를 사용하여 마지막 액세스 시간을 기록하고 무작위로 선택합니다. 구성된 매개변수 수 maxmemory-samples 후보 세트로 lru 속성 값이 가장 작은 데이터를 선택하여 제거합니다.
실제 프로젝트에서 데이터 제거 메커니즘을 선택하는 방법은 무엇입니까?
가장 최근에 액세스한 데이터를 캐시에 보관하여 애플리케이션 액세스 성능을 향상시키려면 allkeys-lru 알고리즘을 선호하세요.
상위 데이터는 휘발성-lru 알고리즘을 사용합니다. 다른 데이터는 만료 시간을 설정하며 LRU 규칙에 따라 필터링됩니다.
Redis 캐시 제거 메커니즘을 이해한 후, Redis가 캐시로 가지고 있는 모드는 몇 개인지 살펴볼까요?
Redis 캐시 모드는 쓰기 요청 수신 여부에 따라 읽기 전용 캐시와 읽기-쓰기 캐시로 나눌 수 있습니다.
읽기 전용 캐시: 읽기 작업만 처리하고 모든 업데이트 작업은 데이터베이스에 있습니다. , 따라서 데이터가 손실될 위험이 없습니다.
캐시 제외 모드
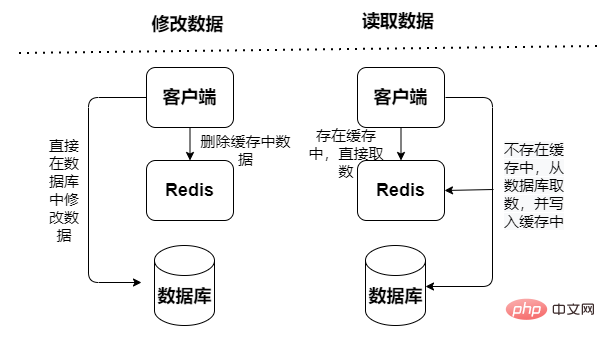
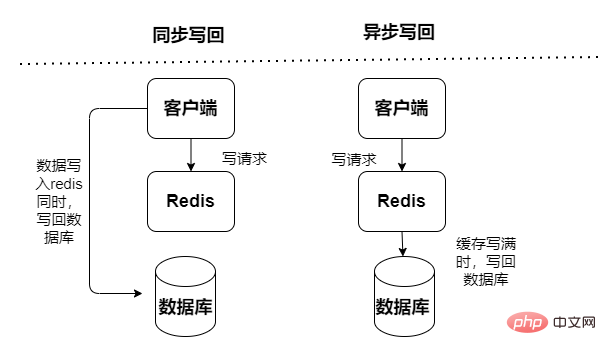
캐시 읽기 및 쓰기, 읽기 및 쓰기 작업은 캐시에서 수행되며 가동 중지 시간이 실패하면 데이터가 손실됩니다. 데이터베이스에 대한 캐시 다시 쓰기 데이터는 동기식과 비동기식의 두 가지 유형으로 나뉩니다.
동기식: 액세스 성능이 낮으므로 데이터 안정성 보장에 더 중점을 둡니다.
Read-Throug 모드
쓰기 -통과 모드
비동기: 데이터 손실 위험이 있으며 지연 시간이 짧은 액세스 제공에 중점을 둡니다
Write-Behind 모드
Query 데이터는 먼저 캐시에서 데이터를 읽고, 캐시에 없으면 데이터베이스에서 데이터를 읽어 업데이트합니다. 캐시에서는 데이터를 업데이트할 때 데이터베이스의 데이터가 먼저 업데이트된 다음 캐시의 데이터가 무효화됩니다.
그리고 캐시 제외 모드에는 동시성 위험이 있습니다. 읽기 작업에서 캐시가 누락된 다음 데이터를 가져오기 위해 데이터베이스가 쿼리되지만 동시에 캐시에 저장되지 않습니다. 업데이트 쓰기 작업은 캐시를 무효화한 다음 읽기 작업이 다시 실행되어 쿼리가 데이터를 캐시에 로드하므로 캐시된 더티 데이터가 생성됩니다.
데이터 쿼리 및 업데이트 데이터 모두 캐시 서비스에 직접 액세스합니다. 캐시 서비스는 데이터를 데이터베이스에 동기식으로 업데이트합니다. 더티 데이터가 발생할 가능성은 낮지만 캐시에 크게 의존하고 캐시 서비스의 안정성에 대한 요구 사항이 더 높습니다. 그러나 동기식 업데이트는 성능 저하로 이어집니다.
데이터 쿼리와 데이터 업데이트 모두 캐시 서비스에 직접 액세스하지만 캐시 서비스는 비동기 방식을 사용하여 (비동기 작업을 통해) 데이터베이스에 데이터를 업데이트합니다. 빠르고 효율적이지만 데이터 일관성이 상대적으로 열악하고 데이터 손실이 있을 수 있으며 구현 논리도 상대적으로 복잡합니다.
실제 프로젝트 개발 중에 실제 비즈니스 시나리오 요구 사항에 따라 캐시 모드를 선택하세요. 위 내용을 이해한 후 애플리케이션에서 Redis Cache를 사용해야 하는 이유는 무엇입니까?
애플리케이션에서 Redis 캐시를 사용하면 시스템 성능과 동시성이 향상될 수 있으며 이는 주로
에 반영됩니다. 고성능: 메모리 쿼리, KV 구조, 간단한 논리 연산 기반
높은 동시성: MySQL은 초당 약 2000개만 지원할 수 있습니다. 요청, Redis는 쉽게 초당 1W를 초과합니다. 80% 이상의 쿼리가 캐시를 통과하도록 허용하고 20% 미만의 쿼리가 데이터베이스를 통과하도록 허용하면 시스템 처리량을 크게 향상시킬 수 있습니다
Redis 캐시를 사용하면 시스템 성능이 크게 향상될 수 있지만, 캐시를 사용할 때 몇 가지 문제가 있습니다. 예를 들어 캐시와 데이터베이스 간의 양방향 불일치, 캐시 사태 등이 있습니다. 이러한 문제를 해결하는 방법은 무엇입니까?
캐시를 사용할 때 주로 다음과 같은 문제가 발생합니다.
캐시와 데이터베이스 이중 쓰기 간의 불일치
캐시 사태: Redis 캐시는 많은 수의 애플리케이션을 처리할 수 없습니다. 요청, 전송 데이터베이스 계층에 대한 압력 급증
캐시 침투: Redis 캐시 및 데이터베이스에 액세스 데이터가 존재하지 않아 대량의 액세스 침투 캐시가 직접 전송됩니다.
캐시 고장: 캐시가 고주파수 핫 데이터를 처리할 수 없어 데이터베이스에 대한 고주파수 액세스가 발생하여 데이터베이스 계층에 대한 압력이 급증합니다.
읽기 전용 캐시(Cache Aside 모드)
For 읽기 전용 캐시(Cache Aside 모드) , 모든 읽기 작업이 캐시에서 발생합니다. , 데이터 불일치는 삭제 작업에서만 발생합니다(새 추가 작업은 데이터베이스에서만 처리되므로 새 작업은 발생하지 않음). 삭제 작업이 발생하면 캐시는 데이터를 유효하지 않은 것으로 표시하고 데이터베이스를 업데이트합니다. 따라서 데이터베이스를 업데이트하고 캐시된 값을 삭제하는 과정에서 두 작업의 실행 순서에 관계없이 하나의 작업이 실패하면 데이터 불일치가 발생하게 됩니다.
위 내용은 자바 웹 인스턴스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



