

Java 분산 Kafka 메시지 큐 인스턴스 분석

소개
Apache Kafka는 분산 게시-구독 메시징 시스템입니다. kafka 공식 웹사이트에서 kafka를 정의하면 분산 게시-구독 메시징 시스템입니다. 원래 LinkedIn에서 개발되었으며 2010년 Apache Foundation에 기부되어 최고의 오픈 소스 프로젝트가 되었습니다. Kafka는 빠르고 확장 가능하며 본질적으로 분산, 분할 및 복제 가능한 커밋 로그 서비스입니다.
참고: Kafka는 JMS 사양()을 따르지 않으며 게시 및 구독 통신 방법만 제공합니다.
Kafka 핵심 관련 이름
Broker: Kafka 노드, Kafka 노드는 브로커, 여러 브로커가 Kafka 클러스터를 형성할 수 있음
Topic: 메시지 유형, 메시지가 저장되는 디렉터리가 주제입니다. , 페이지 조회 로그, 클릭 로그 등이 토픽 형태로 존재할 수 있습니다. Kafka 클러스터는 동시에 여러 토픽의 배포를 담당할 수 있습니다.
massage: Kafka의 가장 기본적인 전달 개체입니다.
파티션: 주제의 물리적 그룹화입니다. 주제는 여러 파티션으로 나눌 수 있으며 각 파티션은 순서가 지정된 대기열입니다. 파티셔닝은 Kafka에서 구현되며 브로커는 지역을 나타냅니다.
파티션은 물리적으로 여러 세그먼트로 구성되며 각 세그먼트는 메시지 정보를 저장합니다
Producer: 생산자, 메시지를 생성하고 이를 주제로 보냅니다
Consumer: 소비자, 주제를 구독하고 메시지를 소비합니다. 스레드로 소비
소비자 그룹: 소비자 그룹, 소비자 그룹에는 여러 소비자가 포함됨
오프셋: 오프셋, 메시지 파티션에서 메시지의 인덱스 위치로 이해됨
주제와 대기열의 차이점 :
Queue는 선입선출 원칙을 따르는 데이터 구조입니다
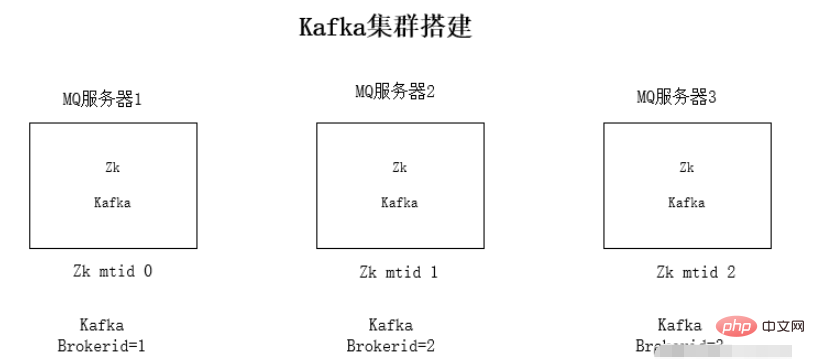
kafka 클러스터 설치
각 서버에 jdk1.8 환경 설치
Zookeeper 클러스터 환경 설치
kafka 설치 클러스터 환경
실행 환경 테스트
jdk 환경 및 Zookeeper 설치에 대해서는 여기서 자세히 설명하지 않습니다.
Kafka가 Zookeeper에 의존하는 이유: Kafka는 전체 클러스터를 쉽게 확장할 수 있도록 Zookeeper의 mq 정보를 저장하기 위해 서로를 감지하는 데 사용됩니다.
kafka 클러스터 설치 단계:
1. kafka의 압축 패키지를 다운로드합니다.
2. 설치 패키지의 압축을 풉니다.
tar -zxvf kafka_2.11-1.0.0.tgz
3. .properties
구성 파일 수정 내용:
zookeeper 연결 주소:
zookeeper.connect=192.168.1.19:2181zookeeper.connect=192.168.1.19:2181监听的ip,修改为本机的ip
listeners=PLAINTEXT://192.168.1.19:9092kafka的brokerid,每台broker的id都不一样
broker.id=0
4、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
kafka使用
kafka文件存储
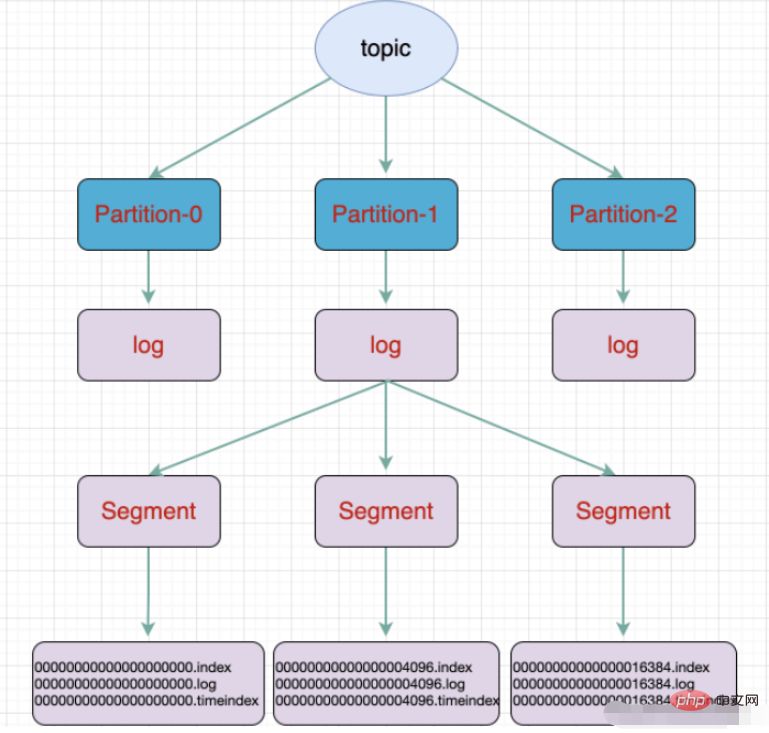
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
 듣는 IP가 로컬 IP로 변경됩니다
듣는 IP가 로컬 IP로 변경됩니다listeners =PLAINTEXT://192.168.1.19:9092
broker.id=0- 4. 카프카를 순차적으로 시작합니다.
-
./kafka-server-start.sh -daemon config/server.propertieskafka는 - kafka 파일 저장소를 사용합니다. 주제는 논리적 개념이고 파티션은 물리적 개념을 기반으로 합니다. 위에서 각 파티션은 로그 파일에 해당하며, 로그 파일에는 생산자가 생성한 데이터가 저장됩니다. 생산자에 의해 생성된 데이터는 로그 파일의 끝에 지속적으로 추가됩니다. 로그 파일이 너무 커서 데이터 위치 지정의 비효율성을 방지하기 위해 Kafka는 각 파티션을 여러 세그먼트로 나누는 샤딩 및 인덱싱 메커니즘을 채택합니다. 각 세그먼트에는 ".index" 파일, ".log" 파일 및 .timeindex 파일이 포함됩니다. 이러한 파일은 폴더에 있으며 폴더의 명명 규칙은 주제 이름 + 파티션 번호입니다.
- 예: 명령을 실행하여 세 개의 영역으로 나누어지고 세 개의 브로커에 저장되는 새 주제를 생성합니다.
./kafka-topics.sh --create --zookeeper localhost:2181 --replication -factor 1 - -partitions 3 --topic kaico
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies># kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}위 내용은 Java 분산 Kafka 메시지 큐 인스턴스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7672
7672
 15
1393
52
1206
24
91
11
73
19
15
1393
52
1206
24
91
11
73
19


 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
