
데이터 정규화는 차원을 통합하고 작은 데이터가 삼켜지는 것을 방지할 수 있는 딥 러닝 데이터 전처리에서 매우 중요한 단계입니다.
정규화는 모든 데이터를 [0,1] 또는 [-1,1] 사이의 숫자로 변환하는 것입니다. 그 목적은 각 차원의 데이터 간의 차이를 없애는 것입니다. 차이는 입력 데이터와 출력 데이터 간의 크기 차이가 크기 때문에 네트워크 예측 오류가 너무 커지는 것을 방지합니다.
후속 데이터 처리의 편의를 위해 정규화를 통해 불필요한 수치 문제를 피할 수 있습니다.
프로그램 실행 시 더 빠르게 수렴하기 위해
차원을 통일하세요. 샘플 데이터에 대한 평가 기준이 다르기 때문에 차원화하고 평가 기준을 통일해야 합니다. 이는 애플리케이션 수준의 요구 사항으로 간주됩니다.
뉴런 포화를 피하세요. 즉, 뉴런의 활성화가 0 또는 1에 가까울 때 이러한 영역에서는 기울기가 거의 0이므로 역전파 과정에서 로컬 기울기가 0에 가까워지며 이는 네트워크에 매우 불리합니다. 훈련.
출력 데이터의 작은 값이 삼켜지지 않도록 하세요.
선형 정규화는 최소-최대 정규화라고도 하며, 는 원본 데이터의 선형 변환으로, 데이터 값을 [0 사이로 변환합니다. ,1].
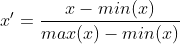
차이 표준화는 원본 데이터에 존재하는 관계를 유지하며 차원 및 데이터 값 범위의 영향을 제거하는 가장 간단한 방법입니다. 코드는 다음과 같이 구현됩니다.
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x적용 범위: 수치가 상대적으로 밀집된 상황에 더 적합
단점:
max와 min이 불안정하면 정규화된 결과를 불안정하게 만들기 쉽습니다. , 후속 사용이 덜 효과적입니다. 값 범위가 현재 속성[최소, 최대]을 초과하면 시스템에서 오류를 보고하게 됩니다. 최소값과 최대값을 다시 결정해야 합니다.
값 세트의 특정 값이 매우 큰 경우 정규화된 값은 0에 가까워지며 크게 다르지 않습니다. (1,1.2,1.3,1.4,1.5,1.6,10 등) 이 데이터 세트입니다.
Z-Score 정규화는 표준편차 정규화라고도 하며, 처리된 데이터의 평균은 0이고 표준편차는 1입니다. 변환 공식은 다음과 같습니다.
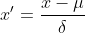
여기서 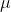 는 원본 데이터의 평균이고,
는 원본 데이터의 평균이고, 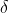 는 원본 데이터의 표준 편차이며, 이는 가장 일반적으로 사용되는 표준화 공식입니다.
는 원본 데이터의 표준 편차이며, 이는 가장 일반적으로 사용되는 표준화 공식입니다.
이 방법은 원본 데이터의 평균과 표준 편차를 제공합니다. 원본 데이터(표준편차)는 데이터를 표준화합니다. 처리된 데이터는 표준 정규 분포, 즉 평균이 0이고 표준 편차가 1입니다. 여기서 핵심은 복합 표준 정규 분포입니다.
코드는 다음과 같이 구현됩니다.
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x이 메서드가 전달됩니다. 속성 값의 소수 자릿수를 이동하고 속성 값을 [-1,1] 사이로 매핑합니다. 이동되는 소수 자릿수는 속성 값의 최대 절대값에 따라 달라집니다. 변환 공식은 다음과 같습니다.
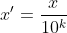
이 방법에는 로그, 지수, 탄젠트가 포함됩니다.
적용 범위: 상대적으로 큰 데이터 분석 시나리오에서 자주 사용되며 일부 값은 매우 크고 일부는 매우 큽니다. 작게, 원래 값을 매핑합니다.
과거 신경망 훈련에서는 입력 계층 데이터만 정규화되었지만 중간 계층에서는 정규화가 없었습니다. 입력 데이터를 정규화했지만, 입력 데이터가 이와 같이 행렬 곱셈을 거친 후에는 데이터 분포가 크게 변할 가능성이 높으며 네트워크의 레이어 수가 계속해서 깊어집니다. 데이터 분포는 점점 더 바뀔 것입니다. 따라서 훈련 효과를 향상시키는 신경망 중간 계층의 이러한 정규화 프로세스를 배치 정규화(BN)라고 합니다
1) 이전 레이어의 출력 데이터의 평균 계산: 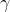
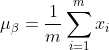
그 중 m은 이 훈련 샘플 배치의 크기입니다.
2) 이전 레이어의 출력 데이터의 표준편차를 계산합니다.
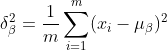
3)
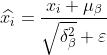
을 얻기 위한 정규화 과정 수식에서  는 분모가 0이 되는 것을 방지하고 작은 값을 추가하는 것입니다. 0값에 가깝습니다.
는 분모가 0이 되는 것을 방지하고 작은 값을 추가하는 것입니다. 0값에 가깝습니다.
4) 재구성, 위 정규화 프로세스 후에 얻은 데이터를 재구성하고 다음을 얻습니다.
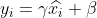
여기서 , 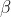 은 학습 가능한 매개변수입니다.
은 학습 가능한 매개변수입니다.
위 내용은 Python의 일반적인 정규화 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



