

Python에서 동적 배열 구현: 초보자부터 숙련자까지

1부 Python 시퀀스 유형의 본질에 대해 이야기해 보겠습니다.
이 블로그에서는 Python의 다양한 "시퀀스" 클래스와 일반적으로 사용되는 세 가지 내장 데이터 구조(리스트 및 튜플) 및 문자열 클래스의 특성에 대해 이야기해 보겠습니다. (str).
알았는지 모르겠지만 이러한 클래스는 모두 여러 데이터 요소를 저장하는 데 사용할 수 있습니다. 주요 기능은 다음과 같습니다. 예를 들어 Seq[i] 구문을 사용합니다. 실제로 위의 각 클래스는 배열과 같은 간단한 데이터 구조로 표현됩니다.
그러나 Python에 익숙한 독자라면 이 세 가지 데이터 구조에 몇 가지 차이점이 있다는 것을 알 수 있습니다. 예를 들어 튜플과 문자열은 수정할 수 없지만 목록은 수정할 수 있습니다.
1. 컴퓨터 메모리의 배열 구조
컴퓨터 아키텍처에서 우리는 컴퓨터 메인 메모리가 비트 정보로 구성된다는 것을 알고 있습니다. 이러한 비트는 일반적으로 더 큰 단위로 분류되며 이러한 단위는 정확한 시스템 아키텍처에 따라 달라집니다. 일반적인 단위는 8비트에 해당하는 바이트입니다.
컴퓨터 시스템에는 엄청난 양의 저장 바이트가 있는데, 우리 정보 중 어떤 바이트가 존재하는지 어떻게 알 수 있나요? 정답은 누구나 일반적으로 알고 있는 저장 주소입니다. 저장 주소에 따라 주 메모리의 모든 바이트에 효과적으로 액세스할 수 있습니다. 실제로 저장소의 각 바이트는 주소 역할을 하는 고유한 이진수와 연결되어 있습니다. 아래 그림과 같이 각 바이트에는 저장 주소가 할당됩니다.
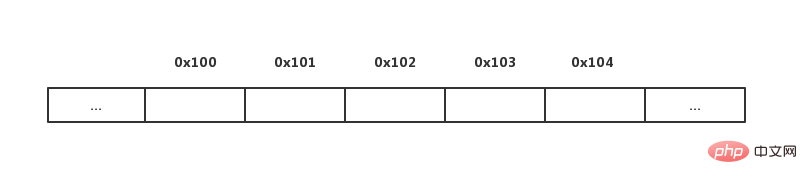
일반적으로 프로그래밍 언어는 식별자와 관련 값이 저장되는 주소 간의 관계를 기록합니다. 예를 들어, 식별자 x가 메모리의 특정 값과 연관될 수 있다고 선언하면 식별자 y는 다른 값과 연관될 수 있습니다. 관련 변수 그룹은 컴퓨터 메모리의 연속 영역에 차례로 저장될 수 있습니다. 우리는 이 접근 방식을 배열이라고 부릅니다.
Python의 예를 살펴보겠습니다. 텍스트 문자열 HELLO는 순서가 지정된 문자의 열로 저장됩니다. 문자열의 각 유니코드 문자에는 2바이트의 저장 공간이 필요하다고 가정합니다. 맨 아래 숫자는 문자열의 인덱스 값입니다.
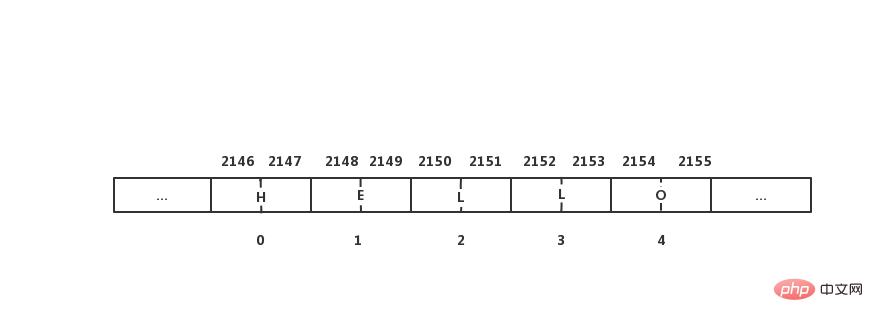
각 항목을 지정하기 위해 특정 인덱스로 여러 변수를 구성하지 않고도 배열이 여러 값을 저장할 수 있다는 것을 알 수 있으며, 거의 모든 프로그래밍 언어(예: C, Java, C#, C++)에서 사용됩니다. Python에는 있지만 Python에는 더 많은 장점이 있습니다. Python이 목록을 작성할 때 친숙한 독자는 배열이나 목록의 크기를 미리 정의할 필요가 없다는 것을 알 수 있습니다. 반대로 Python에서는 목록이 동적 특성을 가지며 원하는 데이터 요소를 지속적으로 추가할 수 있습니다. 목록. 다음으로 Python 목록에 대한 지식을 살펴보겠습니다(이미 익숙한 독자는 빠르게 찾아보거나 건너뛸 수 있습니다).
2. Python 목록
Python 목록 작업
- 목록 생성을 위한 구문 형식:
[ele1, ele2, ele3, ele4, ...]
- 튜플 생성을 위한 구문 형식:
(ele1, ele2, ele3, ele4, ...)
튜플은 고정되어 있으므로 튜플은 목록보다 메모리 공간 효율적이므로 남은 공간이 있는 동적 배열을 만들 필요가 없습니다.
먼저 Python IDE에서 목록을 생성한 다음 목록의 내장 작업을 대략 살펴보겠습니다. 먼저 test_list라는 목록을 생성한 다음 요소를 수정(삽입 또는 삭제)하고,
>>> test_list = []# 创建名为test_list的空列表
>>> test_list.append("Hello")
>>> test_list.append("World")
>>> test_list
['Hello', 'World']
>>> test_list = ["Hello", "Array", 2019, "easy learning", "DataStructure"]# 重新给test_list赋值
>>> len(test_list)# 求列表的长度
5
>>> test_list[2] = 1024# 修改列表元素
>>> test_list
['Hello', 'Array', 1024, 'easy learning', 'DataStructure']
>>>
>>> test_list.insert(1, "I love")# 向列表中指定位置中插入一个元素
>>> test_list
['Hello', 'I love', 'Array', 1024, 'easy learning', 'DataStructure']
>>> test_list.append(2020)# 向列表末尾增加一个元素
>>> test_list
['Hello', 'I love', 'Array', 1024, 'easy learning', 'DataStructure', 2020]
>>>
>>> test_list.pop(1)# 删除指定位置的元素
'I love'
>>> test_list.remove(2020)# 删除指定元素
>>>
>>> test_list.index('Hello')# 查找某个元素的索引值
0
>>> test_list.index('hello')# 如果查找某个元素不在列表中,返回ValueError错误
Traceback (most recent call last):
File "<pyshell#11>", line 1, in <module>
test_list.index('hello')
ValueError: 'hello' is not in list
>>>
>>> test_list.reverse()# 反转整个列表
>>> test_list
['DataStructure', 'easy learning', 2019, 'Array', 'Hello']
>>> test_list.clear()# 清空列表
>>> test_list
[]위의 코드를 보면 목록의 추가, 삭제, 수정, 확인 등의 관련 작업을 볼 수 있습니다. 이미 매우 강력한 내장 메서드도 있습니다. 여기서는 보여주지 않고 독자들이 스스로 발견하고 경험하도록 남겨둡니다.
Python 목록의 메모리 할당에 대한 기본 사항
그래서 코딩 연습을 통해 이 추가 공간 데모와 메모리에 있는 배열의 실제 크기와 주어진 크기 사이의 관계를 살펴보겠습니다.
Jupyter Notebook으로 이동하여 연습해 보세요. 또는 원하는 편집기나 개발 환경을 사용하세요. 아래에 작성된 코드를 복사하세요.
# 导入sys模块能方便我们使用gestsizeof函数
import sys
# set n
n = 20
# set empty list
list = []
for i in range(n):
a = len(list)
# 调用getsizeof函数用于给出Python中存储对象的真实字节数
b = sys.getsizeof(list)
print('Length:{0:3d}; Size of bytes:{1:4d}'.format(a, b))
# Increase length by one
list.append(n)코드를 실행하면 다음 출력을 볼 수 있습니다.
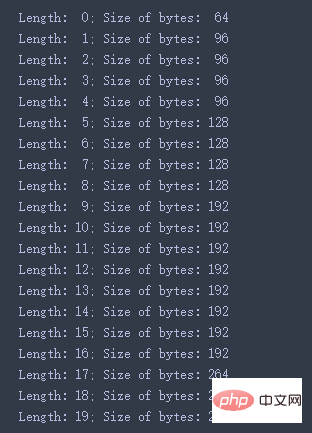
이제 목록의 길이를 늘리면 바이트도 늘어납니다. 분석해 보겠습니다. 길이: 1
위치의 요소가 목록에 채워지면 바이트 수가 64에서 96으로 증가하여 32바이트가 증가합니다. 이 실험은 64비트 시스템에서 실행되었기 때문에 이는 각 메모리 주소가 64비트(즉, 8바이트)임을 의미합니다. 추가 32바이트는 4개의 개체 참조를 저장하기 위해 할당된 배열의 크기입니다. 두 번째, 세 번째, 네 번째 요소를 추가해도 메모리 사용량에는 변화가 없습니다. 바이트 수 96은 4개의 객체에 대한 참조를 제공할 수 있습니다.
96 = 64 + 8 곱하기 4
길이:10
일 때时,字节数从一开始的64跳到192,能存下16个对象的引用,
192 = 64 + 8 times 16
一直到Length: 17
后又开始跳转,所以理论上264个字节数应该可以存下25个对象
264 = 64 + 8 times 25
但因为我们在代码中设置n=20,然后程序就终止了。
我们可以看到Python内置的list类足够智能,知道当需要额外的空间来分配数据时,它会为它们提供额外的大小,那么这究竟是如何被实现的呢?
好吧,答案是动态数组。说到这里,不知道大家学Python列表的时候是不是这样想的——列表很简单嘛,就是list()类、用中括号[]括起来,然后指导书籍或文档上的各类方法append、insert、pop...在各种IDE一顿操作过后,是的我觉得我学会了。
但其实背后的原理真的很不简单,比如我举个例子:A[-1]这个操作怎么实现?列表切片功能怎么实现?如何自己写pop()默认删除列表最右边的元素(popleft删除最左边简单)?...这些功能用起来爽,但真的自己实现太难了(我也还在学习中,大佬们请轻喷!)如果我们能学习并理解,肯定可以加强我们对数组这一结构的理解。
3、动态数组
什么是动态数组
动态数组是内存的连续区域,其大小随着插入新数据而动态增长。在静态数组中,我们需要在分配时指定大小。在定义数组的时候,其实计算机已经帮我们分配好了内存来存储,实际上我们不能扩展数组,因为它的大小是固定的。比如:我们分配一个大小为10的数组,则不能插入超过10个项目。
但是动态数组会在需要的时候自动调整其大小。这一点有点像我们使用的Python列表,可以存储任意数量的项目,而无需在分配时指定大小。
所以实现一个动态数组的实现的关键是——如何扩展数组?当列表list1的大小已满时,而此时有新的元素要添加进列表,我们会执行一下步骤来克服其大小限制的缺点:
- 分配具有更大容量的新数组list2
- 设置list2[i] = list1[i] (i=0,1,2,...,n-1),其中n是该项目的当前编号
- 设置list1 = list2,也就是说,list2正在作为新的数组来引用我们的新列表。
- 然后,只要将新的元素插入(添加)到我们的列表list1即可。
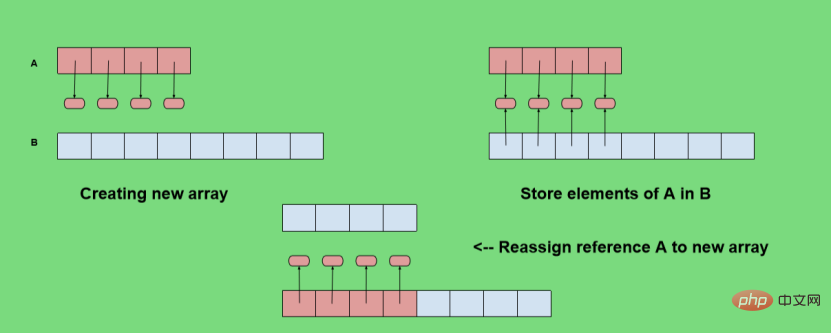
接下来要思考的问题是,新数组应该多大?通常我们得做法是:新数组的大小是已满的旧数组的2倍。我们将在Python中编程实现动态数组的概念,并创建一个简单的代码,很多功能不及Python强大。
实现动态数组的Python代码
在Python中,我们利用ctypes的内置库来创建自己的动态数组类,因为ctypes模块提供对原始数组的支持,为了更快的对数组进行学习,所以对ctypes的知识可以查看官方文档进行学习。关于Python的公有方法与私有方法,我们在方法名称前使用双下划线**__**使其保持隐藏状态,代码如下:
# -*- coding: utf-8 -*-
# @Time: 2019-11-01 17:10
# @Author: yuzhou_1su
# @ContactMe : https://blog.csdn.net/yuzhou_1shu
# @File: DynamicArray.py
# @Software: PyCharm
import ctypes
class DynamicArray:
"""A dynamic array class akin to a simplified Python list."""
def __init__(self):
"""Create an empty array."""
self.n = 0 # count actual elements
self.capacity = 1# default array capacity
self.A = self._make_array(self.capacity)# low-level array
def is_empty(self):
""" Return True if array is empty"""
return self.n == 0
def __len__(self):
"""Return numbers of elements stored in the array."""
return self.n
def __getitem__(self, i):
"""Return element at index i."""
if not 0 <= i < self.n:
# Check it i index is in bounds of array
raise ValueError('invalid index')
return self.A[i]
def append(self, obj):
"""Add object to end of the array."""
if self.n == self.capacity:
# Double capacity if not enough room
self._resize(2 * self.capacity)
self.A[self.n] = obj# Set self.n index to obj
self.n += 1
def _resize(self, c):
"""Resize internal array to capacity c."""
B = self._make_array(c) # New bigger array
for k in range(self.n):# Reference all existing values
B[k] = self.A[k]
self.A = B# Call A the new bigger array
self.capacity = c # Reset the capacity
@staticmethod
def _make_array(c):
"""Return new array with capacity c."""
return (c * ctypes.py_object)()
def insert(self, k, value):
"""Insert value at position k."""
if self.n == self.capacity:
self._resize(2 * self.capacity)
for j in range(self.n, k, -1):
self.A[j] = self.A[j-1]
self.A[k] = value
self.n += 1
def pop(self, index=0):
"""Remove item at index (default first)."""
if index >= self.n or index < 0:
raise ValueError('invalid index')
for i in range(index, self.n-1):
self.A[i] = self.A[i+1]
self.A[self.n - 1] = None
self.n -= 1
def remove(self, value):
"""Remove the first occurrence of a value in the array."""
for k in range(self.n):
if self.A[k] == value:
for j in range(k, self.n - 1):
self.A[j] = self.A[j+1]
self.A[self.n - 1] = None
self.n -= 1
return
raise ValueError('value not found')
def _print(self):
"""Print the array."""
for i in range(self.n):
print(self.A[i], end=' ')
print()测试动态数组Python代码
上面我们已经实现了一个动态数组的类,相信都很激动,接下来让我们来测试一下,看能不能成功呢?在同一个文件下,写的测试代码如下:
def main():
# Instantiate
mylist = DynamicArray()
# Append new element
mylist.append(10)
mylist.append(9)
mylist.append(8)
# Insert new element in given position
mylist.insert(1, 1024)
mylist.insert(2, 2019)
# Check length
print('The array length is: ', mylist.__len__())
# Print the array
print('Print the array:')
mylist._print()
# Index
print('The element at index 1 is :', mylist[1])
# Remove element
print('Remove 2019 in array:')
mylist.remove(2019)
mylist._print()
# Pop element in given position
print('Pop pos 2 in array:')
# mylist.pop()
mylist.pop(2)
mylist._print()
if __name__ == '__main__':
main()测试结果
激动人心的时刻揭晓,测试结果如下。请结合测试代码和数组的结构进行理解,如果由疏漏,欢迎大家指出。
The array length is:5 Print the array: 10 1024 2019 9 8 The element at index 1 is : 1024 Remove 2019 in array: 10 1024 9 8 Pop pos 2 in array: 10 1024 8
Part2总结
通过以上的介绍,我们知道了数组存在静态和动态类型。而在本博客中,我们着重介绍了什么是动态数组,并通过Python代码进行实现。希望你能从此以复杂的方式学会数组。总结发言,其实越是简单的操作,背后实现原理可能很复杂。
위 내용은 Python에서 동적 배열 구현: 초보자부터 숙련자까지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7487
7487
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench는 구성이 올바른 경우 MariadB에 연결할 수 있습니다. 먼저 커넥터 유형으로 "mariadb"를 선택하십시오. 연결 구성에서 호스트, 포트, 사용자, 비밀번호 및 데이터베이스를 올바르게 설정하십시오. 연결을 테스트 할 때는 마리아드 브 서비스가 시작되었는지, 사용자 이름과 비밀번호가 올바른지, 포트 번호가 올바른지, 방화벽이 연결을 허용하는지 및 데이터베이스가 존재하는지 여부를 확인하십시오. 고급 사용에서 연결 풀링 기술을 사용하여 성능을 최적화하십시오. 일반적인 오류에는 불충분 한 권한, 네트워크 연결 문제 등이 포함됩니다. 오류를 디버깅 할 때 오류 정보를 신중하게 분석하고 디버깅 도구를 사용하십시오. 네트워크 구성을 최적화하면 성능이 향상 될 수 있습니다
 MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
생산 환경의 경우 성능, 신뢰성, 보안 및 확장 성을 포함한 이유로 서버는 일반적으로 MySQL을 실행해야합니다. 서버에는 일반적으로보다 강력한 하드웨어, 중복 구성 및 엄격한 보안 조치가 있습니다. 소규모 저하 애플리케이션의 경우 MySQL이 로컬 컴퓨터에서 실행할 수 있지만 자원 소비, 보안 위험 및 유지 보수 비용은 신중하게 고려되어야합니다. 신뢰성과 보안을 높이려면 MySQL을 클라우드 또는 기타 서버에 배포해야합니다. 적절한 서버 구성을 선택하려면 응용 프로그램 부하 및 데이터 볼륨을 기반으로 평가가 필요합니다.
