

gym은 강화 학습 알고리즘을 개발하고 비교하기 위한 툴킷입니다. Python으로 체육관 라이브러리와 하위 시나리오를 설치하는 것은 비교적 간단합니다.
체육관 설치:
pip install gym
자율 주행 모듈을 설치합니다. 여기서는 Edouard Leurent가 github에 게시한 Highway-env 패키지를 사용합니다.
pip install --user git+https://github.com/eleurent/highway-env
6개 장면이 포함되어 있습니다.
자세한 문서는 다음과 같습니다. 여기에서 찾을 수 있습니다:
https://www.php.cn/link/c0fda89ebd645bd7cea60fcbb5960309
설치 후 코드에서 실험할 수 있습니다(고속도로 장면을 예로 들어). :
import gym
import highway_env
%matplotlib inline
env = gym.make('highway-v0')
env.reset()
for _ in range(3):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, done, info = env.step(action)
env.render()
실행 후 시뮬레이터에서 다음 장면이 생성됩니다.
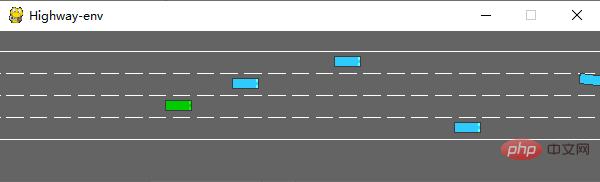
env 클래스에는 구성할 수 있는 많은 매개변수가 있습니다. 자세한 내용은 원본 문서를 참조하세요.
(1) state
highway-env 패키지에 정의된 센서가 없습니다. 차량의 모든 상태(관찰)를 기본 코드에서 읽어서 많은 예비 데이터를 절약합니다. 일하다. 문서에 따르면 상태(ovservations)에는 Kinematics, Grayscale Image 및 Occupancy Grid의 세 가지 출력 방법이 있습니다.
Kinematics
V*F 행렬을 출력합니다. V는 관찰해야 하는 차량 수(자아 차량 자체 포함)를 나타내고, F는 계산해야 하는 특징 수를 나타냅니다. 예:
데이터는 생성 시 기본적으로 정규화되며 값 범위는 [100, 100, 20, 20]입니다. 또한 자아 차량 이외의 차량 속성을 지도의 절대 좌표로 설정할 수도 있습니다. 자아 차량의 상대 좌표.
환경을 정의할 때 기능의 매개변수를 설정해야 합니다.
config =
{
"observation":
{
"type": "Kinematics",
#选取5辆车进行观察(包括ego vehicle)
"vehicles_count": 5,
#共7个特征
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
회색조 이미지
W*H 회색조 이미지를 생성하고, W는 이미지 너비를 나타내고, H는 이미지 높이를 나타냅니다.
점유 그리드
생성 a WHF의 3차원 행렬은 W*H 테이블을 사용하여 자아 차량 주변의 차량 상태를 나타냅니다. 각 그리드에는 F 기능이 포함되어 있습니다.
(2) action
highway-env 패키지의 동작은 연속형과 이산형의 두 가지 유형으로 나뉩니다. 연속 동작은 스로틀 및 조향 각도 값을 직접 정의할 수 있습니다. 개별 동작에는 5가지 메타 동작이 포함됩니다:
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) 보상
Highway-env 패키지는 주차 장면을 제외하고 동일한 보상 기능을 사용합니다.

이 함수는 소스코드에서만 변경할 수 있고, 가중치는 외부 레이어에서만 조정할 수 있습니다.
(주차 장면의 보상 기능은 원본 문서에 포함되어 있습니다.)
DQN 네트워크 구축 데모를 위해 첫 번째 상태 표현 방법인 운동학을 사용합니다. 상태 데이터의 양이 작기 때문에(자동차 5대 * 특징 7개) CNN의 사용을 무시하고 2차원 데이터의 크기 [5,7]을 [1,35]로 직접 변환하면 됩니다. 모델은 35입니다. 출력은 총 5개의 개별 작업 수입니다.
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0# epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
각 부분이 완료된 후 모델을 결합하여 모델을 학습할 수 있습니다. 프로세스는 CARLA와 유사하므로 자세히 설명하지 않겠습니다.
초기화 환경(DQN 클래스만 추가):
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config =
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
훈련 모델:
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300)#随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
코드에 몇 가지 그리기 기능을 추가했고, 실행 과정에서 몇 가지 주요 지표를 파악할 수 있으며, 매번 40회 훈련하고 평균을 계산합니다. 값. ㅋㅋㅋ 증가, 매 에포크 기간이 점차 연장됩니다(충돌이 발생하면 에포크가 즉시 종료됩니다)
요약
시뮬레이터 CARLA와 비교하여 Highway-env 환경 패키지는 게임과 같은 표현을 사용하여 훨씬 더 추상적입니다. 알고리즘이 이상적으로 구현될 수 있도록 데이터 수집 방법, 센서 정확도, 계산 시간 등 실제 문제를 고려하지 않고 가상 환경에서 학습할 수 있습니다. End-to-End 알고리즘 설계 및 테스트에는 매우 친숙하지만, 자동 제어의 관점에서 보면 시작하는 측면이 적고 연구하기에 그다지 유연하지 않습니다. 
위 내용은 자율주행 시스템 구현을 위해 Python을 배워보세요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



