

파이프라인은 Linux 프로세스 간의 통신 방법입니다. 두 프로세스는 공유 메모리 영역을 통해 정보를 전송할 수 있으며 파이프라인의 데이터는 한 방향으로만 흐를 수 있으므로 고정된 쓰기 프로세스와 읽기 프로세스만 있을 수 있습니다. 현재 모든 셸에서 "|"를 사용하여 두 명령을 연결할 수 있습니다. 셸은 프로세스 간 통신의 목적을 달성하기 위해 두 프로세스의 입력과 출력을 파이프로 연결합니다.

이 튜토리얼의 운영 환경: linux7.3 시스템, Dell G3 컴퓨터.
파이프는 UNIX 환경에서 가장 오래된 프로세스 간 통신 방법입니다. 본 글에서는 Linux 환경에서 파이프를 사용하는 방법을 주로 설명합니다.
파이프, 영어는 파이프입니다. 파이프는 Linux 프로세스 간의 통신 방법으로 두 프로세스가 공유 메모리 영역을 통해 정보를 전송할 수 있으며 파이프의 데이터는 한 방향으로만 흐를 수 있으므로 고정된 쓰기 프로세스와 읽기 프로세스만 있을 수 있습니다.
파이프라인의 발명자는 UNIX의 초기 셸 발명자이기도 한 Douglas McElroy입니다. 그는 쉘을 발명한 후 시스템 작업에서 명령을 실행할 때 처리를 위해 한 프로그램의 출력을 다른 프로그램으로 전송해야 하는 경우가 많다는 사실을 발견했습니다. 이 작업은 입력 및 출력 리디렉션을 사용하고 다음과 같은 파일을 추가하여 수행할 수 있습니다. as:
[zorro@zorro-pc pipe]$ ls -l /etc/ > etc.txt [zorro@zorro-pc pipe]$ wc -l etc.txt 183 etc.txt
근데 이건 너무 귀찮은 것 같아요. 그래서 파이프라인이라는 개념이 생겨났습니다. 현재 모든 셸에서 "|"를 사용하여 두 명령을 연결할 수 있습니다. 셸은 프로세스 간 통신의 목적을 달성하기 위해 두 프로세스의 입력과 출력을 연결합니다.
[zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l 183
위의 두 가지 방법을 비교하세요. , 파이프가 본질적으로 파일이라는 것도 이해할 수 있습니다. 이전 프로세스는 파일을 쓰기 모드로 열고 후속 프로세스는 읽기 모드로 엽니다. 이렇게 앞에서 쓰고 나중에 읽으면 의사소통이 이루어진다. 실제로 파이프라인의 설계도 UNIX의 "모든 것이 파일입니다"라는 설계 원칙을 따릅니다. Linux 시스템은 파이프라인을 파일 시스템에 직접 구현하고 VFS를 사용하여 애플리케이션에 대한 운영 인터페이스를 제공합니다.
구현은 파일 형태이지만 파이프라인 자체는 디스크나 기타 외부 저장 공간을 차지하지 않습니다. Linux 구현에서는 메모리 공간을 차지합니다. 따라서 Linux의 파이프는 작동 모드가 파일인 메모리 버퍼입니다.
Linux에는 두 가지 유형의 파이프가 있습니다.
익명 파이프
이름이 지정된 파이프
이 두 파이프는 이름이 지정된 파이프 또는 이름이 지정되지 않은 파이프라고도 합니다. 익명 파이프의 가장 일반적인 형태는 쉘 작업에서 가장 일반적으로 사용하는 "|"입니다. 그 특징은 부모-자식 프로세스에서만 사용할 수 있다는 것입니다. 부모 프로세스는 자식 프로세스를 생성하기 전에 파이프 파일을 연 다음 포크하여 자식 프로세스를 생성해야 합니다. 동일한 파이프라인을 사용하여 통신하려는 목적을 달성하기 위해 상위 프로세스의 프로세스 주소 공간을 복사하여 동일한 파이프 파일을 만듭니다. 이때, 부모 프로세스와 자식 프로세스 외에는 누구도 이 파이프 파일의 디스크립터를 알지 못하므로, 이 파이프에 있는 정보를 다른 프로세스로 전달할 수 없습니다. 이는 전송된 데이터의 보안을 보장하지만 물론 파이프의 다양성을 감소시키므로 시스템은 명명된 파이프도 제공합니다.
mkfifo 또는 mknod 명령을 사용하여 파일을 생성하는 것과 다르지 않은 명명된 파이프를 생성할 수 있습니다.
[zorro@zorro-pc pipe]$ mkfifo pipe [zorro@zorro-pc pipe]$ ls -l pipe prw-r--r-- 1 zorro zorro 0 Jul 14 10:44 pipe
생성된 파일 형식이 매우 특별하다는 것을 알 수 있습니다. p 유형입니다. 파이프라인 파일임을 나타냅니다. 이 파이프 파일을 사용하면 시스템의 파이프에 대한 전역 이름이 있으므로 관련되지 않은 두 프로세스가 이 파이프 파일을 통해 통신할 수 있습니다. 예를 들어, 이제 프로세스가 다음 파이프 파일을 작성하도록 합시다:
[zorro@zorro-pc pipe]$ echo xxxxxxxxxxxxxx > pipe
이때 파이프의 반대쪽 끝에서는 아무도 읽고 있지 않기 때문에 쓰기 작업이 차단됩니다. 이는 파이프 파일 정의에 대한 커널의 기본 동작입니다. 이때 이 파이프를 읽는 프로세스가 있으면 이 쓰기 작업의 차단이 해제됩니다.
[zorro@zorro-pc pipe]$ cat pipe xxxxxxxxxxxxxx
파일을 분류한 후 반대편의 echo 명령도 반환되는 것을 볼 수 있습니다. 이것은 명명된 파이프입니다.
Linux 시스템은 명명된 파이프와 익명 파이프 모두에 대해 하위 계층에서 동일한 파일 시스템 작동 동작을 사용합니다. /etc/proc/filesystems 파일에서 시스템이 이 파일 시스템을 지원하는지 확인할 수 있습니다:
[zorro@zorro-pc pipe]$ cat /proc/filesystems |grep pipefs nodev pipefs
观察完了如何在命令行中使用管道之后,我们再来看看如何在系统编程中使用管道。
我们可以把匿名管道和命名管道分别叫做PIPE和FIFO。这主要因为在系统编程中,创建匿名管道的系统调用是pipe(),而创建命名管道的函数是mkfifo()。使用mknod()系统调用并指定文件类型为为S_IFIFO也可以创建一个FIFO。
使用pipe()系统调用可以创建一个匿名管道,这个系统调用的原型为:
#include <unistd.h> int pipe(int pipefd[2]);
这个方法将会创建出两个文件描述符,可以使用pipefd这个数组来引用这两个描述符进行文件操作。pipefd[0]是读方式打开,作为管道的读描述符。pipefd[1]是写方式打开,作为管道的写描述符。从管道写端写入的数据会被内核缓存直到有人从另一端读取为止。我们来看一下如何在一个进程中使用管道,虽然这个例子并没有什么意义:
[zorro@zorro-pc pipe]$ cat pipe.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
if (write(pipefd[1], STRING, strlen(STRING)) < 0) {
perror("write()");
exit(1);
}
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
exit(0);
}这个程序创建了一个管道,并且对管道写了一个字符串之后从管道读取,并打印在标准输出上。用一个图来说明这个程序的状态就是这样的:

一个进程自己给自己发送消息这当然不叫进程间通信,所以实际情况中我们不会在单个进程中使用管道。进程在pipe创建完管道之后,往往都要fork产生子进程,成为如下图表示的样子:
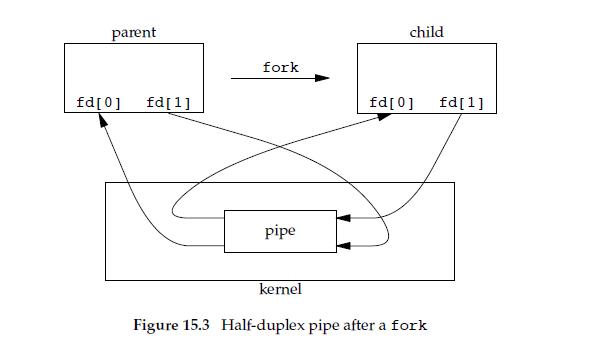
如图中描述,fork产生的子进程会继承父进程对应的文件描述符。利用这个特性,父进程先pipe创建管道之后,子进程也会得到同一个管道的读写文件描述符。从而实现了父子两个进程使用一个管道可以完成半双工通信。此时,父进程可以通过fd[1]给子进程发消息,子进程通过fd[0]读。子进程也可以通过fd[1]给父进程发消息,父进程用fd[0]读。程序实例如下:
[zorro@zorro-pc pipe]$ cat pipe_parent_child.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
bzero(buf, BUFSIZ);
snprintf(buf, BUFSIZ, "Message from child: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
} else {
/* this is parent */
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
sleep(1);
bzero(buf, BUFSIZ);
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
wait(NULL);
}
exit(0);
}父进程先给子进程发一个消息,子进程接收到之后打印消息,之后再给父进程发消息,父进程再打印从子进程接收到的消息。程序执行效果:
[zorro@zorro-pc pipe]$ ./pipe_parent_child Parent pid is: 8309 Child pid is: 8310 Message from parent: My pid is: 8309 Message from child: My pid is: 8310
从这个程序中我们可以看到,管道实际上可以实现一个半双工通信的机制。使用同一个管道的父子进程可以分时给对方发送消息。我们也可以看到对管道读写的一些特点,即:
在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。当一次写的数据量不超过管道容量的时候,对管道的写操作一般不会阻塞,直接将要写的数据写入管道缓冲区即可。
当然写操作也不会再所有情况下都不阻塞。这里我们要先来了解一下管道的内核实现。上文说过,管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做PIPESIZE。内核在处理管道数据的时候,底层也要调用类似read和write这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个page,即默认为4k字节。我们把每次可以操作的数据量长度叫做PIPEBUF。POSIX标准中,对PIPEBUF有长度限制,要求其最小长度不得低于512字节。PIPEBUF的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于PIPEBUF时,保证其操作是原子的。而PIPESIZE的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
在Linux 2.6.11之前,PIPESIZE和PIPEBUF实际上是一样的。在这之后,Linux重新实现了一个管道缓存,并将它与写操作的PIPEBUF实现成了不同的概念,形成了一个默认长度为65536字节的PIPESIZE,而PIPEBUF只影响相关读写操作的原子性。从Linux 2.6.35之后,在fcntl系统调用方法中实现了F_GETPIPE_SZ和F_SETPIPE_SZ操作,来分别查看当前管道容量和设置管道容量。管道容量容量上限可以在/proc/sys/fs/pipe-max-size进行设置。
#define BUFSIZE 65536
......
ret = fcntl(pipefd[1], F_GETPIPE_SZ);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
printf("PIPESIZE: %d\n", ret);
ret = fcntl(pipefd[1], F_SETPIPE_SZ, BUFSIZE);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
......PIPEBUF和PIPESIZE对管道操作的影响会因为管道描述符是否被设置为非阻塞方式而有行为变化,n为要写入的数据量时具体为:
O_NONBLOCK关闭,n <= PIPE_BUF:
n个字节的写入操作是原子操作,write系统调用可能会因为管道容量(PIPESIZE)没有足够的空间存放n字节长度而阻塞。
O_NONBLOCK打开,n <= PIPE_BUF:
如果有足够的空间存放n字节长度,write调用会立即返回成功,并且对数据进行写操作。空间不够则立即报错返回,并且errno被设置为EAGAIN。
O_NONBLOCK关闭,n > PIPE_BUF:
对n字节的写入操作不保证是原子的,就是说这次写入操作的数据可能会跟其他进程写这个管道的数据进行交叉。当管道容量长度低于要写的数据长度的时候write操作会被阻塞。
O_NONBLOCK打开,n > PIPE_BUF:
如果管道空间已满。write调用报错返回并且errno被设置为EAGAIN。如果没满,则可能会写入从1到n个字节长度,这取决于当前管道的剩余空间长度,并且这些数据可能跟别的进程的数据有交叉。
以上是在使用半双工管道的时候要注意的事情,因为在这种情况下,管道的两端都可能有多个进程进行读写处理。如果再加上线程,则事情可能变得更复杂。实际上,我们在使用管道的时候,并不推荐这样来用。管道推荐的使用方法是其单工模式:即只有两个进程通信,一个进程只写管道,另一个进程只读管道。实现为:
[zorro@zorro-pc pipe]$ cat pipe_parent_child2.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
close(pipefd[1]);
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
} else {
/* this is parent */
close(pipefd[0]);
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
wait(NULL);
}
exit(0);
}这个程序实际上比上一个要简单,父进程关闭管道的读端,只写管道。子进程关闭管道的写端,只读管道。整个管道的打开效果最后成为下图所示:
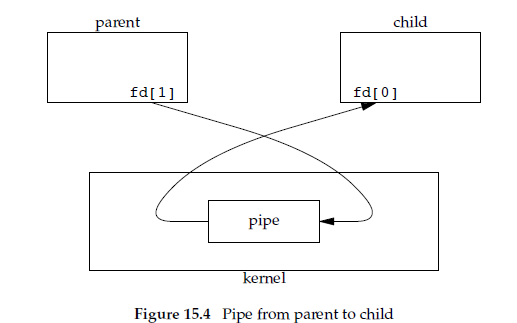
此时两个进程就只用管道实现了一个单工通信,并且这种状态下不用考虑多个进程同时对管道写产生的数据交叉的问题,这是最经典的管道打开方式,也是我们推荐的管道使用方式。另外,作为一个程序员,即使我们了解了Linux管道的实现,我们的代码也不能依赖其特性,所以处理管道时该越界判断还是要判断,该错误检查还是要检查,这样代码才能更健壮。
命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用。再程序中创建一个命名管道文件的方法有两种,一种是使用mkfifo函数。另一种是使用mknod系统调用,例子如下:
[zorro@zorro-pc pipe]$ cat mymkfifo.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Argument error!\n");
exit(1);
}
/*
if (mkfifo(argv[1], 0600) < 0) {
perror("mkfifo()");
exit(1);
}
*/
if (mknod(argv[1], 0600|S_IFIFO, 0) < 0) {
perror("mknod()");
exit(1);
}
exit(0);
}我们使用第一个参数作为创建的文件路径。创建完之后,其他进程就可以使用open()、read()、write()标准文件操作等方法进行使用了。其余所有的操作跟匿名管道使用类似。需要注意的是,无论命名还是匿名管道,它的文件描述都没有偏移量的概念,所以不能用lseek进行偏移量调整。
相关推荐:《Linux视频教程》
위 내용은 리눅스 채널이 뭐야?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

![[초보자를 위한 입문서, 이해하기 쉽다] 일주일 만에 리눅스 배우기](https://img.php.cn/upload/course/000/000/068/6242a86a890b1568.png)

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



