
최근에 멀티스레딩을 사용하여 파일을 다운로드하는 예를 보았는데 매우 흥미로워서 살펴보고 멀티스레딩을 사용하여 로컬로 파일을 복사해 보았습니다. 글을 다 쓰고 나니 두 가지가 실제로 매우 유사하다는 것을 알게 되었습니다. 로컬 파일 복사이든 네트워크 멀티스레드 다운로드이든 스트림 사용은 동일합니다. 로컬 파일 시스템의 경우 입력 스트림은 로컬 파일 시스템의 파일에서 가져옵니다. 네트워크 리소스의 경우 원격 서버의 파일에서 가져옵니다.
참고: 많은 사람들이 이 멀티 스레드 다운로드 코드를 작성했지만 모든 사람이 이해할 수는 없으므로 여기에 다시 작성하겠습니다. 하.
멀티스레딩 사용의 확실한 이점은 다음과 같습니다. 속도를 높이기 위해 유휴 CPU를 사용합니다. 하지만 스레드가 많을수록 좋습니다. n개의 스레드가 함께 다운로드되는 것처럼 보이지만 각 스레드는 작은 부분을 다운로드하며 다운로드 시간은 1/n이 됩니다. 이것은 아주 간단한 이해입니다. 한 사람이 집을 짓는 데는 100일이 걸리지만 10,000명이 집을 짓는 데는 1/10일 밖에 걸리지 않는 것과 같습니다. (과장입니다 하하!)
스레드 간 전환에도 시스템 오버헤드가 필요하며, 스레드 개수는 합리적인 범위 내에서 제어되어야 합니다.
이 클래스는 비교적 독특합니다. 파일에서 데이터를 읽고 파일에 데이터를 쓸 수 있습니다. 그러나 이는 OutputStream 및 InputStream의 하위 클래스가 아니며 DataOutput 및 DataInput 두 인터페이스를 구현하는 클래스입니다.
API 소개:
이 클래스의 인스턴스는 임의 액세스 파일 읽기 및 쓰기를 지원합니다. 파일에 무작위로 액세스하는 것은 파일 시스템에 저장된 많은 수의 바이트처럼 동작합니다. 파일 포인터라고 하는 암시적 배열에 대한 인덱스 또는 커서 유형이 있습니다. 입력 작업은 파일 포인터에서 시작하여 바이트를 읽고 읽은 바이트를 지나서 파일 포인터를 확장합니다. 읽기/쓰기 모드에서 임의 액세스 파일이 생성된 경우에도 출력 작업을 사용할 수 있습니다. 출력 작업은 파일 포인터에서 시작하여 바이트를 쓰고 파일 포인터를 작성된 바이트로 이동합니다. 암시적 배열의 현재 측면에 쓰는 출력 작업으로 인해 배열이 확장됩니다. 파일 포인터는 getFilePointer 메서드로 읽고 seek 메서드로 설정할 수 있습니다.
그래서 이 클래스에서 가장 중요한 것은 Seek 메서드를 사용하면 쓰기 위치를 제어할 수 있으므로 멀티스레딩 구현이 훨씬 쉽습니다. 따라서 로컬 파일 복사이든 네트워크 멀티스레드 다운로드이든 이 클래스가 필요합니다.
구체적인 아이디어는 다음과 같습니다. 먼저 RandomAccessFile을 사용하여 File 개체를 만든 다음 이 파일의 크기를 설정합니다. (예, 파일 크기를 직접 설정할 수 있습니다.) 이 파일을 복사하거나 다운로드하려는 파일과 동일하게 설정하십시오. (이 파일에 데이터를 쓰지는 않았지만 파일이 생성되었습니다.) 파일을 여러 부분으로 나누고 스레드를 사용하여 각 부분의 내용을 복사하거나 다운로드하세요.
이것은 파일 덮어쓰기와 다소 비슷합니다. 기존 파일이 파일의 선두부터 데이터를 쓰기 시작하여 파일의 끝에 쓰면 원본 파일은 더 이상 존재하지 않고 새로 작성된 문서가 됩니다.
파일 크기 설정:
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
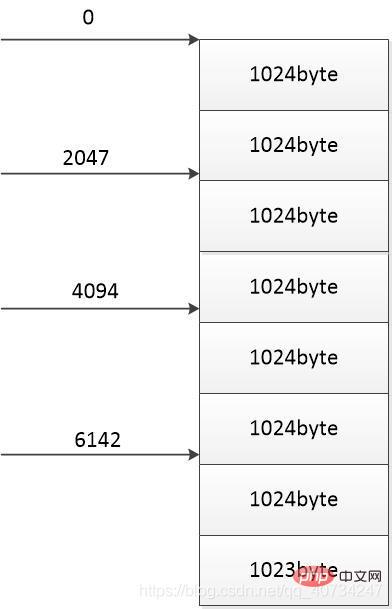
}설명에 그림 사용: 이 그림은 8191바이트 크기의 파일을 나타냅니다. 각 부분의 크기는 다음과 같습니다. 8191 / 4 = 2047바이트
이 파일을 다음으로 나눕니다. 4개 부분으로, 각 부분은 복사 또는 다운로드를 위해 스레드를 사용하며, 각 화살표는 스레드의 다운로드 시작 위치를 나타냅니다. 파일이 1024바이트로 정확히 나누어지는 경우가 거의 없기 때문에 의도적으로 마지막 부분을 1024바이트로 설정하지 않은 채로 두었습니다. (1024바이트를 사용하는 이유는 매번 1024바이트를 읽기 때문입니다. 1024바이트를 읽으면, 그렇지 않으면 읽은 해당 바이트 수만큼 쓰여집니다.)
이 다이어그램에 따르면 각 스레드는 2047바이트를 다운로드하고 다운로드된 총 바이트 수는 다음과 같습니다. 2047 * 4 = 8188바이트 < 8191바이트(파일의 총 크기) 따라서 문제가 발생합니다. 다운로드된 바이트 수가 총 바이트 수보다 적습니다. 이는 문제이므로 다운로드된 바이트 수가 총 바이트 수보다 커야 합니다. (더 많이 있어도 상관없습니다. 추가로 다운로드한 부분은 이후 부분에 의해 덮어쓰기 되어 문제가 발생하지 않기 때문입니다.)
따라서 각 부분의 크기는 8191 / 4 + 1 = 2048이 되어야 합니다. 바이트. (이렇게 하면 네 부분의 크기의 합이 전체 크기를 초과하게 되어 데이터 손실이 발생하지 않습니다.)
그래서 여기에 1을 추가하는 것이 매우 필요합니다.
long size = len / FileCopyUtil.THREAD_NUM + 1;
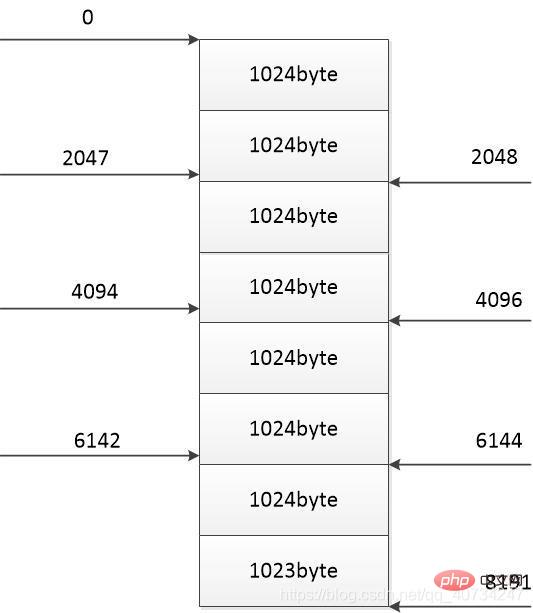
각 스레드가 다운로드를 완료한 위치(오른쪽) 각 스레드는 자신의 부분만 복사하고 다운로드하기 때문에 모든 내용을 다운로드할 필요는 없으므로 파일 데이터를 읽고 쓰는 것이 파일 부분에 판정이 하나 더 추가됩니다.
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h2000%2F20180113%2F0bdc-fyqrewh6850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
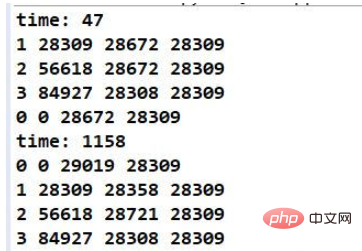
}运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)
产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了。
위 내용은 Java 멀티스레딩 및 IO 스트림의 애플리케이션 시나리오 및 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



