
단락 정렬은 정보 검색 분야에서 매우 중요하고 도전적인 주제로, 학계와 업계에서 폭넓은 관심을 받아왔습니다. 문단 순위 모델의 효율성은 검색 엔진 사용자 만족도를 높이고 질의응답 시스템, 독해 등 정보 검색 관련 애플리케이션에 도움이 될 수 있습니다. 이러한 맥락에서 문단 정렬 관련 연구 작업을 지원하기 위해 MS-MARCO, DuReader_retrieval 등과 같은 일부 벤치마크 데이터 세트를 구축했습니다. 그러나 일반적으로 사용되는 데이터 세트의 대부분은 영어 장면에 중점을 두고 있습니다. 중국어 장면의 경우 기존 데이터 세트는 데이터 규모, 세분화된 사용자 주석 및 위음성 예제 문제에 대한 솔루션에 한계가 있습니다. 이러한 맥락에서 우리는 실제 검색 로그를 기반으로 새로운 중국어 단락 순위 벤치마크 데이터세트인 T2Ranking을 구축했습니다.
T2랭킹은 300,000개 이상의 실제 쿼리와 200만개 이상의 인터넷 문단으로 구성되며 전문 주석자가 제공하는 4단계 세분화된 관련성 주석을 포함합니다. 현재 데이터와 일부 기본 모델은 Github에 게시되었으며 관련 연구 작업은 SIGIR 2023에서 리소스 논문으로 승인되었습니다.
문단 순위 작업의 목표는 주어진 질의어를 기반으로 대규모 문단 모음에서 후보 문단을 불러와 정렬하고, 높은 문단부터 낮은 문단 순으로 구하는 것입니다. 관련 목록. 단락 정렬은 일반적으로 단락 회상과 단락 재정렬의 두 단계로 구성됩니다.
단락 정렬 작업을 지원하기 위해 단락 정렬 알고리즘을 훈련하고 테스트하기 위한 여러 데이터 세트가 구성됩니다. 널리 사용되는 대부분의 데이터 세트는 영어 시나리오에 중점을 둡니다. 예를 들어 가장 일반적으로 사용되는 데이터 세트는 500,000개 이상의 쿼리 용어와 800만 개 이상의 문단을 포함하는 MS-MARCO 데이터 세트입니다. MS-MARCO 데이터 출시팀은 각 질의어에 대해 표준 답변을 제공하기 위해 주석자를 모집했습니다. 주어진 문단에 수동으로 제공된 표준 답변이 포함되어 있는지 여부에 따라 이 문단이 질의어와 관련이 있는지 여부를 판단합니다.
중국어 시나리오에는 단락 정렬 작업을 지원하기 위해 구축된 일부 데이터 세트도 있습니다. 예를 들어 mMarco-English는 MS-MARCO 데이터 세트의 중국어 번역 버전이고 DuReader_retrieval 데이터 세트는 MS-MARCO와 동일한 패러다임을 사용하여 단락 레이블을 생성합니다. 즉, 쿼리 단어-문단 쌍의 상관 관계는 다음과 같습니다. 인간이 제공한 표준 답변에서 제공됩니다. 다중 CPR 모델에는 세 가지 다른 도메인(전자상거래, 엔터테인먼트 비디오 및 의학)의 단락 검색 데이터가 포함되어 있습니다. Sogou 검색의 로그 데이터를 기반으로 Sogou-SRR, Sogou-QCL 및 Tiangong-PDR과 같은 데이터 세트도 제안되었습니다.
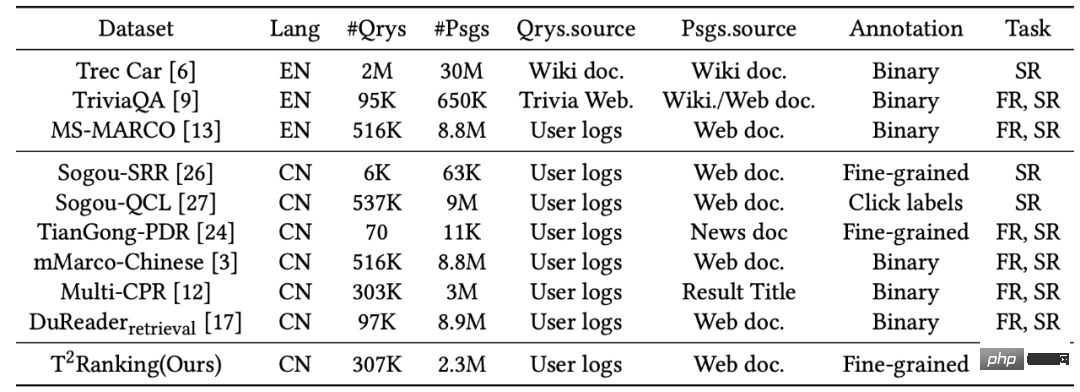
그림 1: 단락 정렬 작업에서 일반적으로 사용되는 데이터 세트의 통계
기존 데이터 세트가 단락 정렬 애플리케이션의 개발을 촉진했지만, 우리는 또한 몇 가지 제한 사항에 주의해야 합니다. :
1) 이러한 데이터 세트는 대규모가 아니거나 특히 중국 시나리오에서 관련성 레이블에 수동으로 주석이 추가되지 않습니다. Sogou-SRR 및 Tiangong-PDR에는 소량의 쿼리 데이터만 포함됩니다. mMarco-China와 Sogou-QCL은 규모가 더 크지만 전자는 기계 번역을 기반으로 하고 후자는 관련성 태그를 사용자 클릭 데이터로 사용합니다. 최근에는 상대적으로 큰 규모의 두 가지 데이터 세트인 Multi-CPR과 DuReader_retrieval이 구축되어 출시되었습니다.
2) 기존 데이터 세트에는 세분화된 상관 관계 주석 정보가 부족합니다. 대부분의 데이터 세트는 이진 상관 주석(대략적), 즉 관련성 또는 관련성이 없는 주석을 사용합니다. 기존 작업에서는 세분화된 상관 관계 주석 정보가 서로 다른 엔터티 간의 관계를 마이닝하고 보다 정확한 순위 알고리즘을 구축하는 데 도움이 될 수 있음을 보여주었습니다. 그런 다음 소량의 다단계 세분화 주석을 제공하지 않거나 제공하지 않는 기존 데이터 세트가 있습니다. 예를 들어 Sogou-SRR 또는 Tiangong-PDR은 100,000개 이하의 세분화된 주석만 제공합니다.
3) 위음성 예시의 문제는 평가의 정확성에 영향을 미칩니다. 기존 데이터 세트는 다수의 관련 문서가 관련 없는 것으로 표시되는 위음성 예제 문제의 영향을 받습니다. 이 문제는 대규모 데이터의 수동 주석 수가 적기 때문에 발생하며 이는 평가의 정확성에 큰 영향을 미칩니다. 예를 들어, Multi-CPR에서는 단 하나의 단락만 각 검색어와 관련이 있는 것으로 표시되고 나머지는 관련이 없는 것으로 표시됩니다. DuReader_retrieval은 주석자가 상위 단락 세트를 수동으로 검사하고 다시 주석을 달 수 있도록 하여 거짓 부정 문제를 완화하려고 시도합니다.
고품질 훈련 및 평가를 위한 단락 순위 모델을 더 잘 지원하기 위해 새로운 중국어 단락 검색 벤치마크 데이터세트인 T2Ranking을 구축하고 출시했습니다.
데이터 세트 구성 프로세스에는 검색어 샘플링, 문서 호출, 단락 추출 및 세분화된 관련성 주석이 포함됩니다. 동시에 우리는 문단의 의미 무결성과 다양성을 보장하기 위해 모델 기반 문단 분할 방법과 클러스터링 기반 문단 중복 제거 방법을 사용하고 능동 학습을 사용하는 등 데이터 세트의 품질을 향상시키기 위한 여러 방법을 설계했습니다. 기반 주석의 효율성과 품질을 향상시키는 방법 등
1) 전체 프로세스
그림 2: Wikipedia 페이지의 예. 제시된 문서에는 명확하게 정의된 단락이 포함되어 있습니다.
2) 모델 기반 단락 분할 방법
기존 데이터 세트에서는 일반적으로 자연 단락(줄 바꿈) 또는 고정 길이 슬라이딩 창을 통해 문서에서 단락을 분할합니다. 그러나 두 방법 모두 의미상 불완전하거나 너무 길고 여러 가지 주제를 포함하는 단락이 될 수 있습니다. 본 연구에서는 모델 기반 단락 분할 방법을 채택했습니다. 구체적으로, 문서의 이 부분의 구조가 비교적 명확하고 자연스러운 단락도 얻어지기 때문에 Sogou Encyclopedia, Baidu Encyclopedia 및 Chinese Wikipedia를 훈련 데이터로 사용했습니다. 더 나은 정의. 우리는 주어진 단어가 분할 지점이 되어야 하는지 여부를 결정하기 위해 분할 모델을 훈련했습니다. 우리는 시퀀스 라벨링 작업 아이디어를 사용하고 각 자연 세그먼트의 마지막 단어를 모델 학습을 위한 긍정적인 예로 사용했습니다.
3) 클러스터링 기반 단락 중복 제거 방법
문단 순위 모델의 경우 매우 유사한 단락 내용에 주석을 추가하는 것은 중복되고 의미가 없습니다. 정보 획득이 제한되므로 클러스터링을 설계했습니다. 주석의 효율성을 높이기 위한 기반 단락 중복 제거 방법입니다. 구체적으로, 유사한 문서의 비지도 클러스터링을 수행하기 위해 계층적 클러스터링 알고리즘인 Ward를 사용합니다. 동일한 클래스의 단락은 매우 유사한 것으로 간주되며 관련성 주석을 위해 각 클래스에서 하나의 단락을 샘플링합니다. 테스트 세트의 경우 거짓음성 예시의 영향을 줄이기 위해 추출된 모든 단락에 완전히 주석을 달 것입니다.
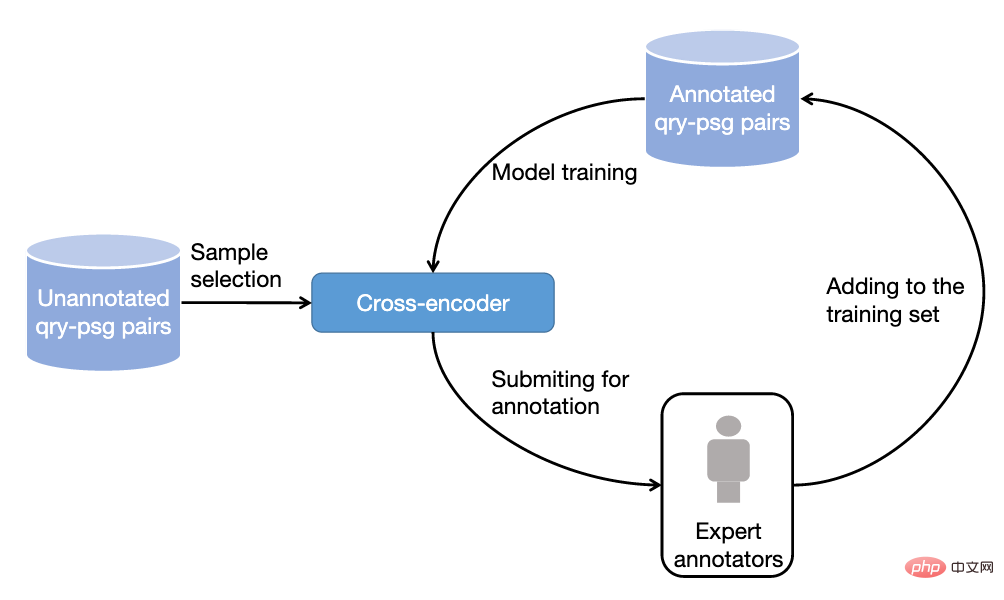
그림 3: 능동 학습 기반 샘플링 주석 과정
4) 능동 학습 기반 데이터 샘플링 주석 방법
실제로는 그렇지 않은 것으로 관찰되었습니다. 모든 훈련 샘플은 순위 모델의 성능을 더욱 향상시킬 수 있습니다. 모델이 정확하게 예측할 수 있는 훈련 샘플의 경우 후속 모델에 대한 훈련 도움말이 제한됩니다. 따라서 우리는 모델이 추가 주석을 위해 더 유익한 훈련 샘플을 선택할 수 있도록 능동 학습 아이디어를 차용했습니다. 구체적으로 먼저 기존 학습 데이터를 기반으로 하는 크로스 인코더 프레임워크를 기반으로 쿼리 단어 단락 재정렬 모델을 학습한 다음 이 모델을 사용하여 다른 데이터를 예측하고 과도한 신뢰도 점수(정보 내용)도 제거했습니다. 낮은 신뢰도 점수(노이즈가 있는 데이터), 유지된 단락에 추가로 주석을 달고 이 프로세스를 반복합니다.
T2랭킹은 300,000개 이상의 실제 쿼리와 2백만 개의 인터넷 문단으로 구성됩니다. 그 중 트레이닝 세트에는 약 250,000개의 쿼리 단어가 포함되어 있고, 테스트 세트에는 약 50,000개의 쿼리 단어가 포함되어 있습니다. 검색어는 최대 40자까지 가능하며 평균 길이는 약 11자입니다. 동시에 데이터 세트의 검색어는 의학, 교육, 전자상거래 등 여러 분야를 포괄합니다. 또한 검색어의 다양성 점수(ILS)도 기존 데이터 세트와 비교하여 계산했습니다. 더 높습니다. 175만 개의 문서에서 230만 개 이상의 문단을 샘플링했으며, 각 문서는 평균 1.3개의 문단으로 나누어졌다. 훈련 세트에서는 검색어당 평균 6.25개의 문단에 수동으로 주석이 달렸고, 테스트 세트에서는 검색어당 평균 15.75개의 문단에 수동으로 주석이 달렸습니다.
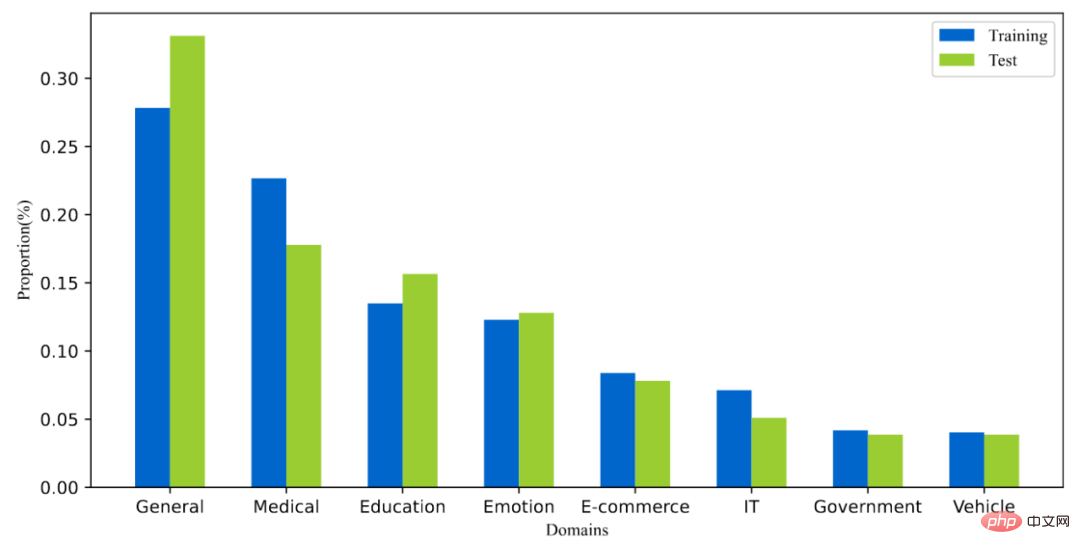
그림 4: 데이터 세트에 있는 쿼리 단어의 도메인 분포
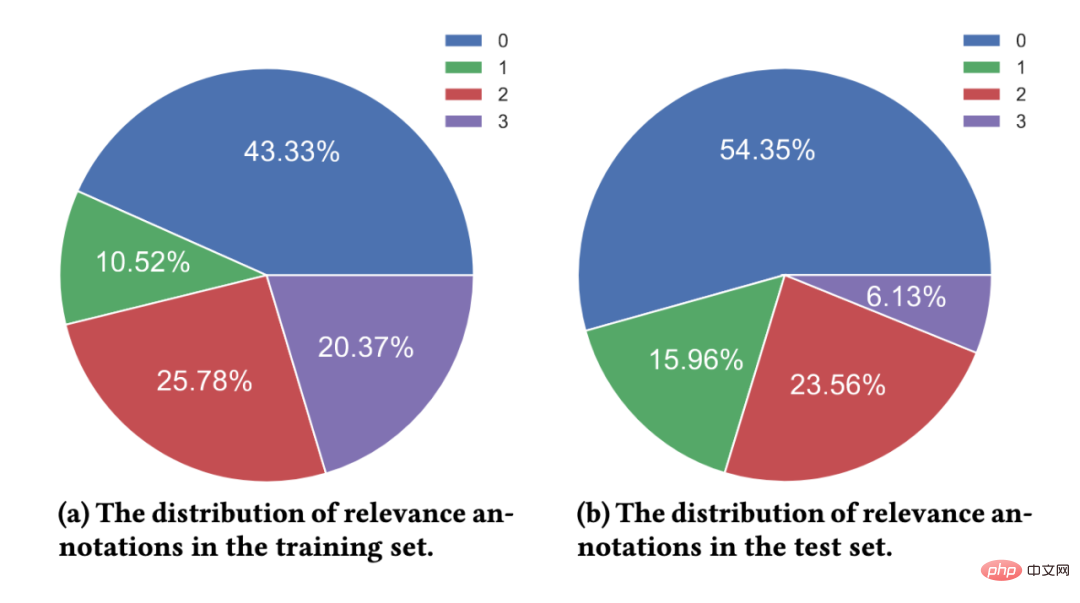
그림 5: 관련성 주석 분포
획득한 데이터 세트에 대해 일반적으로 사용되는 일부 단락 정렬 모델의 성능을 단락 회상 및 단락 재정렬의 두 단계에서 테스트했습니다.
1) 단락 회상 실험
기존 단락 회상 모델은 크게 희소 회상 모델과 밀집 회상 모델로 나눌 수 있습니다.
다음 회상 모델의 성능을 테스트했습니다.
이 모델 중 QL과 BM25는 Sparse Recall 모델이고, 다른 모델은 Dense Recall 모델입니다. 우리는 MRR 및 Recall과 같은 일반적인 지표를 사용하여 이러한 모델의 성능을 평가합니다. 실험 결과는 다음 표에 나와 있습니다.
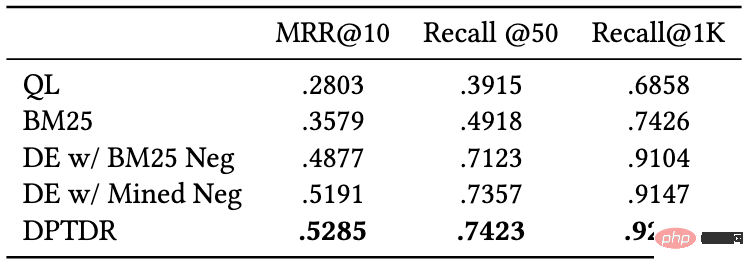
그림 6: 테스트 세트에 대한 단락 회상 모델의 성능
실험 결과에서 전통적인 희소 정렬 모델에 비해 밀집 검색 모델이 더 나은 성능을 보이는 것을 알 수 있습니다. 동시에, hard-to-negative 예제를 도입하는 것도 모델 성능을 향상시키는 데 도움이 됩니다. 우리 데이터 세트에서 이러한 실험 모델의 리콜 성능은 다른 데이터 세트보다 나쁘다는 점을 언급할 가치가 있습니다. 예를 들어, 우리 데이터 세트에서 BM25의 Recall@50은 0.492인 반면, MS-Marco와 Dureader_retrieval에서는 0.601과 0.700입니다. . 이는 수동으로 주석을 추가한 단락이 더 많기 때문일 수 있습니다. 테스트 세트에는 쿼리 용어당 평균 4.74개의 관련 문서가 있어 회상 작업이 더 어려워지고 거짓 부정이 어느 정도 감소합니다. 문제. 이는 또한 T2Ranking이 까다로운 벤치마크 데이터 세트이며 향후 리콜 모델을 개선할 여지가 크다는 것을 보여줍니다.
2) 문단 재정렬 실험
문단 회상 단계에 비해 재정렬 단계에서 고려하는 문단의 크기가 작기 때문에 대부분의 방법은 Interactive Encoder(Cross-Encoder)를 사용하는 경향이 있습니다. ) 모델 프레임워크로서 본 연구에서는 단락 재정렬 작업에 대한 대화형 인코더 모델의 성능을 테스트했습니다. 실험 결과는 다음과 같습니다.

그림 7 : 단락 재정렬 작업에 대한 대화형 인코더의 성능
실험 결과 듀얼 인코더(Dual-Encoder)에 의해 호출된 단락을 기반으로 재정렬하는 것이 호출된 단락을 기반으로 재정렬하는 것보다 더 효과적인 것으로 나타났습니다. by BM25 기존 연구의 실험적 결론과 일치하는 더 나은 결과를 얻을 수 있습니다. 리콜 실험과 유사하게, 우리 데이터 세트의 순위 재지정 모델의 성능은 다른 데이터 세트의 성능보다 나빴습니다. 이는 우리 데이터 세트의 세밀한 주석과 더 높은 쿼리 단어 다양성 때문일 수 있습니다. 이는 까다로우며 모델 성능을 보다 정확하게 반영할 수 있습니다.
데이터 세트는 칭화대학교 컴퓨터과학과 정보 검색 연구 그룹(THUIR)과 Tencent의 QQ 브라우저 검색 기술 센터 팀이 공동으로 출시했으며, 칭화대학교 천궁지능컴퓨팅연구소. THUIR 연구 그룹은 검색 및 추천 방법에 대한 연구에 중점을 두고 있으며 사용자 행동 모델링 및 설명 가능한 학습 방법에서 전형적인 결과를 얻었습니다. 연구 그룹의 성과로는 WSDM2022 최우수 논문상, SIGIR2020 최우수 논문 후보상 및 CIKM2018 최우수 논문상이 있습니다. 2020년 중국정보학회의 '첸웨이창 중국 정보처리 과학기술상'을 비롯해 다수의 학술상을 수상했습니다. QQ 브라우저 검색 기술 센터 팀은 Tencent PCG 정보 플랫폼 및 서비스 라인의 검색 기술 연구 및 개발을 담당하는 팀입니다. Tencent의 콘텐츠 생태계를 기반으로 사용자 연구를 통해 제품 혁신을 추진하여 사용자에게 그래픽, 정보, 소설, 장문의 콘텐츠를 제공합니다. 짧은 비디오, 서비스 등 오리엔테이션 정보 요구 사항이 충족됩니다.
위 내용은 중국어 단락 정렬 벤치마크 데이터 세트 출시: 실제 쿼리 300,000개와 인터넷 단락 200만 개를 기반으로 합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



