
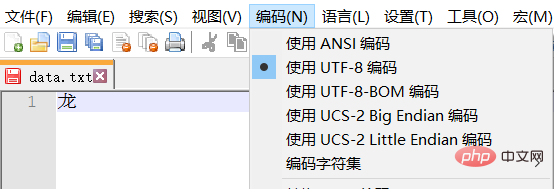
참고: 테스트 텍스트는 UTF-8로 인코딩되며 중국어 문자는 일반적으로 3바이트를 차지합니다. GBK의 한자는 일반적으로 2바이트를 차지합니다.
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号콘솔 출력 이 함수 실행의 출력은 의미가 없지만 실행되었는지 알고 싶어서 인쇄해봅니다.

Test 폴더 data1.txt는 변환 및 인코딩된 텍스트입니다.
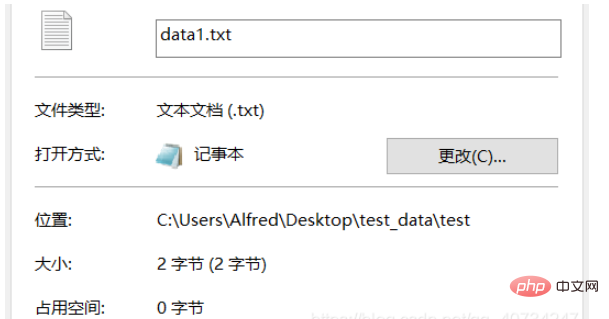
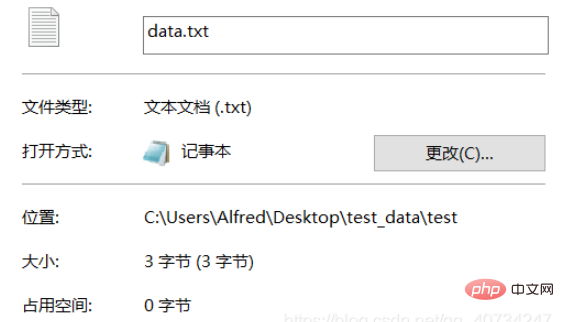
생성된 파일로 판단해보면, 한 단어만 포함되어 있기 때문에 크기만 비교해도 변환 성공 여부를 알 수 있습니다. 물론 직접 열어서 보기도 가능하지만, 직접 열어서 보기에는 효과가 없으며 한자 龙가 표시됩니다. 그래서 여기서는 다른 접근 방식을 취하고 다른 보기 방법을 사용합니다!
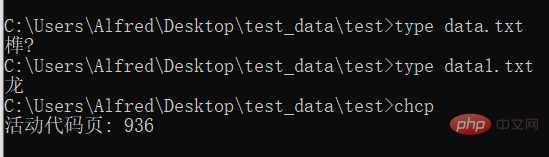
참고: data.txt는 UTF-8로 인코딩되고 data1.txt는 GBK로 인코딩됩니다. 중국에서 사용되는 Windows는 기본적으로 중국의 인코딩 방식을 채택하고 있기 때문에 UTF-8로 인코딩된 텍스트를 표시할 수 없습니다. 세 번째 출력은 현재 사용되는 인코딩을 보는 것입니다. 자세한 내용은 아래 그림을 참조하세요.
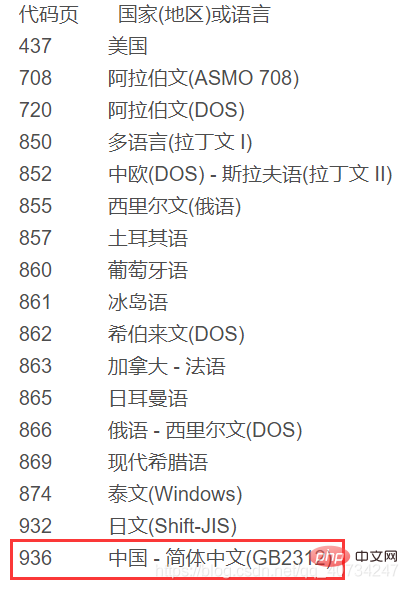
참고: GBK는 GB2312와 호환되는 인코딩입니다.
파이썬을 사용하는 경우 단일 파일을 변환하는 데 7줄의 코드만 있으면 됩니다! 위에서 두 가지 함수를 작성했지만, 함수의 차이점은 첫 번째 함수가 특정 인코딩으로 텍스트 정보를 읽은 다음 다른 인코딩으로 직접 쓴다는 점입니다. 두 번째 함수는 파일 내용을 바이너리 형식으로 읽은 다음 쓰기 위해 디코딩하고 트랜스코딩합니다. 그 원리는 동일합니다. 즉, 순차적인 디코딩 및 트랜스코딩 작업을 포함해야 합니다.
인코딩, 디코딩, 문자셋 자체가 너무 복잡해서 어떻게 깊이 설명해야 할지 모르겠습니다. 여기에서의 이해는 다음과 같이 단순화될 수 있습니다. 두 개의 서로 다른 인코딩 문자 집합은 동일한 문자를 가지므로 UTF-8로 인코딩된 파일을 읽는 목적은 매핑되는 문자를 가져온 다음 이를 다른 인코딩된 문자에 매핑하기 위해 다시 쓰는 것입니다. 문자 집합이므로 문자는 환승역의 기능과 유사합니다. 한 문자 집합을 직접 사용하여 다른 문자 집합의 내용을 읽으면 위 cmd에 표시된 문자가 깨져서 나타납니다.
PS: 따라서 문제, 즉 대용량 텍스트 파일을 열면 프로그램이 정지되는 이유를 설명할 수도 있습니다! 큰 텍스트 파일에는 디코딩해야 할 문자가 많이 포함되어 있기 때문입니다. 이는 큐잉과 다소 유사합니다. 각 문자가 디코딩되기를 기다리고 있습니다. 한 문자를 처리하는 것은 빠르지만 큰 텍스트 파일에는 많은 수의 문자가 포함되어 있습니다. 예를 들어, Notepad++는 큰 텍스트를 여는 데 문제가 없습니다. 하지만 이 매우 큰 텍스트를 열면 여전히 멈췄습니다. (여기서 큐잉은 비유일 뿐 실제 상황은 모르겠지만 하나씩 처리해야 합니다.)
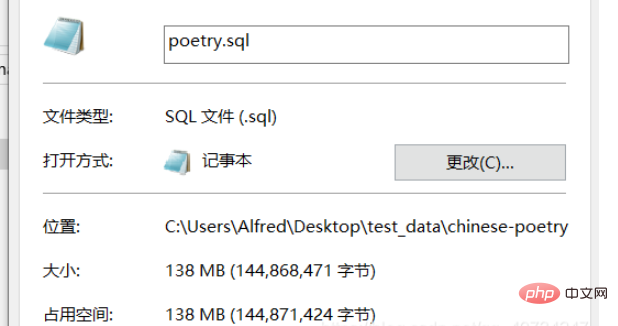
모든 문자가 한자라고 가정하고 추정합니다(실제로는 아직 일부는 영어로 되어 있지만 일반적으로 중국어가 대다수입니다.) 디코딩해야 할 문자가 약 5천만 개에 달하는 것으로 나타나 아직 컴퓨터가 요약을 볼 수는 있지만 Notepad++에서는 처리하기가 매우 어렵습니다. 직접 열면 멈춥니다. 여기서는 시도하지 않겠습니다.

위 내용은 Python에서 텍스트 파일 변환 인코딩 문제를 해결하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



