

Python 함수의 구현 원리는 무엇입니까

Wedge
함수는 모든 프로그래밍 언어의 기본 요소입니다. 함수는 수행할 여러 작업을 결합할 수 있습니다. 그리고 함수를 호출하면 어떻게 될까요? 예, 함수 실행을 위해서는 스택 프레임이 생성되어야 합니다.
PyFunctionObject
Python의 모든 것은 객체이며 함수도 예외는 아닙니다. 함수는 funcobject.h에 정의된 PyFunctionObject 구조를 통해 하단에 구현됩니다.
typedef struct {
/* 头部信息,无需多说 */
PyObject_HEAD
/* 函数对应的 PyCodeObject 对象
因为函数也是基于 PyCodeObject 对象构建的 */
PyObject *func_code;
/* 函数的 global 名字空间 */
PyObject *func_globals;
/* 函数参数的默认值,一个元组或者空 */
PyObject *func_defaults;
/* 只能通过关键字的方式传递的 "参数" 和 "该参数的默认值" 组成的字典
或者空 */
PyObject *func_kwdefaults;
/* 闭包 */
PyObject *func_closure;
/* 函数的 docstring */
PyObject *func_doc;
/* 函数名 */
PyObject *func_name;
/* 函数的属性字典,一般为空 */
PyObject *func_dict;
/* 弱引用列表,对函数的弱引用都会保存在里面 */
PyObject *func_weakreflist;
/* 函数所在的模块 */
PyObject *func_module;
/* 函数的类型注解 */
PyObject *func_annotations;
/* 函数的全限定名 */
PyObject *func_qualname;
/* Python 函数在底层也是某个类(PyFunction_Type)的实例对象
调用时会执行类型对象的 tp_call,在 Python 里面就是 __call__
但函数比较特殊,它创建出来就是为了调用的,所以不能走通用的 tp_call
为了优化调用效率,引入了 vectorcall */
vectorcallfunc vectorcall;
} PyFunctionObject;실제로 이 멤버를 가져와 Python에서 어떻게 작동하는지 살펴보겠습니다.
func_code: 함수의 바이트 코드
def foo(a, b, c):
pass
code = foo.__code__
print(code) # <code object foo at ......>
print(code.co_varnames) # ('a', 'b', 'c')func_globals: 전역 네임스페이스
def foo(a, b, c):
pass
name = "古明地觉"
print(foo.__globals__) # {......, 'name': '古明地觉'}
# 拿到的其实就是外部的 global名字空间
print(foo.__globals__ is globals()) # Truefunc_defaults: 함수 매개변수의 기본값
def foo(name="古明地觉", age=16):
pass
# 打印的是默认值
print(foo.__defaults__) # ('古明地觉', 16)
def bar():
pass
# 没有默认值的话,__defaults__ 为 None
print(bar.__defaults__) # Nonefun c_k wdefaults: 키워드를 통해서만 구성된 사전 전달된 "매개변수" 및 "매개변수의 기본값"
def foo(name="古明地觉", age=16):
pass
# 打印为 None,这是因为虽然有默认值
# 但并不要求必须通过关键字参数的方式传递
print(foo.__kwdefaults__) # None
def bar(*, name="古明地觉", age=16):
pass
print(
bar.__kwdefaults__
) # {'name': '古明地觉', 'age': 16}앞에는 *가 붙는데, 이는 다음 매개변수가 키워드를 통해 전달되어야 함을 의미합니다. 키워드 매개변수를 통해 전달되지 않으면 *로 수신된 위치 매개변수가 아무리 많아도 이름이나 나이에는 전달될 수 없기 때문입니다.
우리는 *args가 정의되면 함수가 원하는 수의 위치 매개변수를 받을 수 있으며 이러한 매개변수는 튜플 형식으로 args에 저장된다는 것을 알고 있습니다. 하지만 여기서는 필요하지 않습니다. 후속 매개변수가 키워드 매개변수를 통해 전달되어야 하므로 앞에 *만 작성하면 됩니다. 물론 *args를 작성하는 것도 가능합니다.
func_closure: 클로저 객체
def foo():
name = "古明地觉"
age = 16
def bar():
nonlocal name
nonlocal age
return bar
# 查看的是闭包里面使用的外层作用域的变量
# 所以 foo().__closure__ 是一个包含两个元素的元组
print(foo().__closure__)
"""
(<cell at 0x000001FD1D3B02B0: int object at 0x00007FFDE559D660>,
<cell at 0x000001FD1D42E310: str object at 0x000001FD1D3DA090>)
"""
print(foo().__closure__[0].cell_contents) # 16
print(foo().__closure__[1].cell_contents) # 古明地觉참고: 클로저 속성을 보려면 외부 foo가 아닌 내부 함수를 사용합니다.
func_doc: 함수의 독스트링
def foo():
"""
hi,欢迎来到我的编程教室
遇见你真好
"""
pass
print(foo.__doc__)
"""
hi,欢迎来到我的编程教室
遇见你真好
"""func_name: 함수의 이름
def foo(name, age):
pass
print(foo.__name__) # foo물론 함수뿐만 아니라 메소드, 클래스, 모듈에도 고유한 이름이 있습니다.
import numpy as np print(np.__name__) # numpy print(np.ndarray.__name__) # ndarray print(np.array([1, 2, 3]).transpose.__name__) # transpose
func_dict: 함수의 속성 사전
함수도 최하위 수준의 클래스에 의해 인스턴스화되기 때문에 자체 속성 사전을 가질 수 있지만 이 사전은 일반적으로 비어 있습니다.
def foo(name, age):
pass
print(foo.__dict__) # {}물론 몇 가지 트릭도 사용할 수 있습니다.
def foo(name, age):
return f"name: {name}, age: {age}"
code = """
name, age = "古明地觉", 17
def foo():
return "satori"
"""
exec(code, foo.__dict__)
print(foo.name) # 古明地觉
print(foo.age) # 17
print(foo.foo()) # satori
print(foo("古明地觉", 17)) # name: 古明地觉, age: 17따라서 함수라고 부르기는 하지만 특정 유형의 개체에 의해 구현되기도 합니다.
func_weakreflist: 약한 참조 목록
Python은 이 속성을 얻을 수 없습니다. 여기서는 약한 참조에 대해 자세히 논의하지 않습니다.
func_module: 함수가 위치한 모듈
def foo(name, age):
pass
print(foo.__module__) # __main__
import pandas as pd
print(
pd.read_csv.__module__
) # pandas.io.parsers.readers
from pandas.io.parsers.readers import read_csv
print(read_csv is pd.read_csv) # True클래스, 메소드, 코루틴에도 __module__ 속성이 있습니다.
func_annotations: 유형 주석
def foo(name: str, age: int):
pass
# Python3.5 新增的语法,但只能用于函数参数
# 而在 3.6 的时候,声明变量也可以使用这种方式
# 特别是当 IDE 无法得知返回值类型时,便可通过类型注解的方式告知 IDE
# 这样就又能使用 IDE 的智能提示了
print(foo.__annotations__)
# {'name': <class 'str'>, 'age': <class 'int'>}func_qualname: 정규화된 이름
def foo():
pass
print(foo.__name__, foo.__qualname__) # foo foo
class A:
def foo(self):
pass
print(A.foo.__name__, A.foo.__qualname__) # foo A.foo완전한 이름이 더 완전해야 합니다.
def foo(name, age):
pass
# <class 'function'> 就是 C 里面的 PyFunction_Type
print(foo.__class__) # <class 'function'>하지만 이 클래스의 맨 아래 레이어는 우리에게 노출되지 않으며 직접 사용할 수 없습니다. 함수는 def를 통해 생성할 수 있고 유형 개체를 통해 생성할 필요가 없기 때문입니다.
함수는 언제 만들어졌나요?
앞서 이 함수는 최하위 수준의 PyFunctionObject 구조에 의해 구현된다고 언급했습니다. 여기에는 PyCodeObject 객체를 가리키는 func_code 멤버가 있고, 이를 기반으로 함수가 생성됩니다.
PyCodeObject는 코드 조각의 정적 표현이기 때문에 Python 컴파일러가 소스 코드를 컴파일한 후 각 코드 블록(코드 블록)에 대해 단 하나의 PyCodeObject 객체를 생성합니다. 이 객체에는 소스 코드에서 볼 수 있는 정보인 이 코드 블록에 대한 일부 정적 정보가 포함되어 있습니다.
예를 들어 함수에 해당하는 코드 블록에 a = 1과 같은 표현식이 있으면 기호 a, 정수 1 및 이들 사이의 관계는 정적 정보이며 이 정보는 정적으로 저장됩니다.
기호 a는 기호 테이블 co_varnames에 저장됩니다.
integer 1은 상수 풀 co_consts에 저장됩니다.
은 둘 사이에 할당문이므로 LOAD_CONST와 STORE_FAST라는 두 가지 명령이 있습니다. , 이는 바이트코드 명령 시퀀스 co_code에 존재합니다.
위 정보는 컴파일 중에 얻을 수 있으므로 PyCodeObject 객체는 컴파일의 결과입니다.
그런데 PyFunctionObject 객체는 언제 생성되었나요? 분명히 이는 런타임 시 Python 코드에 의해 동적으로 생성됩니다. 더 정확하게 말하면 def 문을 실행할 때 가상 머신에 의해 생성됩니다.
가상 머신이 현재 스택 프레임에서 바이트코드를 실행할 때 def 문을 발견한다는 것은 새로운 PyCodeObject 객체가 발견되었음을 의미합니다. 왜냐하면 이 객체는 계층별로 중첩될 수 있기 때문입니다. 따라서 가상 머신은 이 PyCodeObject 객체를 기반으로 해당 PyFunctionObject 객체를 생성한 다음, 함수 이름과 PyFunctionObject 객체(함수 본문)의 키-값 쌍을 현재 로컬 공간에 배치합니다.
PyFunctionObject 객체에서는 관련 정적 정보도 얻어야 하므로 PyCodeObject를 가리키는 func_code 멤버가 있을 것입니다.
除此之外,PyFunctionObject 对象中还包含了一些函数在执行时所必需的动态信息,即上下文信息。比如 func_globals,就是函数在执行时关联的 global 空间,说白了就是在局部变量找不到的时候能够找全局变量,可如果连 global 空间都没有的话,那即便想找也无从下手呀。
而 global 作用域中的符号和值必须在运行时才能确定,所以这部分必须在运行时动态创建,无法静态存储在 PyCodeObject 中,因此要根据 PyCodeObject 对象创建 PyFunctionObject 对象。总之一切的目的,都是为了更好地执行字节码。
我们举个例子:
# 虚拟机从上到下顺序执行字节码
name = "古明地觉"
age = 16
# 啪,很快啊,发现了一个 def 语句
def foo():
pass
# 出现 def,虚拟机就知道源代码进入一个新的作用域了
# 也就是遇到一个新的 PyCodeObject 对象了
# 而通过 def 可以得知这是创建函数的语句
# 所以会基于 PyCodeObject 创建 PyFunctionObject
# 因此当执行完 def 语句之后,一个函数就创建好了
# 创建完之后,会将函数名和函数体组成键值对,存放在当前的 local 空间中
print(locals()["foo"])
"""
<function foo at 0x7fdc280e6280>
"""调用的时候,会从 local 空间中取出符号 foo 对应的 PyFunctionObject 对象。然后根据这个 PyFunctionObject 对象创建 PyFrameObject 对象,也就是为函数创建一个栈帧,随后将执行权交给新创建的栈帧,并在新创建的栈帧中执行字节码。
函数是怎么创建的
通过上面的分析,我们知道了函数是虚拟机在遇到 def 语句的时候创建的,并保存在 local 空间中。当我们通过函数名()的方式调用时,会从 local 空间取出和函数名绑定的函数对象,然后执行。
那么问题来了,函数(对象)是怎么创建的呢?或者说虚拟机是如何完成 PyCodeObject 对象到 PyFunctionObject 对象之间的转变呢?显然想了解这其中的奥秘,就必须从字节码入手。
import dis
s = """
name = "satori"
def foo(a, b):
print(a, b)
return 123
foo(1, 2)
"""
dis.dis(compile(s, "<...>", "exec"))源代码很简单,定义一个变量 name 和函数 foo,然后调用函数。显然源代码在编译之后会产生两个 PyCodeObject,一个是模块的,一个是函数 foo 的,我们来看一下。
# 加载字符串常量 "satori",压入运行时栈
2 0 LOAD_CONST 0 ('satori')
# 将字符串从运行时栈弹出,并使用变量 name 绑定起来
# 也就是将 "name": "satori" 放到 local 名字空间中
2 STORE_NAME 0 (name)
# 注意这一步也是 LOAD_CONST,但它加载的是 PyCodeObject 对象
# 所以 PyCodeObject 对象本质上也是一个常量
3 4 LOAD_CONST 1 (<code object foo at 0x7fb...>)
# 加载符号 "foo"
6 LOAD_CONST 2 ('foo')
# 将符号 "foo" 和 PyCodeObject 对象从运行时栈弹出
# 然后创建 PyFunctionObject 对象,并压入运行时栈
8 MAKE_FUNCTION 0
# 将上一步创建的函数对象从运行时栈弹出,并用变量 foo 与之绑定起来
# 后续通过 foo() 即可发起函数调用
10 STORE_NAME 1 (foo)
# 函数创建完了,我们调用函数
# 通过 LOAD_NAME 将 foo 对应的函数对象(指针)压入运行时栈
6 12 LOAD_NAME 1 (foo)
# 将整数常量(参数)压入运行时栈
14 LOAD_CONST 3 (1)
16 LOAD_CONST 4 (2)
# 将栈里面的参数和函数弹出,发起调用,并将调用的结果(返回值)压入运行时栈
18 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有用变量接收返回值
# 如果我们用变量接收了,那么这里的指令就会从 POP_TOP 变成 STORE_NAME
20 POP_TOP
# return None
22 LOAD_CONST 5 (None)
24 RETURN_VALUE
# 以上是模块对应的字节码指令,下面是函数 foo 的字节码指令
Disassembly of <code object foo at 0x7fb......>:
# 从局部作用域中加载内置变量 print
4 0 LOAD_GLOBAL 0 (print)
# 从局部作用域中加载局部变量 a
2 LOAD_FAST 0 (a)
# 从局部作用域中加载局部变量 b
4 LOAD_FAST 1 (b)
# 从运行时栈中将参数和函数依次弹出,发起调用,也就是 print(a, b)
6 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有接收 print 的返回值
8 POP_TOP
# return 123
10 LOAD_CONST 1 (123)
12 RETURN_VALUE上面有一个有趣的现象,就是源代码的行号。之前看到源代码的行号都是从上往下、依次增大的,这很好理解,毕竟一条一条解释嘛。但是这里却发生了变化,先执行了第 6 行,之后再执行第 4 行。
如果是从 Python 层面的函数调用来理解的话,很容易一句话就解释了,因为函数只有在调用的时候才会执行,而调用肯定发生在创建之后。但是从字节码的角度来理解的话,我们发现函数的声明和实现是分离的,是在不同的 PyCodeObject 对象中。
确实如此,虽然函数名和函数体是一个整体,但是虚拟机在实现的时候,却在物理上将它们分离开了。
正所谓函数即变量,我们可以把函数当成普通的变量来处理。函数名就是变量名,它位于模块对应的 PyCodeObject 的符号表中;函数体就是变量指向的值,它是基于一个独立的 PyCodeObject 构建的。
换句话说,在编译时,函数体里面的代码会位于一个新的 PyCodeObject 对象当中,所以函数的声明和实现是分离的。
至此,函数的结构就已经非常清晰了。
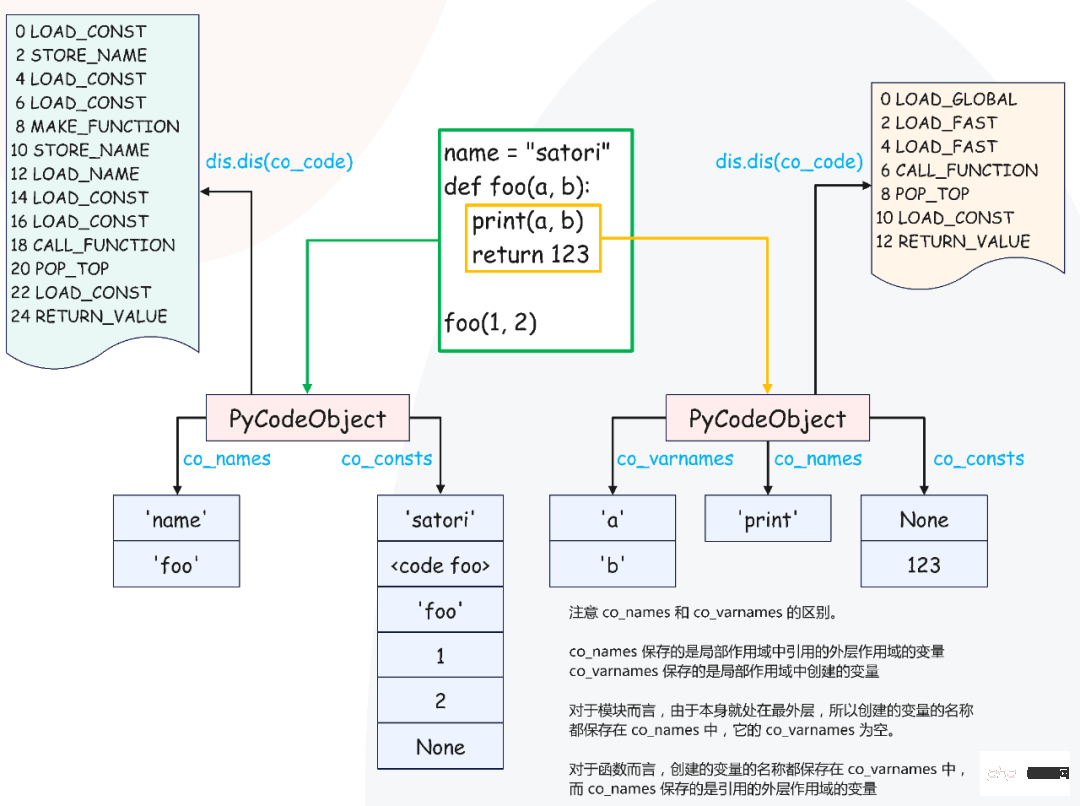
所以函数名和函数体是分离的,它们存储在不同的 PyCodeObject 对象当中。
分析完结构之后,重点就要落在 MAKE_FUNCTION 指令上了,我们说当遇到 def foo(a, b) 的时候,就知道要创建函数了。在语法上这是函数的声明语句,但从虚拟机的角度来看这其实是函数对象的创建语句。
所以下面我们就要分析一下这个指令,看看它到底是怎么将一个 PyCodeObject 对象变成一个 PyFunctionObject 对象的。
case TARGET(MAKE_FUNCTION): {
// 弹出压入运行时栈的函数名
PyObject *qualname = POP();
// 弹出对应的 PyCodeObject 对象
PyObject *codeobj = POP();
// 创建 PyFunctionObject 对象,需要三个参数
// 分别是 PyCodeObject 对象、global 名字空间、函数的全限定名
// 我们看到创建函数的时候将 global 名字空间传递了进去
// 所以现在我们应该明白为什么函数可以调用 __globals__ 了
// 当然也明白为什么函数在局部变量找不到的时候可以去找全局变量了
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
// 减少引用计数
// 如果函数创建失败会返回 NULL,跳转至 error
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
// 编译时能够静态检测出函数有没有设置闭包、类型注解等属性
// 比如设置了闭包,那么 oparg & 0x08 为真
// 设置了类型注解,那么 oparg & 0x04 为真
// 如果条件为真,那么进行相关属性设置
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
func ->func_closure = POP();
}
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
// 将创建好的函数对象的指针压入运行时栈
// 下一个指令 STORE_NAME 会将它从运行时栈弹出
// 并用变量 foo 和它绑定起来,放入 local 空间中
PUSH((PyObject *)func);
DISPATCH();
}整个步骤很好理解,先通过 LOAD_CONST 将 PyCodeObject 对象和符号 foo 压入栈中。然后执行 MAKE_FUNCTION 的时候,将两者从栈中弹出,再加上当前栈帧对象中维护的 global 名字空间,三者作为参数传入 PyFunction_NewWithQualName 函数中,从而构建出相应的函数对象。
上面的函数比较简单,如果再加上类型注解、以及默认值,会有什么效果呢?
s = """
name = "satori"
def foo(a: int = 1, b: int = 2):
print(a, b)
foo(1, 2)
"""
import dis
dis.dis(compile(s, "func", "exec"))这里我们加上了类型注解和默认值,看看它的字节码指令会有什么变化?
0 LOAD_CONST 0 ('satori')
2 STORE_NAME 0 (name)
4 LOAD_CONST 7 ((1, 2))
6 LOAD_NAME 1 (int)
8 LOAD_NAME 1 (int)
10 LOAD_CONST 3 (('a', 'b'))
12 BUILD_CONST_KEY_MAP 2
14 LOAD_CONST 4 ()
16 LOAD_CONST 5 ('foo')
18 MAKE_FUNCTION 5 (defaults, annotations)
......
......
不难发现,在构建函数时会先将默认值以元组的形式压入运行时栈;然后再根据使用了类型注解的参数和类型构建一个字典,并将这个字典压入运行时栈。
后续创建函数的时候,会将默认值保存在 func_defaults 成员中,类型注解对应的字典会保存在 func_annotations 成员中。
def foo(a: int = 1, b: int = 2):
print(a, b)
print(foo.__defaults__)
print(foo.__annotations__)
# (1, 2)
# {'a': <class 'int'>, 'b': <class 'int'>}基于类型注解和描述符,我们便可以像静态语言一样,实现函数参数的类型约束。介绍完描述符之后,我们会举例说明。
函数的一些骚操作
我们通过一些骚操作,来更好地理解一下函数。
之前说
def f():
pass
print(type(f)) # <class 'function'>
# lambda匿名函数的类型也是 function
print(type(lambda: None)) # <class 'function'>那么下面就来创建函数:
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
# 得到PyCodeObject对象
code = f.__code__
# 根据类function创建函数对象
# 接收三个参数: PyCodeObject对象、名字空间、函数名
new_f = type(f)(code, globals(), "根据 f 创建的 new_f")
# 打印函数名
print(new_f.__name__) # 根据 f 创建的 new_f
# 调用函数
print(
new_f("古明地觉", 16)
) # name: 古明地觉, age: 16, gender: female是不是很神奇呢?另外我们说函数在访问变量时,显然先从自身的符号表中查找,如果没有再去找全局变量。这是因为,我们在创建函数的时候将 global 名字空间传进去了,如果我们不传递呢?
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
try:
new_f = type(f)(code, None, "根据 f 创建的 new_f")
except TypeError as e:
print(e)
"""
function() argument 'globals' must be dict, not None
"""
# 这里告诉我们 function 的第二个参数 globals 必须是一个字典
# 我们传递一个空字典
new_f1 = type(f)(code, {}, "根据 f 创建的 new_f1")
# 打印函数名
print(new_f1.__name__) # 根据 f 创建的 new_f1
# 调用函数
try:
print(new_f1("古明地觉", 16))
except NameError as e:
print(e)
"""
name 'gender' is not defined
"""
# 我们看到提示 gender 没有定义因此现在我们又从 Python 的角度理解了一遍,为什么函数能够在局部变量找不到的时候,去找全局变量。原因就在于构建函数的时候,将 global 名字空间交给了函数,使得函数可以在 global 空间进行变量查找,所以它才能够找到全局变量。而我们这里给了一个空字典,那么显然就找不到 gender 这个变量了。
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
new_f = type(f)(code, {"gender": "少女觉"}, "根据 f 创建的 new_f")
# 我们可以手动传递一个字典进去
# 此时我们传递的字典对于函数来说就是 global 名字空间
# 所以在函数内部找不到某个变量的时候, 就会去我们指定的名字空间中查找
print(new_f("古明地觉", 16))
"""
name: 古明地觉, age: 16, gender: 少女觉
"""
# 所以此时的 gender 不再是外部的 "female"
# 而是我们指定的 "少女觉"此外我们还可以为函数指定默认值:
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
# 必须接收一个PyTupleObject对象
f.__defaults__ = ("古明地觉", 16, "female")
print(f())
"""
name: 古明地觉, age: 16, gender: female
"""我们看到函数 f 明明接收三个参数,但是调用时不传递居然也不会报错,原因就在于我们指定了默认值。而默认值可以在定义函数的时候指定,也可以通过 __defaults__ 指定,但很明显我们应该通过前者来指定。
如果你用的是 pycharm,那么会在 f() 这个位置给你飘黄,提示你参数没有传递。但我们知道,由于使用 __defaults__ 已经设置了默认值,所以这里是不会报错的。只不过 pycharm 没有检测到,当然基本上所有的 IDE 都无法做到这一点,毕竟动态语言。
另外 __defaults__ 接收的元组里面的元素个数和参数个数不匹配怎么办?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = (15, "female")
print(f("古明地恋"))
"""
name: 古明地恋, age: 15, gender: female
"""由于元组里面只有两个元素,意味着我们在调用时需要至少传递一个参数,而这个参数会赋值给 name。原因就是在设置默认值的时候是从后往前设置的,也就是 "female" 会给赋值给 gender,15 会赋值给 age。而 name 没有得到默认值,那么它就需要调用者显式传递了。
为啥 Python 在设置默认值是从后往前设置呢?如果从前往后设置的话,会出现什么后果呢?显然此时 15 会赋值给 name,"female" 会赋值给 age,那么函数就等价于如下:
def f(name=15, age="female", gender):
return f"name: {name}, age: {age}, gender: {gender}"这样的函数能够通过编译吗?显然是不行的,因为默认参数必须在非默认参数的后面。所以 Python 的这个做法是完全正确的,必须要从后往前进行设置。
另外我们知道默认值的个数是小于等于参数个数的,如果大于会怎么样呢?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = ("古明地觉", "古明地恋", 15, "female")
print(f())
"""
name: 古明地恋, age: 15, gender: female
"""依旧从后往前进行设置,当所有参数都有默认值了,那么就结束了。当然,如果不使用 __defaults__,是不可能出现默认值个数大于参数个数的。
可要是 __defaults__ 指向的元组先结束,那么没有得到默认值的参数就必须由我们来传递了。
最后再来说一下如何深拷贝一个函数。首先如果是你的话,你会怎么拷贝一个函数呢?不出意外的话,你应该会使用 copy 模块。
import copy
def f(a, b):
return [a, b]
# 但是问题来了,这样能否实现深度拷贝呢?
new_f = copy.deepcopy(f)
f.__defaults__ = (2, 3)
print(new_f()) # [2, 3]修改 f 的 __defaults__,会对 new_f 产生影响,因此我们并没有实现函数的深度拷贝。事实上,copy 模块无法对函数、方法、回溯栈、栈帧、模块、文件、套接字等类型的实例实现深度拷贝。
那我们应该怎么做呢?
from types import FunctionType
def f(a, b):
return "result"
# FunctionType 就是函数的类型对象
# 它也是通过 type 得到的
new_f = FunctionType(f.__code__,
f.__globals__,
f.__name__,
f.__defaults__,
f.__closure__)
# 显然 function 还可以接收第四个参数和第五个参数
# 分别是函数的默认值和闭包
# 然后别忘记将属性字典也拷贝一份
# 由于函数的属性字典几乎用不上,这里就浅拷贝了
new_f.__dict__.update(f.__dict__)
f.__defaults__ = (2, 3)
print(f.__defaults__) # (2, 3)
print(new_f.__defaults__) # None此时修改 f 不会影响 new_f,当然在拷贝的时候也可以自定义属性。
其实上面实现的深拷贝,本质上就是定义了一个新的函数。由于是两个不同的函数,那么自然就没有联系了。
判断函数都有哪些参数
再来看看如何检测一个函数有哪些参数,首先函数的局部变量(包括参数)在编译时就已经确定,会存在符号表 co_varnames 中。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
print(varnames)
"""
('a', 'b', 'c', 'd', 'e', 'f', 'args', 'kwargs', 'g', 'h')
"""注意:在定义函数的时候,* 和 ** 最多只能出现一次。
显然 a 和 b 必须通过位置参数传递,c 和 d 可以通过位置参数和关键字参数传递,e 和 f 必须通过关键字参数传递。
而从打印的符号表来看,里面的符号是有顺序的。参数永远处于函数内部定义的局部变量的前面,比如 g 和 h 就是函数内部定义的局部变量,所以它在所有参数的后面。
而对于参数,* 和 ** 会位于最后面,其它参数位置不变。所以除了 g 和 h,最后面的就是 args 和 kwargs。
那么接下来我们就可以进行检测了。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
# 1. 寻找必须通过位置参数传递的参数
posonlyargcount = f.__code__.co_posonlyargcount
print(posonlyargcount) # 2
print(varnames[: posonlyargcount]) # ('a', 'b')
# 2. 寻找既可以通过位置参数传递、又可以通过关键字参数传递的参数
argcount = f.__code__.co_argcount
print(argcount) # 4
print(varnames[: 4]) # ('a', 'b', 'c', 'd')
print(varnames[posonlyargcount: 4]) # ('c', 'd')
# 3. 寻找必须通过关键字参数传递的参数
kwonlyargcount = f.__code__.co_kwonlyargcount
print(kwonlyargcount) # 2
print(varnames[argcount: argcount + kwonlyargcount]) # ('e', 'f')
# 4. 寻找 *args 和 **kwargs
flags = f.__code__.co_flags
# 在介绍 PyCodeObject 的时候,我们说里面有一个 co_flags 成员
# 它是函数的标识,可以对函数类型和参数进行检测
# 如果co_flags和 4 进行按位与之后为真,那么就代表有* args, 否则没有
# 如果co_flags和 8 进行按位与之后为真,那么就代表有 **kwargs, 否则没有
step = argcount + kwonlyargcount
if flags & 0x04:
print(varnames[step]) # args
step += 1
if flags & 0x08:
print(varnames[step]) # kwargs以上我们检测出了函数都有哪些参数,你也可以将其封装成一个函数,实现代码的复用。
然后需要注意一下 args 和 kwargs,打印的内容主要取决定义时使用的名字。如果定义的时候是 *ARGS 和 **KWARGS,那么这里就会打印 ARGS 和 KWARGS,只不过一般我们都叫做 *args 和 **kwargs。
但如果我们定义的时候不是 *args,只是一个 *,那么它就不是参数了。
def f(a, b, *, c):
pass
# 我们看到此时只有a、b、c
print(f.__code__.co_varnames) # ('a', 'b', 'c')
print(f.__code__.co_flags & 0x04) # 0
print(f.__code__.co_flags & 0x08) # 0
# 显然此时也都为假单独的一个 * 只是为了强制要求后面的参数必须通过关键字参数的方式传递。
函数是怎么调用的
到目前为止,我们聊了聊 Python 函数的底层实现,并且还演示了如何通过函数的类型对象自定义一个函数,以及如何获取函数的参数。虽然这在工作中没有太大意义,但是可以让我们深刻理解函数的行为。
下面我来探讨一下函数在底层是怎么调用的,但是在介绍调用之前,我们需要补充一个知识点。
def foo():
pass
print(type(foo))
print(type(sum))
"""
<class 'function'>
<class 'builtin_function_or_method'>
"""函数实际上分为两种:
如果是 Python 实现的函数,底层会对应 PyFunctionObject。其类型在 Python 里面是
,在底层是 PyFunction_Type; 如果是 C 实现的函数,底层会对应 PyCFunctionObject。其类型在 Python 里面是
,在底层是 PyCFunction_Type;
像内置函数、使用 C 扩展编写的函数,它们都是 PyCFunctionObject。
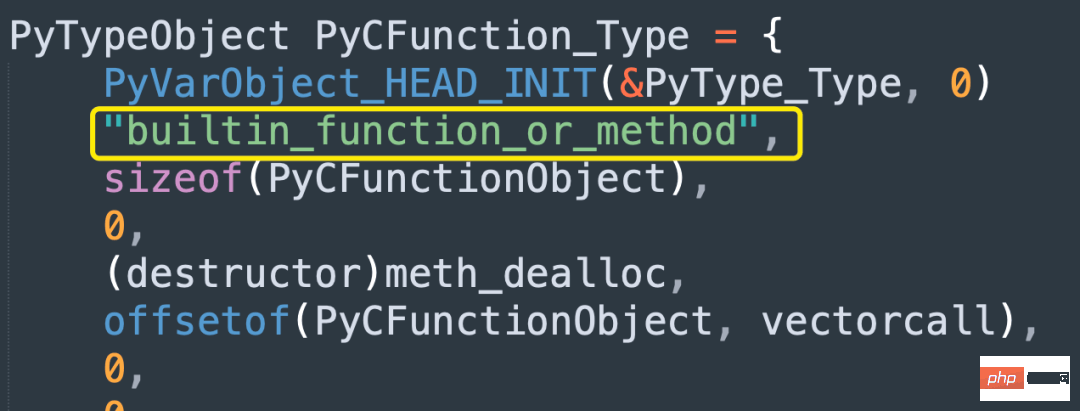
另外从名字上可以看出 PyCFunctionObject 不仅用于 C 实现的函数,还用于方法。关于方法,我们后续在介绍类的时候细说,这里暂时不做深入讨论。
总之对于 Python 函数和 C 函数,底层在实现的时候将两者分开了,因为 C 函数可以有更快的执行方式。
注意这里说的 C 函数,指的是 C 实现的 Python 函数。像内置函数就是 C 实现的,比如 sum、getattr 等等。
好了,下面来看函数调用的具体细节。
s = """
def foo():
a, b = 1, 2
return a + b
foo()
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "<...>", "exec"))还是以一个简单的函数为例,看看它的字节码:
# 遇见 def 表示构建函数 # 于是加载 PyCodeObject 对象和函数名 "foo" 0 LOAD_CONST 0 (<code object foo at 0x7f...>) 2 LOAD_CONST 1 ('foo') # 构建函数对象,压入运行时栈 4 MAKE_FUNCTION 0 # 从栈中弹出函数对象,用变量 foo 保存 6 STORE_NAME 0 (foo) # 将变量 foo 压入运行时栈 8 LOAD_NAME 0 (foo) # 从栈中弹出 foo,执行 foo(),也就是函数调用,这一会要剖析的重点 10 CALL_FUNCTION 0 # 从栈顶弹出返回值 12 POP_TOP # return None 14 LOAD_CONST 2 (None) 16 RETURN_VALUE Disassembly of <code object foo at 0x7...>: # 函数的字节码,因为模块和函数都会对应 PyCodeObject # 只不过后者在前者的常量池中 # 加载元组常量 (1, 2) 0 LOAD_CONST 1 ((1, 2)) # 解包,将常量压入运行时栈 2 UNPACK_SEQUENCE 2 # 再从栈中弹出,分别赋值给 a 和 b 4 STORE_FAST 0 (a) 6 STORE_FAST 1 (b) # 加载 a 和 b 8 LOAD_FAST 0 (a) 10 LOAD_FAST 1 (b) # 执行加法运算 12 BINARY_ADD # 将相加之和的值返回 14 RETURN_VALUE
相信现在看字节码已经不是什么问题了,然后我们看到调用函数用的是 CALL_FUNCTION 指令,那么这个指令都做了哪些事情呢?
case TARGET(CALL_FUNCTION): {
PREDICTED(CALL_FUNCTION);
PyObject **sp, *res;
// 指向运行时栈的栈顶
sp = stack_pointer;
// 调用函数,将返回值赋值给 res
// tstate 表示线程状态对象
// &sp 是一个三级指针,oparg 表示指令的操作数
res = call_function(tstate, &sp, oparg, NULL);
// 函数执行完毕之后,sp 会指向运行时栈的栈顶
// 所以再将修改之后的 sp 赋值给 stack_pointer
stack_pointer = sp;
// 将 res 压入栈中:*stack_pointer++ = res
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}CALL_FUNCTION 这个指令之前提到过,但是函数的核心执行流程是在 call_function 里面,它位于 ceval.c 中,我们来看一下。


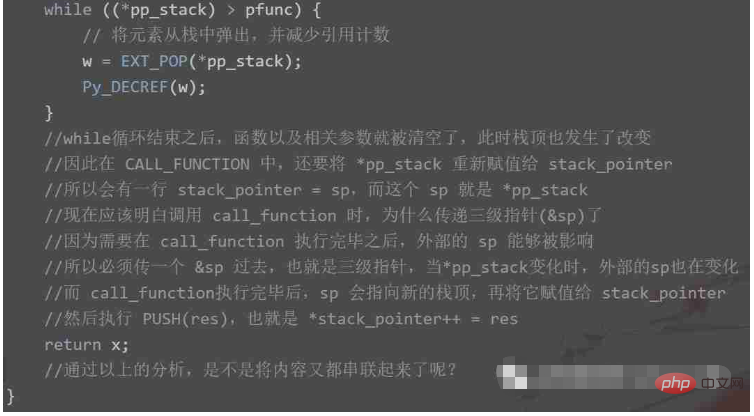
因此接下来重点就在 _PyObject_Vectorcall 函数上面,在该函数内部又会调用其它函数,最终会走到 _PyFunction_FastCallDict 这里。
//Objects/call.c
PyObject *
_PyFunction_FastCallDict(PyObject *func, PyObject *const *args, Py_ssize_t nargs,
PyObject *kwargs)
{
//获取PyCodeObject对象
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
//获取global名字空间
PyObject *globals = PyFunction_GET_GLOBALS(func);
//获取默认值
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
//....
//我们观察一下下面的return
//一个是function_code_fastcall,一个是最后的_PyEval_EvalCodeWithName
//从名字上能看出来function_code_fastcall是一个快分支
//但是这个快分支要求函数调用时不能传递关键字参数
if (co->co_kwonlyargcount == 0 &&
(kwargs == NULL || PyDict_GET_SIZE(kwargs) == 0) &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
/* Fast paths */
if (argdefs == NULL && co->co_argcount == nargs) {
//function_code_fastcall里面逻辑很简单
//直接抽走当前PyFunctionObject里面PyCodeObject和global名字空间
//根据PyCodeObject对象直接为其创建一个PyFrameObject对象
//然后PyEval_EvalFrameEx执行栈帧
//也就是真正的进入了函数调用,执行函数里面的代码
return function_code_fastcall(co, args, nargs, globals);
}
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
/* function called with no arguments, but all parameters have
a default value: use default values as arguments .*/
args = _PyTuple_ITEMS(argdefs);
return function_code_fastcall(co, args, PyTuple_GET_SIZE(argdefs),
globals);
}
}
//适用于有关键字参数的情况
nk = (kwargs != NULL) ? PyDict_GET_SIZE(kwargs) : 0;
//.....
//调用_PyEval_EvalCodeWithName
result = _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
args, nargs,
k, k != NULL ? k + 1 : NULL, nk, 2,
d, nd, kwdefs,
closure, name, qualname);
Py_XDECREF(kwtuple);
return result;
}所以函数调用时会有两种方式:
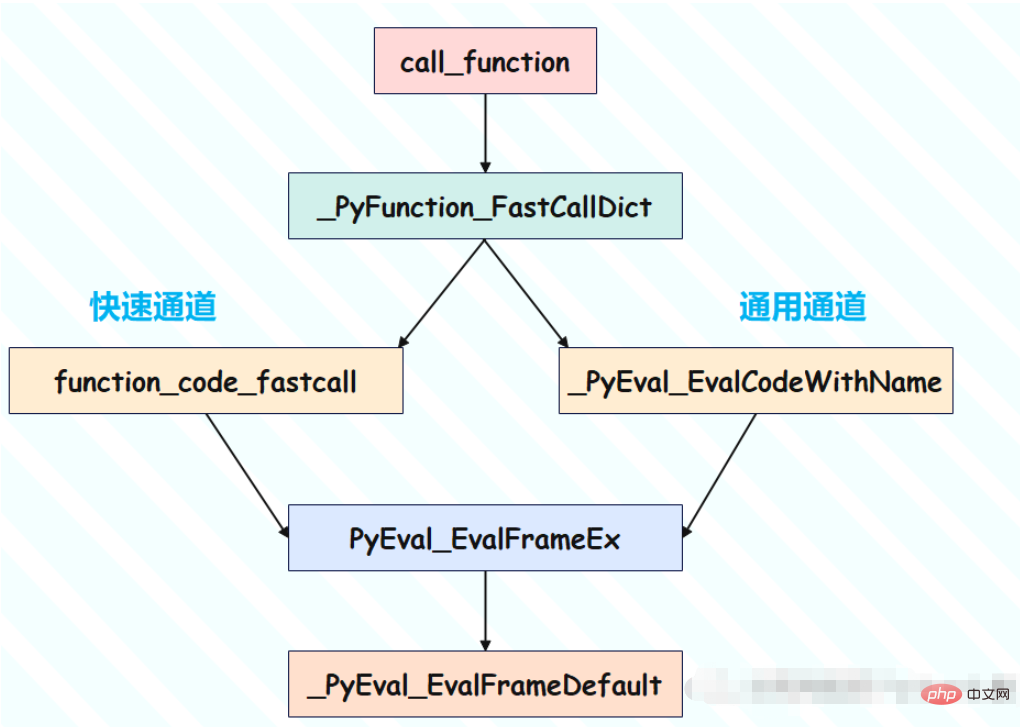
因此我们看到,总共有两条途径,分别针对有无关键字参数。但是最终殊途同归,都会走到 PyEval_EvalFrameEx 那里,然后虚拟机在新的栈帧中执行新的 PyCodeObject。
不过可能有人会好奇,我们之前说过:
PyFrameObject 是根据 PyCodeObject 创建的
PyFunctionObject 也是根据 PyCodeObject 创建的
那么 PyFrameObject 和 PyFunctionObject 之间有啥关系呢?
如果把 PyCodeObject 比喻成妹子,那么 PyFunctionObject 就是妹子的备胎,PyFrameObject 就是妹子的心上人。
其实在栈帧中执行指令时候,PyFunctionObject 的影响就已经消失了,真正对栈帧产生影响的是PyFunctionObject 里面的 PyCodeObject 对象和 global 名字空间。
也就是说,最终是 PyFrameObject 和 PyCodeObject 两者如胶似漆,跟 PyFunctionObject 之间没有关系,所以 PyFunctionObject 辛苦一场,实际上是为别人做了嫁衣。PyFunctionObject 主要是对 PyCodeObject 和 global 名字空间的一种打包和运输方式。
위 내용은 Python 함수의 구현 원리는 무엇입니까의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7487
7487
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench는 구성이 올바른 경우 MariadB에 연결할 수 있습니다. 먼저 커넥터 유형으로 "mariadb"를 선택하십시오. 연결 구성에서 호스트, 포트, 사용자, 비밀번호 및 데이터베이스를 올바르게 설정하십시오. 연결을 테스트 할 때는 마리아드 브 서비스가 시작되었는지, 사용자 이름과 비밀번호가 올바른지, 포트 번호가 올바른지, 방화벽이 연결을 허용하는지 및 데이터베이스가 존재하는지 여부를 확인하십시오. 고급 사용에서 연결 풀링 기술을 사용하여 성능을 최적화하십시오. 일반적인 오류에는 불충분 한 권한, 네트워크 연결 문제 등이 포함됩니다. 오류를 디버깅 할 때 오류 정보를 신중하게 분석하고 디버깅 도구를 사용하십시오. 네트워크 구성을 최적화하면 성능이 향상 될 수 있습니다
 MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
생산 환경의 경우 성능, 신뢰성, 보안 및 확장 성을 포함한 이유로 서버는 일반적으로 MySQL을 실행해야합니다. 서버에는 일반적으로보다 강력한 하드웨어, 중복 구성 및 엄격한 보안 조치가 있습니다. 소규모 저하 애플리케이션의 경우 MySQL이 로컬 컴퓨터에서 실행할 수 있지만 자원 소비, 보안 위험 및 유지 보수 비용은 신중하게 고려되어야합니다. 신뢰성과 보안을 높이려면 MySQL을 클라우드 또는 기타 서버에 배포해야합니다. 적절한 서버 구성을 선택하려면 응용 프로그램 부하 및 데이터 볼륨을 기반으로 평가가 필요합니다.
