

Java 기반 분산 서비스 프레임워크 Dubbo의 원리 및 사례 분석

머리말
Dubbo를 소개하기 전에 기본 개념을 이해해 봅시다.
Dubbo는 RPC 프레임워크, RPC, 즉 Remote Procedure입니다. Call (원격 프로시저 호출), 그 반대는 로컬 프로시저 호출입니다. 분산 아키텍처 이전에는 단일 애플리케이션 아키텍처와 수직 애플리케이션 아키텍처에서 로컬 프로시저 호출을 사용했습니다. 이를 통해 프로그래머는 원격 호출의 세부 사항을 명시적으로 코딩하지 않고도 프로그램이 다른 주소 공간(일반적으로 네트워크에서 공유되는 다른 시스템)의 프로시저나 함수를 호출할 수 있습니다. <code>RPC框架,RPC,即Remote Procedure Call(远程过程调用),相对的就是本地过程调用,在分布式架构之前的单体应用架构和垂直应用架构运用的都是本地过程调用。它允许程序调用另外一个地址空间(通常是网络共享的另外一台机器)的过程或函数,并且不用程序员显式编码这个远程调用的细节。
而分布式架构应用与应用之间的远程调用就需要RPC框架来做,目的就是为了让远程调用像本地调用一样简单。
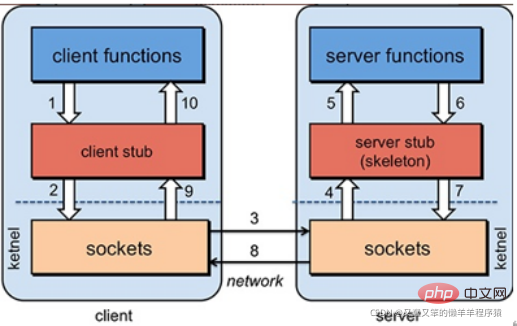
Dubbo框架有以下部件
Consumer
即调用远程服务的服务消费方,消费者需要面向接口编程,知道了哪些接口可以调用了,具体实现需要框架提供一个代理类来为接口提供具体实现,让消费者只管调用什么接口,而具体实现的获取由代理类来处理。
消费者还需要提供调用方法名以及方法的参数值。
但是代理类此时还不知道需要调用哪个服务器上的远程方法,此时需要一个注册中心,通过注册中心获取可以调用的远程服务列表。
远程服务器一般都是集群部署,那么调用哪个服务器则需要通过负载均衡来选择一个最合适的服务器来调用。
同时还需要有集群容错机制,因为各种原因,可能远程调用会失败,此时需要容错机制来重试调用,保证远程调用的稳定性。
同时与服务提供方约定好通信协议和序列化格式,方便通信以及数据传输。
Provider
即暴露服务的服务提供方,服务提供方内部实现具体的接口,然后将接口暴露出去,再将服务注册到注册中心,服务消费方调用服务,提供者接收到调用请求后,通过约定好的通信协议来处理该请求,然后做反序列化,完成后,将请求放入线程池中处理,某个线程接收到这个请求然后找到对应的接口实现进行调用,然后将调用结果原路返回。
Registry
即服务注册与发现的注册中心,注册中心负责服务地址的注册与查找,相当于服务目录,服务提供者和消费者只会再启动时与注册中心交互,注册中心不转发请求,压力小。
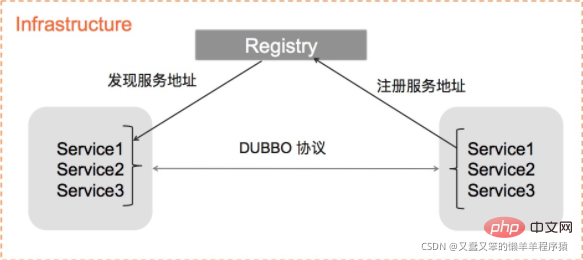
注册中心还可以集中化处理配置以及动态地将变更通知订阅方。
但是为什么需要注册中心呢?没有注册中心不可以吗?
在没有注册中心,各服务之间的调用关系是这样的:
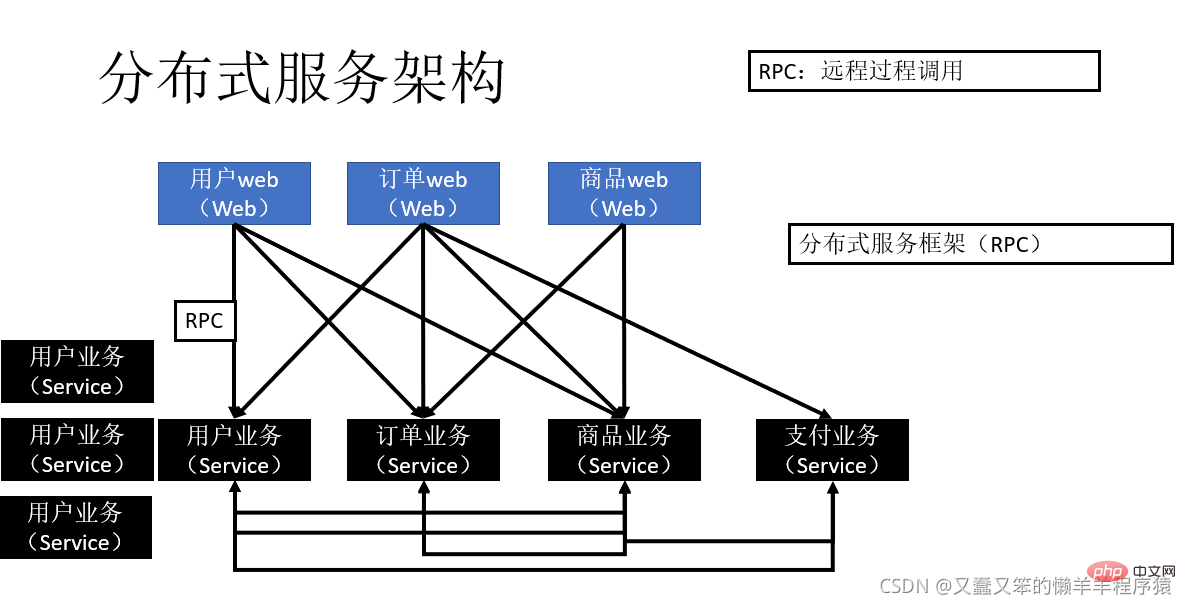
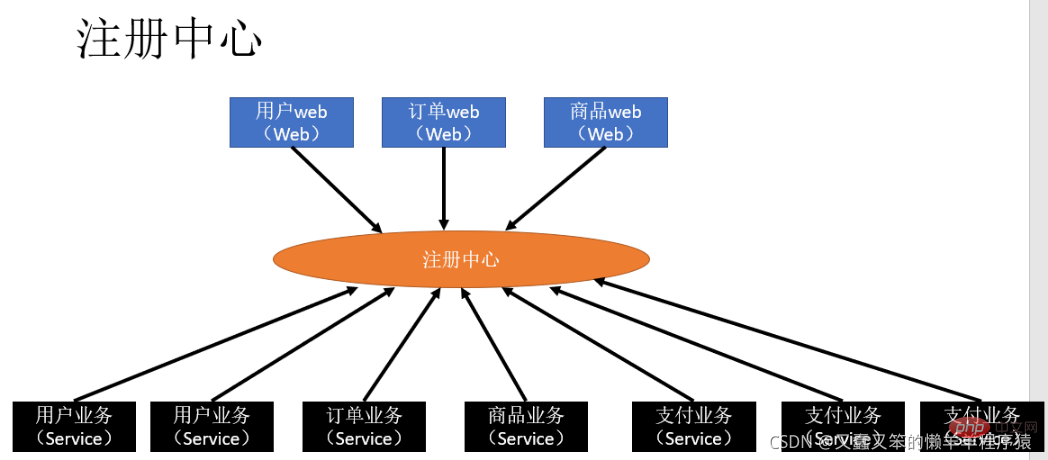
当服务越来越多时,服务URL配置管理变得非常困难,硬件负载均衡器的单点压力也越来越大,而有了注册中心之后,就可以实现服务的统一管理,并且实现软负载均衡,降低硬件成本,以下为注册中心示意图:
Monitor
即统计服务调用次数和调用时间的监控中心,面对众多服务,精细化的监控和方便的运维是不可或缺的,对后期维护相当重要。
Container
即服务运行的容器。
架构
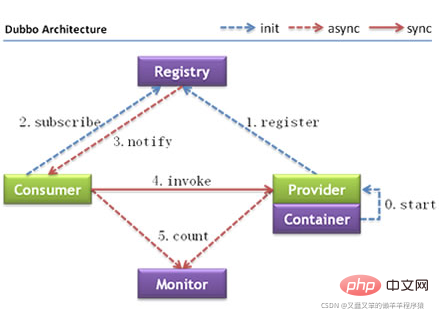
图中的各个节点充当的角色已经介绍过了,以下是各节点之间调用关系:
Container服务容器负责启动,加载以及运行
Provider服务提供者Provider服务提供者启动时,需要将自身暴露出去让远程服务器可以发现,同时向Registry注册中心注册自己提供的服务
Consumer服务消费者启动时,向Registry注册中心订阅所需要的服务
Registry
RPC 프레임워크가 필요합니다. 🎜🎜🎜 🎜 Dubbo 프레임워크에는 다음과 같은 구성 요소가 있습니다.🎜Consumer
🎜즉, 원격 서비스를 호출하는 서비스 소비자입니다. 소비자는 어떤 인터페이스를 호출할 수 있는지 알기 위해 인터페이스 지향 프로그래밍이 필요합니다. 인터페이스에 대한 프록시 클래스는 특정 구현을 제공하므로 소비자는 어떤 인터페이스를 호출하기만 하면 되며 특정 구현의 획득은 프록시 클래스에 의해 처리됩니다. 🎜🎜소비자는 호출 메서드 이름과 메서드 매개변수 값도 제공해야 합니다. 🎜🎜그러나 이때 프록시 클래스는 서버에서 어떤 원격 메서드를 호출해야 하는지 아직 알지 못합니다. 이때 호출할 수 있는 원격 서비스 목록을 얻으려면 등록 센터가 필요합니다. 🎜🎜원격 서버는 일반적으로 클러스터에 배포되므로 어떤 서버를 호출할지에 가장 적합한 서버를 선택하기 위한 로드 밸런싱이 필요합니다. 🎜🎜동시에 여러 가지 이유로 원격 호출이 실패할 수 있는 경우 원격 호출의 안정성을 보장하기 위해 호출을 재시도하는 내결함성 메커니즘도 필요합니다. . 🎜🎜동시에 원활한 통신 및 데이터 전송을 위해 서비스 제공자와 통신 프로토콜 및 직렬화 형식에 동의하세요. 🎜Provider
🎜즉, 서비스를 노출하는 서비스 제공자입니다. 서비스 제공자는 내부적으로 특정 인터페이스를 구현한 후 해당 인터페이스를 노출한 후 서비스 소비자를 호출합니다. 서비스 제공자는 이를 수신한 후 합의된 통신 프로토콜을 통해 요청을 처리한 후 역직렬화하여 처리를 위해 스레드 풀에 넣습니다. 호출할 해당 인터페이스 구현을 찾은 다음 호출 결과를 원래 경로로 반환합니다. 🎜레지스트리
🎜서비스 등록 및 검색을 위한 등록 센터입니다. 등록 센터는 서비스 주소 등록 및 검색을 담당하며, 이는 서비스 공급자와 소비자만 상호 작용합니다. 등록 센터는 요청을 전달하지 않으므로 부담이 거의 없습니다. 🎜🎜🎜 🎜 또한 등록 센터는 구성을 중앙에서 처리하고 가입자에게 변경 사항을 동적으로 알릴 수도 있습니다. 🎜🎜그런데 등록센터가 왜 필요한가요? 등록센터 없이는 불가능한가요? 🎜🎜등록 센터가 없는 경우 서비스 간의 호출 관계는 다음과 같습니다. 🎜🎜🎜🎜서비스가 많아지면 서비스 URL 구성 관리가 매우 어려워지고 하드웨어 로드 밸런서에 대한 단일 지점 압력도 증가하며, 등록 센터를 사용하면 서비스 통합 관리가 가능하고 소프트 로드 밸런싱이 가능하며 하드웨어 비용을 줄일 수 있습니다. 다음은 등록 센터의 개략도입니다. 🎜🎜🎜모니터
🎜즉, 서비스 호출 횟수와 호출 시간을 계산하는 모니터링 센터, 다양한 서비스에 직면하여 정교한 모니터링과 편리한 운영 및 유지 관리는 필수이며 향후 유지 관리에 매우 중요합니다. 🎜컨테이너
🎜서비스가 실행되는 컨테이너입니다. 🎜🎜Architecture🎜🎜🎜🎜그림에서 각 노드가 수행하는 역할은 다음과 같습니다. 각 노드 간의 호출 관계는 다음과 같습니다. 🎜🎜컨테이너서비스 컨테이너는 시작, 로드 및 실행을 담당합니다🎜🎜공급자 서비스 공급자공급자서비스 공급자가 시작되면 원격 서버가 이를 검색할 수 있도록 자신을 노출해야 하며 동시에 제공하는 서비스를 Registry 등록 센터🎜 🎜 Consumer 서비스 컨슈머가 시작되면 필수 서비스 🎜🎜RegistryRegistry 등록 센터에 가입합니다. /code> 등록 센터는 서비스 제공자 목록을 소비자에게 반환합니다. 동시에 변경 사항이 발생하면 등록 센터는 긴 연결을 기반으로 소비자에게 실시간 데이터를 푸시합니다🎜서비스 소비자가 원격 서비스를 호출해야 하는 경우 호출할 로드 밸런싱 알고리즘을 기반으로 공급자의 주소 목록에서 공급자 서버를 선택합니다. 호출이 실패하면 클러스터 내결함성 전략에 따라 호출이 재시도됩니다.
서비스 소비 통신사와 제공자는 메모리에 있는 통화 횟수와 통화 시간을 계산한 후 예약된 작업을 통해모니터 모니터링 센터에 데이터를 보냅니다
고가용성
-
Monitor监控中心高可用性
监控中心宕机后不会对服务造成影响,只是丢失部分统计数据
注册中心集群后,任意一台宕机后,将自动切换到其他注册中心
当所有注册中心均宕机后,服务提供者和消费者之间仍然能通过本地记录了彼此信息的缓存进行通讯,但是如果一方产生变更,另外一方无法感知
服务提供者无状态,任意一台服务器宕机后不影响使用,会有其他服务提供者提供服务
当所有服务提供者宕机后,服务消费者无法正常使用,将进行无限次重连等待服务提供者重新连线恢复
框架设计

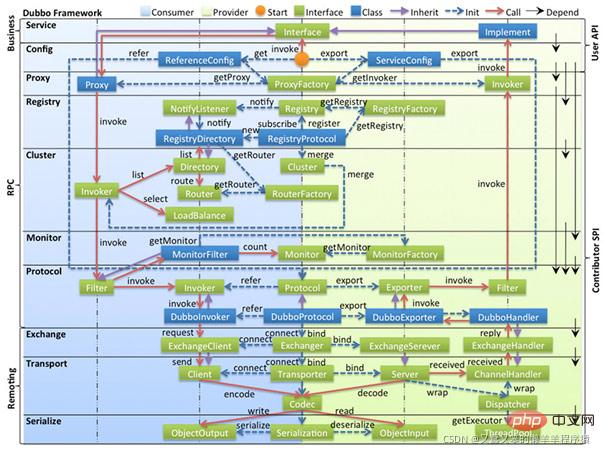
大的分层为Business(业务逻辑层)、RPC层和Remoting层。
再细分下来,Dubbo一共有十层架构,作用分别如下:
Service,业务层,即日常开发中的业务逻辑层Config,配置层,对外配置接口,以ServiceConfig和ReferenceConfig为中心,可以直接初始化配置类,也可以通过Spring解析配置生成配置类Proxy,服务代理层,服务接口透明代理,生成服务的客户端Stub和客户端Skeleton,负责远程调用和返回结果Registry,注册中心层,封装服务地址的注册与发现,以服务URL为中心,拓展接口为RegistryFactory,Registry,RegistryServiceCluster路由和集群容错层,封装了多个提供者的路由、负载均衡以及集群容错,并桥接注册中心,负责通过负载均衡选取调用具体的节点,处理特殊调用请求和负责远程调用失败的容错措施Monitor,监控层,负责监控统计RPC调用次数和调用时间Portocol,远程调用层,主要封装RPC远程调用方法Exchange,信息交换层,用于封装请求响应模型Transport,网络传输层,抽象化网络传输统一接口,有Mina和Netty可供使用Serialize,序列化层,将数据序列化成二进制流进行传输,也可以反序列化接收数据服务暴露过程
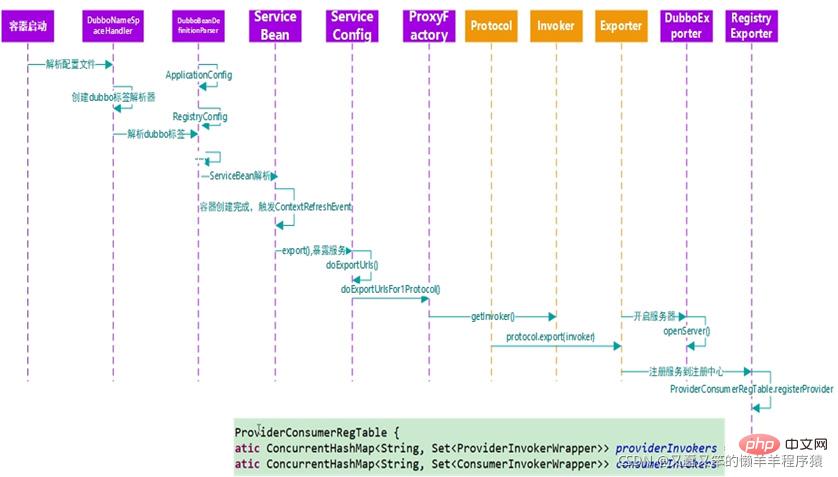
首先Provider启动,Protocal通过Proxy代理将需要暴露的接口封装成Invoker,是一个可执行体,然后通过Exporter包装并发送到注册中心完成注册,至此服务就暴露完成。
服务消费过程
注:上图中蓝色部分为服务消费者,绿色部分为服务提供者。
服务消费者启动时会向注册中心订阅并拉取所需服务提供者的信息,并保存到本地缓存,由此即使所有注册中心宕机后,服务提供者和服务消费者也可以通过本地缓存进行通讯,只是一方出现了信息变更,另一方无法感知,但并不影响服务的进行。
之后整个服务消费流程从图中的Proxy开始,由代理类完成处理,以此到达透明无感知。
ProxyFactory生成一个Proxy代理类,Proxy持有一个Invoker可执行对象,调用invoke之后需要通过Cluster从Directory中获取所有可调用的远程服务Invoker列表,如果配置了某些路由规则,还需要再过滤一遍Invoker列表。剩下的Invoker再通过
LoadBalance做负载均衡选取一个,还需要再通过Filter进行一些数据统计,之后将这些数据保存下来,定时发送给Monitor。接下来用
Client做数据传输,一般用Netty进行传输。传输需要通过
Codec接口进行协议构造,然后再通过Serialization모니터링 센터가 다운된 후에도 서비스에는 영향을 미치지 않지만 일부 통계 데이터는 손실됩니다 - 🎜센터 등록 후 클러스터 중 하나가 다운되면 자동으로 다른 등록 센터로 전환됩니다🎜
- 🎜모든 등록 센터가 다운되더라도 서비스 제공자와 소비자는 로컬에서 서로의 정보를 기록하는 캐시를 통해 여전히 통신할 수 있습니다. 한쪽이 변경되면 다른 쪽은 감지할 수 없습니다. 🎜
- 🎜서비스 제공자는 무상태입니다. 서버가 다운되더라도 서비스를 제공하는 다른 서비스 제공자는 영향을 받지 않습니다. /li>
- 🎜모든 서비스가 제공되는 경우 서비스 제공자가 다운된 후 서비스 소비자는 정상적으로 사용할 수 없으며 무한정 재접속하여 서비스 제공자의 재접속 및 재개를 기다리게 됩니다🎜
프레임워크 설계
🎜 🎜🎜큰 계층은 비즈니스(비즈니스 로직 계층), RPC 계층 및 원격 계층입니다. 🎜🎜더 세분화하면 Dubbo는 총 10개의 아키텍처 계층을 가지며 기능은 다음과 같습니다. 🎜🎜
🎜🎜큰 계층은 비즈니스(비즈니스 로직 계층), RPC 계층 및 원격 계층입니다. 🎜🎜더 세분화하면 Dubbo는 총 10개의 아키텍처 계층을 가지며 기능은 다음과 같습니다. 🎜🎜Service, 비즈니스 계층, 일상적인 개발에서 비즈니스 로직 계층🎜🎜Config, 구성 레이어, 외부 구성 인터페이스, ServiceConfig 및 ReferenceConfig를 중심으로 구성 클래스를 직접 초기화하거나 구성 클래스를 생성할 수 있습니다. Spring의 구성🎜🎜프록시, 서비스 프록시 레이어, 서비스 인터페이스 투명 프록시 구문 분석을 통해 서비스의 클라이언트 Stub 및 클라이언트 Skeleton을 생성합니다. 원격 호출 및 결과 반환을 담당합니다. 등록 센터 계층인 🎜🎜 레지스트리는 서비스 URL을 중심으로 서비스 주소 등록 및 검색을 캡슐화하고 확장 인터페이스는 입니다. RegistryFactory, Registry, RegistryService🎜🎜<code>Cluster라우팅 및 클러스터 내결함성 계층은 라우팅, 로드 밸런싱 및 클러스터 내결함성을 캡슐화합니다. 여러 공급자의 로드 밸런싱을 통해 특정 노드를 선택 및 호출하고 특수 호출 요청 및 원격 호출 실패에 대한 내결함성 조치를 처리하는 등록 센터를 연결합니다.🎜🎜모니터, 모니터링 레이어 , RPC 호출 수 및 호출 시간🎜🎜Portocol을 모니터링하고 계산하는 역할을 담당하며 원격 호출 계층은 주로 RPC 원격 호출 방법 🎜🎜Exchange, 정보 교환 계층을 캡슐화합니다. , 요청 응답 모델 🎜🎜Transport, 네트워크 전송 계층을 캡슐화하는 데 사용되며 Mina 및 Netty를 사용하여 네트워크 전송 통합 인터페이스를 추상화합니다. 직렬화 계층인🎜🎜직렬화는 전송을 위해 데이터를 바이너리 스트림으로 직렬화하고 데이터를 역직렬화하고 수신할 수도 있습니다. 🎜서비스 노출 프로세스
🎜먼저, 공급자는 다음과 같습니다. 프로토콜은 Proxy 에이전트를 통해 Invoker에 노출되어야 하는 인터페이스를 실행 가능한 본체로 캡슐화한 다음 이를 내보내기를 통해 패키징하고 등록 센터로 보내 등록을 완료합니다. 서비스 노출이 완료되었습니다. 🎜🎜🎜 서비스 소비 프로세스🎜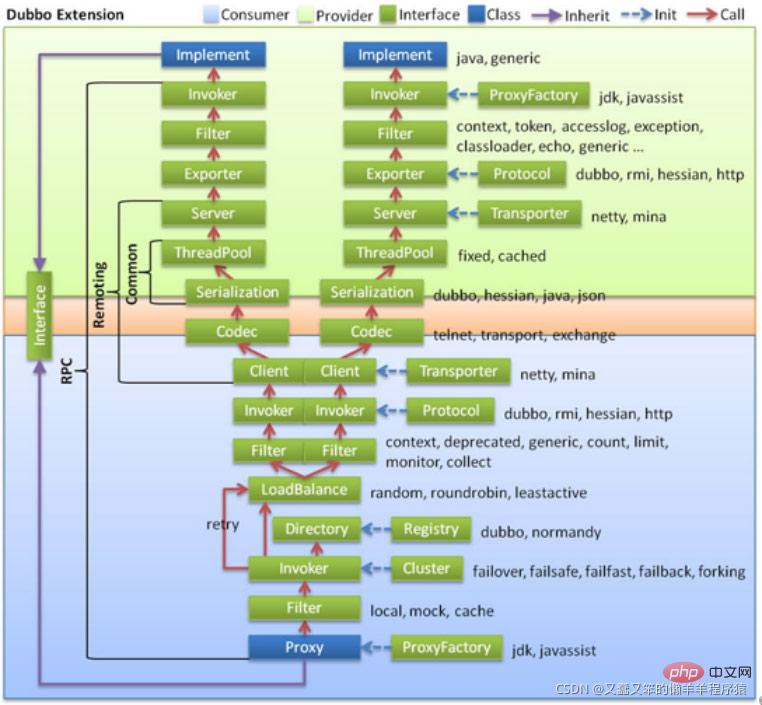 🎜🎜참고: 위 그림의 파란색 부분은 서비스 소비자, 녹색 부분은 서비스 제공자입니다. 🎜🎜서비스 소비자가 시작되면 등록 센터에 가입하고 필요한 서비스 공급자 정보를 가져와 로컬 캐시에 저장하므로 모든 등록 센터가 다운된 후에도 서비스 공급자와 서비스 소비자는 계속 액세스할 수 있습니다. 캐시는 로컬 캐시를 통해 로컬 서비스 제공자와 통신하지만, 한쪽에서 정보 변경이 있어도 상대방에서는 이를 감지할 수 없지만 서비스 진행에는 영향을 미치지 않습니다. 🎜🎜그러면 전체 서비스 소비 프로세스는 그림의 Proxy에서 시작하여 Proxy 클래스에 의해 처리되므로 투명성과 인식이 달성되지 않습니다. 🎜🎜
🎜🎜참고: 위 그림의 파란색 부분은 서비스 소비자, 녹색 부분은 서비스 제공자입니다. 🎜🎜서비스 소비자가 시작되면 등록 센터에 가입하고 필요한 서비스 공급자 정보를 가져와 로컬 캐시에 저장하므로 모든 등록 센터가 다운된 후에도 서비스 공급자와 서비스 소비자는 계속 액세스할 수 있습니다. 캐시는 로컬 캐시를 통해 로컬 서비스 제공자와 통신하지만, 한쪽에서 정보 변경이 있어도 상대방에서는 이를 감지할 수 없지만 서비스 진행에는 영향을 미치지 않습니다. 🎜🎜그러면 전체 서비스 소비 프로세스는 그림의 Proxy에서 시작하여 Proxy 클래스에 의해 처리되므로 투명성과 인식이 달성되지 않습니다. 🎜🎜ProxyFactory는 Proxy 프록시 클래스를 생성합니다. 프록시는 호출자 실행 가능 개체를 보유하고 있으며, invoke를 호출한 후 Cluster<code>디렉터리에서 호출 가능한 모든 원격 서비스 호출자 목록을 가져옵니다. 특정 라우팅 규칙이 구성된 경우 호출자 목록을 다시 필터링해야 합니다. 🎜🎜나머지 호출자는 LoadBalance를 통해 로드 밸런싱을 위해 선택되며, 필터를 통해 일부 데이터 통계를 수행한 다음 데이터를 저장하고 정기적으로 Monitor로 보내야 합니다. . 🎜🎜다음으로 데이터 전송에는 Client를 사용하고, 전송에는 일반적으로 Netty를 사용합니다. 🎜🎜전송에는 코덱 인터페이스를 통한 프로토콜 구성과 직렬화를 통한 직렬화가 필요하며, 최종적으로 직렬화된 바이너리 스트림은 해당 서비스 제공자에게 전송됩니다. 🎜바이너리 스트림을 수신한 후 서비스 제공자는 코덱 프로토콜 처리를 수행한 다음 역직렬화(여기서 처리는 전송 전 처리와 대칭임)한 다음 처리를 위해 요청을 스레드 풀에 넣습니다. 해당 Exporter 요청에 따라 필터를 통해 레이어별로 필터링하여 Invoker를 얻고 마지막으로 해당 구현 클래스를 호출하여 원래 방식으로 결과를 반환합니다.
위 내용은 Java 기반 분산 서비스 프레임워크 Dubbo의 원리 및 사례 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7461
7461
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
