
본 글은 AI 뉴미디어 큐빗(공개 계정 ID: QbitAI)의 승인을 받아 재인쇄되었습니다.
ChatGPT를 사용하여 블로그를 작성하면 실제로 하루에 10,000개 이상을 만들 수 있습니다!
농담이 아닙니다. 실제로 이런 일이 일어났습니다.

사건의 원인은 한 젊은 여성이 3,000단어 정도의 데이터 분석 기사 출판을 준비하던 중이었습니다.
하지만 데이터를 분석하는 동시에 텍스트 내용을 정리하는 것은 좀 번거롭다고 생각해서 아이디어가 떠올랐고 ChatGPT에 도움을 요청했습니다.
처음에는 결과에 큰 기대를 하지 않았는데, 수익 수치가 나오자 충격을 받았습니다.
일 수입2,000달러(약 14,000위안), 엄청나네요. 어렵다 AI가 쓴 글이 이렇게 큰 영향력을 발휘할 수 있다고 믿어요!
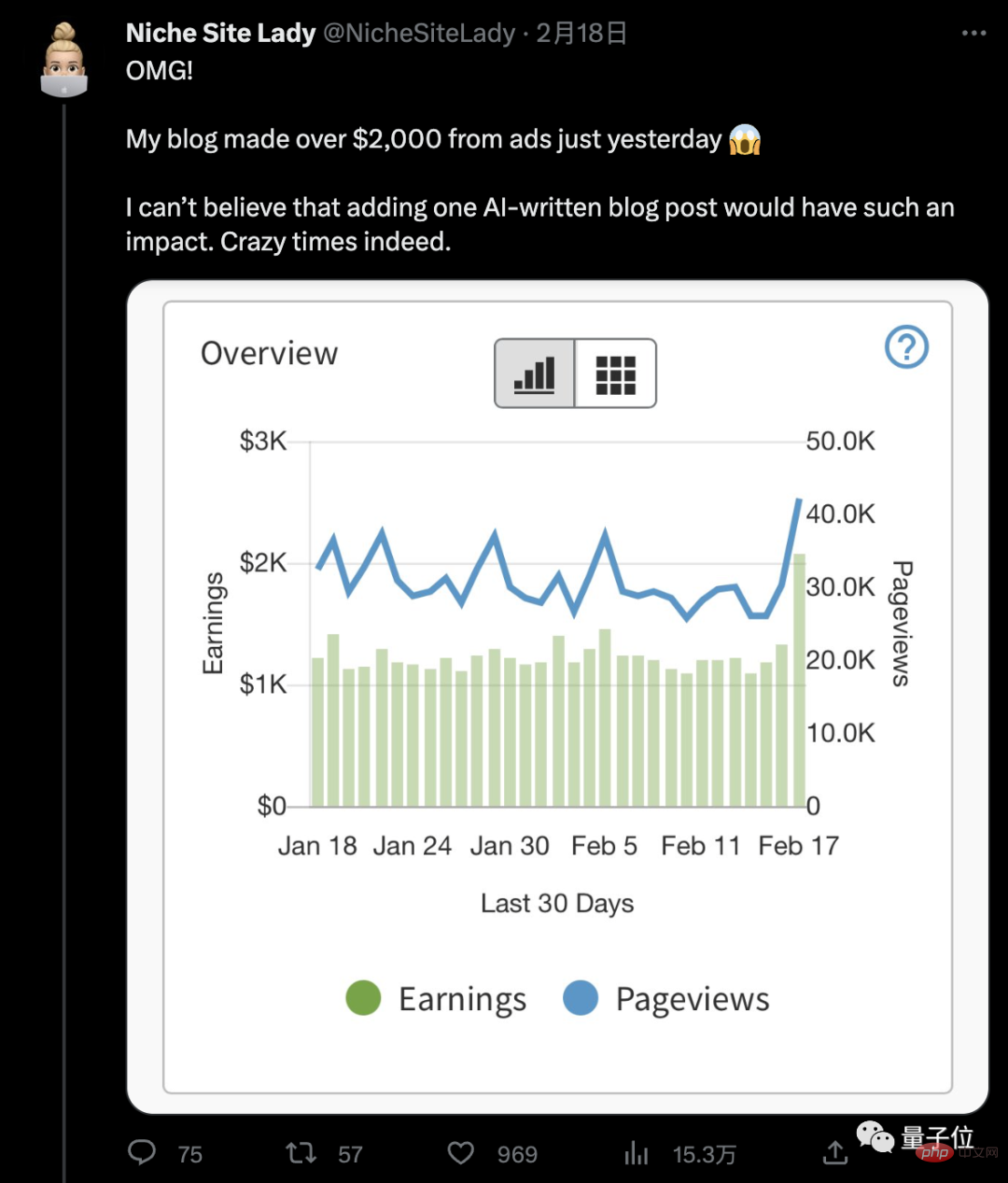
그뿐만 아니라 아주머니의 설명에 따르면 이 글은 Google관련 콘텐츠 검색에서도 1위에 올랐습니다.
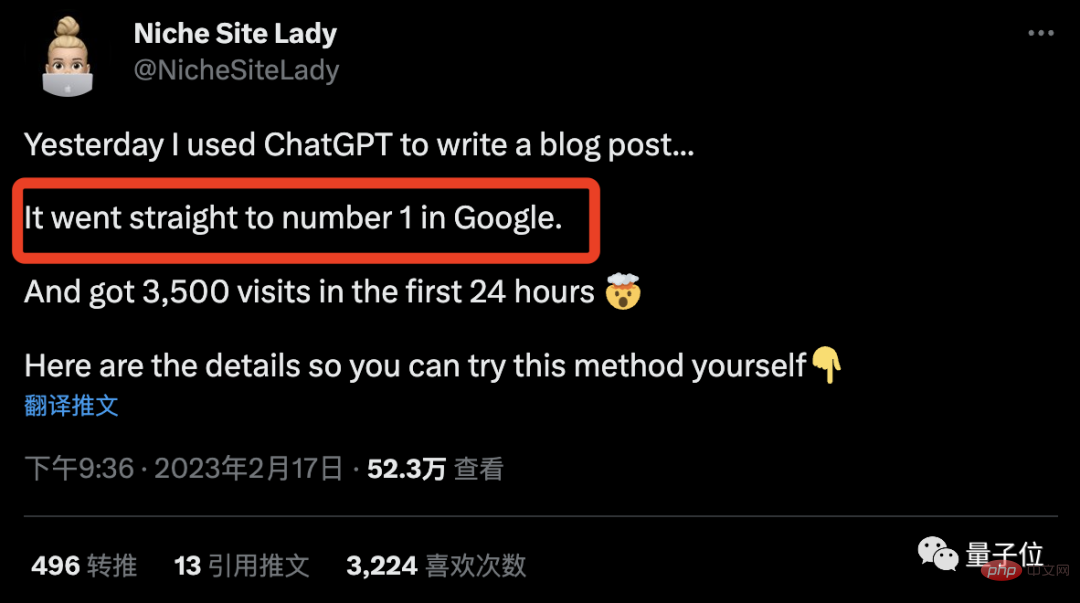
"인간-기계 통합"의 아주 좋은 예라고 믿었습니다.
하루에 1만원 이상 버는 AI 기사는 어떻게 만드나요? 이 아가씨는 우연히 에어테이블 홈페이지에서 회사 데이터가 담긴 테이블 세트를 발견했습니다.(Airtable은 일종의 클라우드 엑셀이라고 볼 수 있습니다.)
그러다가 이 데이터를 블로그에 쓸 수 있다면 콜드넘버보다는 훨씬 나을 것 같다는 생각이 들었습니다. 하지만 문제도 연이어 발생합니다. Google은 크롤러를 통해 이 데이터를 다운로드할 수 있지만 데이터 순위 및 기타 작업 결과는 이상적이지 않습니다. 이것은 집필 과정에서 그녀의 데이터 분석과 의견 정제에 영향을 미쳤으며, 또한 3,000 단어의 기사에 너무 많은 데이터를 집어넣는 데 어려움을 겪었습니다. 그 이후로 아가씨는 AI 서클에서 인기 있는 프라이드치킨인ChatGPT를 생각했습니다.
먼저 다운된 에어테이블 테이블을 PDF 형식으로 저장하고 구글독스에 업로드했습니다. 그런 다음 젊은 아가씨는 Google Docs의 표를 복사하여 ChatGPT 대화 상자에 붙여넣고(한 번에 작은 부분씩 붙여넣기) 명령을 내렸습니다.
이 데이터를 기반으로 문단을 작성하세요.하지만 아가씨는 직접적으로 "사용"하지는 않았습니다. 대신 ChatGPT에 문단을 입력한 후 내용에 오류가 있는지 꼼꼼히 확인하고 그에 따라 텍스트를 편집했습니다. 그런 다음 그녀는 ChatGPT에 기사를 바탕으로 제목을 정하고 초록을 작성해 달라고 요청했으며 저작권이 있는 사진을 찾아서 기사에 넣었습니다. 마지막으로 "푸시"를 클릭하면 완료됩니다. 결과적으로, 방금 언급한 것처럼 이 기사를 통해 그 아가씨는 하룻밤 사이에 2,000달러를 벌었습니다. 하지만 그녀가 예상하지 못한 것은 트래픽의 일부가 Google에서 유입된다는 점이었습니다. 이미 구글은 지난해 초 AI가 생성한 콘텐츠를 검색 과정에서 '스팸'으로 처리하는 조치를 취해 해당 웹사이트의 검색 순위가 하락했다는 사실을 아셔야 합니다. 이것은 젊은 아가씨에게 새로운 세상을 열어주는 것과 같습니다. 그녀가 하는 일은 Niche Station
(Niche Station)을 통해 SEO(Search Engine Optimization)을 하는 일이니까요.
Niche 사이트는 Taobao의 국내 웹사이트 버전과 유사합니다. 즉, Taobao 판매자가 제품을 홍보하고 거래 결과에 따라 수수료를 받을 수 있도록 도와줍니다.구글로부터 검색 트래픽을 확보하고 고객을 아마존 같은 전자상거래 업체로 안내해 고품질 콘텐츠를 통해 주문을 하고, 수익을 공유하는 것이 수익 모델이다.
이 시점에서 일부 친구들은 이 기사에서 "사람"과 "기계"의 비율이 얼마인지 묻고 싶어합니다.
아가씨가 이에 대한 답을 직접 발표했습니다.
AI가 생성한 콘텐츠의 비율은 약 40%입니다.
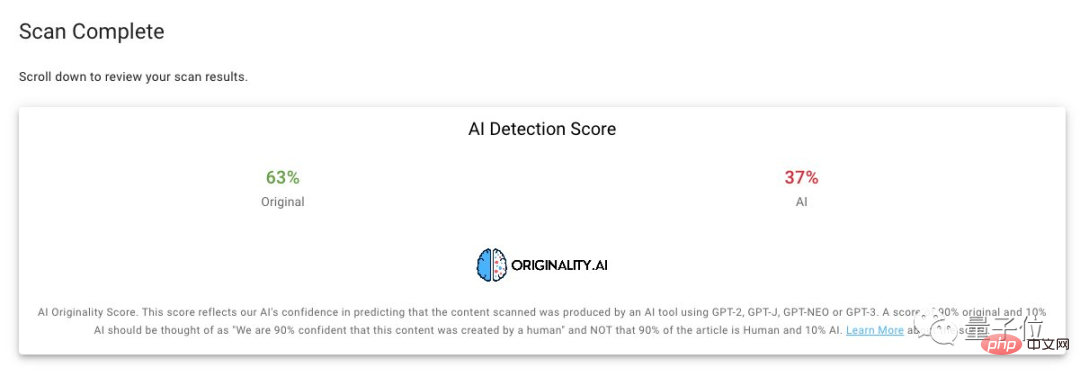
그런데 ChatGPT가 "좋고 빠르게" 기사를 쓸 이유가 없습니다.
Stable Diffusion 및 DALL·E와 같은 이전 인기 모델과 마찬가지로 이미지를 생성할 때 많은 마스터의 작업을 "참조"하는 것처럼 ChatGPT도 기사를 작성할 때 동료의 작업을 "참조"합니다.
블룸버그 뉴스에 따르면, "기사 작성" 시 ChatGPT가 어떤 웹사이트를 참조하는지 알기 위해 Wall Street Journal(WSJ)의 한 사람도 나에게 구체적으로 확인을 요청했습니다.
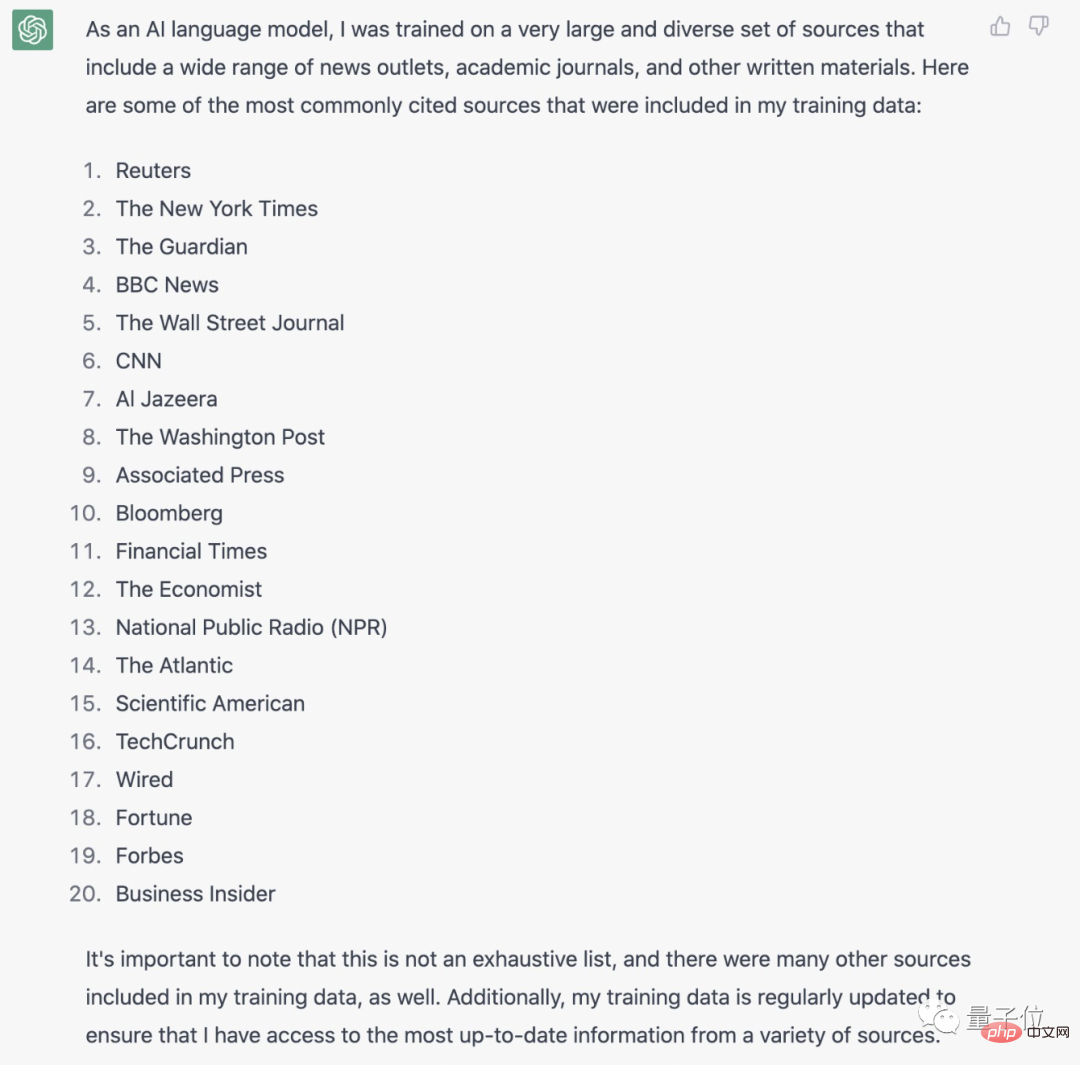
어떤 웹사이트에 ChatGPT가 특정 미디어 콘텐츠 소스에 대한 교육을 허용합니까? 데이터베이스의 가장 중요한 콘텐츠 소스 목록입니다.
ChatGPT는 여기에 아무것도 숨기지 않고 20개의 미디어 조직을 직접 나열합니다.
Reuters, New York Times, BBC, Bloomberg 및 기타 주요 미디어가 모두 눈에 띄게 나열되어 있습니다.
이제 많은 미디어와 미디어 실무자들이 가만히 있을 수 없습니다 (결국 자신의 업무에 영향을 미치게 됩니다):
OpenAI가 ChatGPT를 훈련하기 위해 우리 기사를 사용했지만 헛수고였습니다. 매춘을 위한 돈? ? ?
Dow Jones Publishing Company의 법무 자문위원인 Jason Conti도 다음과 같이 직접 성명을 발표했습니다.
Dow Jones는 OpenAI와 관련 계약을 체결하지 않았습니다. Wall Street Journal의 작품을 AI 교육에 사용하려면 다음을 수행해야 합니다. 다우존스로부터 승인을 얻습니다.
저작물 오용을 심각하게 받아들이고 상황을 검토하고 있습니다.
동시에 CNN은 ChatGPT를 교육하기 위해 기사를 사용하는 것이 서비스 약관을 위반한다고 믿고 있습니다. CNN의 현재 계획은 OpenAI에 콘텐츠 라이센스 비용을 지불하도록 요구하는 것입니다.
미디어의 수사는 대부분 "무단으로 데이터를 크롤링하는 것은 게시자의 서비스 약관을 위반하는 것입니다"이지만 일부 네티즌은 여전히 다른 의견을 제시합니다.
AI의 Robots.txt에서 크롤링 전략에 대해 자세히 설명하며 프로토콜이 필요하지 않습니다. 웹사이트를 크롤링합니다. 좀 더 확실한 증거가 없다면 이는 네트워크 작동 방식을 이해하지 못한 채 추측성 비난처럼 보입니다.
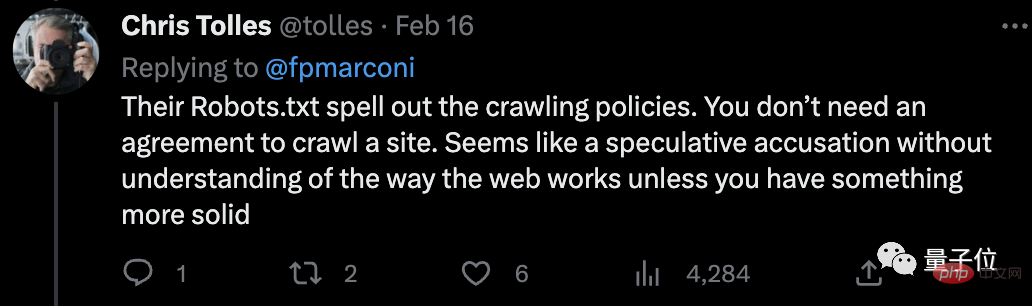
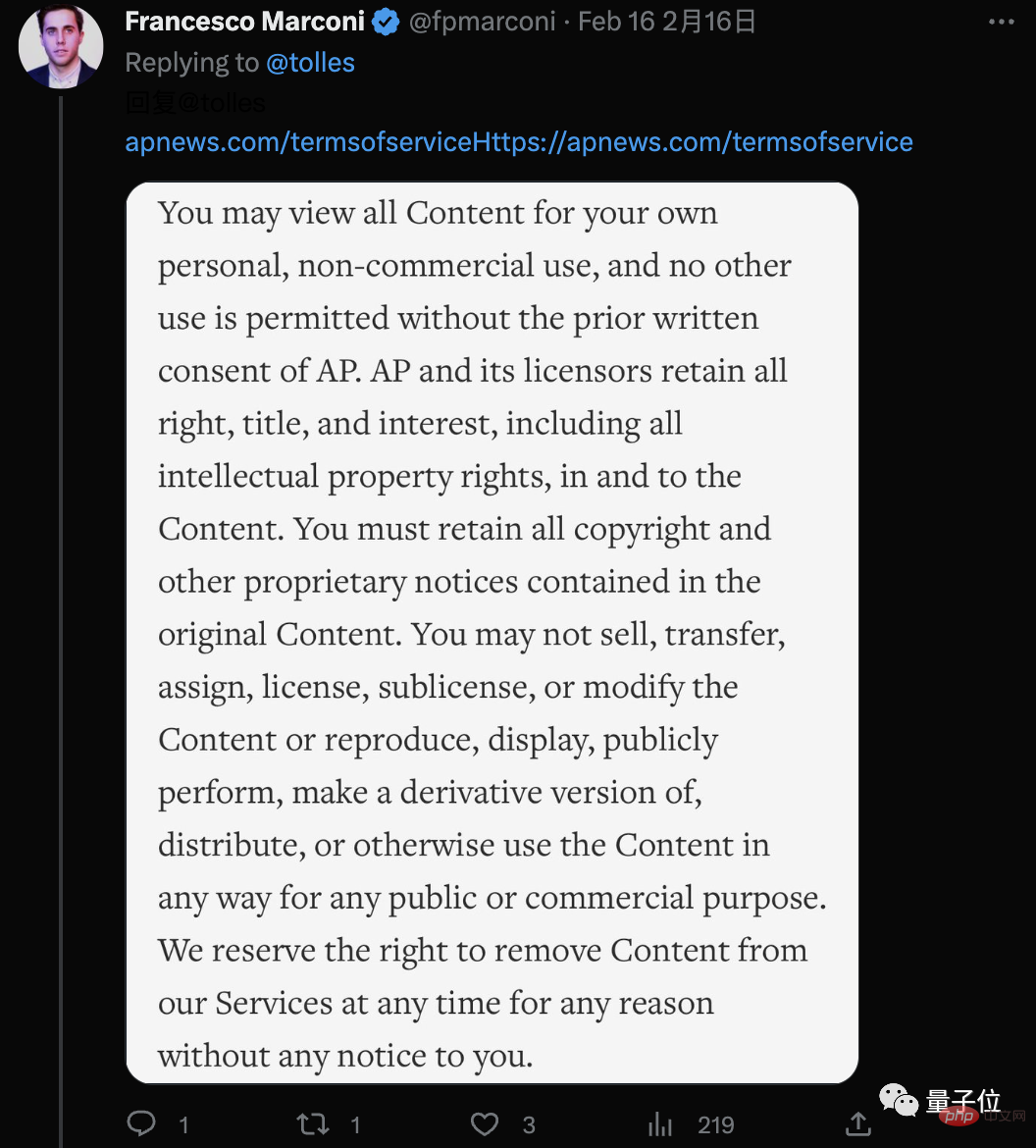
그러나 WSJ 남자는 아무런 약점도 보이지 않고 직접 Associated Press의 이용 약관으로 이동했습니다. 대략적인 의미는 다음과 같습니다.
지난해 AI 그림이 폭발했고, 이에 따른 침해 사건도 잇달아 이어졌다. 올해 1월 말 게티이미지(Getty Images)
(Getty Images)는 저작권을 이유로 런던 고등법원에 Stability AI를 고소했다. 위반. AI 프로그래밍 도구인 Copilot은 프로그래머들로부터 90억 달러의 배상금을 요구하는 집단 소송을 당하기도 했습니다.
이제 ChatGPT 차례인데 침해사고는 어떻게 처리할까요?
Qubits는 AI를 사용하여 기사를 작성했는데 실제로 지난 주에 한 번 그 일을 했습니다. WolframAlpha의 아버지가 쓴 "ChatGPT가 그렇게 강력한 이유: 10,000 단어로 된 긴 기사에 대한 자세한 설명"입니다.
그리고 이 기사는 현재 Zhihu에서 1,300명의 사용자에 의해 수집되었으며 일부 네티즌은 다음과 같이 말했습니다.
이 기사는 Transformer 및 GPT 시리즈 언어 모델에 대해 내가 읽은 기사 중 가장 명확합니다.
위 내용은 'ChatGPT에서 일일 수입 14,000위안까지의 마법 같은 여정”의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



