

JAVA의 간단한 for 루프에서 예외를 방지하는 방법은 무엇입니까?

소개
실제 비즈니스 프로젝트 개발에서는 주어진 목록에서 조건에 맞지 않는 요소를 제거하는 작업을 누구나 숙지해야겠죠?
많은 학생들이 즉시 여러 가지 구현 방법을 떠올릴 수 있지만, 당신이 생각하는 이러한 구현 방법은 인간과 동물에게 무해합니까? 겉보기에 평범해 보이는 많은 작업이 실제로는 함정이며, 많은 초보자들이 조심하지 않으면 함정에 빠질 수 있습니다.
실수로 밟은 경우:
-
코드가 실행 중일 때 직접 예외를 발생시키고 오류를 보고합니다. 이는 적어도 시간이 지나면 발견하고 해결할 수 있다는 점입니다.
코드는 오류를 보고하지 않지만 비즈니스 로직은 설명할 수 없을 정도로 나타납니다. 이상한 문제는 이런 종류가 더 비극적입니다. 왜냐하면 이 문제에 주의를 기울이지 않으면 후속 비즈니스에 숨겨진 위험이 발생할 수 있기 때문입니다. - 그렇다면 이를 달성하는 방법은 무엇인가요? 어떤 구현 방법에 문제가 있을 수 있나요? 여기서 함께 논의해 봅시다. 여기서 논의되는 것은 회향콩에 "회향"이라는 단어를 어떻게 쓰는지에 대한 문제가 아니라 쉽게 무시할 수 있는 매우 심각하고 실용적인 기술적 문제라는 점을 유의하시기 바랍니다.
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
for (UserDetail user : allUsers) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(user.getDepartment())) {
allUsers.remove(user);
}
}
// 返回剩余的用户数据
return allUsers;
}
java.util.ConcurrentModificationException: null at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909) at java.util.ArrayList$Itr.next(ArrayList.java:859) at com.veezean.demo4.UserService.filterAllDevDeptUsers(UserService.java:13) at com.veezean.demo4.Main.main(Main.java:26)
아래 첨자 루프 연산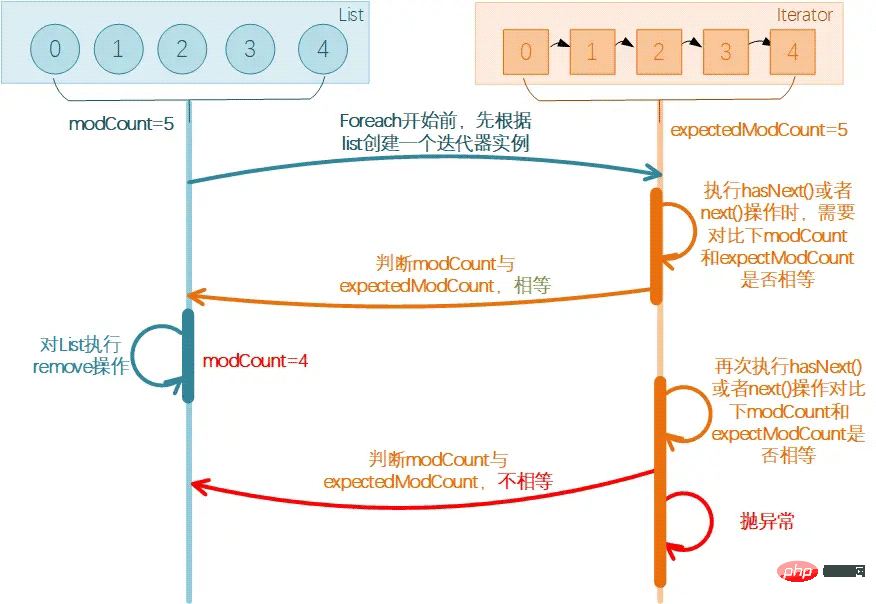
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
for (int i = 0; i < allUsers.size(); i++) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(allUsers.get(i).getDepartment())) {
allUsers.remove(i);
}
}
// 返回剩余的用户数据
return allUsers;
}로그인 후 복사
코드가 한 번에 완성되고, 실행하고 처리된 출력을 확인하세요:public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
for (int i = 0; i < allUsers.size(); i++) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(allUsers.get(i).getDepartment())) {
allUsers.remove(i);
}
}
// 返回剩余的用户数据
return allUsers;
}{id=2, name='lee思', Department='dev'}
{id =3, name ='王五', Department='product'}{id=4, name='Tiezhu', Department='pm'}기타..? 정말 괜찮은 걸까요? 우리의 코드 로직은 "dev".equals(department)인지 판단하는 것인데, 출력 결과에는 왜 아직도 제거해야 할 Department=dev 같은 데이터가 있나요? 실제 비즈니스 프로젝트라면 개발 단계에서 오류가 보고되지 않고, 결과가 꼼꼼히 검증되지 않은 후 생산 라인으로 흘러가게 된다면 비정상적인 비즈니스 로직이 발생할 수 있습니다. 이 현상이 나타나는 구체적인 이유를 살펴보겠습니다. 원인 분석: 우리는 실제로 목록의 요소와 첨자 사이에 강력한 바인딩 관계가 없다는 것을 알고 있습니다. 이는 단지 목록의 요소가 변경된 후 해당 첨자의 대응 관계일 뿐입니다. 각 요소는 아래와 같이 아래 첨자가 변경될 수 있습니다.
물론, 오류도 보고되지 않고 결과도 출력됩니다. , 완벽해요~
그런 다음 목록에서 요소를 삭제한 후 목록에서 삭제된 요소 뒤에 있는 모든 요소의 아래 첨자는 앞으로 이동하지만 for의 포인터 i 루프는 항상 거꾸로 누적됩니다. 예, 다음 루프를 처리할 때 일부 요소가 누락되어 처리되지 않을 수 있습니다. 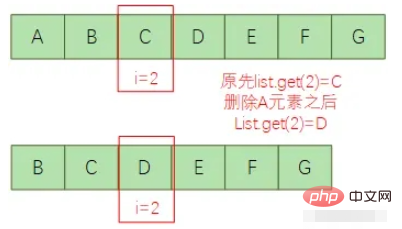
여기서 위 코드가 실행 후 누락되는 이유를 알 수 있습니다~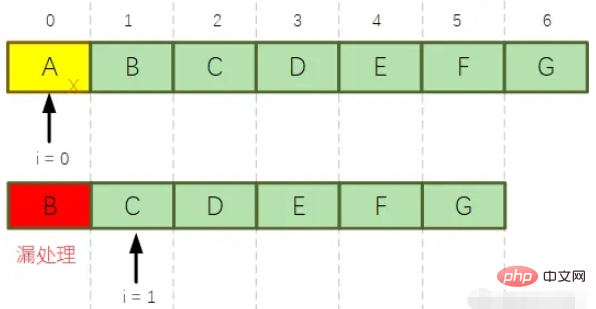
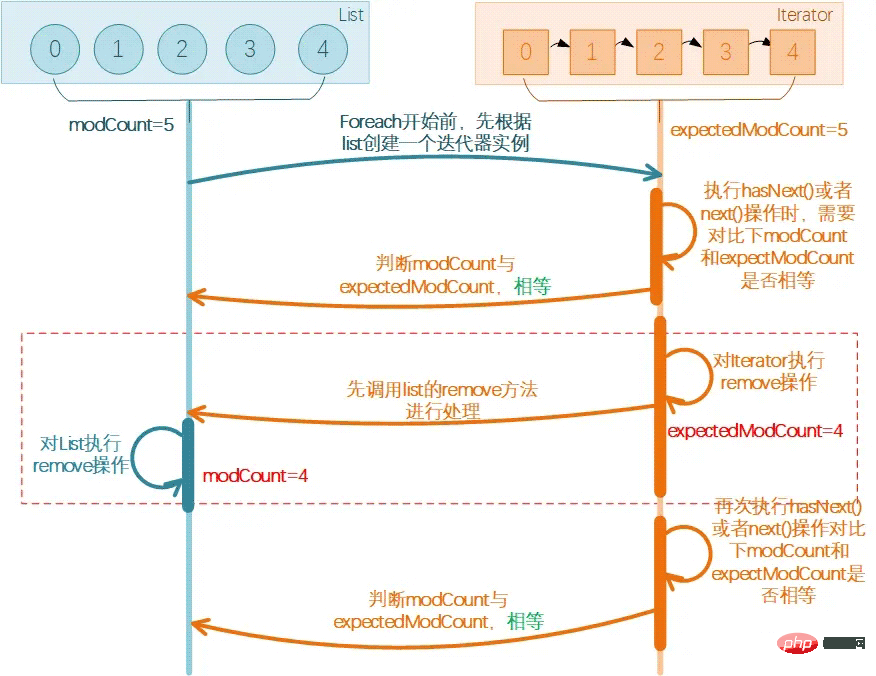
위의 2가지 함정을 확인했습니다. 수술 후 올바르고 적절한 수술방법은 무엇인가요? Iterator 메서드어? 좋아요? foreach 메서드도 반복자를 사용한다고 방금 말하지 않았는데 실제로는 트랩 작업인가요? 여기서 반복자 패턴이 올바른 방식이라고 말하는 이유는 무엇입니까?
虽然都是基于迭代器,但是使用逻辑是不一样的,看下代码:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
Iterator<UserDetail> iterator = allUsers.iterator();
while (iterator.hasNext()) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(iterator.next().getDepartment())) {
// 这是重点,此处操作的是Iterator,而不是list
iterator.remove();
}
}
// 返回剩余的用户数据
return allUsers;
}执行结果:
{id=3, name='王五', department='product'}
{id=4, name='铁柱', department='pm'}
这次竟然直接执行成功了,且结果也是正确的。为啥呢?
在前面foreach方式的时候,我们提过之所以会报错的原因,是由于直接修改了原始list数据而没有同步让Iterator感知到,所以导致Iterator操作前校验失败抛异常了。
而此处的写法中,直接调用迭代器中的remove()方法,此操作会在调用集合的remove(),add()方法后,将expectedModCount重新赋值为modCount,所以在迭代器中增加、删除元素是可以正常运行的。,所以这样就不会出问题啦。
Lambda表达式
言简意赅,直接上代码:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
allUsers.removeIf(user -> "dev".equals(user.getDepartment()));
return allUsers;
}Stream流操作
作为JAVA8开始加入的Stream,使得这种场景实现起来更加的优雅与易懂:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
return allUsers.stream()
.filter(user -> !"dev".equals(user.getDepartment()))
.collect(Collectors.toList());
}中间对象辅助方式
既然前面说了不能直接循环的时候执行移除操作,那就先搞个list对象将需要移除的元素暂存起来,最后一起剔除就行啦 ~
嗯,虽然有点挫,但是不得不承认,实际情况中,很多人都在用这个方法 —— 说的就是你,你是不是也曾这么写过?
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
List<UserDetail> needRemoveUsers = new ArrayList<>();
for (UserDetail user : allUsers) {
if ("dev".equals(user.getDepartment())) {
needRemoveUsers.add(user);
}
}
allUsers.removeAll(needRemoveUsers);
return allUsers;
}或者:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
List<UserDetail> resultUsers = new ArrayList<>();
for (UserDetail user : allUsers) {
if (!"dev".equals(user.getDepartment())) {
resultUsers.add(user);
}
}
return resultUsers;
}위 내용은 JAVA의 간단한 for 루프에서 예외를 방지하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7350
7350
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호 안내 여기에서는 일부 코드와 함께 Java의 Armstrong 번호에 대한 소개를 논의합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
