

sql中 in , not in , exists , not exists效率分析_MySQL

in和exists执行时,in是先执行子查询中的查询,然后再执行主查询。而exists查询它是先执行主查询,即外层表的查询,然后再执行子查询。
exists 和 in 在执行时效率单从执行时间来说差不多,exists要稍微优于in。在使用时一般应该是用exists而不用in
如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in,反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。IN时不对NULL进行处理。
not exists 和 not in 比较时,not exists 的效率比较高。
为了说明测试结果,我把emp1表中的数据到了315392条。emp2中删除只有2条件数据。测试的依据是执行的时间来说明的。
emp1中的数据记录情况。
SQL> select count(*) from emp1;
COUNT(*)
----------
315392
emp2中的数据记录情况:
SQL> select count(*) from emp2;
COUNT(*)
----------
2
1、 执行exists查询,要求在emp1中查询出所有存在于emp2的数据总数
SQL> select count(*) from emp1 where exists ( select null from emp2 where emp1.ename = emp2.ename);
COUNT(*)
----------
45056
执行次数十次,最大的一次为0.125S
2、 使用not exists查询出所在不在emp2中的数据总数
SQL> select count(*) from emp1 where not exists ( select null from emp2 where emp1.ename = emp2.ename);
COUNT(*)
----------
270336
执行次数十次,最大的一次为0.141S
3、执行in 查询,要求在emp1中查询出所有存在于emp2的数据总数
SQL> select count(*) from emp1 where ename in ( select ename from emp2);
COUNT(*)
----------
45056
执行十次,最大的一次为0.141S
4、使用not in查询出所在不在emp2中的数据总数
SQL> select count(*) from emp1 where ename not in ( select ename from emp2 );
COUNT(*)
----------
270336
执行十次,最长一次为0.328S
5、使用in查询,调用外层与子查询的位置,要求查询出存在于emp2中,且存在于emp1中的数据记录数
SQL> select count(*) from emp2 where ename in (select ename from emp1 );
COUNT(*)
----------
2
执行次数十次,最长的一次为0.047S
6、使用exists查询,调用外层与子查询的位置,要求查询出存在于emp2中,且存在于emp1中的数据记录数
SQL> select count(*) from emp2 where ename in (select ename from emp1 );
COUNT(*)
----------
2
执行次数十次,最长的一次为0.047S
综上所述:在使用in 和 exists时,个人觉得,效率差不多。而在not in 和 not exists比较时,not exists的效率要比not in的效率要高。
当使用in时,子查询where条件不受外层的影响,自动优化会转成exist语句,它的效率和exist一样。(没有验证)
如select * from t1 where f1 in (select f1 from t2 where t2.fx='x') 这时,认为in 和 exists效率一样。
IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7691
7691
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 Windows 11에서 앱이나 프로세스에 대해 생산성 모드를 켜거나 끄는 방법
Apr 14, 2023 pm 09:46 PM
Windows 11에서 앱이나 프로세스에 대해 생산성 모드를 켜거나 끄는 방법
Apr 14, 2023 pm 09:46 PM
Windows 11 22H2의 새로운 작업 관리자는 고급 사용자에게 도움이 됩니다. 이제 실행 중인 프로세스, 작업, 서비스 및 하드웨어 구성 요소를 감시할 수 있는 추가 데이터를 통해 더 나은 UI 환경을 제공합니다. 새로운 작업 관리자를 사용해 왔다면 새로운 생산성 모드를 발견했을 것입니다. 그것은 무엇입니까? Windows 11 시스템의 성능을 향상시키는 데 도움이 됩니까? 알아 보자! Windows 11의 생산성 모드란 무엇입니까? 생산성 모드는 작업 관리자의 작업 중 하나입니다.
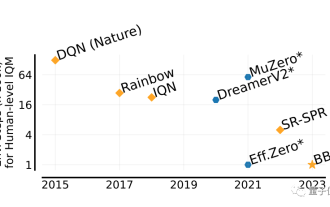 2시간이면 인간을 능가할 수 있다! DeepMind의 최신 AI는 26개의 Atari 게임을 빠르게 실행합니다.
Jul 03, 2023 pm 08:57 PM
2시간이면 인간을 능가할 수 있다! DeepMind의 최신 AI는 26개의 Atari 게임을 빠르게 실행합니다.
Jul 03, 2023 pm 08:57 PM
DeepMind의 AI 에이전트가 다시 작동합니다! 주목하세요, BBF라는 이 남자는 단 2시간 만에 26개의 Atari 게임을 마스터했습니다. 그의 효율성은 그의 전임자들을 모두 능가하는 인간의 효율성과 동일합니다. 아시다시피 AI 에이전트는 항상 강화학습을 통해 문제를 해결하는 데 효과적이었지만, 가장 큰 문제는 이 방법이 매우 비효율적이고 탐색하는 데 오랜 시간이 걸린다는 것입니다. Picture BBF가 가져온 혁신은 효율성 측면에서 이루어졌습니다. 전체 이름이 Bigger, Better 또는 Faster로 불릴 수 있다는 것은 놀라운 일이 아닙니다. 더욱이, 단 하나의 카드로 훈련을 완료할 수 있으며 컴퓨팅 성능 요구 사항도 훨씬 줄어듭니다. BBF는 Google DeepMind와 몬트리올 대학이 공동으로 제안했으며, 데이터와 코드는 현재 오픈 소스입니다. 도달할 수 있는 가장 높은 인간
 PyCharm 원격 개발 실용 가이드: 개발 효율성 향상
Feb 23, 2024 pm 01:30 PM
PyCharm 원격 개발 실용 가이드: 개발 효율성 향상
Feb 23, 2024 pm 01:30 PM
PyCharm은 Python 개발자가 코드 작성, 디버깅 및 프로젝트 관리를 위해 널리 사용하는 강력한 Python 통합 개발 환경(IDE)입니다. 실제 개발 과정에서 대부분의 개발자는 개발 효율성을 높이는 방법, 개발 시 팀 구성원과 협력하는 방법 등과 같은 다양한 문제에 직면하게 됩니다. 이 기사에서는 개발자가 원격 개발에 PyCharm을 더 잘 활용하고 작업 효율성을 향상할 수 있도록 PyCharm 원격 개발에 대한 실용적인 가이드를 소개합니다. 1. PyCh에서의 준비 작업
 AI 그림을 가지고 놀 수 있는 Stable Diffusion의 비공개 배포
Mar 12, 2024 pm 05:49 PM
AI 그림을 가지고 놀 수 있는 Stable Diffusion의 비공개 배포
Mar 12, 2024 pm 05:49 PM
StableDiffusion은 오픈소스 딥러닝 모델로, 텍스트 설명을 통해 고품질 이미지를 생성하는 것이 주요 기능이며, 그래프 생성, 모델 병합, 모델 훈련 등의 기능을 지원합니다. 모델의 작동 인터페이스는 아래 그림에서 볼 수 있습니다. 그림 생성 방법 다음은 사슴이 물을 마시는 그림을 만드는 과정을 소개합니다. 그림을 생성할 때 프롬프트 단어와 부정적인 프롬프트 단어로 나누어서 입력해야 합니다. 원하는 장면, 대상, 스타일, 색상을 자세히 설명해보세요. 예를 들어, 단순히 "사슴이 물을 마신다"라고 말하는 대신 "개울, 울창한 나무 옆, 그리고 개울 옆에 사슴이 물을 마시고 있다"라고 말합니다. 예를 들어, 부정 프롬프트 단어는 반대 방향입니다. 건물도 없고, 사람도 없고, 다리도 없고, 울타리도 없고, 너무 모호한 설명은 부정확한 결과를 초래할 수 있습니다.
 공개된 Java 개발 기술: 데이터베이스 트랜잭션 처리 효율성 최적화
Nov 20, 2023 pm 03:13 PM
공개된 Java 개발 기술: 데이터베이스 트랜잭션 처리 효율성 최적화
Nov 20, 2023 pm 03:13 PM
인터넷의 급속한 발전과 함께 데이터베이스의 중요성은 더욱 부각되고 있습니다. Java 개발자로서 우리는 데이터베이스 작업을 수행하는 경우가 많습니다. 데이터베이스 트랜잭션 처리의 효율성은 전체 시스템의 성능 및 안정성과 직접적인 관련이 있습니다. 이 기사에서는 개발자가 시스템 성능과 응답 속도를 향상시키는 데 도움이 되도록 데이터베이스 트랜잭션 처리 효율성을 최적화하기 위해 Java 개발에서 일반적으로 사용되는 몇 가지 기술을 소개합니다. 일괄 삽입/업데이트 작업 일반적으로 단일 레코드를 한 번에 데이터베이스에 삽입하거나 업데이트하는 효율성은 일괄 작업보다 훨씬 낮습니다. 따라서 일괄 삽입/업데이트를 수행할 때
 Microsoft Edge에서 절전 모드를 켜는 방법은 무엇입니까?
Apr 20, 2023 pm 08:22 PM
Microsoft Edge에서 절전 모드를 켜는 방법은 무엇입니까?
Apr 20, 2023 pm 08:22 PM
Edge와 같은 Chromium 기반 브라우저는 많은 리소스를 사용하지만 Microsoft Edge에서 효율성 모드를 활성화하여 성능을 향상시킬 수 있습니다. Microsoft Edge 웹 브라우저는 처음부터 많은 발전을 이루었습니다. 최근 Microsoft는 PC에서 브라우저의 전반적인 성능을 향상시키기 위해 브라우저에 새로운 효율성 모드를 추가했습니다. 효율성 모드는 배터리 수명을 연장하고 시스템 리소스 사용량을 줄이는 데 도움이 됩니다. 예를 들어, Google Chrome 및 Microsoft Edge와 같이 Chromium으로 구축된 브라우저는 RAM 및 CPU 주기를 많이 잡아먹는 것으로 악명이 높습니다. 그러므로 순서대로
 업무 효율성과 삶의 질을 향상시키는 Python 마스터하기
Feb 18, 2024 pm 05:57 PM
업무 효율성과 삶의 질을 향상시키는 Python 마스터하기
Feb 18, 2024 pm 05:57 PM
제목: 삶을 더욱 편리하게 만드는 Python: 업무 효율성과 삶의 질을 향상하려면 이 언어를 마스터하세요. 강력하고 배우기 쉬운 프로그래밍 언어인 Python은 오늘날 디지털 시대에 점점 더 인기를 끌고 있습니다. 프로그램을 작성하고 데이터 분석을 수행하는 것뿐만 아니라 Python은 일상 생활에서도 큰 역할을 할 수 있습니다. 이 언어를 익히면 업무 효율성이 향상될 뿐만 아니라 삶의 질도 향상됩니다. 이 기사에서는 특정 코드 예제를 사용하여 생활에서 Python을 광범위하게 적용하는 방법을 보여주고 독자에게 도움을 줄 것입니다.
 서브넷 마스크: 네트워크 통신 효율성에 대한 역할 및 영향
Dec 26, 2023 pm 04:28 PM
서브넷 마스크: 네트워크 통신 효율성에 대한 역할 및 영향
Dec 26, 2023 pm 04:28 PM
서브넷 마스크의 역할과 이것이 네트워크 통신 효율성에 미치는 영향 서론: 인터넷의 대중화와 함께 네트워크 통신은 현대 사회에서 없어서는 안 될 부분이 되었습니다. 동시에 네트워크 통신의 효율성도 사람들의 관심의 초점 중 하나가 되었습니다. 네트워크를 구축하고 관리하는 과정에서 서브넷 마스크는 네트워크 통신에 있어서 핵심적인 역할을 하는 중요하고 기본적인 구성 옵션입니다. 이 기사에서는 서브넷 마스크의 역할과 이것이 네트워크 통신 효율성에 미치는 영향을 소개합니다. 1. 서브넷 마스크의 정의 및 기능 서브넷 마스크(subnetmask)
