
일반적인 동기화 방법의 경우 잠금은 현재 인스턴스 개체입니다.
정적 동기화 방법의 경우 잠금은 현재 클래스 개체입니다.
메서드 코드 블록을 수정하세요. 동기화된 메서드 블록의 경우 잠금은 동기화된 괄호 안에 구성된 개체입니다!
스레드가 동기화된 코드 블록에 액세스하려고 하면 완료 후(또는 예외 발생) 잠금을 해제해야 합니다. 그렇다면 자물쇠는 정확히 어디에 존재하는 걸까요? 함께 탐험해 보세요!
하지만 이 글을 찾아보시면 이미 그 사용법에 익숙하시리라 믿습니다. 멀티스레딩에서 데이터가 혼동되는 이유와 사용법에 대해서는 자세히 설명하지 않겠습니다! 참고용으로 몇 가지 사용 방법만 나열되어 있습니다!
인스턴스 방식 수정 일반 동기화 방식의 경우 잠금은 현재 인스턴스 객체입니다
동일 인스턴스 사용 후 동기화 추가 후 스레드가 대기열에 추가되어야 하는 것은 당연합니다. Atom 작업을 완료하려면 동일한 인스턴스를 사용하는 경우에만 적용됩니다! 使用的同一个实例,他才会生效!
正例:
<code>/**<br> * @author huangfu<br> */<br>public class ExploringSynchronized implements Runnable {<br> /**<br> * 共享资源(临界资源)<br> */<br> static int i=0;<br> public synchronized void add(){<br> i++;<br> }<br><br> @Override<br> public void run() {<br> for (int j = 0; j add();<br> }<br> }<br><br> public static void main(String[] args) throws InterruptedException {<br> ExploringSynchronized exploringSynchronized = new ExploringSynchronized();<br> Thread t1 = new Thread(exploringSynchronized);<br> Thread t2 = new Thread(exploringSynchronized);<br> t1.start();<br> t2.start();<br> //join 主线程需要等待子线程完成后在结束<br> t1.join();<br> t2.join();<br> System.out.println(i);<br><br> }<br>}</code>反例:
<code>/**<br> * @author huangfu<br> */<br>public class ExploringSynchronized implements Runnable {<br> /**<br> * 共享资源(临界资源)<br> */<br> static int i=0;<br> public synchronized void add(){<br> i++;<br> }<br><br> @Override<br> public void run() {<br> for (int j = 0; j add();<br> }<br> }<br><br> public static void main(String[] args) throws InterruptedException {<br> Thread t1 = new Thread(new ExploringSynchronized());<br> Thread t2 = new Thread(new ExploringSynchronized());<br> t1.start();<br> t2.start();<br> //join 主线程需要等待子线程完成后在结束<br> t1.join();<br> t2.join();<br> System.out.println(i);<br><br> }<br>}</code>这种,即使你在方法上加上了synchronized也无济于事,因为,对于普通同步方法,锁是当前的实例对象!实例对象都不一样了,那么他们之间的锁自然也就不是同一个!
修饰静态方法,对于静态同步方法,锁是当前的Class对象
从定义上可以看出来,他的锁是类对象,那么也就是说,以上面那个类为例:普通方法的锁对象是 new ExploringSynchronized()而静态方法对应的锁对象是ExploringSynchronized.class所以对于静态方法添加同步锁,即使你重新创建一个实例,它拿到的锁还是同一个!
<code>package com.byit.test;<br><br>/**<br> * @author huangfu<br> */<br>public class ExploringSynchronized implements Runnable {<br> /**<br> * 共享资源(临界资源)<br> */<br> static int i=0;<br> public synchronized static void add(){<br> i++;<br> }<br><br> @Override<br> public void run() {<br> for (int j = 0; j add();<br> }<br> }<br><br> public static void main(String[] args) throws InterruptedException {<br> Thread t1 = new Thread(new ExploringSynchronized());<br> Thread t2 = new Thread(new ExploringSynchronized());<br> t1.start();<br> t2.start();<br> //join 主线程需要等待子线程完成后在结束<br> t1.join();<br> t2.join();<br> System.out.println(i);<br><br> }<br>}</code>当然,结果是我们期待的 200000
修饰方法代码块,对于同步方法块,锁是synchronized括号里面配置的对象!
<code>package com.byit.test;<br><br>/**<br> * @author huangfu<br> */<br>public class ExploringSynchronized implements Runnable {<br> /**<br> * 锁标记<br> */<br> private static final String LOCK_MARK = "LOCK_MARK";<br> /**<br> * 共享资源(临界资源)<br> */<br> static int i=0;<br> public void add(){<br> synchronized (LOCK_MARK){<br> i++;<br> }<br> }<br><br> @Override<br> public void run() {<br> for (int j = 0; j add();<br> }<br> }<br><br> public static void main(String[] args) throws InterruptedException {<br> Thread t1 = new Thread(new ExploringSynchronized());<br> Thread t2 = new Thread(new ExploringSynchronized());<br> t1.start();<br> t2.start();<br> //join 主线程需要等待子线程完成后在结束<br> t1.join();<br> t2.join();<br> System.out.println(i);<br><br> }<br>}</code>对于同步代码块,括号里面是什么,锁对象就是什么,里面可以使用this 字符串 对象等等!
java中synchronized的实现是基于进入和退出的 Monitor对象实现的,无论是显式同步(修饰代码块,有明确的monitorenter和 monitorexit指令)还是隐式同步(修饰方法体)!
需要注意的是,只有修饰代码块的时候,才是基于monitorenter和 monitorexit指令来实现的;修饰方法的时候,是通过另一种方式实现的!我会放到后面去说!
在了解整个实现底层之前,我还是希望你能够大致了解一下对象在内存中的结构详情!
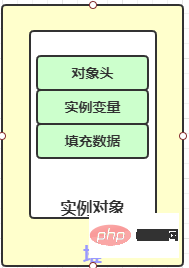
实例变量:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按4字节对齐。
填充数据:由于虚拟机要求对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐,这点了解即可。
这两个概念,我们简单理解就好!我们今天并不去探究对象的构成原理!我们着重探究一下对象头,他对我们理解锁尤为重要!
一般而言,synchronized使用的锁存在于对象头里面!如果是数组对象,则虚拟机使用3个字宽存储对象,如果是非数组对象,则使用两个字宽存储对象头!字虚拟机里面1字宽等于4字节!主要结构是 Mark Word 和 Class Metadata Address
<code>package com.byit.test;<br><br>/**<br> * @author Administrator<br> */<br>public class SynText {<br> private static String A = "a";<br> public int i ;<br><br> public void add(){<br> synchronized (A){<br> i++;<br> }<br><br> }<br>}</code>| ②정적 메소드 수정 | 정적 동기화 메소드의 경우 잠금은 현재 클래스 객체입니다 | |
|---|---|---|
| ③Modify method code block | Modify method code block의 경우 동기화된 메서드에 잠금이 구성됩니다. 괄호 개체! | javap -verbose -p SynText > 3.txt 로그인 후 복사 로그인 후 복사 | 동기화된 코드 블록의 경우 괄호 안에 무엇이 있는지, 잠금 객체는 무엇인지, 이 문자열 객체 등을 사용할 수 있습니다!
| Java의 | 코드 블록 수정 시에만 | 전체 구현의 최하위 계층을 이해하기 전에, 메모리에 있는 객체의 구조 세부 사항에 대한 일반적인 이해를 가질 수 있기를 바랍니다! |
| 인스턴스 변수: 상위 클래스의 속성 정보를 포함한 클래스의 속성 데이터 정보를 저장합니다. 배열의 인스턴스 부분에는 배열의 길이도 포함되며, 메모리의 이 부분은 4바이트로 정렬됩니다. |
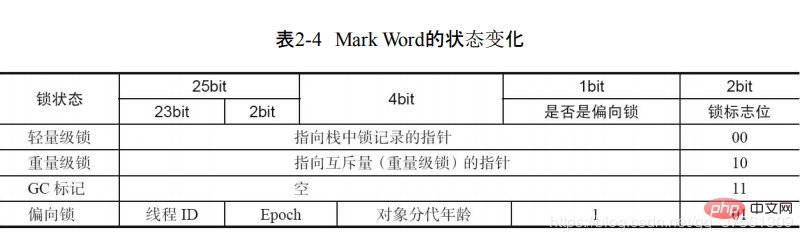
synchronized에서 사용하는 잠금은 개체 헤더에 존재합니다! 배열 개체인 경우 가상 머신은 3워드 너비를 사용하여 개체를 저장하고, 배열이 아닌 개체인 경우 2워드 너비를 사용하여 개체 헤더를 저장합니다. 가상 머신이라는 단어에서 1워드 너비는 4바이트와 같습니다! 주요 구조는 Mark Word와 Class Metadata Address로 구성됩니다. 구조는 다음과 같습니다. 🎜🎜🎜🎜🎜🎜가상 머신 비트🎜🎜헤더 개체 구조🎜🎜설명 🎜🎜🎜🎜 🎜🎜32/64bit🎜🎜Mark Word🎜🎜저장소 객체의 해시코드, 잠금 정보 또는 세대 연령 또는 GC 플래그 및 기타 정보🎜🎜🎜🎜32/64bit🎜🎜클래스 메타데이터 주소🎜🎜형식 데이터에 저장된 포인터 🎜 🎜🎜🎜32/64bit (어레이)🎜🎜어레이 길이🎜🎜어레이의 길이🎜🎜🎜🎜위 표를 보면 锁信息 存在于 Mark Word가 내부에 있음을 알 수 있는데, 마크워드 내부는 어떻게 구성되어 있나요?
| 잠금 상태 | 25bit | 4bit | 1bit는 편향된 잠금 | 2bit 잠금 플래그 |
|---|---|---|---|---|
| 잠금 해제 상태 | 객체의 해시 코드 | 물체의 세대연령 | 0 | 01 |
在运行起见,mark Word 里存储的数据会随着锁的标志位的变化而变化。mark Word可能变化为存储一下四种数据
Java SE 1.6为了减少获得锁和释放锁带来的消耗,引入了偏向锁和轻量级锁,从之前上来就是重量级锁到1.6之后,锁膨胀升级的优化,极大地提高了synchronized的效率;
锁一共有4中状态,级别从低到高:
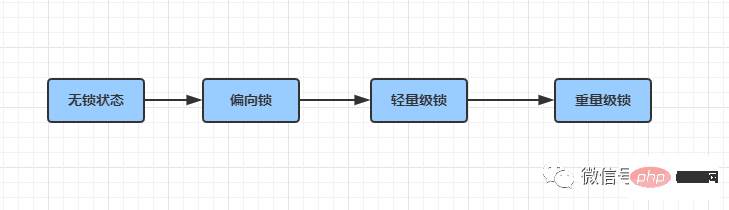
这几个状态会随着锁的竞争,逐渐升级。锁可以升级,但是不能降级,其根本的原因就是为了提高获取锁和释放锁的效率!
那么,synchronized是又如何保证的线程安全的呢?或许我们需要从字节码寻找答案!
<code>package com.byit.test;<br><br>/**<br> * @author Administrator<br> */<br>public class SynText {<br> private static String A = "a";<br> public int i ;<br><br> public void add(){<br> synchronized (A){<br> i++;<br> }<br><br> }<br>}</code>反编译的字节码
<code>Compiled from "SynText.java"<br>public class com.byit.test.SynText {<br> public int i;<br><br> public com.byit.test.SynText();<br> Code:<br> 0: aload_0<br> 1: invokespecial #1 // Method java/lang/Object."<init>":()V<br> 4: return<br><br> public void add();<br> Code:<br> 0: getstatic #2 // Field A:Ljava/lang/String;<br> 3: dup<br> 4: astore_1<br> 5: monitorenter<br> 6: aload_0<br> 7: dup<br> 8: getfield #3 // Field i:I<br> 11: iconst_1<br> 12: iadd<br> 13: putfield #3 // Field i:I<br> 16: aload_1<br> 17: monitorexit<br> 18: goto 26<br> 21: astore_2<br> 22: aload_1<br> 23: monitorexit<br> 24: aload_2<br> 25: athrow<br> 26: return<br> Exception table:<br> from to target type<br> 6 18 21 any<br> 21 24 21 any<br><br> static {};<br> Code:<br> 0: ldc #4 // String a<br> 2: putstatic #2 // Field A:Ljava/lang/String;<br> 5: return<br>}<br></init></code>省去不必要的,简化在简化
<code> 5: monitorenter<br> ...<br> 17: monitorexit<br> ...<br> 23: monitorexit</code>
从字节码中可知同步语句块的实现使用的是monitorenter和 monitorexit指令,其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置,当执行monitorenter指令的时候,线程将试图获取对象所所对应的monitor特权,当monitor的的计数器为0的时候,线程就可以获取monitor,并将计数器设置为1.去锁成功!如果当前线程已经拥有monitor特权,则可以直接进入方法(可重入锁),计数器+1;如果其他线程已经拥有了monitor特权,那么本县城将会阻塞!
拥有monitor特权的线程执行完成后释放monitor,并将计数器设置为0;同时执行monitorexit指令;不要担心出现异常无法执行monitorexit指令;为了保证在方法异常完成时 monitorenter 和 monitorexit 指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令。从字节码中也可以看出多了一个monitorexit指令,它就是异常结束时被执行的释放monitor 的指令。
同步代码块的原理了解了,那么同步方法如何解释?不急,我们不妨来反编译一下同步方法的状态!
javap -verbose -p SynText > 3.txt
代码
<code>package com.byit.test;<br><br>/**<br> * @author huangfu<br> */<br>public class SynText {<br> public int i ;<br><br> public synchronized void add(){<br> i++;<br><br> }<br>}</code>字节码
<code>Classfile /D:/2020project/byit-myth-job/demo-client/byit-demo-client/target/classes/com/byit/test/SynText.class<br> Last modified 2020-1-6; size 382 bytes<br> MD5 checksum e06926a20f28772b8377a940b0a4984f<br> Compiled from "SynText.java"<br>public class com.byit.test.SynText<br> minor version: 0<br> major version: 52<br> flags: ACC_PUBLIC, ACC_SUPER<br>Constant pool:<br> #1 = Methodref #4.#17 // java/lang/Object."<init>":()V<br> #2 = Fieldref #3.#18 // com/byit/test/SynText.i:I<br> #3 = Class #19 // com/byit/test/SynText<br> #4 = Class #20 // java/lang/Object<br> #5 = Utf8 i<br> #6 = Utf8 I<br> #7 = Utf8 <init><br> #8 = Utf8 ()V<br> #9 = Utf8 Code<br> #10 = Utf8 LineNumberTable<br> #11 = Utf8 LocalVariableTable<br> #12 = Utf8 this<br> #13 = Utf8 Lcom/byit/test/SynText;<br> #14 = Utf8 syncTask<br> #15 = Utf8 SourceFile<br> #16 = Utf8 SynText.java<br> #17 = NameAndType #7:#8 // "<init>":()V<br> #18 = NameAndType #5:#6 // i:I<br> #19 = Utf8 com/byit/test/SynText<br> #20 = Utf8 java/lang/Object<br>{<br> public int i;<br> descriptor: I<br> flags: ACC_PUBLIC<br><br> public com.byit.test.SynText();<br> descriptor: ()V<br> flags: ACC_PUBLIC<br> Code:<br> stack=1, locals=1, args_size=1<br> 0: aload_0<br> 1: invokespecial #1 // Method java/lang/Object."<init>":()V<br> 4: return<br> LineNumberTable:<br> line 6: 0<br> LocalVariableTable:<br> Start Length Slot Name Signature<br> 0 5 0 this Lcom/byit/test/SynText;<br><br> public synchronized void syncTask();<br> descriptor: ()V<br> flags: ACC_PUBLIC, ACC_SYNCHRONIZED<br> Code:<br> stack=3, locals=1, args_size=1<br> 0: aload_0<br> 1: dup<br> 2: getfield #2 // Field i:I<br> 5: iconst_1<br> 6: iadd<br> 7: putfield #2 // Field i:I<br> 10: return<br> LineNumberTable:<br> line 10: 0<br> line 11: 10<br> LocalVariableTable:<br> Start Length Slot Name Signature<br> 0 11 0 this Lcom/byit/test/SynText;<br>}<br>SourceFile: "SynText.java"<br></init></init></init></init></code>简化,在简化
<code> public synchronized void syncTask();<br> descriptor: ()V<br> flags: ACC_PUBLIC, ACC_SYNCHRONIZED<br> Code:<br> stack=3, locals=1, args_size=1<br> 0: aload_0<br> 1: dup</code>
我们能够看到 flags: ACC_PUBLIC, ACC_SYNCHRONIZED这样的一句话
从字节码中可以看出,synchronized修饰的方法并没有monitorenter指令和monitorexit指令,取得代之的确实是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法,JVM通过该ACC_SYNCHRONIZED访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。这便是synchronized锁在同步代码块和同步方法上实现的基本原理。
那么在JAVA6之前,为什么synchronized会如此的慢?
那是因为,操作系统实现线程之间的切换需要系统内核从用户态切换到核心态!这个状态之间的转换,需要较长的时间,时间成本高!所以这也就是synchronized慢的原因!
在这之前,你需要知道什么是锁膨胀!他是JAVA6之后新增的一个概念!是一种针对之前重量级锁的一种性能的优化!他的优化,大部分是基于经验上的一些感官,对锁来进行优化!
研究发现,大多数情况下,锁不仅不存在多线程竞争,而且还总是由一条线程获得!因为为了减少锁申请的次数!引进了偏向锁!在没有锁竞争的情况下,如果一个线程获取到了锁,那么锁就进入偏向锁的模式!当线程再一次请求锁时,无需申请,直接获取锁,进入方法!但是前提是没有锁竞争的情况,存在锁竞争,锁会立即膨胀,膨胀为轻量级锁!
偏向锁失败,那么锁膨胀为轻量级锁!此时锁机构变为轻量级锁结构!他的经验依据是:“绝大多数情况下,在整个同步周期内,不会存在锁的竞争”,故而,轻量级锁适合,线程交替进行的场景!如果在同一时间出现两条线程对同一把锁的竞争,那么此时轻量级锁就不会生效了!但是,jdk官方为了是锁的优化性能更好,轻量级锁失效后,并不会立即膨胀为重量级锁!而是将锁转换为自旋锁状态!
轻量级锁失败后,为了是避免线程挂起,引起内核态的切换!为了优化,此时线程会进入自选状态!他可能会进行几十次,上百次的空轮训!为什么呢?又是经验之谈!他们认为,大多数情况下,线程持有锁的时间都不会太长!做几次空轮训,就能大概率的等待到锁!事实证明,这种优化方式确实有效!最后如果实在等不到锁!没办法,才会彻底升级为重量级锁!
jvm在进行代码编译时,会基于上下文扫描;将一些不可能存在资源竞争的的锁给消除掉!这也是JVM对于锁的一种优化方式!不得不感叹,jdk官方的脑子!举个例子!在方法体类的局部变量对象,他永远也不可能会发生锁竞争,例如:
<code>/**<br> * @author huangfu<br> */<br>public class SynText {<br> public static void add(String name1 ,String name2){<br> StringBuffer sb = new StringBuffer();<br> sb.append(name1).append(name2);<br> }<br><br> public static void main(String[] args) {<br> for (int i = 0; i add("w"+i,"q"+i);<br> }<br> }<br>}</code>不能否认,StringBuffer是线程安全的!但是他永远也不会被其他线程引用!故而,锁失效!故而,被消除掉!
위 내용은 Java의 동기화 키워드는 스레드 동기화를 달성하는 데 사용됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



