

흥미롭고 강력한 Python 라이브러리

Python 언어는 항상 풍부한 타사 라이브러리로 유명했습니다. 오늘은 재미있고 재미있고 강력한 몇 가지 아주 멋진 라이브러리를 소개하겠습니다!
데이터 수집
오늘날의 인터넷 시대에는 데이터가 정말 중요합니다. 먼저 우수한 데이터 수집 프로젝트 몇 가지를 소개하겠습니다.
AKShare
AKShare는 Python 기반의 금융 데이터 인터페이스 라이브러리로, 주식 분석을 실현하는 것을 목적으로 합니다. 외환, 채권, 지수, 암호화폐 등 금융상품의 기초 데이터, 실시간 및 과거 시장 데이터, 파생 데이터에 대한 데이터 수집, 데이터 정리부터 데이터 구현까지의 도구 세트입니다. 주로 학술 연구에 사용됩니다. 목적.
import akshare as ak stock_zh_a_hist_df = ak.stock_zh_a_hist(symbol="000001", period="daily", start_date="20170301", end_date='20210907', adjust="") print(stock_zh_a_hist_df)
출력:
日期开盘 收盘最高...振幅 涨跌幅 涨跌额 换手率 0 2017-03-01 9.49 9.49 9.55...0.840.110.010.21 1 2017-03-02 9.51 9.43 9.54...1.26 -0.63 -0.060.24 2 2017-03-03 9.41 9.40 9.43...0.74 -0.32 -0.030.20 3 2017-03-06 9.40 9.45 9.46...0.740.530.050.24 4 2017-03-07 9.44 9.45 9.46...0.630.000.000.17 ............... ... ... ... ... 11002021-09-0117.4817.8817.92...5.110.450.081.19 11012021-09-0218.0018.4018.78...5.482.910.521.25 11022021-09-0318.5018.0418.50...4.35 -1.96 -0.360.72 11032021-09-0617.9318.4518.60...4.552.270.410.78 11042021-09-0718.6019.2419.56...6.564.280.790.84 [1105 rows x 11 columns]
https://github.com/akfamily/akshare
TuShare
TuShare는 주식과 같은 금융 데이터의 데이터 저장, 정리 및 처리 과정을 구현하는 도구입니다. /futures, 금융 정량 분석가와 데이터 분석을 연구하는 사람들의 데이터 수집 요구 사항 충족 넓은 데이터 범위, 간단한 인터페이스 호출 및 빠른 응답이 특징입니다.
그러나 이 프로젝트의 일부 기능은 유료이므로 선택하여 사용하세요.
import tushare as ts
ts.get_hist_data('600848') #一次性获取全部数据출력:
openhigh close low volumep_changema5 date 2012-01-11 6.880 7.380 7.060 6.880 14129.96 2.62 7.060 2012-01-12 7.050 7.100 6.980 6.9007895.19-1.13 7.020 2012-01-13 6.950 7.000 6.700 6.6906611.87-4.01 6.913 2012-01-16 6.680 6.750 6.510 6.4802941.63-2.84 6.813 2012-01-17 6.660 6.880 6.860 6.4608642.57 5.38 6.822 2012-01-18 7.000 7.300 6.890 6.880 13075.40 0.44 6.788 2012-01-19 6.690 6.950 6.890 6.6806117.32 0.00 6.770 2012-01-20 6.870 7.080 7.010 6.8706813.09 1.74 6.832 ma10ma20v_ma5 v_ma10 v_ma20 turnover date 2012-01-11 7.060 7.060 14129.96 14129.96 14129.96 0.48 2012-01-12 7.020 7.020 11012.58 11012.58 11012.58 0.27 2012-01-13 6.913 6.9139545.679545.679545.67 0.23 2012-01-16 6.813 6.8137894.667894.667894.66 0.10 2012-01-17 6.822 6.8228044.248044.248044.24 0.30 2012-01-18 6.833 6.8337833.338882.778882.77 0.45 2012-01-19 6.841 6.8417477.768487.718487.71 0.21 2012-01-20 6.863 6.8637518.008278.388278.38 0.23
https://github.com/waditu/tushare
GoPUP
GoPUP 프로젝트에서 수집한 데이터 공개 데이터 소스에서 제공되는 데이터에는 개인 정보 보호 데이터나 비공개 데이터가 포함되지 않습니다. 그러나 마찬가지로 일부 인터페이스를 사용하려면 TOKEN 등록이 필요합니다.
import gopup as gp df = gp.weibo_index(word="疫情", time_type="1hour") print(df)
출력:
疫情 index 2022-12-17 18:15:0018544 2022-12-17 18:20:0014927 2022-12-17 18:25:0013004 2022-12-17 18:30:0013145 2022-12-17 18:35:0013485 2022-12-17 18:40:0014091 2022-12-17 18:45:0014265 2022-12-17 18:50:0014115 2022-12-17 18:55:0015313 2022-12-17 19:00:0014346 2022-12-17 19:05:0014457 2022-12-17 19:10:0013495 2022-12-17 19:15:0014133
https://github.com/justinzm/gopup
GeneralNewsExtractor
이 프로젝트는 "텍스트 및 기호 밀도에 따른 웹페이지 텍스트 추출 방법" 논문을 기반으로 하며 텍스트 추출기를 사용합니다. Python으로 구현되어 HTML에서 텍스트의 내용, 작성자 및 제목을 추출하는 데 사용할 수 있습니다.
>>> from gne import GeneralNewsExtractor >>> html = '''经过渲染的网页 HTML 代码''' >>> extractor = GeneralNewsExtractor() >>> result = extractor.extract(html, noise_node_list=['//div[@]']) >>> print(result)
출력:
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}뉴스 페이지 추출 예시
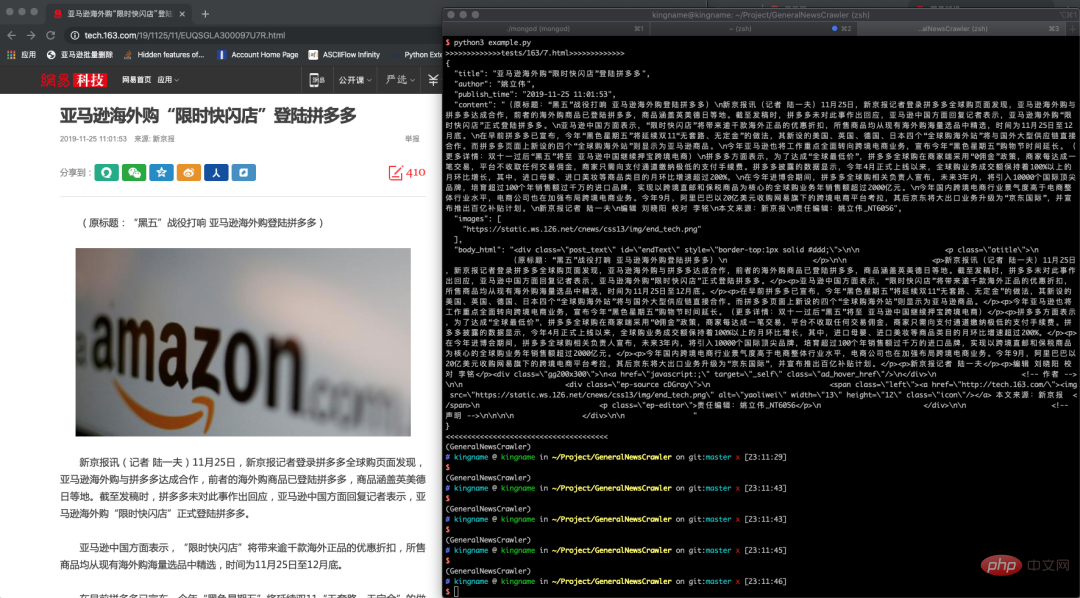
https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
Crawler
Crawler도 Python 언어의 주요 응용 방향이며, 많은 친구들이 또한 동일합니다. 크롤러를 시작하려면 몇 가지 훌륭한 크롤러 프로젝트를 살펴보겠습니다.
playwright-python
Microsoft의 오픈 소스 브라우저 자동화 도구는 Python 언어를 사용하여 브라우저를 작동할 수 있습니다. Linux, macOS 및 Windows 시스템에서 Chromium, Firefox 및 WebKit 브라우저를 지원합니다.
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch()
page = browser.new_page()
page.goto('http://whatsmyuseragent.org/')
page.screenshot(path=f'example-{browser_type.name}.png')
browser.close()https://github.com/microsoft/playwright-python
awesome-python-login-model
이 프로젝트는 주요 웹사이트의 로그인 방법과 일부 웹사이트의 크롤러 프로그램을 수집합니다. 로그인 방법에는 셀레늄 로그인, 패킷 캡처를 통한 직접 시뮬레이션 로그인 등이 포함됩니다. 초보자가 크롤러를 연구하고 작성하는 데 도움이 됩니다.
그러나 우리 모두 알고 있듯이 크롤러는 사후 유지 관리를 매우 요구합니다. 프로젝트가 오랫동안 업데이트되지 않았기 때문에 여전히 다양한 로그인 인터페이스를 정상적으로 사용할 수 있는지 의문이 있습니다. , 아니면 스스로 개발하세요.

https://github.com/Kr1s77/awesome-python-login-model
DecryptLogin
이 프로젝트는 이전 프로젝트와 비교하여 계속 업데이트되고 있으며 주요 웹 사이트에 대한 로그인도 시뮬레이션합니다. . , 초보자에게는 여전히 훌륭한 연구 가치가 있습니다.
from DecryptLogin import login # the instanced Login class object lg = login.Login() # use the provided api function to login in the target website (e.g., twitter) infos_return, session = lg.twitter(username='Your Username', password='Your Password')
https://github.com/CharlesPikachu/DecryptLogin
Scylla
Scylla는 현재 Python 3.6만 지원하는 고품질 무료 프록시 IP 풀링 도구입니다.
http://localhost:8899/api/v1/stats
출력:
{
"median": 181.2566407083,
"valid_count": 1780,
"total_count": 9528,
"mean": 174.3290085201
}https://github.com/scylladb/scylladb
ProxyPool
Crawler 프록시 IP 풀 프로젝트의 주요 기능은 확인 및 저장을 위해 온라인에 게시된 무료 프록시를 정기적으로 수집하는 것입니다. 에이전트는 에이전트의 가용성을 보장하고 API와 CLI라는 두 가지 사용 방법을 제공합니다. 동시에 프록시 소스를 확장하여 프록시 풀 IP의 품질과 수량을 늘릴 수도 있습니다. 프로젝트 설계 문서는 상세하고 모듈 구조는 간결하고 이해하기 쉽습니다. 또한 초보 크롤러가 크롤러 기술을 더 잘 배우는 데 적합합니다.
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return Nonehttps://github.com/Python3WebSpider/ProxyPool
getproxy
getproxy는 프록시 웹사이트를 크롤링 및 배포하고 http/https 프록시를 획득하여 15분마다 데이터를 업데이트하는 프로그램입니다.
(test2.7) ➜~ getproxy INFO:getproxy.getproxy:[*] Init INFO:getproxy.getproxy:[*] Current Ip Address: 1.1.1.1 INFO:getproxy.getproxy:[*] Load input proxies INFO:getproxy.getproxy:[*] Validate input proxies INFO:getproxy.getproxy:[*] Load plugins INFO:getproxy.getproxy:[*] Grab proxies INFO:getproxy.getproxy:[*] Validate web proxies INFO:getproxy.getproxy:[*] Check 6666 proxies, Got 666 valid proxies ...
https://github.com/fate0/getproxy
freeproxy
또한 무료 프록시 크롤링을 위한 프로젝트입니다. 이 프로젝트는 많은 프록시 웹사이트 크롤링을 지원하며 사용하기 쉽습니다.
from freeproxy import freeproxy
proxy_sources = ['proxylistplus', 'kuaidaili']
fp_client = freeproxy.FreeProxy(proxy_sources=proxy_sources)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = fp_client.get('https://space.bilibili.com/406756145', headers=headers)
print(response.text)https://github.com/CharlesPikachu/freeproxy
fake-useragent
크롤러에 일반적으로 사용되는 브라우저 ID를 위장합니다. 이 프로젝트의 코드는 매우 작습니다. 코드를 읽으면 ua.random이 어떻게 임의의 브라우저 ID를 반환하는지 확인할 수 있습니다.
from fake_useragent import UserAgent ua = UserAgent() ua.ie # Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US); ua.msie # Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)' ua['Internet Explorer'] # Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US) ua.opera # Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11 ua.chrome # Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2' ua.google # Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13 ua['google chrome'] # Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11 ua.firefox # Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1 ua.ff # Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1 ua.safari # Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25 # and the best one, get a random browser user-agent string ua.random
https://github.com/fake-useragent/fake-useragent
웹 관련
Python Web에는 Django, Flask 등 우수하고 오래된 라이브러리가 너무 많아서 언급하지 않겠습니다 여러분 그들을 알고 있으므로 틈새지만 유용한 몇 가지를 소개합니다.
streamlit
streamlit은 데이터를 시각적인 대화형 페이지로 신속하게 변환할 수 있는 Python 프레임워크입니다. 몇 분 만에 데이터를 그래프로 변환할 수 있습니다.
import streamlit as st
x = st.slider('Select a value')
st.write(x, 'squared is', x * x)출력:
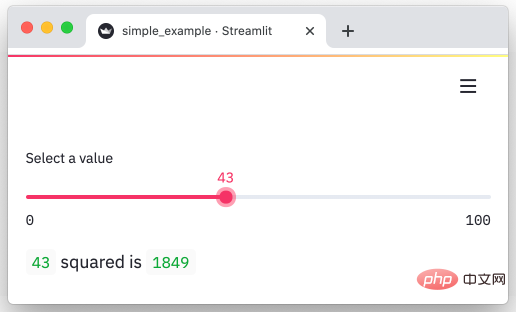
https://github.com/streamlit/streamlit
wagtail
是一个强大的开源 Django CMS(内容管理系统)。首先该项目更新、迭代活跃,其次项目首页提到的功能都是免费的,没有付费解锁的骚操作。专注于内容管理,不束缚前端实现。
https://github.com/wagtail/wagtail
fastapi
基于 Python 3.6+ 的高性能 Web 框架。“人如其名”用 FastAPI 写接口那叫一个快、调试方便,Python 在进步而它基于这些进步,让 Web 开发变得更快、更强。
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}https://github.com/tiangolo/fastapi
django-blog-tutorial
这是一个 Django 使用教程,该项目一步步带我们使用 Django 从零开发一个个人博客系统,在实践的同时掌握 Django 的开发技巧。
https://github.com/jukanntenn/django-blog-tutorial
dash
dash 是一个专门为机器学习而来的 Web 框架,通过该框架可以快速搭建一个机器学习 APP。
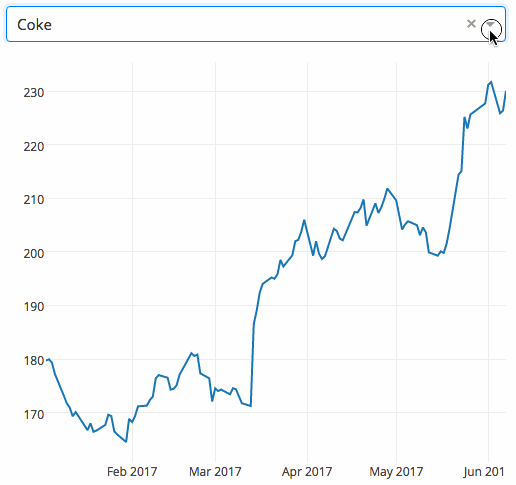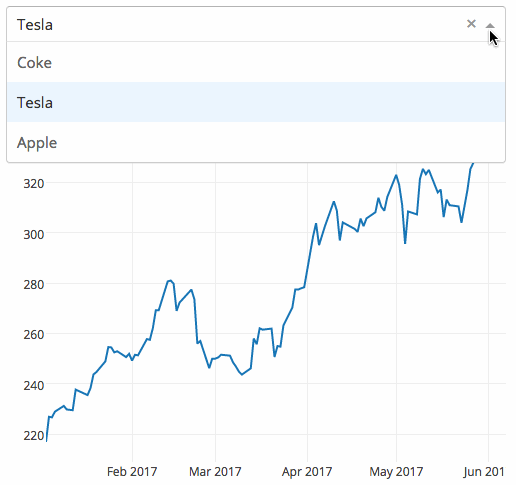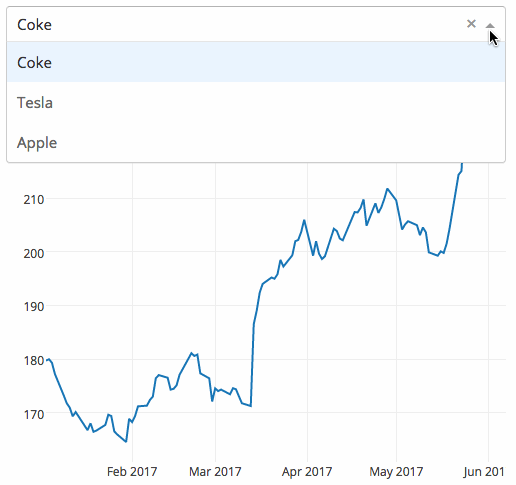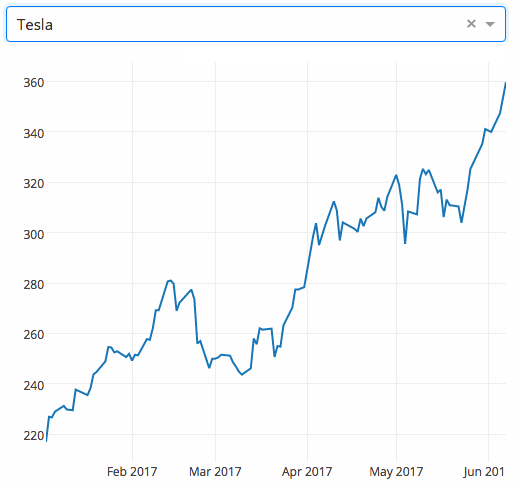
https://github.com/plotly/dash
PyWebIO
同样是一个非常优秀的 Python Web 框架,在不需要编写前端代码的情况下就可以完成整个 Web 页面的搭建,实在是方便。
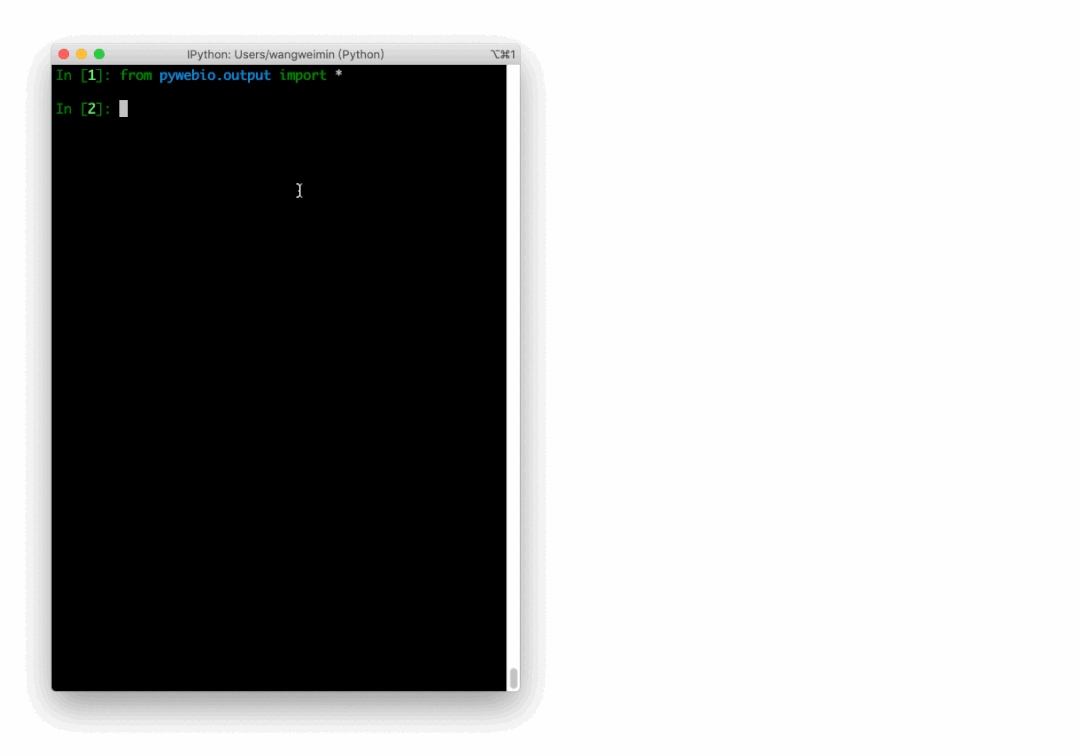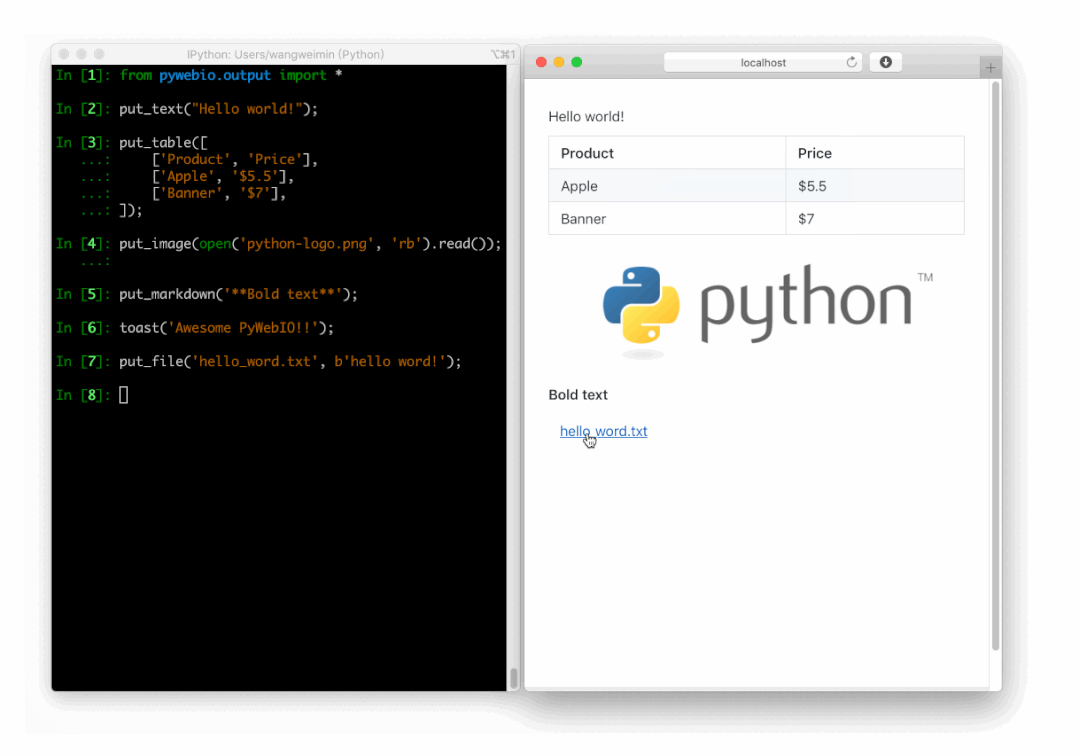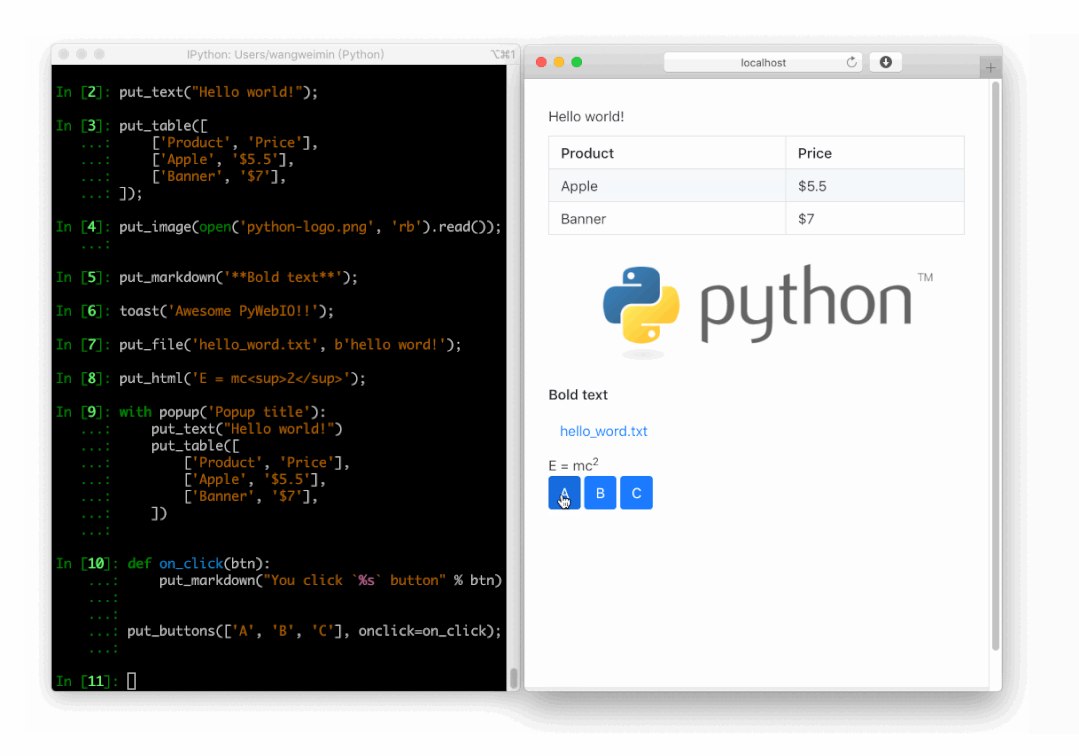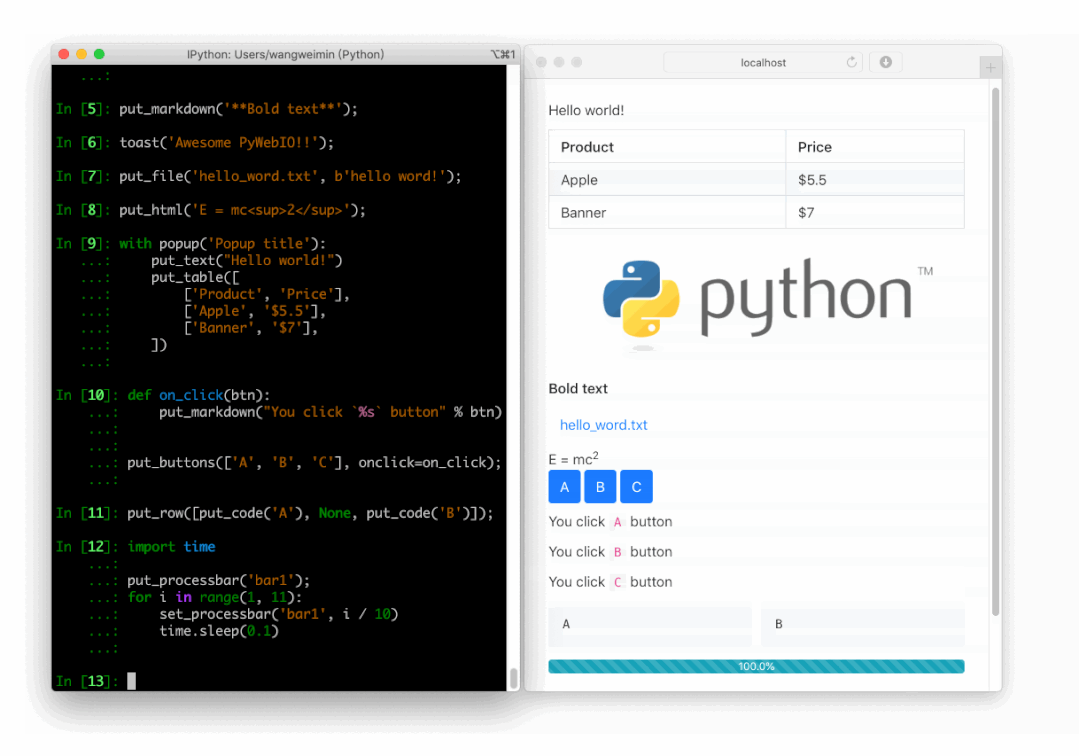
https://github.com/pywebio/PyWebIO
Python 教程
practical-python
一个人气超高的 Python 学习资源项目,是 MarkDown 格式的教程,非常友好。
https://github.com/dabeaz-course/practical-python
learn-python3
一个 Python3 的教程,该教程采用 Jupyter notebooks 形式,便于运行和阅读。并且还包含了练习题,对新手友好。
https://github.com/jerry-git/learn-python3
python-guide
Requests 库的作者——kennethreitz,写的 Python 入门教程。不单单是语法层面的,涵盖项目结构、代码风格,进阶、工具等方方面面。一起在教程中领略大神的风采吧~
https://github.com/realpython/python-guide
其他
pytools
这是一位大神编写的类似工具集的项目,里面包含了众多有趣的小工具。
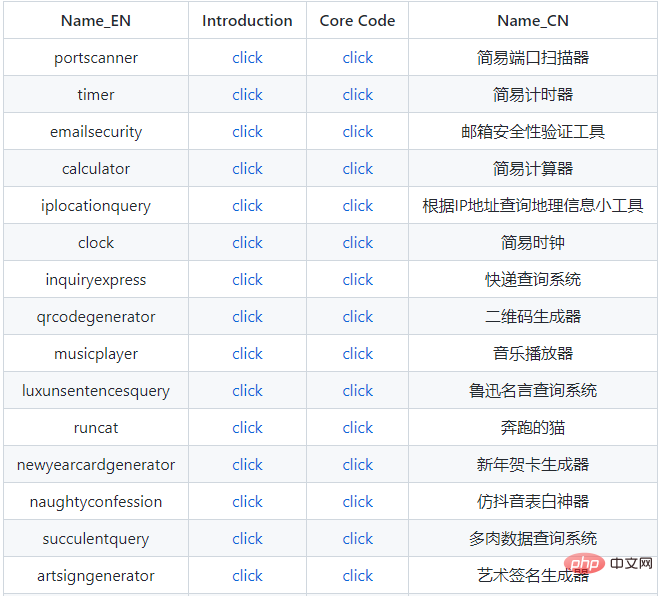
截图只是冰山一角,全貌需要大家自行探索了
import random from pytools import pytools tool_client = pytools.pytools() all_supports = tool_client.getallsupported() tool_client.execute(random.choice(list(all_supports.values())))
https://github.com/CharlesPikachu/pytools
amazing-qr
可以生成动态、彩色、各式各样的二维码,真是个有趣的库。
#3 -n, -d amzqr https://github.com -n github_qr.jpg -d .../paths/
https://github.com/x-hw/amazing-qr
sh
sh 是一个成熟的,用于替代 subprocess 的库,它允许我们调用任何程序,看起来它就是一个函数一样。
$> ./run.sh FunctionalTests.test_unicode_arg
https://github.com/amoffat/sh
tqdm
强大、快速、易扩展的 Python 进度条库。
from tqdm import tqdm for i in tqdm(range(10000)): ...
https://github.com/tqdm/tqdm
loguru
一个让 Python 记录日志变得简单的库。
from loguru import logger
logger.debug("That's it, beautiful and simple logging!")https://github.com/Delgan/loguru
click
Python 的第三方库,用于快速创建命令行。支持装饰器方式调用、多种参数类型、自动生成帮助信息等。
import click
@click.command()
@click.option("--count", default=1, help="Number of greetings.")
@click.option("--name", prompt="Your name", help="The person to greet.")
def hello(count, name):
"""Simple program that greets NAME for a total of COUNT times."""
for _ in range(count):
click.echo(f"Hello, {name}!")
if __name__ == '__main__':
hello()Output:
$ python hello.py --count=3 Your name: Click Hello, Click! Hello, Click! Hello, Click!
KeymouseGo
Python 实现的精简绿色版按键精灵,记录用户的鼠标、键盘操作,自动执行之前记录的操作,可设定执行的次数。在进行某些简单、单调重复的操作时,使用该软件可以十分省事儿。只需要录制一遍,剩下的交给 KeymouseGo 来做就可以了。
https://github.com/taojy123/KeymouseGo
위 내용은 흥미롭고 강력한 Python 라이브러리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7569
7569
 15
1386
52
87
11
61
19
28
107
15
1386
52
87
11
61
19
28
107

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
